Recognition: 2 theorem links
· Lean TheoremToward Individual Fairness Without Centralized Data: Selective Counterfactual Consistency for Vertical Federated Learning
Pith reviewed 2026-05-11 01:41 UTC · model grok-4.3
The pith
Individual fairness can be enforced in vertical federated learning by selectively enforcing counterfactual consistency using private sketches of sensitive attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
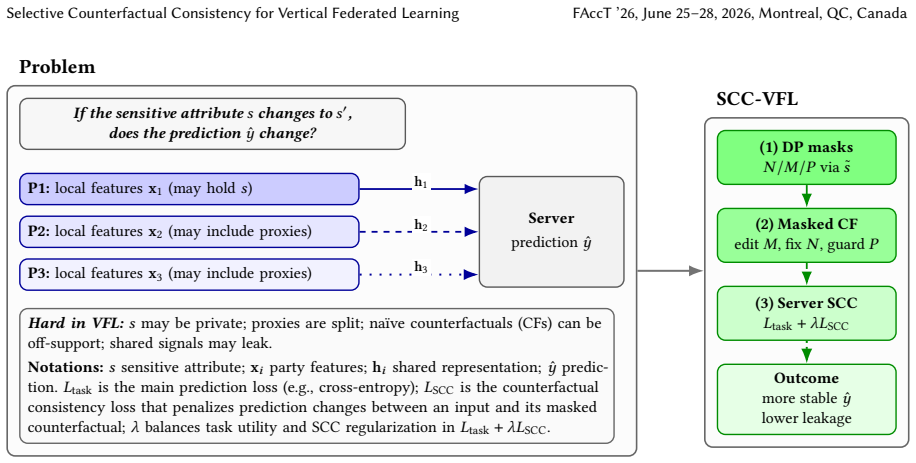
SCC-VFL operationalizes a policy by combining differentially private, graph-free discovery of feature roles using only a private sketch of the sensitive attribute, masked counterfactual generation that edits only mediators while fixing non-descendants and suppressing proxies, and server-side enforcement of an SCC consistency loss that penalizes impermissible prediction changes. On three real-world datasets this yields maintained or improved predictive accuracy together with up to 98 percent lower decision flip rates under protected-attribute interventions, plus reduced attribute-inference attack success.
What carries the argument
Selective counterfactual consistency (SCC) enforced through differentially private feature-role discovery and masked counterfactual generation that isolates policy-permitted mediators.
Load-bearing premise
A differentially private sketch of the sensitive attribute is enough to correctly classify features into non-descendants, mediators, and proxies without producing errors that would invalidate the masked counterfactuals or the consistency enforcement.
What would settle it
Run the role-discovery procedure on a synthetic vertical dataset whose true causal graph and feature roles are known in advance, then measure whether the recovered roles match the ground truth closely enough to produce the claimed reduction in flip rates without accuracy loss.
Figures




read the original abstract
When algorithmic decisions depend on data distributed across institutions, how can we ensure that an individual's outcome does not change arbitrarily based on a protected attribute? We study this question in vertical federated learning (VFL), where features are split across parties, sensitive attributes may be private, and proxies for protected characteristics can be scattered across institutional boundaries under strict privacy constraints. Our focus is on individual-level counterfactual stability, i.e., per-instance prediction consistency under protected-attribute interventions as formalized in the causal fairness literature, rather than group parity guarantees such as demographic parity or equalized odds. We propose SCC-VFL, a server-centric framework for enforcing selective counterfactual consistency (SCC) at the individual level in VFL. SCC-VFL operationalizes a given policy specification by combining three components: (i) differentially private, graph-free discovery of feature roles into non-descendants, policy-permitted mediators, and impermissible proxies using only a formally private sketch of the sensitive attribute, with a formal per-release privacy that does not extend to the full training pipeline; (ii) masked counterfactual generation that edits only mediators while fixing non-descendants and suppressing proxy leakage; and (iii) server-side enforcement via an SCC consistency loss that penalizes impermissible prediction changes under protected-attribute interventions. Across three real-world datasets spanning credit, healthcare, and criminal justice, SCC-VFL maintains or improves predictive accuracy while sharply reducing decision flip rates by up to 98% relative to strong baselines. It also lowers attribute-inference attack success and improves robustness, demonstrating favorable utility-fairness-privacy trade-offs in realistic VFL deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SCC-VFL, a server-centric framework for individual fairness in vertical federated learning via selective counterfactual consistency. It discovers feature roles (non-descendants, policy-permitted mediators, impermissible proxies) using a differentially private graph-free sketch of the sensitive attribute, generates masked counterfactuals that edit only permitted mediators while suppressing proxies, and enforces an SCC consistency loss on the server to penalize impermissible prediction changes under protected-attribute interventions. Empirical evaluation on three real-world datasets (credit, healthcare, criminal justice) claims maintained or improved predictive accuracy alongside up to 98% reduction in decision flip rates relative to baselines, plus improved robustness and lower attribute-inference attack success.
Significance. If the DP sketch accurately recovers feature roles and the masked counterfactuals correctly isolate impermissible paths, the framework would offer a meaningful advance in applying causal individual fairness to privacy-constrained VFL settings without data centralization. The explicit policy-driven role partition and server-side loss provide a concrete operationalization of counterfactual stability that goes beyond group fairness metrics, and the reported utility-fairness-privacy trade-offs on heterogeneous real datasets indicate practical relevance for domains like credit and healthcare.
major comments (2)
- [Abstract] Abstract, component (i): the central claim of maintained accuracy plus up to 98% flip-rate reduction rests on the DP sketch correctly partitioning features into non-descendants, mediators, and proxies; however, no error rates, sensitivity analysis, or validation of role-assignment accuracy under the stated per-release privacy noise are provided, leaving open the possibility that noise flips proxies into mediators (or vice versa) and thereby invalidates the masked counterfactual generation in (ii) and the SCC loss in (iii).
- [Abstract] Abstract: the reported empirical gains supply no information on the precise baselines, hyperparameter choices, statistical significance tests, or exact privacy budgets used to obtain the 98% flip-rate reduction, making it impossible to assess whether the numbers are robust or whether they depend on favorable sketch parameters that may not generalize.
minor comments (1)
- [Abstract] The abstract refers to 'formally private sketch' and 'per-release privacy' without clarifying how these compose with the full training pipeline; a brief note on the scope of the privacy guarantee would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract, component (i): the central claim of maintained accuracy plus up to 98% flip-rate reduction rests on the DP sketch correctly partitioning features into non-descendants, mediators, and proxies; however, no error rates, sensitivity analysis, or validation of role-assignment accuracy under the stated per-release privacy noise are provided, leaving open the possibility that noise flips proxies into mediators (or vice versa) and thereby invalidates the masked counterfactual generation in (ii) and the SCC loss in (iii).
Authors: We acknowledge that while the manuscript provides formal differential privacy guarantees for the per-release sketch of the sensitive attribute, it does not include sufficient empirical validation of role-assignment accuracy under noise. This is a valid concern, as misclassification could affect downstream components. In the revised manuscript, we will add a dedicated sensitivity analysis subsection reporting error rates for feature role discovery (non-descendants, mediators, proxies) across multiple privacy budgets and datasets. We will also include cases simulating noise-induced flips and demonstrate their limited impact on the masked counterfactuals and SCC loss, thereby strengthening the empirical support for the central claims. revision: yes
-
Referee: [Abstract] Abstract: the reported empirical gains supply no information on the precise baselines, hyperparameter choices, statistical significance tests, or exact privacy budgets used to obtain the 98% flip-rate reduction, making it impossible to assess whether the numbers are robust or whether they depend on favorable sketch parameters that may not generalize.
Authors: The full experimental section of the manuscript details the baselines (standard VFL, group-fairness VFL variants), hyperparameter grids, and privacy budgets, with results averaged over multiple random seeds. However, we agree the abstract omits these specifics, which hinders immediate assessment. We will revise the abstract to concisely note the key baselines, the privacy budgets (e.g., ε values) yielding the reported gains, and that improvements are statistically significant via paired t-tests (p < 0.05). Hyperparameter sensitivity will be further emphasized in the main text to address generalizability concerns. revision: partial
Circularity Check
No significant circularity in SCC-VFL derivation or claims
full rationale
The paper introduces SCC-VFL as a server-centric framework that combines a differentially private sketch for feature-role discovery, masked counterfactual generation, and a consistency loss for enforcing selective counterfactual consistency. No equations, derivations, or self-citations in the abstract or described components reduce the consistency loss, flip-rate reductions, or accuracy claims to quantities defined in terms of themselves or to fitted inputs renamed as predictions. The central results rest on empirical evaluation across external real-world datasets rather than internal self-definition or load-bearing self-citation chains, rendering the approach self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Feature roles (non-descendants, policy-permitted mediators, impermissible proxies) can be recovered from a differentially private sketch of the sensitive attribute.
- domain assumption Masked counterfactual generation can edit only mediators while fixing non-descendants and suppressing proxy leakage under the given privacy constraints.
invented entities (1)
-
SCC consistency loss
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
differentially private, graph-free discovery of feature roles into non-descendants, policy-permitted mediators, and impermissible proxies using only a formally private sketch of the sensitive attribute
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
server-side enforcement via an SCC consistency loss that penalizes impermissible prediction changes under protected-attribute interventions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2023.Fairness and Machine Learning: Limitations and Opportunities
Solon Barocas, Moritz Hardt, and Arvind Narayanan. 2023.Fairness and Machine Learning: Limitations and Opportunities. MIT Press. https://fairmlbook.org/
work page 2023
-
[2]
Solon Barocas and Andrew D Selbst. 2016. Big data’s disparate impact.Calif. L. Rev.104 (2016), 671
work page 2016
-
[3]
Solon Barocas, Andrew D Selbst, and Manish Raghavan. 2020. The hidden assumptions behind counterfactual explanations and principal reasons. InProceedings of the 2020 conference on fairness, accountability, and transparency. 80–89
work page 2020
-
[4]
Reuben Binns. 2020. On the apparent conflict between individual and group fairness. InProceedings of the 2020 conference on fairness, accountability, and transparency. 514–524
work page 2020
-
[5]
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. Practical secure aggregation for privacy-preserving machine learning. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 1175–1191
work page 2017
-
[6]
Yuhang Chen, Wenke Huang, and Mang Ye. 2024. Fair federated learning under domain skew with local consistency and domain diversity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12077–12086
work page 2024
-
[7]
Silvia Chiappa. 2019. Path-specific counterfactual fairness. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 7801–7808
work page 2019
-
[8]
Alexandra Chouldechova. 2017. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments.Big Data5, 2 (2017), 153–163
work page 2017
- [9]
-
[10]
Sam Corbett-Davies, Emma Pierson, Avi Feller, Sharad Goel, and Aziz Huq. 2017. Algorithmic decision making and the cost of fairness. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 797–806
work page 2017
-
[11]
Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. 2021. Retiring adult: New datasets for fair machine learning.Advances in Neural Information Processing Systems34 (2021), 6478–6490
work page 2021
-
[12]
Julia Dressel and Hany Farid. 2018. The accuracy, fairness, and limits of predicting recidivism.Science Advances4, 1 (2018), eaao5580
work page 2018
-
[13]
Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard S. Zemel. 2012. Fairness through Awareness. InInnovations in Theoretical Computer Science 2012, Cambridge, MA, USA, January 8-10, 2012. ACM, 214–226. doi:10.1145/2090236.2090255
-
[14]
Cynthia Dwork and Aaron Roth. 2014. The algorithmic foundations of differential privacy.Foundations and trends®in theoretical computer science9, 3-4 (2014), 211–487
work page 2014
-
[15]
Yahya H Ezzeldin, Shen Yan, Chaoyang He, Emilio Ferrara, and A Salman Avestimehr. 2023. Fairfed: Enabling group fairness in federated learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 7494–7502
work page 2023
-
[16]
Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian
Michael Feldman, Sorelle A. Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian. 2015. Certifying and Removing Disparate Impact. InProceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, August 10-13, 2015. ACM, 259–268. doi:10.1145/2783258.2783311
-
[17]
Chong Fu, Xuhong Zhang, Shouling Ji, Jinyin Chen, Jingzheng Wu, Shanqing Guo, Jun Zhou, Alex X Liu, and Ting Wang. 2022. Label inference attacks against vertical federated learning. In31st USENIX security symposium (USENIX Security 22). 1397–1414
work page 2022
-
[18]
Sahaj Garg, Vincent Perot, Nicole Limtiaco, Ankur Taly, Ed H Chi, and Alex Beutel. 2019. Counterfactual fairness in text classification through robustness. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. 219–226
work page 2019
-
[19]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford
- [20]
-
[21]
Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Schölkopf. 2005. Measuring statistical dependence with Hilbert-Schmidt norms. InInternational conference on algorithmic learning theory. Springer, 63–77
work page 2005
-
[22]
Moritz Hardt, Eric Price, and Nati Srebro. 2016. Equality of opportunity in supervised learning.Advances in Neural Information Processing Systems29 (2016)
work page 2016
-
[23]
Hans Hofmann. 1994. Statlog (German credit data).UCI Machine Learning Repository10 (1994), C5NC77
work page 1994
-
[24]
Junyuan Hong, Zhuangdi Zhu, Shuyang Yu, Zhangyang Wang, Hiroko H Dodge, and Jiayu Zhou. 2021. Federated adversarial debiasing for fair and transferable representations. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 617–627
work page 2021
-
[25]
Andras Janosi, William Steinbrunn, Matthias Pfisterer, and Robert Detrano. 1988. UCI machine learning repository-heart disease data set.School Inf. Comput. Sci., Univ. California, Irvine, CA, USA(1988)
work page 1988
-
[26]
Xiao Jin, Pin-Yu Chen, Chia-Yi Hsu, Chia-Mu Yu, and Tianyi Chen. 2021. Cafe: Catastrophic data leakage in vertical federated learning. Advances in neural information processing systems34 (2021), 994–1006
work page 2021
-
[27]
Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Keith Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. 2021. Advances and Open Problems in Federated Learning.Foundations and Trends in Machine Learning14, 1–2 (2021), 1–210. doi:10.1561/2200000083 FAccT ’26, June 25–28, 2026, Montreal, ...
-
[28]
Atoosa Kasirzadeh and Andrew Smart. 2021. The use and misuse of counterfactuals in ethical machine learning. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency. 228–236
work page 2021
-
[29]
Niki Kilbertus, Mateo Rojas Carulla, Giambattista Parascandolo, Moritz Hardt, Dominik Janzing, and Bernhard Schölkopf. 2017. Avoiding discrimination through causal reasoning.Advances in Neural Information Processing Systems30 (2017)
work page 2017
-
[30]
Inherent trade-offs in the fair determination of risk scores
Jon M. Kleinberg, Sendhil Mullainathan, and Manish Raghavan. 2017. Inherent Trade-Offs in the Fair Determination of Risk Scores. In 8th Innovations in Theoretical Computer Science Conference, ITCS 2017, Berkeley, CA, USA, January 9-11, 2017 (LIPIcs, Vol. 67). Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 43:1–43:23. doi:10.4230/LIPICS.ITCS.2017.43
-
[31]
Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. 2017. Counterfactual fairness.Advances in Neural Information Processing Systems30 (2017)
work page 2017
-
[32]
Yang Liu, Yan Kang, Tianyuan Zou, Yanhong Pu, Yuanqin He, Xiaozhou Ye, Ye Ouyang, Ya-Qin Zhang, and Qiang Yang. 2024. Vertical federated learning: Concepts, advances, and challenges.IEEE Transactions on Knowledge and Data Engineering36, 7 (2024), 3615–3634
work page 2024
- [33]
-
[34]
Xinjian Luo, Yuncheng Wu, Xiaokui Xiao, and Beng Chin Ooi. 2021. Feature Inference Attack on Model Predictions in Vertical Federated Learning. In37th IEEE International Conference on Data Engineering (ICDE). IEEE, 181–192. doi:10.1109/ICDE51399.2021.00023
-
[35]
David Madras, Elliot Creager, Toniann Pitassi, and Richard Zemel. 2018. Learning adversarially fair and transferable representations. In International Conference on Machine Learning. PMLR, 3384–3393
work page 2018
-
[36]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas
H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) (Proceedings of Machine Learning Research, Vol. 54). PMLR, 1273–1282. https://procee...
work page 2017
-
[37]
Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov. 2019. Exploiting unintended feature leakage in collaborative learning. In2019 IEEE symposium on security and privacy (SP). IEEE, 691–706
work page 2019
-
[38]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. InProceedings of the conference on fairness, accountability, and transparency. 220–229
work page 2019
-
[39]
Razieh Nabi and Ilya Shpitser. 2018. Fair inference on outcomes. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 32
work page 2018
-
[40]
Afroditi Papadaki, Natalia Martinez, Martin Bertran, Guillermo Sapiro, and Miguel Rodrigues. 2022. Minimax demographic group fairness in federated learning. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 142–159
work page 2022
-
[41]
2009.Causality: Models, Reasoning, and Inference(2 ed.)
Judea Pearl. 2009.Causality: Models, Reasoning, and Inference(2 ed.). Cambridge University Press
work page 2009
- [42]
- [43]
-
[44]
Prasanna Sattigeri, Samuel C Hoffman, Vijil Chenthamarakshan, and Kush R Varshney. 2019. Fairness GAN: Generating datasets with fairness properties using a generative adversarial network.IBM Journal of Research and Development63, 4/5 (2019), 3–1
work page 2019
-
[45]
Andrew D Selbst, Danah Boyd, Sorelle A Friedler, Suresh Venkatasubramanian, and Janet Vertesi. 2019. Fairness and abstraction in sociotechnical systems. InProceedings of the conference on fairness, accountability, and transparency. 59–68
work page 2019
-
[46]
Berk Ustun, Alexander Spangher, and Yang Liu. 2019. Actionable recourse in linear classification. InProceedings of the conference on fairness, accountability, and transparency. 10–19
work page 2019
-
[47]
Boris Van Breugel, Trent Kyono, Jeroen Berrevoets, and Mihaela Van der Schaar. 2021. Decaf: Generating fair synthetic data using causally-aware generative networks.Advances in Neural Information Processing Systems34 (2021), 22221–22233
work page 2021
-
[48]
Sandra Wachter, Brent Mittelstadt, and Chris Russell. 2018. Counterfactual explanations without opening the black box: Automated decisions and the GDPR.Harvard Journal of Law & Technology31, 2 (2018), 841–887
work page 2018
-
[49]
Yu Wang, Yuying Zhao, Yushun Dong, Huiyuan Chen, Jundong Li, and Tyler Derr. 2022. Improving fairness in graph neural networks via mitigating sensitive attribute leakage. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1938–1948
work page 2022
-
[50]
Dawood Wasif, Dian Chen, Sindhuja Madabushi, Nithin Alluru, Terrence J Moore, and Jin-Hee Cho. 2025. Empirical analysis of privacy-fairness-accuracy trade-offs in federated learning: a step towards responsible AI. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 8. 2666–2677
work page 2025
-
[51]
Dawood Wasif, Terrence J Moore, and Jin-Hee Cho. 2025. RESFL: An Uncertainty-Aware Framework for Responsible Federated Learning by Balancing Privacy, Fairness and Utility in Autonomous Vehicles.arXiv preprint arXiv:2503.16251(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Hilde Weerts, Raphaële Xenidis, Fabien Tarissan, Henrik Palmer Olsen, and Mykola Pechenizkiy. 2023. Algorithmic unfairness through the lens of EU non-discrimination law: Or why the law is not a decision tree. InProceedings of the 2023 ACM conference on fairness, accountability, and transparency. 805–816. Selective Counterfactual Consistency for Vertical F...
work page 2023
- [53]
-
[54]
Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. 2019. Federated Machine Learning: Concept and Applications.ACM Transactions on Intelligent Systems and Technology10, 2 (2019), 12:1–12:19. doi:10.1145/3298981
-
[55]
Xubo Yue, Maher Nouiehed, and Raed Al Kontar. 2023. Gifair-fl: A framework for group and individual fairness in federated learning. INFORMS Journal on Data Science2, 1 (2023), 10–23
work page 2023
- [56]
- [57]
-
[58]
Richard Zemel, Yu Wu, Kevin Swersky, Toni Pitassi, and Cynthia Dwork. 2013. Learning Fair Representations. InProceedings of the 30th International Conference on Machine Learning (ICML), Vol. 28. PMLR, 325–333. https://proceedings.mlr.press/v28/zemel13.html
work page 2013
-
[59]
Brian Hu Zhang, Blake Lemoine, and Margaret Mitchell. 2018. Mitigating Unwanted Biases with Adversarial Learning. InProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society (AIES). ACM, 335–340. doi:10.1145/3278721.3278779
-
[60]
Junzhe Zhang and Elias Bareinboim. 2018. Equality of opportunity in classification: A causal approach.Advances in Neural Information Processing Systems31 (2018)
work page 2018
-
[61]
Junzhe Zhang and Elias Bareinboim. 2018. Fairness in Decision-Making: The Causal Explanation Formula. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18). 2037–2045. https://aaai.org/papers/11564-fairness-in-decision- making-the-causal-explanation-formula/
work page 2018
-
[62]
Tianxiang Zhao, Enyan Dai, Kai Shu, and Suhang Wang. 2022. Towards fair classifiers without sensitive attributes: Exploring biases in related features. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 1433–1442
work page 2022
-
[63]
Aoqi Zuo, Susan Wei, Tongliang Liu, Bo Han, Kun Zhang, and Mingming Gong. 2022. Counterfactual fairness with partially known causal graph.Advances in Neural Information Processing Systems35 (2022), 1238–1252. FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Wasif et al. APPENDICES A Datasets and Client Partitions We use three tabular benchmarks with a he...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.