Recognition: 2 theorem links
· Lean TheoremTopology-Enhanced Alignment for Large Language Models: Trajectory Topology Loss and Topological Preference Optimization
Pith reviewed 2026-05-11 01:11 UTC · model grok-4.3
The pith
Using 0D persistent homology to guide LLM alignment trajectories improves preference metrics over non-topological baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
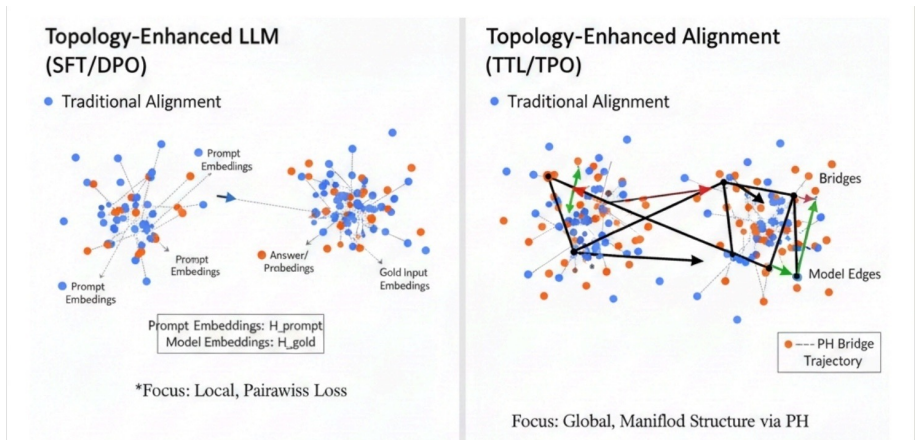
By treating prompt and answer embeddings as a mixed point cloud and applying 0D persistent homology to extract prompt-answer bridges, the model can be trained to follow these topological structures during alignment, resulting in Trajectory Topology Loss for SFT and Topological Preference Optimization for DPO that outperform standard approaches.
What carries the argument
0D persistent homology on embedding point clouds to extract 'prompt-answer bridges' that define desired update directions for alignment.
If this is right
- Topology-enhanced training yields higher automatic preference metrics than per-example, nearest-neighbor, or random regularizers.
- LLM-as-judge evaluations also rate the outputs from topology-guided models more favorably.
- Toxicity remains the same or decreases compared to baselines.
- The dynamic weighting between DPO and TPO losses helps balance the contributions effectively.
Where Pith is reading between the lines
- If the topological bridges truly capture semantic desirability, similar homology-based guidance could be applied to other LLM training objectives like safety tuning or multi-task learning.
- Extracting these bridges might allow for better diagnosis of why some alignment attempts fail by examining mismatches in the point cloud topology.
- Extending the method to higher-dimensional persistent homology could capture more complex trajectory features beyond simple bridges.
Load-bearing premise
The prompt-answer bridges found by 0D persistent homology represent directions that lead to semantically preferred model behavior.
What would settle it
If experiments with TTL and TPO on the same setup showed equal or worse performance on preference metrics and judge scores compared to the non-topological baselines, that would disprove the benefit of the topological approach.
Figures



read the original abstract
Alignment of large language models (LLMs) via SFT and RLHF/DPO typically ignores the global geometry of the representation space, relying instead on local token likelihoods or scalar scores. We view generation as tracing a semantic trajectory in hidden space and propose a topology-enhanced alignment framework that regularizes these trajectories using 0-dimensional persistent homology. First, for SFT, we introduce Trajectory Topology Loss (TTL). Treating prompt and gold-answer embeddings as a mixed point cloud, we use a 0D persistent homology algorithm to extract "prompt-answer bridges." TTL aligns the model's actual update direction with these topological bridges rather than arbitrary directions. Second, for DPO, we propose Topological Preference Optimization (TPO). TPO constructs topic-specific semantic preference vectors and aligns the improvement direction between rejected and chosen responses with these vectors in an intermediate hidden layer. We also introduce a dynamic weighting scheme to balance DPO and TPO losses. Evaluating on Qwen2.5-7B-Instruct using UltraChat and Anthropic HH-RLHF, our topology-enhanced objectives consistently outperform strong non-topological baselines (e.g., per-example, nearest-neighbor, random regularizers) on automatic preference metrics and LLM-judge evaluations, while maintaining or improving toxicity. Results show persistent homology and trajectory geometry offer a promising direction for controllable alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that incorporating 0-dimensional persistent homology to extract 'prompt-answer bridges' from mixed embedding point clouds can enhance LLM alignment. It introduces Trajectory Topology Loss (TTL) to regularize SFT updates toward these topological bridges, Topological Preference Optimization (TPO) to align DPO improvement directions with topic-specific semantic preference vectors in hidden layers, and a dynamic weighting scheme to balance the losses. On Qwen2.5-7B-Instruct fine-tuned with UltraChat and Anthropic HH-RLHF, the topology-enhanced objectives reportedly outperform non-topological baselines (per-example, nearest-neighbor, random regularizers) on automatic preference metrics and LLM-judge scores while maintaining or improving toxicity.
Significance. If the central results hold under rigorous validation, the work would demonstrate that global geometric structure in representation space can provide controllable regularization for alignment beyond local token-level or scalar-preference methods. The explicit use of persistent homology for trajectory guidance and the comparison against nearest-neighbor baselines are concrete strengths; reproducible code or machine-checked derivations are not mentioned. The significance remains provisional given the absence of statistical tests and targeted ablations.
major comments (3)
- [Method (TTL definition)] Method section on TTL: No analysis is provided showing that the 0D persistent homology 'prompt-answer bridges' (extracted from distance-based connectivity in mixed prompt-answer embeddings) correspond to semantically desirable update directions rather than incidental proximities. This assumption is load-bearing for the claim that TTL improves alignment.
- [Experiments and Results] Evaluation section: The reported outperformance lacks statistical significance tests, error bars on metrics, multiple random seeds, or ablations isolating the dynamic weighting scheme and the topological component from the specific loss formulation around the bridges. This undermines support for the central empirical claim.
- [Method (TPO definition)] TPO construction: The procedure for building 'topic-specific semantic preference vectors' and aligning rejected/chosen improvement directions with them is not accompanied by any validation that these vectors capture human-preferred semantics rather than embedding artifacts.
minor comments (2)
- The abstract and method descriptions do not specify the exact persistent homology implementation (e.g., filtration, library used) or the precise embedding layer chosen for bridge extraction, limiting reproducibility.
- Notation for 'prompt-answer bridges' and 'topic-specific semantic preference vectors' is introduced without a clear mathematical definition or pseudocode, making the connection to standard 0D PH output (birth times and merging edges) difficult to follow.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our work. We appreciate the acknowledgment of the potential value in using persistent homology to capture global geometric structure for LLM alignment, as well as the identification of areas needing stronger validation and empirical rigor. We address each major comment below with clarifications from the manuscript and indicate planned revisions to enhance the paper without overstating current results.
read point-by-point responses
-
Referee: Method section on TTL: No analysis is provided showing that the 0D persistent homology 'prompt-answer bridges' (extracted from distance-based connectivity in mixed prompt-answer embeddings) correspond to semantically desirable update directions rather than incidental proximities. This assumption is load-bearing for the claim that TTL improves alignment.
Authors: We agree that explicit validation of the semantic desirability of the bridges is a key point. The 0D persistent homology is applied to the mixed point cloud of prompt and gold-answer embeddings precisely to identify the minimal connectivity components linking each prompt to its corresponding answer; because these embeddings reside in the model's hidden space (which encodes semantic relationships learned during pretraining), the resulting bridges reflect shortest-path connections in that space rather than purely incidental proximities. In the revision we will add a qualitative section with concrete examples of extracted bridges, including cosine-similarity measurements between bridged points and manual inspection of semantic coherence (e.g., topic continuity or intent preservation). We will also note that the consistent outperformance over nearest-neighbor and random regularizers provides indirect support that the bridges are not arbitrary. A full human study of every bridge remains outside the current scope but can be flagged as future work. revision: partial
-
Referee: Evaluation section: The reported outperformance lacks statistical significance tests, error bars on metrics, multiple random seeds, or ablations isolating the dynamic weighting scheme and the topological component from the specific loss formulation around the bridges. This undermines support for the central empirical claim.
Authors: We fully concur that statistical rigor and targeted ablations are necessary to substantiate the central claims. In the revised manuscript we will (1) rerun all experiments across at least three random seeds and report means with standard deviations and error bars on all automatic metrics and LLM-judge scores; (2) conduct paired statistical tests (e.g., t-tests) between our methods and baselines to establish significance; and (3) add ablations that isolate the dynamic weighting scheme, the topological bridge component, and the full loss formulation. These additions will directly address the concern that current results may be sensitive to specific hyper-parameters or loss details. revision: yes
-
Referee: TPO construction: The procedure for building 'topic-specific semantic preference vectors' and aligning rejected/chosen improvement directions with them is not accompanied by any validation that these vectors capture human-preferred semantics rather than embedding artifacts.
Authors: We acknowledge the need for direct validation of the topic-specific vectors. The vectors are constructed by clustering responses by topic (via embedding similarity) and computing the difference between chosen and rejected hidden-state directions within each cluster; this is intended to capture preference gradients that are both topic-aware and geometrically consistent. In the revision we will add an analysis that correlates these vectors with human preference labels from the HH-RLHF dataset and with LLM-as-a-judge assessments of semantic improvement (helpfulness, harmlessness). We will also report the alignment accuracy between the TPO update directions and these validated vectors. While the overall preference-metric gains provide supporting evidence, the added checks will make the claim more robust. revision: partial
Circularity Check
No circularity: topology extracted from embeddings and used as external regularizer
full rationale
The derivation proceeds by computing 0D persistent homology on the mixed prompt-answer embedding point cloud to obtain bridges, then defining TTL to align SFT update directions to those bridges and TPO to align DPO preference vectors to topic-specific vectors derived from the same geometry. These steps use the topological output as an independent input to the loss rather than fitting parameters to the preference metric or re-expressing the homology in terms of the alignment objective. Dynamic weighting is a standard loss-balancing heuristic with no self-referential dependence on the target metrics. No self-citations are invoked to justify uniqueness or the core ansatz, and the method remains falsifiable against external baselines without reducing any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- dynamic weighting coefficients
axioms (1)
- domain assumption 0-dimensional persistent homology extracts meaningful prompt-answer bridges from mixed embedding point clouds that indicate desirable alignment directions
invented entities (2)
-
prompt-answer bridges
no independent evidence
-
topic-specific semantic preference vectors
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We treat mean-pooled embeddings of prompts and gold answers as a mixed point cloud, run a Union-Find-based 0D persistent homology algorithm, and extract 'prompt–answer bridge' edges... TTL encourages the model's actual update direction... to align with these topologically derived bridges
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ltopo = 1/|B| Σ (1 - cos(v_topo(p,a), v_model_p)) ... LSFT = L_CE + λ_topo Ltopo
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alessandro Achille and Stefano Soatto. 2018. Emergence of invariance and disentanglement in deep representations. Journal of Machine Learning Research, 19(50):1--54
work page 2018
-
[2]
Henry Adams, Trey Emerson, Martin Kirby, Christopher J. Neville, Chris Peterson, Patrick Shipman, Svetlana Chepushtanova, Mariah Hanson, Fabio Motta, and Leonard Ziegelmeier. 2015. Persistence images: A stable vector representation of persistent homology. Journal of Machine Learning Research, 18(8):1--35
work page 2015
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, and 12 others. 2022. Training a helpful and harmless assistant with reinfor...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [4]
-
[5]
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. 2017. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3319--3327
work page 2017
-
[6]
Ralph Allan Bradley and Milton E. Terry. 1952. The rank analysis of incomplete block designs: The method of paired comparisons. Biometrika, 39:324--345
work page 1952
-
[7]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. Language models are few-shot learner...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Peter Bubenik. 2015. Statistical topological data analysis using persistence landscapes. Journal of Machine Learning Research, 16(1):77--102
work page 2015
-
[9]
Gunnar Carlsson. 2009. Topology and data. Bulletin of the American Mathematical Society, 46(2):255--308
work page 2009
-
[10]
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. arXiv preprint arXiv:1706.03741
-
[11]
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. Enhancing chat language models by scaling high-quality instructional conversations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029--3051
work page 2023
-
[12]
Herbert Edelsbrunner and John Harer. 2010. Computational topology: An introduction. American Mathematical Society
work page 2010
-
[13]
Kawin Ethayarajh. 2019. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. In Proceedings of EMNLP-IJCNLP, pages 55--65
work page 2019
-
[14]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3356--3369
work page 2020
-
[15]
Robert Ghrist. 2008. Barcodes: the persistent topology of data. Bulletin of the American Mathematical Society, 45(1):61--75
work page 2008
-
[16]
Dan Hendrycks and Kevin Gimpel. 2017. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In International Conference on Learning Representations
work page 2017
-
[17]
Christoph Hofer and 1 others. 2019. Deep learning with topological signatures. In NeurIPS
work page 2019
-
[18]
Joseph Kruskal. 1956. On the shortest spanning subtree of a graph. Proc. AMS
work page 1956
-
[19]
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems, volume 31, pages 7167--7177
work page 2018
-
[20]
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. In Proceedings of the ICLR 2013 Workshop on Representation Learning for NLP
work page 2013
- [21]
-
[22]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human fee...
work page 2022
- [23]
-
[24]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290
work page internal anchor Pith review arXiv 2024
-
[25]
Maithra Raghu, Ben Poole, Jon Kleinberg, Surya Ganguli, and Jascha Sohl-Dickstein. 2017. On the expressive power of neural networks. In Proceedings of the 34th International Conference on Machine Learning, pages 2847--2854
work page 2017
-
[26]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of EMNLP-IJCNLP, pages 3982--3992
work page 2019
- [27]
-
[28]
Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. 2020. Learning to summarize from human feedback. In Advances in Neural Information Processing Systems, volume 33, pages 3008--3021
work page 2020
-
[29]
Robert Endre Tarjan. 1975. Efficiency of a good but not linear set union algorithm. Journal of the ACM, 22(2):215--225
work page 1975
-
[30]
Gomez, ukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, pages 5998--6008
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.