Recognition: no theorem link
Reformulating KV Cache Eviction Problem for Long-Context LLM Inference
Pith reviewed 2026-05-11 02:34 UTC · model grok-4.3
The pith
Reformulating KV cache eviction as an output-aware matrix multiplication approximation enables LLMs to maintain performance using only 5% of the cache.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors reformulate KV cache eviction from a conventional head-wise, weight-averaging approach into an output-aware, layer-wise matrix multiplication approximation problem. They introduce LaProx, which explicitly models the multiplicative interaction between attention maps and projected value states to quantify each token's contribution while accounting for inter-head dependencies. This metric supports the first unified eviction strategy that assigns globally comparable importance scores, enabling model-wide token selection rather than local head-wise decisions.
What carries the argument
LaProx, an eviction strategy that approximates token importance through the multiplicative interaction of attention maps and projected value states across layers and heads.
Load-bearing premise
The output-aware matrix multiplication approximation accurately quantifies each token's contribution to the final output without introducing errors that accumulate across layers or tasks.
What would settle it
Measuring accuracy on the Needle-In-A-Haystack benchmark when LaProx keeps only 5% of the KV cache and comparing the drop against both full-cache baselines and prior eviction methods; a larger drop than claimed would falsify the result.
Figures



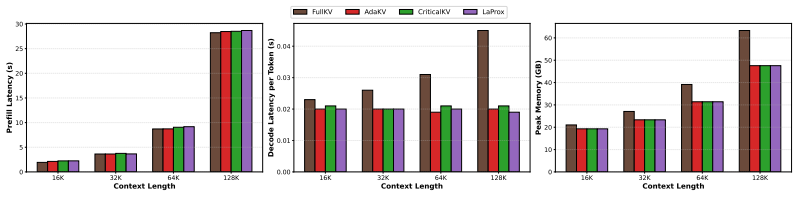


read the original abstract
Large language models (LLMs) support long-context inference but suffer from substantial memory and runtime overhead due to Key-Value (KV) Cache growth. Existing KV Cache eviction methods primarily rely on local attention weights, neglecting the influence of value representations, output projection, and inter-head interactions. In this work, we reformulate KV Cache eviction from a conventional head-wise, weight-averaging approach into an output-aware, layer-wise matrix multiplication approximation problem. We introduce LaProx, a novel eviction strategy that explicitly models the multiplicative interaction between attention maps and projected value states to accurately quantify token contributions while accounting for inter-head dependencies. Building on this metric, we propose the first unified eviction strategy that assigns globally comparable importance scores to tokens, enabling model-wide selection instead of local, head-wise decisions. Experimental results across 19 datasets on long-context benchmarks LongBench and Needle-In-A-Haystack demonstrate that our approach maintains model performance with only 5\% of the KV cache and consistently outperforms prior works across all configurations. Notably, our method achieves up to 2$\times$ accuracy loss reduction under extreme compression scenarios compared to existing state-of-the-art baselines with minimal overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reformulates KV cache eviction in long-context LLMs as an output-aware, layer-wise matrix-multiplication approximation problem rather than head-wise attention-weight averaging. It introduces the LaProx metric, which explicitly incorporates multiplicative interactions between attention maps and projected value states while accounting for inter-head dependencies, and uses this to define a unified eviction strategy that produces globally comparable token importance scores for model-wide selection. Experiments on LongBench and Needle-In-A-Haystack across 19 datasets claim that the method preserves performance at 5% KV cache size and reduces accuracy loss by up to 2× relative to prior SOTA baselines under extreme compression.
Significance. If the matrix approximation and LaProx metric are shown to be accurate without substantial error accumulation, the work would meaningfully advance efficient long-context inference by enabling more principled, globally consistent KV eviction with low overhead. The shift from local head-wise to model-wide selection addresses a recognized limitation in existing eviction literature and could improve compression ratios while better preserving output quality.
major comments (3)
- [LaProx formulation section] The derivation of the output-aware matrix-multiplication approximation (introduced when defining LaProx) is presented at a high level without explicit steps, assumptions about the output projection, or bounds on approximation error. This is load-bearing for the central claim that LaProx more accurately quantifies token contributions than attention weights alone.
- [Experiments section] The experimental claims of maintaining performance with 5% KV cache and up to 2× accuracy-loss reduction lack reported per-task scores, standard deviations, error bars, baseline re-implementation details, and data-selection criteria. These omissions make it impossible to verify the 'consistently outperforms prior works across all configurations' statement.
- [Unified eviction strategy subsection] The unified eviction strategy's assertion that LaProx scores are globally comparable across heads and layers is not supported by any quantitative analysis (e.g., score-distribution statistics or ablation comparing global vs. per-head selection). This directly affects the claimed advantage over local methods.
minor comments (2)
- Clarify the exact normalization procedure used for LaProx scores and whether it introduces any task-specific hyperparameters.
- [Experiments section] Add a table or figure summarizing the 19 datasets, their lengths, and the specific metrics reported for each benchmark.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important areas for clarification and additional support, and we address each major comment point by point below with our planned revisions.
read point-by-point responses
-
Referee: [LaProx formulation section] The derivation of the output-aware matrix-multiplication approximation (introduced when defining LaProx) is presented at a high level without explicit steps, assumptions about the output projection, or bounds on approximation error. This is load-bearing for the central claim that LaProx more accurately quantifies token contributions than attention weights alone.
Authors: We agree that expanding the derivation will improve clarity and rigor. In the revised manuscript, we will provide a step-by-step mathematical derivation of the output-aware matrix-multiplication approximation in the LaProx formulation section. We will explicitly list the assumptions, including linearity of the output projection and the handling of inter-head dependencies through the layer-wise formulation. For approximation error, we will add an empirical analysis showing observed error accumulation across layers on representative long-context inputs, along with a discussion of its impact on token importance scoring. While closed-form theoretical bounds are difficult to derive due to the input-dependent nature of attention, the added empirical validation will better substantiate the claim that LaProx captures token contributions more accurately than attention weights alone. revision: yes
-
Referee: [Experiments section] The experimental claims of maintaining performance with 5% KV cache and up to 2× accuracy-loss reduction lack reported per-task scores, standard deviations, error bars, baseline re-implementation details, and data-selection criteria. These omissions make it impossible to verify the 'consistently outperforms prior works across all configurations' statement.
Authors: We recognize that additional experimental details are necessary for full verification. In the revision, we will expand the experiments section to report per-task scores for all 19 datasets on LongBench and Needle-In-A-Haystack, include standard deviations from repeated runs where available (with a note on single-run results for compute-intensive settings), add error bars to figures, detail the re-implementation of baselines including hyperparameters and any modifications, and specify data-selection criteria and evaluation protocols. These changes will enable readers to directly assess the consistency of the performance claims. revision: partial
-
Referee: [Unified eviction strategy subsection] The unified eviction strategy's assertion that LaProx scores are globally comparable across heads and layers is not supported by any quantitative analysis (e.g., score-distribution statistics or ablation comparing global vs. per-head selection). This directly affects the claimed advantage over local methods.
Authors: We agree that quantitative evidence is needed to support the global comparability claim. In the revised version, we will add score-distribution statistics (e.g., mean, variance, and overlap metrics) across heads and layers to demonstrate that LaProx produces comparable scores. We will also include an ablation study contrasting the unified global selection with per-head local selection, reporting performance differences on key benchmarks. This will provide direct empirical support for the advantage of the model-wide eviction strategy. revision: yes
Circularity Check
No significant circularity; derivation introduces independent reformulation
full rationale
The paper reformulates KV cache eviction as an output-aware matrix-multiplication approximation and defines the LaProx metric from first principles by modeling attention-value interactions and inter-head dependencies. No equation reduces a claimed prediction or importance score to a fitted parameter or prior self-citation by construction; the new global selection strategy and experimental validation on LongBench/Needle-In-A-Haystack stand as independent content rather than tautological restatements of inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LaProx eviction strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Faster neural network training with approximate tensor operations
Menachem Adelman et al. “Faster neural network training with approximate tensor operations”. In:Advances in Neural Information Processing Systems34 (2021), pp. 27877–27889
work page 2021
-
[2]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie et al. “Gqa: Training generalized multi-query transformer models from multi- head checkpoints”. In:arXiv preprint arXiv:2305.13245(2023)
work page internal anchor Pith review arXiv 2023
-
[3]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai et al. “Longbench: A bilingual, multitask benchmark for long context understanding”. In:Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). 2024, pp. 3119–3137
work page 2024
-
[4]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. “Longformer: The long-document trans- former”. In:arXiv preprint arXiv:2004.05150(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[5]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai et al. “Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling”. In:arXiv preprint arXiv:2406.02069(2024)
work page internal anchor Pith review arXiv 2024
-
[6]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. “Flashattention-2: Faster attention with better parallelism and work partitioning”. In: arXiv preprint arXiv:2307.08691(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Pradeep Dasigi et al. “A dataset of information-seeking questions and answers anchored in research papers”. In:arXiv preprint arXiv:2105.03011(2021)
-
[8]
A simple and effective l\_2 norm-based strategy for kv cache compression
Alessio Devoto et al. “A Simple and Effective L_2 Norm-Based Strategy for KV Cache Compression”. In:arXiv preprint arXiv:2406.11430(2024)
-
[9]
Fast Monte Carlo algorithms for matrices I: Approximating matrix multiplication
Petros Drineas, Ravi Kannan, and Michael W Mahoney. “Fast Monte Carlo algorithms for matrices I: Approximating matrix multiplication”. In:SIAM Journal on Computing36.1 (2006), pp. 132–157
work page 2006
-
[10]
Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model
Alexander Richard Fabbri et al. “Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model”. In:Proceedings of the 57th annual meeting of the association for computational linguistics. 2019, pp. 1074–1084
work page 2019
-
[11]
Yuan Feng et al. “Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference”. In:arXiv preprint arXiv:2407.11550(2024)
-
[12]
Yuan Feng et al. “Identify critical kv cache in llm inference from an output perturbation perspective”. In:arXiv preprint arXiv:2502.03805(2025)
-
[13]
Yu Fu et al. “Not all heads matter: A head-level kv cache compression method with integrated retrieval and reasoning”. In:arXiv preprint arXiv:2410.19258(2024)
-
[14]
Samsum corpus: A human- annotated dialogue dataset for abstractive summarization
Bogdan Gliwa et al. “SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization”. In:arXiv preprint arXiv:1911.12237(2019)
-
[15]
Raghavv Goel et al. “CAOTE: KV Cache Selection for LLMs via Attention Output Error-Based Token Eviction”. In:arXiv preprint arXiv:2504.14051(2025)
-
[16]
Aaron Grattafiori et al. “The llama 3 herd of models”. In:arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Yifeng Gu et al. “AhaKV: Adaptive Holistic Attention-Driven KV Cache Eviction for Efficient Inference of Large Language Models”. In:arXiv preprint arXiv:2506.03762(2025)
-
[18]
Longcoder: A long-range pre-trained language model for code completion
Daya Guo et al. “Longcoder: A long-range pre-trained language model for code completion”. In:International Conference on Machine Learning. PMLR. 2023, pp. 12098–12107
work page 2023
-
[19]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,
Xanh Ho et al. “Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps”. In:arXiv preprint arXiv:2011.01060(2020)
-
[20]
Kvquant: Towards 10 million context length llm inference with kv cache quantization
Coleman Hooper et al. “Kvquant: Towards 10 million context length llm inference with kv cache quantization”. In:Advances in Neural Information Processing Systems37 (2024), pp. 1270–1303
work page 2024
-
[21]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh et al. “RULER: What’s the Real Context Size of Your Long-Context Language Models?” In:arXiv preprint arXiv:2404.06654(2024)
work page internal anchor Pith review arXiv 2024
-
[22]
Efficient attentions for long document summarization,
Luyang Huang et al. “Efficient attentions for long document summarization”. In:arXiv preprint arXiv:2104.02112(2021)
-
[23]
Albert Q. Jiang et al.Mistral 7B. 2023. arXiv: 2310.06825 [cs.CL].URL: https://arxiv. org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi et al. “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension”. In:arXiv preprint arXiv:1705.03551(2017). 10
work page internal anchor Pith review arXiv 2017
-
[25]
Evaluating open-domain question answering in the era of large language models
Ehsan Kamalloo et al. “Evaluating open-domain question answering in the era of large language models”. In:Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). 2023, pp. 5591–5606
work page 2023
-
[26]
2023.URL: https:// github.com/gkamradt/LLMTest_NeedleInAHaystack
Gregory Kamradt.Needle In A Haystack - pressure testing LLMs. 2023.URL: https:// github.com/gkamradt/LLMTest_NeedleInAHaystack
work page 2023
-
[27]
The narrativeqa reading comprehension challenge
Tomáš Koˇcisk`y et al. “The narrativeqa reading comprehension challenge”. In:Transactions of the Association for Computational Linguistics6 (2018), pp. 317–328
work page 2018
-
[28]
Wonbeom Lee et al. “{InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management”. In:18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 2024, pp. 155–172
work page 2024
-
[29]
Xin Li and Dan Roth. “Learning question classifiers”. In:COLING 2002: The 19th Interna- tional Conference on Computational Linguistics. 2002
work page 2002
-
[30]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li et al. “Snapkv: Llm knows what you are looking for before generation”. In: Advances in Neural Information Processing Systems37 (2024), pp. 22947–22970
work page 2024
-
[31]
RepoBench : Benchmarking repository-level code auto-completion systems
Tianyang Liu, Canwen Xu, and Julian McAuley. “Repobench: Benchmarking repository-level code auto-completion systems”. In:arXiv preprint arXiv:2306.03091(2023)
-
[32]
Zichang Liu et al. “Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time”. In:Advances in Neural Information Processing Systems 36 (2023), pp. 52342–52364
work page 2023
-
[33]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu et al. “Kivi: A tuning-free asymmetric 2bit quantization for kv cache”. In:arXiv preprint arXiv:2402.02750(2024)
work page internal anchor Pith review arXiv 2024
-
[34]
Ziran Qin et al. “Cake: Cascading and adaptive kv cache eviction with layer preferences”. In: arXiv preprint arXiv:2503.12491(2025)
-
[35]
Exploring the limits of transfer learning with a unified text-to-text trans- former
Colin Raffel et al. “Exploring the limits of transfer learning with a unified text-to-text trans- former”. In:Journal of machine learning research21.140 (2020), pp. 1–67
work page 2020
- [36]
-
[37]
Flexgen: High-throughput generative inference of large language mod- els with a single gpu
Ying Sheng et al. “Flexgen: High-throughput generative inference of large language mod- els with a single gpu”. In:International Conference on Machine Learning. PMLR. 2023, pp. 31094–31116
work page 2023
-
[38]
Razorattention: Efficient kv cache compression through retrieval heads
Hanlin Tang et al. “Razorattention: Efficient kv cache compression through retrieval heads”. In:arXiv preprint arXiv:2407.15891(2024)
-
[39]
arXiv preprint arXiv:2406.10774 , year=
Jiaming Tang et al. “Quest: Query-aware sparsity for efficient long-context llm inference”. In: arXiv preprint arXiv:2406.10774(2024)
-
[40]
Vicuna: An open-source chatbot impressing gpt-4 with 90% chatgpt quality
Vicuna Team. “Vicuna: An open-source chatbot impressing gpt-4 with 90% chatgpt quality”. In:Vicuna: An open-source chatbot impressing gpt-4 with90 (2023)
work page 2023
-
[41]
MuSiQue: Multihop Questions via Single-hop Question Composition
Harsh Trivedi et al. “MuSiQue: Multihop Questions via Single-hop Question Composition”. In:Transactions of the Association for Computational Linguistics10 (2022), pp. 539–554
work page 2022
-
[42]
Zhongwei Wan et al. “D2o: Dynamic discriminative operations for efficient long-context inference of large language models”. In:arXiv preprint arXiv:2406.13035(2024)
-
[43]
Spatten: Efficient sparse attention architecture with cascade token and head pruning
Hanrui Wang, Zhekai Zhang, and Song Han. “Spatten: Efficient sparse attention architecture with cascade token and head pruning”. In:2021 IEEE International Symposium on High- Performance Computer Architecture (HPCA). IEEE. 2021, pp. 97–110
work page 2021
-
[44]
Duoattention: Efficient long-context LLM inference with retrieval and streaming heads
Guangxuan Xiao et al. “Duoattention: Efficient long-context llm inference with retrieval and streaming heads”. In:arXiv preprint arXiv:2410.10819(2024)
-
[45]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao et al. “Efficient streaming language models with attention sinks, 2024”. In: URL https://arxiv. org/abs/2309.174531 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
An Yang et al. “Qwen3 technical report”. In:arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Pyramid- infer: Pyramid kv cache compression for high-throughput llm inference
Dongjie Yang et al. “Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference”. In:arXiv preprint arXiv:2405.12532(2024)
-
[48]
Zhilin Yang et al.HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answer- ing. 2018. arXiv:1809.09600 [cs.CL].URL:https://arxiv.org/abs/1809.09600
work page internal anchor Pith review arXiv 2018
-
[49]
Pqcache: Product quantization-based kvcache for long context llm infer- ence
Hailin Zhang et al. “Pqcache: Product quantization-based kvcache for long context llm infer- ence”. In:Proceedings of the ACM on Management of Data3.3 (2025), pp. 1–30. 11
work page 2025
-
[50]
Benchmarking large language models for news summarization
Tianyi Zhang et al. “Benchmarking large language models for news summarization”. In: Transactions of the Association for Computational Linguistics12 (2024), pp. 39–57
work page 2024
-
[51]
∞Bench: Extending Long Context Evaluation Beyond 100K Tokens
Xinrong Zhang et al. ∞Bench: Extending Long Context Evaluation Beyond 100K Tokens
- [52]
-
[53]
H2o: Heavy-hitter oracle for efficient generative inference of large lan- guage models
Zhenyu Zhang et al. “H2o: Heavy-hitter oracle for efficient generative inference of large lan- guage models”. In:Advances in Neural Information Processing Systems36 (2023), pp. 34661– 34710
work page 2023
-
[54]
Alisa: Accelerating large language model inference via sparsity-aware kv caching
Youpeng Zhao, Di Wu, and Jun Wang. “Alisa: Accelerating large language model inference via sparsity-aware kv caching”. In:2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE. 2024, pp. 1005–1017
work page 2024
-
[55]
QMSum: A new benchmark for query-based multi-domain meeting summarization
Ming Zhong et al. “QMSum: A new benchmark for query-based multi-domain meeting summarization”. In:Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021, pp. 5905– 5921. 12 A Implementation details Methods with uniform allocation assign equal cache capacity to ea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.