Recognition: 2 theorem links
· Lean TheoremSR²-LoRA: Self-Rectifying Inter-layer Relations in Low-Rank Adaptation for Class-Incremental Learning
Pith reviewed 2026-05-11 02:02 UTC · model grok-4.3
The pith
Inter-layer relation drift shrinks old-task margins, which singular-value alignment in SR²-LoRA reverses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
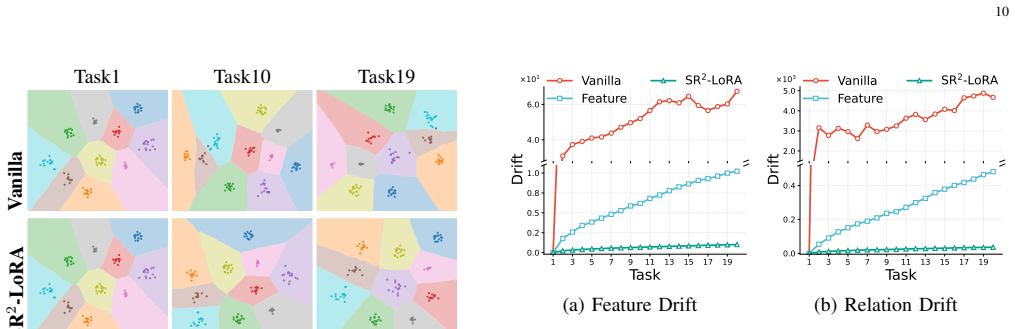
SR²-LoRA addresses catastrophic forgetting by constraining inter-layer relation drift through the alignment of singular values in relation matrices derived from previous and current models evaluated on current-task samples.
What carries the argument
Alignment of singular values from relation matrices induced on current-task samples by prior and adapted models.
If this is right
- Old-task classification margins are preserved as drift is limited.
- Overall accuracy improves across the sequence of tasks.
- Advantages grow with increasing task count.
- Compatible with existing LoRA-based fine-tuning pipelines.
Where Pith is reading between the lines
- Similar relational constraints might help in other continual learning scenarios beyond class-incremental.
- Focus on singular values rather than full matrices could reduce computational overhead in monitoring drift.
- Relation-based regularization may complement other forgetting-mitigation techniques like replay or regularization.
Load-bearing premise
The inter-layer relations estimated from new-task samples alone suffice to maintain performance on all prior tasks.
What would settle it
Observe whether aligning the singular values actually increases the classification margins for previously learned classes when tested on held-out old data.
Figures






read the original abstract
Pre-trained models with parameter-efficient fine-tuning (PEFT) have demonstrated promising potential for class-incremental learning (CIL), yet catastrophic forgetting still persists when adapting models to new tasks. In this paper, we present a novel perspective on catastrophic forgetting through the analysis of inter-layer relation drift, i.e., the progressive disruption of relationships among layer-wise representations during the learning of new tasks. We theoretically show that the increase of such drift reduces the classification margins of previously learned tasks, thereby degrading overall model performance. To address this issue, we propose \underline{S}elf-\underline{R}ectifying inter-layer \underline{R}elation Low-Rank Adaptation~(SR$^2$-LoRA), a simple yet effective method that mitigates catastrophic forgetting by constraining inter-layer relation drift. Specifically, SR$^2$-LoRA constructs the relation matrices induced by the previous and current models on current-task samples, and aligns the corresponding singular values. We further theoretically show that this alignment exhibits greater robustness to estimation perturbations than direct entry-wise alignment. Extensive experiments on standard CIL benchmarks demonstrate that SR$^2$-LoRA effectively mitigates catastrophic forgetting, with its advantages becoming more pronounced as the number of tasks increases. Code is available in the \href{https://github.com/FqWan24/SR-2-LoRA}{repository}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SR²-LoRA, a low-rank adaptation method for class-incremental learning that mitigates catastrophic forgetting by self-rectifying inter-layer relation drift. It theoretically demonstrates that such drift reduces classification margins on prior tasks and proposes aligning singular values of relation matrices built from previous and current models using only current-task samples. The alignment is shown to be more robust to perturbations than entry-wise methods, and experiments indicate superior performance on CIL benchmarks as task count grows.
Significance. Should the theoretical derivations hold and the empirical gains prove consistent, this contributes a fresh perspective on forgetting mechanisms in PEFT-based CIL and a practical, scalable solution. The open-source code enhances its potential impact. The work's value is contingent on substantiating that current-sample relation matrices serve as valid proxies for drifts impacting old-task performance.
major comments (3)
- [§2 (Theoretical Analysis)] The assertion that inter-layer relation drift reduces classification margins of previously learned tasks is central to motivating the method. However, the provided abstract states the result without derivations or quantitative details on effect sizes; the full manuscript must include explicit steps linking drift quantification to margin reduction to allow verification of the claim.
- [§3.2 (SR²-LoRA Construction)] Relation matrices for both previous and current models are constructed solely from current-task samples. This assumption is load-bearing for the central claim: if representation geometry differs systematically due to class-specific shifts, the singular-value alignment may constrain an irrelevant drift rather than the one analyzed in the margin proof. The manuscript should either derive that the proxy holds or include ablations showing correlation between the estimated drift and actual forgetting on old tasks.
- [Theoretical Robustness Result] The result that singular-value alignment exhibits greater robustness to estimation perturbations than direct entry-wise alignment addresses noise but does not resolve whether the estimated matrix is the correct target for preserving prior performance. This distinction should be clarified in the discussion of the robustness theorem.
minor comments (2)
- [Abstract] The abstract claims 'extensive experiments' demonstrate effectiveness, but lacks summary statistics such as average accuracy improvements or specific benchmark results to support the claim that advantages become more pronounced with more tasks.
- [Notation and Definitions] Ensure consistent definition of relation matrices and singular values across sections to avoid ambiguity in the alignment objective.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment point by point below, outlining the revisions we will make to improve clarity and substantiation of the key claims.
read point-by-point responses
-
Referee: [§2 (Theoretical Analysis)] The assertion that inter-layer relation drift reduces classification margins of previously learned tasks is central to motivating the method. However, the provided abstract states the result without derivations or quantitative details on effect sizes; the full manuscript must include explicit steps linking drift quantification to margin reduction to allow verification of the claim.
Authors: We agree that explicit step-by-step derivations are essential for verifiability. While Section 2 of the full manuscript presents the theoretical analysis linking inter-layer relation drift (quantified via singular-value differences in relation matrices) to reduced classification margins on prior tasks, we will expand this section with additional intermediate steps, formal proofs, and quantitative bounds on margin reduction to make the connection fully transparent and self-contained. revision: yes
-
Referee: [§3.2 (SR²-LoRA Construction)] Relation matrices for both previous and current models are constructed solely from current-task samples. This assumption is load-bearing for the central claim: if representation geometry differs systematically due to class-specific shifts, the singular-value alignment may constrain an irrelevant drift rather than the one analyzed in the margin proof. The manuscript should either derive that the proxy holds or include ablations showing correlation between the estimated drift and actual forgetting on old tasks.
Authors: We acknowledge the importance of validating the proxy assumption. The manuscript motivates the use of current-task samples by noting that they induce the relevant inter-layer relations under the incremental update; however, to strengthen this, we will add new ablation studies in the experiments section that measure the correlation between the estimated drift (from current samples) and observed forgetting on old tasks across multiple benchmarks. We will also include a brief discussion clarifying the conditions under which the proxy is expected to hold. revision: yes
-
Referee: [Theoretical Robustness Result] The result that singular-value alignment exhibits greater robustness to estimation perturbations than direct entry-wise alignment addresses noise but does not resolve whether the estimated matrix is the correct target for preserving prior performance. This distinction should be clarified in the discussion of the robustness theorem.
Authors: We will revise the discussion following the robustness theorem to explicitly distinguish the two aspects: the theorem establishes greater robustness to perturbations in the estimated matrices, while the choice of target (current-sample proxy) is justified separately via the margin analysis and the new ablations mentioned above. This clarification will be added to avoid any ambiguity regarding the scope of the robustness result. revision: yes
Circularity Check
No circularity: theoretical claims and alignment method are independently derived
full rationale
The paper derives the effect of inter-layer relation drift on classification margins as a standalone theoretical result, then defines SR²-LoRA by explicitly constructing relation matrices from current-task samples of both models and aligning their singular values. The separate robustness theorem compares singular-value alignment to entry-wise alignment under estimation noise. Neither step reduces to the other by construction, nor does any load-bearing premise collapse to a self-citation or fitted input renamed as prediction. The construction uses only observable quantities on the current distribution and does not presuppose the margin result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Increase in inter-layer relation drift reduces classification margins of previously learned tasks
- ad hoc to paper Singular-value alignment of relation matrices constrains drift more robustly than entry-wise alignment
Reference graph
Works this paper leans on
-
[1]
On the stability- plasticity dilemma in continual meta-learning: Theory and algorithm,
Q. CHEN, C. Shui, L. Han, and M. Marchand, “On the stability- plasticity dilemma in continual meta-learning: Theory and algorithm,” inNeural Information Processing Systems (NeruIPS), 2023
work page 2023
-
[2]
A continual learning survey: Defying forgetting in classification tasks,
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A continual learning survey: Defying forgetting in classification tasks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 3366–3385, 2021
work page 2021
-
[3]
Mastering the game of go with deep neural networks and tree search,
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V . Panneershelvam, M. Lanc- tot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. P. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of go with deep neural networks and tree search,” Nature,...
work page 2016
-
[4]
Highly accurate protein structure prediction with alphafold,
J. Jumper, R. Evans, A. Pritzel, T. Green, and D. Hassabis, “Highly accurate protein structure prediction with alphafold,”Nature, pp. 1–11, 2021
work page 2021
-
[5]
N. K. Kasabov, D. Zhang, and P. S. Fang, “Incremental learning in autonomous systems: evolving connectionist systems for on-line image and speech recognition,”IEEE Workshop on Advanced Robotics and its Social Impacts., pp. 120–125, 2005
work page 2005
-
[6]
Continual learning for real-world autonomous systems: Algorithms, challenges and frameworks,
K. Shaheen, M. A. Hanif, O. Hasan, and M. Shafique, “Continual learning for real-world autonomous systems: Algorithms, challenges and frameworks,”Journal Of Intelligent and Robotic Systems., p. 9, 2022
work page 2022
-
[7]
Incremental learning of abnormalities in autonomous systems,
H. Zaal, H. Iqbal, D. Campo, L. Marcenaro, and C. S. Regazzoni, “Incremental learning of abnormalities in autonomous systems,” in Conference on Advanced Video and Signal (CAVS), 2019
work page 2019
-
[8]
Catastrophic forgetting in connectionist networks,
R. M. French, “Catastrophic forgetting in connectionist networks,” Trends in cognitive sciences, pp. 128–135, 1999
work page 1999
-
[9]
Modeling time perception in rats: Evidence for catastrophic interference in animal learning,
R. M. French and A. Ferrara, “Modeling time perception in rats: Evidence for catastrophic interference in animal learning,” inCognitive Science Society (CSS), 2020
work page 2020
-
[10]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,”Pro- ceedings of the national academy of sciences, pp. 3521–3526, 2017
work page 2017
-
[11]
Maintaining discrimination and fairness in class incremental learning,
B. Zhao, X. Xiao, G. Gan, B. Zhang, and S. Xia, “Maintaining discrimination and fairness in class incremental learning,” inComputer Vision and Pattern Recognition (CVPR), 2020
work page 2020
-
[12]
A model or 603 exemplars: Towards memory-efficient class-incremental learning,
D. Zhou, Q. Wang, H. Ye, and D. Zhan, “A model or 603 exemplars: Towards memory-efficient class-incremental learning,” inInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[13]
Pycil: a python toolbox for class-incremental learning,
D.-W. Zhou, F.-Y . Wang, H.-J. Ye, and D.-C. Zhan, “Pycil: a python toolbox for class-incremental learning,”SCIENCE CHINA Information Sciences, 2023
work page 2023
-
[14]
Lora-fa: Memory- efficient low-rank adaptation for large language models fine-tuning,
L. Zhang, L. Zhang, S. Shi, X. Chu, and B. Li, “Lora-fa: Memory- efficient low-rank adaptation for large language models fine-tuning,” CoRR, 2023
work page 2023
-
[15]
Visual prompt tuning in null space for continual learning,
Y . Lu, S. Zhang, D. Cheng, Y . Xing, N. Wang, P. Wang, and Y . Zhang, “Visual prompt tuning in null space for continual learning,” inNeural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[16]
Pre-trained models for natural language processing: A survey,
X. Qiu, T. Sun, Y . Xu, Y . Shao, N. Dai, and X. Huang, “Pre-trained models for natural language processing: A survey,”Science China technological sciences, pp. 1872–1897, 2020
work page 2020
-
[17]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning (ICML), 2021
work page 2021
-
[18]
How to train your vit? data, augmentation, and regularization in vision transformers,
A. Steiner, A. Kolesnikov, X. Zhai, R. Wightman, J. Uszkoreit, and L. Beyer, “How to train your vit? data, augmentation, and regularization in vision transformers,”CoRR, 2021
work page 2021
-
[19]
Inflora: Interference-free low-rank adaptation for continual learning,
Y .-S. Liang and W.-J. Li, “Inflora: Interference-free low-rank adaptation for continual learning,” inComputer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[20]
Dualprompt: Complementary prompting for rehearsal-free continual learning,
Z. Wang, Z. Zhang, S. Ebrahimi, R. Sun, H. Zhang, C.-Y . Lee, X. Ren, G. Su, V . Perot, J. Dyet al., “Dualprompt: Complementary prompting for rehearsal-free continual learning,” inEuropean Conference Computer Vision (ECCV), 2022
work page 2022
-
[21]
Expandable subspace ensemble for pre-trained model-based class-incremental learning,
D.-W. Zhou, H.-L. Sun, H.-J. Ye, and D.-C. Zhan, “Expandable subspace ensemble for pre-trained model-based class-incremental learning,” in Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[22]
Learning to prompt for continual learning,
Z. Wang, Z. Zhang, C.-Y . Lee, H. Zhang, R. Sun, X. Ren, G. Su, V . Perot, J. Dy, and T. Pfister, “Learning to prompt for continual learning,” in Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[23]
Exemplar-free continual representation learning via learnable drift compensation,
A. Gomez-Villa, D. Goswami, K. Wang, A. D. Bagdanov, B. Twar- dowski, and J. van de Weijer, “Exemplar-free continual representation learning via learnable drift compensation,” inEuropean Computer Vision Conference (ECCV), 2024
work page 2024
-
[24]
H. Wang, S. Ren, W. Huang, M. Zhang, X. Deng, Y . Bao, and L. Nie, “Understanding the forgetting of (replay-based) continual learning via feature learning: Angle matters,” inInternational Conference on Ma- chine Learning (ICML), 2025
work page 2025
-
[25]
Enhancing few-shot class-incremental learning via training-free bi-level modality calibration,
Y . Chen, T. Ding, L. Wang, J. Huo, Y . Gao, and W. Li, “Enhancing few-shot class-incremental learning via training-free bi-level modality calibration,” inComputer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[26]
R. He, D. Fang, Y . Xu, Y . Cui, M. Li, C. Chen, Z. Zeng, and H. Zhuang, “Semantic shift estimation via dual-projection and classifier recon- struction for exemplar-free class-incremental learning,” inInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[27]
Training consistent mixture-of-experts-based prompt generator for con- tinual learning,
Y . Lu, S. Zhang, D. Cheng, G. Liang, Y . Xing, N. Wang, and Y . Zhang, “Training consistent mixture-of-experts-based prompt generator for con- tinual learning,” inAssociation for the Advancement of Artificial Intel- ligence (AAAI), 2025
work page 2025
-
[28]
W. Shi and M. Ye, “Prototype reminiscence and augmented asymmetric knowledge aggregation for non-exemplar class-incremental learning,” in International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[29]
Bilora: Almost-orthogonal parameter spaces for continual learning,
H. Zhu, Y . Zhang, J. Dong, and P. Koniusz, “Bilora: Almost-orthogonal parameter spaces for continual learning,” inComputer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[30]
Coda-prompt: Contin- ual decomposed attention-based prompting for rehearsal-free continual learning,
J. S. Smith, L. Karlinsky, V . Gutta, P. Cascante-Bonilla, D. Kim, A. Arbelle, R. Panda, R. Feris, and Z. Kira, “Coda-prompt: Contin- ual decomposed attention-based prompting for rehearsal-free continual learning,” inComputer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[31]
Deep anomaly detec- tion with outlier exposure,
D. Hendrycks, M. Mazeika, and T. Dietterich, “Deep anomaly detec- tion with outlier exposure,” inInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[32]
The many faces of robustness: A critical analysis of out-of-distribution generalization,
D. Hendrycks, S. Basart, N. Mu, S. Kadavath, F. Wang, E. Dorundo, R. Desai, T. Zhu, S. Parajuli, M. Guoet al., “The many faces of robustness: A critical analysis of out-of-distribution generalization,” in International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[33]
Adapter merging with centroid prototype mapping for scalable class-incremental learning,
T. Fukuda, H. Kera, and K. Kawamoto, “Adapter merging with centroid prototype mapping for scalable class-incremental learning,” inComputer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[34]
Mixture of noise for pre-trained model-based class-incremental learning,
K. Jiang, Z. Shi, D. Zhang, H. Zhang, and X. Li, “Mixture of noise for pre-trained model-based class-incremental learning,”Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[35]
Preserving cross- modal consistency for clip-based class-incremental learning,
H. Chen, H. Xu, M. Goldblum, D. Dong, and Z. Wu, “Preserving cross- modal consistency for clip-based class-incremental learning,”CoRR, 2025
work page 2025
-
[36]
Compensating distribution drifts in class-incremental learning of pre- trained vision transformers,
X. Rao, S. Xu, Z. Li, B. Zhao, D. Liu, M. Ha, and C. Alippi, “Compensating distribution drifts in class-incremental learning of pre- trained vision transformers,”CoRR, 2025
work page 2025
-
[37]
Navigating semantic drift in task-agnostic class-incremental learning,
F. Wu, L. Cheng, S. Tang, X. Zhu, C. Fang, D. Zhang, and M. Wang, “Navigating semantic drift in task-agnostic class-incremental learning,” inInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[38]
H. Qiu, M. Zhang, Z. Qiao, W. Guan, M. Zhang, and L. Nie, “Splitlora: Balancing stability and plasticity in continual learning through gradient space splitting,”International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[39]
Y . Wang, D.-W. Zhou, and H.-J. Ye, “Integrating task-specific and uni- versal adapters for pre-trained model-based class-incremental learning,” inInternational Conference on Computer Vision (ICCV), 2025
work page 2025
-
[40]
Tracing representation progression: Analyzing and enhancing layer-wise similarity,
J. Jiang, J. Zhou, and Z. Zhu, “Tracing representation progression: Analyzing and enhancing layer-wise similarity,”CORR, 2024
work page 2024
-
[41]
Cr-net: Scaling parameter-efficient training with cross-layer low-rank structure,
B. Kong, J. Liang, Y . Liu, R. Deng, and K. Yuan, “Cr-net: Scaling parameter-efficient training with cross-layer low-rank structure,”CORR, 2025
work page 2025
-
[42]
RS-GCL: randomized svd- based graph-enhanced contrastive learning for recommendation,
J. Sun, X. Peng, G. Li, and F. Chen, “RS-GCL: randomized svd- based graph-enhanced contrastive learning for recommendation,”Expert Systems With Applications, 2026
work page 2026
-
[43]
Mos: Model surgery for pre-trained model-based class-incremental learning,
H.-L. Sun, D.-W. Zhou, H. Zhao, L. Gan, D.-C. Zhan, and H.-J. Ye, “Mos: Model surgery for pre-trained model-based class-incremental learning,” inAssociation for the Advancement of Artificial Intelligence (AAAI), 2025
work page 2025
-
[44]
Parameter-efficient fine-tuning for large models: A comprehensive survey,
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang, “Parameter-efficient fine-tuning for large models: A comprehensive survey,”CoRR, 2024
work page 2024
-
[45]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[46]
Cl-lora: Continual low-rank adaptation for rehearsal-free class-incremental learning,
J. He, Z. Duan, and F. Zhu, “Cl-lora: Continual low-rank adaptation for rehearsal-free class-incremental learning,” inComputer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[47]
Semantically- shifted incremental adapter-tuning is a continual vitransformer,
Y . Tan, Q. Zhou, X. Xiang, K. Wang, Y . Wu, and Y . Li, “Semantically- shifted incremental adapter-tuning is a continual vitransformer,” in Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[48]
Lora subtraction for drift-resistant space in exemplar-free continual learning,
X. Liu and X. Chang, “Lora subtraction for drift-resistant space in exemplar-free continual learning,” inComputer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[49]
Maintaining fairness in logit-based knowledge distillation for class-incremental learning,
Z. Gao, S. Han, X. Zhang, K. Xu, D. Zhou, X. Mao, Y . Dou, and H. Wang, “Maintaining fairness in logit-based knowledge distillation for class-incremental learning,” inAssociation for the Advancement of Artificial Intelligence (AAAI), 2025
work page 2025
-
[50]
Class-incremental learning by knowledge distillation with adaptive feature consolidation,
M. Kang, J. Park, and B. Han, “Class-incremental learning by knowledge distillation with adaptive feature consolidation,” inComputer Vision and Pattern Recognition (CVPR), 2022. 12
work page 2022
-
[51]
C. Bucila, R. Caruana, and A. Niculescu-Mizil, “Model compression,” inKnowledge Discovery and Data Mining (KDD), T. Eliassi-Rad, L. H. Ungar, M. Craven, and D. Gunopulos, Eds., 2006
work page 2006
-
[52]
Distilling the knowledge in a neural network,
G. E. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”CoRR, 2015
work page 2015
-
[53]
Logit standardization in knowledge distillation,
S. Sun, W. Ren, J. Li, R. Wang, and X. Cao, “Logit standardization in knowledge distillation,” inComputer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[54]
Y . Li, H. Xu, Y . Yang, C. Hu, C. Sun, H. Song, and L. Yang, “An incremental learning method with feature-attention distillation and logit adjustment for rotating machinery fault diagnosis,”IEEE Transactions on Instrumentation and Measurement, pp. 1–13, 2025
work page 2025
-
[55]
Class-incremental learn- ing using diffusion model for distillation and replay,
Q. Jodelet, X. Liu, Y . J. Phua, and T. Murata, “Class-incremental learn- ing using diffusion model for distillation and replay,” inInternational Conference on Computer Vision (ICCV), 2023
work page 2023
-
[56]
H. Khan, N. C. Bouaynaya, and G. Rasool, “Brain-inspired continual learning: Robust feature distillation and re-consolidation for class incre- mental learning,”IEEE Access, 2024
work page 2024
-
[57]
Few- shot class-incremental learning via relation knowledge distillation,
S. Dong, X. Hong, X. Tao, X. Chang, X. Wei, and Y . Gong, “Few- shot class-incremental learning via relation knowledge distillation,” in Association for the Advancement of Artificial Intelligence (AAAI), 2021
work page 2021
-
[58]
Task relation distillation and prototypical pseudo label for incremental named entity recognition,
D. Zhang, H. Li, W. Cong, R. Xu, J. Dong, and X. Chen, “Task relation distillation and prototypical pseudo label for incremental named entity recognition,” inInformation and Knowledge Management (IKM), 2023
work page 2023
-
[59]
Multi-view correlation distillation for incremental object detection,
D. Yang, Y . Zhou, A. Zhang, X. Sun, D. Wu, W. Wang, and Q. Ye, “Multi-view correlation distillation for incremental object detection,” Pattern Recognition, 2022
work page 2022
-
[60]
Correlation-based knowl- edge distillation in exemplar-free class-incremental learning,
Z. Gao, B. Liu, K. Xu, X. Mao, and H. Wang, “Correlation-based knowl- edge distillation in exemplar-free class-incremental learning,”IEEE Open Journal of the Computer Society, 2025
work page 2025
-
[61]
R-dfcil: Relation-guided representation learning for data-free class incremental learning,
Q. Gao, C. Zhao, B. Ghanem, and J. Zhang, “R-dfcil: Relation-guided representation learning for data-free class incremental learning,” in European Conference on Computer Vision (ECCV), 2022
work page 2022
-
[62]
Be your own teacher: Improve the performance of convolutional neural networks via self distillation,
L. Zhang, J. Song, A. Gao, J. Chen, C. Bao, and K. Ma, “Be your own teacher: Improve the performance of convolutional neural networks via self distillation,” inInternational Conference on Computer Vision (ICCV), 2019
work page 2019
-
[63]
Snapshot distillation: Teacher- student optimization in one generation,
C. Yang, L. Xie, C. Su, and A. L. Yuille, “Snapshot distillation: Teacher- student optimization in one generation,” inComputer Vision and Pattern Recognition (CVPR), 2019
work page 2019
-
[64]
Mitigating neu- ral network overconfidence with logit normalization,
H. Wei, R. Xie, H. Cheng, L. Feng, B. An, and Y . Li, “Mitigating neu- ral network overconfidence with logit normalization,” inInternational Conference on Machine Learning (ICML), 2022
work page 2022
-
[65]
Slca: Slow learner with classifier alignment for continual learning on a pre-trained model,
G. Zhang, L. Wang, G. Kang, L. Chen, and Y . Wei, “Slca: Slow learner with classifier alignment for continual learning on a pre-trained model,” inInternational Conference on Computer Vision (ICCV), 2023
work page 2023
-
[66]
Theory on mixture-of-experts in continual learning,
H. Li, S. Lin, L. Duan, Y . Liang, and N. B. Shroff, “Theory on mixture-of-experts in continual learning,” inInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[67]
Theory on forgetting and generalization of continual learning,
S. Lin, P. Ju, Y . Liang, and N. B. Shroff, “Theory on forgetting and generalization of continual learning,” inInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[68]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,”Handbook of Systemic Autoimmune Diseases, 2009
work page 2009
-
[69]
The caltech-ucsd birds-200-2011 dataset,
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,”IEEE Dataport, 2011
work page 2011
-
[70]
D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song, “Natural adversarial examples,” inComputer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[71]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”CoRR, 2020
work page 2020
-
[72]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International Journal of Computer Vision, pp. 211–252, 2015
work page 2015
-
[73]
Laurens, V . D. Maaten, and G. Hinton, “Visualizing data using t-sne,” Journal of Machine Learning Research, pp. 2579–2605, 2008. Fengqiang Wanis currently working towards the Ph.D. degree at the School of Computer Science and Engineering, Nanjing University of Science and Technology. His research interests mainly lie in deep learning and data mining. He ...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.