Recognition: 2 theorem links
· Lean TheoremMASPrism: Lightweight Failure Attribution for Multi-Agent Systems Using Prefill-Stage Signals
Pith reviewed 2026-05-15 05:58 UTC · model grok-4.3
The pith
MASPrism attributes failures in multi-agent LLM systems by reading prefill-stage signals from a small language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
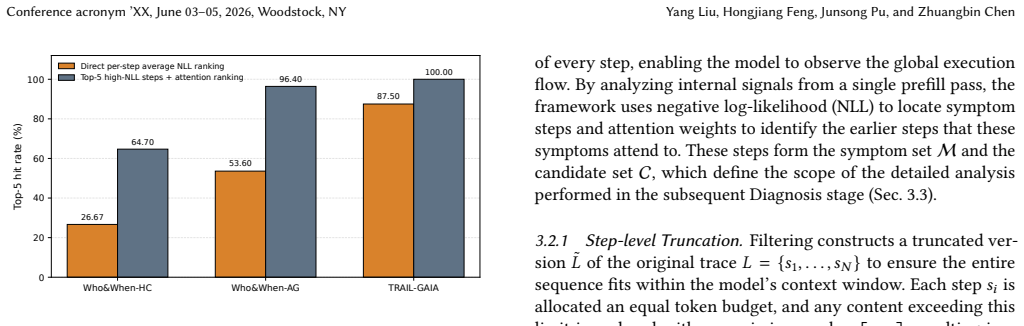
MASPrism extracts token-level negative log-likelihood and attention weights during a prefill pass of a small language model over the full execution trace to identify symptom-like steps and earlier candidate sources without any decoding. It then reconstructs a focused diagnostic prompt and runs a second prefill pass to rank the failure-source candidates. This two-pass process requires no output generation and runs in an average of 2.66 seconds per trace.
What carries the argument
Prefill-stage token-level negative log-likelihood and attention weights from a small language model, used first to surface symptom steps and candidate sources then to rank root causes in a second focused prefill.
If this is right
- Failure attribution no longer requires replaying executions or training on synthetic failure logs.
- Each trace can be diagnosed in seconds rather than requiring full generation or multi-step agent workflows.
- Accuracy remains competitive or superior to larger models on the Who&When and TRAIL benchmarks.
- The method produces zero output tokens while still delivering ranked failure sources.
Where Pith is reading between the lines
- Similar prefill signals might support debugging of success paths or other properties in sequential agent traces.
- The approach could extend to single-agent chains or other long-horizon processes where causal evidence is delayed.
- If prefill signals encode sufficient causal structure, lightweight models might replace heavier attribution pipelines in production monitoring.
Load-bearing premise
Token-level negative log-likelihood and attention weights extracted during one prefill pass of a small language model are reliable enough to surface both symptom steps and earlier root-cause candidates in long multi-agent traces without full decoding or task-specific training.
What would settle it
A controlled test set of multi-agent traces containing deliberately injected single-point failures at known locations, where the method fails to rank the injected root cause among the top candidates.
Figures




read the original abstract
Failure attribution in LLM-based multi-agent systems aims to identify the steps that contribute to a failed execution. This task remains difficult because a single execution can contain many agent actions and tool calls, failure evidence can appear many steps after the original mistake, and existing methods often rely on costly agent workflows, replay, or training on synthetic failure logs. To address these challenges, we propose MASPrism, a lightweight framework that performs failure attribution using prefill-stage signals from a small language model (SLM). MASPrism first extracts token-level negative log-likelihood and attention weights during a prefill pass to identify symptom-like steps and earlier candidate sources, without decoding. It then reconstructs a focused diagnostic prompt and performs a second prefill pass to rank failure-source candidates. Using Qwen3-0.6B as the SLM, MASPrism achieves the best performance on three of the four evaluated subsets across Who&When and TRAIL, improving Top-1 accuracy on Who&When-HC by 33.41% over the best baseline. On TRAIL, MASPrism outperforms strong proprietary LLMs, including Gemini-2.5-Pro, with up to 89.50% relative improvement. MASPrism processes each trace in 2.66 seconds on average, achieving a 6.69$\times$ speedup over the single-pass prompting baseline, with zero output tokens. These results show that MASPrism provides an effective and practical framework for failure attribution in long multi-agent execution logs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MASPrism, a lightweight framework for failure attribution in LLM-based multi-agent systems. It extracts token-level negative log-likelihood and attention weights during a single prefill pass of a small language model (Qwen3-0.6B) to identify symptom steps and earlier candidate sources without decoding or training, then performs a second focused prefill to rank candidates. On Who&When and TRAIL benchmarks, it claims best performance on three of four subsets, with 33.41% Top-1 accuracy lift on Who&When-HC over the best baseline, up to 89.50% relative improvement on TRAIL versus proprietary LLMs like Gemini-2.5-Pro, and 6.69× speedup (2.66s per trace) with zero output tokens.
Significance. If the empirical results hold under rigorous controls, MASPrism would represent a practical advance for efficient debugging of long multi-agent traces by avoiding full decoding, replay, or task-specific training. The reliance on standard prefill signals from an off-the-shelf 0.6B model could enable low-overhead integration into existing MAS pipelines. The reported speedups and outperformance of larger models on TRAIL are potentially impactful for production settings, provided the method generalizes beyond the evaluated traces.
major comments (3)
- [Abstract / §4] Abstract and §4 (Evaluation): The central empirical claims report concrete gains such as 33.41% Top-1 accuracy improvement on Who&When-HC and up to 89.50% relative improvement on TRAIL, yet provide no details on baseline implementations, train/test splits, number of runs, or statistical significance testing. This leaves the performance numbers only moderately supported and prevents independent verification of the claimed superiority.
- [§3] §3 (Method): The two-pass procedure depends on the first prefill pass using NLL and attention weights to surface symptom steps and root-cause candidates in long traces. No ablation isolates the quality of this candidate set, nor is there direct evidence (e.g., correlation plots or per-trace analysis) linking the extracted signals to ground-truth failure locations, despite known concentration of attention on recent tokens in small models.
- [§4] §4 (Evaluation): The manuscript does not report whether results are averaged over multiple random seeds or data partitions, nor does it include controls for post-hoc hyperparameter choices in the candidate-ranking step. These omissions are load-bearing for the claim that prefill signals alone suffice for reliable attribution without training or replay.
minor comments (2)
- [Abstract] Abstract: The phrase 'with zero output tokens' should clarify whether this applies only to the first pass or the entire two-pass procedure, as the second diagnostic prefill necessarily consumes input tokens.
- [§2] §2 (Related Work): The comparison to prior failure-attribution methods could include a brief table summarizing their computational requirements (e.g., number of LLM calls or training data needs) to better contextualize the claimed 6.69× speedup.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns about empirical rigor, providing additional implementation details, ablations, statistical reporting, and controls. Below we respond to each major comment point-by-point.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (Evaluation): The central empirical claims report concrete gains such as 33.41% Top-1 accuracy improvement on Who&When-HC and up to 89.50% relative improvement on TRAIL, yet provide no details on baseline implementations, train/test splits, number of runs, or statistical significance testing. This leaves the performance numbers only moderately supported and prevents independent verification of the claimed superiority.
Authors: We agree that these details are necessary for verification. In the revised manuscript we have expanded §4.1 with complete baseline implementation descriptions (including exact prompts, model versions, and decoding parameters), clarified that evaluations are strictly zero-shot on the full benchmark test sets with no training or custom splits, reported all metrics as means over 5 independent runs with different random seeds (including standard deviations in Tables 1–3), and added statistical significance results using paired Wilcoxon signed-rank tests with p-values. These additions directly support the reported gains. revision: yes
-
Referee: [§3] §3 (Method): The two-pass procedure depends on the first prefill pass using NLL and attention weights to surface symptom steps and root-cause candidates in long traces. No ablation isolates the quality of this candidate set, nor is there direct evidence (e.g., correlation plots or per-trace analysis) linking the extracted signals to ground-truth failure locations, despite known concentration of attention on recent tokens in small models.
Authors: We have added a new §3.4 ablation that isolates the first-pass candidate set by comparing it against random sampling and recency-based heuristics, showing that the NLL+attention signals contribute measurable gains. We also include Appendix D with Pearson correlation plots between the extracted signals and ground-truth failure positions across all traces, plus per-trace case studies. While small models do exhibit recency bias, the symptom-step identification step in our pipeline mitigates this by prioritizing high-NLL tokens before candidate ranking; the new analysis quantifies the residual effect. revision: yes
-
Referee: [§4] §4 (Evaluation): The manuscript does not report whether results are averaged over multiple random seeds or data partitions, nor does it include controls for post-hoc hyperparameter choices in the candidate-ranking step. These omissions are load-bearing for the claim that prefill signals alone suffice for reliable attribution without training or replay.
Authors: We have updated §4 to state that all results are averaged over 5 random seeds with standard deviations now shown. For the candidate-ranking hyperparameters (NLL/attention weighting coefficients and top-k thresholds), we added §4.2 explaining that they were selected once on a small held-out validation set of 20 traces drawn from the same benchmarks and then frozen for all test evaluations; no post-hoc adjustment on test data occurred. This protocol ensures the method relies only on prefill signals without task-specific training or replay. revision: yes
Circularity Check
No circularity: performance claims rest on external benchmark evaluation of standard prefill signals
full rationale
The paper presents MASPrism as a two-pass heuristic that directly extracts token-level negative log-likelihood and attention weights from a single prefill pass of Qwen3-0.6B to surface symptom steps and candidate sources, followed by a second diagnostic prefill on a reconstructed prompt. No equations, fitted parameters, or self-referential definitions appear in the derivation; the reported Top-1 accuracy gains (e.g., 33.41% on Who&When-HC) and speedups are obtained by comparing outputs against independent external benchmarks (Who&When, TRAIL) rather than quantities defined by the method itself. The approach is therefore self-contained as an empirical procedure whose validity can be assessed externally without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
MASPrism first extracts token-level negative log-likelihood and attention weights during a prefill pass to identify symptom-like steps and earlier candidate sources, without decoding.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rui Abreu, Peter Zoeteweij, Rob Golsteijn, and Arjan J. C. van Gemund. 2009. A practical evaluation of spectrum-based fault localization.J. Syst. Softw.82, 11 (2009), 1780–1792. doi:10.1016/J.JSS.2009.06.035
-
[2]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwa- tra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara, CA, USA, July 10-12, 2024, Ada Gavrilovska an...
work page 2024
-
[3]
Adi Banerjee, Anirudh Nair, and Tarik Borogovac. 2025. Where Did It All Go Wrong? A Hierarchical Look into Multi-Agent Error Attribution. InNeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling. https://openreview.net/forum?id=0MyUdq7wLe
work page 2025
-
[4]
Islem Bouzenia, Premkumar T. Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. In47th IEEE/ACM In- ternational Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 2188–2200. doi:10.1109/ICSE55347.2025.00157
-
[5]
Islem Bouzenia and Michael Pradel. 2025. Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories. In40th IEEE/ACM Inter- national Conference on Automated Software Engineering, ASE 2025, Seoul, Korea, Republic of, November 16-20, 2025. IEEE, 2846–2857. doi:10.1109/ASE63991.2025. 00234
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page 2020
-
[7]
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ram- chandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. 2026. Why Do Multi-Agent LLM Systems Fail?. InThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems Datasets and Benchmarks T...
work page 2026
-
[8]
Esha Choukse, Pratyush Patel, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, Rodrigo Fonseca, and Ricardo Bianchini. 2025. Splitwise: Efficient Gen- erative LLM Inference Using Phase Splitting.IEEE Micro45, 4 (2025), 54–59. doi:10.1109/MM.2025.3575361
-
[10]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch
-
[11]
Improving Factuality and Reasoning in Language Models through Multia- gent Debate. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 (Proceedings of Machine Learning Research), Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp ...
work page 2024
-
[12]
Qiong Feng, Xiaotian Ma, Jiayi Sheng, Ziyuan Feng, Wei Song, and Peng Liang
-
[13]
arXiv:2412.03905 doi:10.48550/ARXIV.2412.03905
Integrating Various Software Artifacts for Better LLM-based Bug Local- ization and Program Repair.CoRRabs/2412.03905 (2024). arXiv:2412.03905 doi:10.48550/ARXIV.2412.03905
-
[14]
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Ger- rits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. 2024. Magentic-One: A Generalist Multi-Agent System for Solving Complex ...
-
[16]
Shanshan Han, Qifan Zhang, Yuhang Yao, Weizhao Jin, Zhaozhuo Xu, and Chaoyang He. 2024. LLM Multi-Agent Systems: Challenges and Open Problems. CoRRabs/2402.03578 (2024). arXiv:2402.03578 doi:10.48550/ARXIV.2402.03578
-
[17]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. In The Twelfth International Conference on Learning Representatio...
work page 2024
-
[18]
Robert Hutter and Michael Pradel. 2026. AgentStepper: Interactive Debugging of Software Development Agents.CoRRabs/2602.06593 (2026). arXiv:2602.06593 doi:10.48550/ARXIV.2602.06593
-
[19]
Yeonjun In, Mehrab Tanjim, Jayakumar Subramanian, Sungchul Kim, Uttaran Bhattacharya, Wonjoong Kim, Sangwu Park, Somdeb Sarkhel, and Chany- oung Park. 2026. Rethinking Failure Attribution in Multi-Agent Systems: A Multi-Perspective Benchmark and Evaluation.CoRRabs/2603.25001 (2026). arXiv:2603.25001 doi:10.48550/ARXIV.2603.25001
-
[20]
Ashraful Islam, Mohammed Eunus Ali, and Md
Md. Ashraful Islam, Mohammed Eunus Ali, and Md. Rizwan Parvez. 2024. Map- Coder: Multi-Agent Code Generation for Competitive Problem Solving. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (...
-
[21]
Sarthak Jain and Byron C. Wallace. 2019. Attention is not Explanation. InPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio (...
-
[23]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[24]
James A. Jones and Mary Jean Harrold. 2005. Empirical evaluation of the tarantula automatic fault-localization technique. In20th IEEE/ACM International Conference on Automated Software Engineering (ASE 2005), November 7-11, 2005, Long Beach, CA, USA, David F. Redmiles, Thomas Ellman, and Andrea Zisman (Eds.). ACM, 273–282. doi:10.1145/1101908.1101949
-
[25]
Sungmin Kang, Gabin An, and Shin Yoo. 2024. A Quantitative and Qualitative Evaluation of LLM-Based Explainable Fault Localization.Proc. ACM Softw. Eng. 1, FSE (2024), 1424–1446. doi:10.1145/3660771
-
[26]
Abdelfattah, and Alexander M Rush
Woojeong Kim, Junxiong Wang, Jing Nathan Yan, Mohamed S. Abdelfattah, and Alexander M Rush. 2025. Overfill: Two-Stage Models for Efficient Language Model Decoding. InSecond Conference on Language Modeling. https://openreview. net/forum?id=e112iu5ssg
work page 2025
-
[27]
Fanqi Kong, Ruijie Zhang, Huaxiao Yin, Guibin Zhang, Xiaofei Zhang, Ziang Chen, Zhaowei Zhang, Xiaoyuan Zhang, Song-Chun Zhu, and Xue Feng. 2026. Aegis: Automated Error Generation and Attribution for Multi-Agent Systems. InThe Fourteenth International Conference on Learning Representations. https: //openreview.net/forum?id=zqcYoxXiN3
work page 2026
-
[28]
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. 2024. A survey on LLM-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth1, 1 (2024), 9
work page 2024
-
[29]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Trans. Assoc. Comput. Linguistics12 (2024), 157–173. doi:10. 1162/TACL_A_00638
work page 2024
-
[30]
Jiaying Lu, Bo Pan, Jieyi Chen, Yingchaojie Feng, Jingyuan Hu, Yuchen Peng, and Wei Chen. 2025. AgentLens: Visual Analysis for Agent Behaviors in LLM-Based Autonomous Systems.IEEE Trans. Vis. Comput. Graph.31, 8 (2025), 4182–4197. doi:10.1109/TVCG.2024.3394053
-
[31]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. GAIA: a benchmark for General AI Assistants. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=fibxvahvs3
work page 2024
-
[32]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative Agents for Software Development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangk...
-
[33]
Ruoyu Qin, Weiran He, Yaoyu Wang, Zheming Li, Xinran Xu, Yongwei Wu, Weimin Zheng, and Mingxing Zhang. 2026. Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter. arXiv:2604.15039 [cs.DC] https://arxiv.org/abs/2604.15039
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog Conference acronym ’XX, June 03–05, 2026, Woodstock, NY Yang Liu, Hongjiang Feng, Junsong Pu, and Zhuangbin Chen 1, 8 (2019), 9
work page 2019
-
[35]
Zhilei Ren, Changlin Liu, Xusheng Xiao, He Jiang, and Tao Xie. 2019. Root Cause Localization for Unreproducible Builds via Causality Analysis Over System Call Tracing. In34th IEEE/ACM International Conference on Automated Software Engineering, ASE 2019, San Diego, CA, USA, November 11-15, 2019. IEEE, 527–538. doi:10.1109/ASE.2019.00056
-
[36]
Linxin Song, Jiale Liu, Jieyu Zhang, Shaokun Zhang, Ao Luo, Shijian Wang, Qingyun Wu, and Chi Wang. 2024. Adaptive In-conversation Team Building for Language Model Agents.CoRRabs/2405.19425 (2024). arXiv:2405.19425 doi:10.48550/ARXIV.2405.19425
-
[37]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30: An- nual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxbur...
work page 2017
-
[38]
Yawen Wang, Wenjie Wu, Junjie Wang, and Qing Wang. 2026. From Flat Logs to Causal Graphs: Hierarchical Failure Attribution for LLM-based Multi-Agent Systems.CoRRabs/2602.23701 (2026). arXiv:2602.23701 doi:10.48550/ARXIV. 2602.23701
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[39]
Alva West, Yixuan Weng, Minjun Zhu, Zhen Lin, Zhiyuan Ning, and Yue Zhang
-
[40]
arXiv:2509.10401 doi:10.48550/ARXIV.2509.10401
Abduct, Act, Predict: Scaffolding Causal Inference for Automated Failure At- tribution in Multi-Agent Systems.CoRRabs/2509.10401 (2025). arXiv:2509.10401 doi:10.48550/ARXIV.2509.10401
-
[41]
Sarah Wiegreffe and Yuval Pinter. 2019. Attention is not not Explanation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Process- ing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (Eds....
-
[42]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework.CoRR abs/2308.08155 (2023). arXiv:2308.08155 doi:10.48550/ARXIV.2308.08155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08155 2023
-
[43]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. De- mystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE (2025), 801–824. doi:10.1145/3715754
-
[44]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated Program Repair via Conversation: Fixing 162 out of 337 Bugs for $0.42 Each using ChatGPT. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, Maria Christakis and Michael Pradel (Eds.). ACM, 819–831. doi:1...
-
[45]
Junjielong Xu, Qinan Zhang, Zhiqing Zhong, Shilin He, Chaoyun Zhang, Qing- wei Lin, Dan Pei, Pinjia He, Dongmei Zhang, and Qi Zhang. 2025. OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures?. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://o...
work page 2025
-
[46]
Aidan Z. H. Yang, Claire Le Goues, Ruben Martins, and Vincent J. Hellendoorn
-
[47]
Large Language Models for Test-Free Fault Localization. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024. ACM, 17:1–17:12. doi:10.1145/3597503.3623342
-
[48]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, Dece...
work page 2024
-
[49]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. CoRRabs/2406.12045 (2024). arXiv:2406.12045 doi:10.48550/ARXIV.2406.12045
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.12045 2024
-
[50]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview. net/forum?id=WE_vluYUL-X
work page 2023
-
[51]
Chenxi Zhang, Zhen Dong, Xin Peng, Bicheng Zhang, and Miao Chen. 2024. Trace-based Multi-Dimensional Root Cause Localization of Performance Issues in Microservice Systems. InProceedings of the 46th IEEE/ACM International Con- ference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024. ACM, 110:1–110:12. doi:10.1145/3597503.3639088
-
[52]
Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, and Shuicheng YAN. 2026. AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=l05DseqvuD
work page 2026
-
[53]
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, and Qingyun Wu. 2025. Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-1...
work page 2025
-
[54]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, Maria Christakis and Michael Pradel (Eds.). ACM, 1592–1604. doi:10.1145/3650212.3680384
-
[55]
Chenyang Zhu, Spencer Hong, Jingyu Wu, Kushal Chawla, Yuhui Tang, Youbing Yin, Nathan Wolfe, Erin Babinsky, and Daben Liu. 2025. RAFFLES: Reasoning- based Attribution of Faults for LLM Systems. InFirst Workshop on Multi-Turn Inter- actions in Large Language Models. https://openreview.net/forum?id=0oxelK4W6c
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.