Recognition: no theorem link
FS-I2P:A Hierarchical Focus-Sweep Registration Network with Dynamically Allocated Depth
Pith reviewed 2026-05-11 02:17 UTC · model grok-4.3
The pith
A focus-sweep interaction module with dynamic depth allocation improves cross-modal image-to-point cloud registration by cutting attention drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
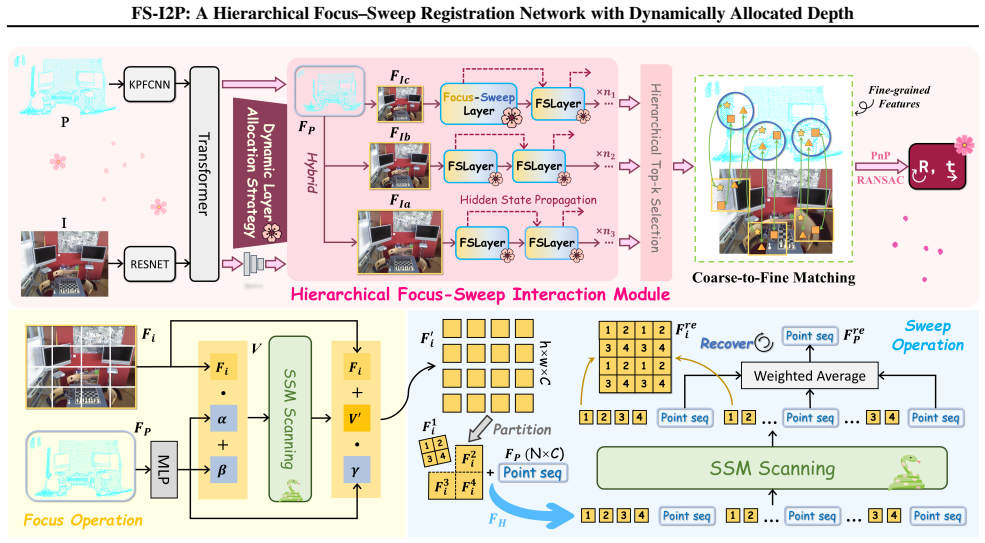
The central claim is that the Hierarchical Focus-Sweep Interaction Module, placed inside an SSM-based registration network, performs multi-level cross-modal feature association that reduces attention drift across layers and intra-scale inconsistencies, while the accompanying Dynamic Layer Allocation Strategy adaptively sets iteration depth to strengthen geometric constraints and produce more robust matches.
What carries the argument
The Hierarchical Focus-Sweep Interaction Module, which emulates human focus-sweep behavior to build multi-level cross-modal associations within an SSM framework, together with the Dynamic Layer Allocation Strategy that decides per-sample iteration depth.
If this is right
- Registration pipelines can exploit multi-scale features more reliably without extra post-processing for drift correction.
- Adaptive depth selection lets the network trade compute for accuracy depending on scene geometry complexity.
- The same focus-sweep pattern can be inserted into other SSM-based cross-modal tasks that currently use fixed-layer transformers.
- Benchmarks that measure both rotation and translation error will show lower failure rates on repetitive-texture scenes.
Where Pith is reading between the lines
- The dynamic allocation idea could be tested on other vision backbones to see whether iteration depth is a general lever for scale-ambiguous matching problems.
- If the focus-sweep module generalizes, it might reduce the need for heavy data augmentation in training registration networks.
- Real-world deployment on resource-limited robots would require measuring whether the adaptive depth keeps latency predictable.
Load-bearing premise
That the focus-sweep module and dynamic allocation actually cut attention drift and scale inconsistencies enough to deliver the observed registration gains.
What would settle it
If ablating the Hierarchical Focus-Sweep Interaction Module or the Dynamic Layer Allocation Strategy on RGB-D Scenes V2 produces no drop in registration accuracy relative to the full model, the contribution of these components is falsified.
Figures



read the original abstract
Image-to-point cloud registration is often challenged by viewpoint changes, cross-modal discrepancies, and repetitive textures, which induce scale ambiguity and consequently lead to erroneous correspondences. Recent detection-free methods alleviate this issue by leveraging multi-scale features and transformer-based interactions. However, they still suffer from attention drift across layers and intra-scale inconsistencies, hindering precise registration. Inspired by human behavior, we propose a ``Focus--Sweep'' paradigm and develop a Hierarchical Focus--Sweep Interaction Module within an SSM-based framework to enhance multi-level cross-modal feature association. In addition, we introduce a Dynamic Layer Allocation Strategy that adaptively determines the iteration depth to better exploit geometric constraints and improve matching robustness. Extensive experiments and ablations on two benchmarks, RGB-D Scenes V2 and 7-Scenes, demonstrate that our approach achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FS-I2P, a hierarchical focus-sweep registration network for image-to-point cloud registration. It introduces a Hierarchical Focus-Sweep Interaction Module within an SSM-based framework to improve multi-level cross-modal feature association and mitigate attention drift and intra-scale inconsistencies, along with a Dynamic Layer Allocation Strategy that adaptively sets iteration depth to exploit geometric constraints. The central claim is that these components yield state-of-the-art registration performance on the RGB-D Scenes V2 and 7-Scenes benchmarks, supported by experiments and ablations.
Significance. If the performance claims and mechanistic attributions hold, the work could meaningfully advance detection-free cross-modal registration by introducing a human-inspired focus-sweep paradigm and adaptive depth allocation that address persistent issues of scale ambiguity and attention drift in transformer-based methods. The SSM backbone may additionally confer efficiency advantages, but the overall significance hinges on whether the reported gains can be isolated to the proposed modules rather than unablated factors.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the SOTA claim rests on ablations that remove the Hierarchical Focus-Sweep Interaction Module and Dynamic Layer Allocation Strategy, yet no auxiliary metrics (e.g., attention-map entropy, layer-wise correspondence consistency, or scale-specific feature variance) are reported to demonstrate that these modules specifically alleviate attention drift or intra-scale inconsistencies. Without such isolation, gains could arise from the SSM backbone, training schedule, or other design choices.
- [Method description of Hierarchical Focus-Sweep Interaction Module] The description of the Hierarchical Focus-Sweep Interaction Module (likely §3): the assertion that the module enhances multi-level cross-modal feature association by reducing attention drift is load-bearing for the central claim, but the manuscript supplies only overall registration recall/precision improvements rather than direct before/after comparisons or visualizations that would confirm the mechanism.
minor comments (2)
- [Abstract] The abstract would benefit from including at least one quantitative result (e.g., registration recall on 7-Scenes) to allow readers to gauge the magnitude of the claimed improvement.
- [Throughout] Ensure all acronyms (SSM, FS-I2P) are defined on first use and used consistently in figure captions and tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on isolating the contributions of our proposed modules. We address each major comment below and outline revisions to strengthen the mechanistic evidence.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the SOTA claim rests on ablations that remove the Hierarchical Focus-Sweep Interaction Module and Dynamic Layer Allocation Strategy, yet no auxiliary metrics (e.g., attention-map entropy, layer-wise correspondence consistency, or scale-specific feature variance) are reported to demonstrate that these modules specifically alleviate attention drift or intra-scale inconsistencies. Without such isolation, gains could arise from the SSM backbone, training schedule, or other design choices.
Authors: We agree that auxiliary metrics would provide stronger isolation of the modules' effects. The ablations show clear performance degradation when removing either component, but we acknowledge that this does not fully rule out contributions from the SSM backbone or training details. In the revised manuscript, we will add attention-map entropy calculations, layer-wise correspondence consistency metrics, and scale-specific feature variance analysis, along with corresponding visualizations, to directly demonstrate mitigation of attention drift and intra-scale inconsistencies. revision: yes
-
Referee: [Method description of Hierarchical Focus-Sweep Interaction Module] The description of the Hierarchical Focus-Sweep Interaction Module (likely §3): the assertion that the module enhances multi-level cross-modal feature association by reducing attention drift is load-bearing for the central claim, but the manuscript supplies only overall registration recall/precision improvements rather than direct before/after comparisons or visualizations that would confirm the mechanism.
Authors: We acknowledge that direct before-and-after evidence would better substantiate the mechanism. The Hierarchical Focus-Sweep Interaction Module is explicitly designed with progressive focus-sweep operations across hierarchical levels to refine cross-modal associations and counteract drift, as motivated in the introduction and method sections. However, the current version relies primarily on aggregate metrics. We will incorporate attention map visualizations and before/after comparisons of correspondence consistency in the revised manuscript to illustrate the reduction in attention drift. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper proposes a Hierarchical Focus-Sweep Interaction Module and Dynamic Layer Allocation Strategy inside an SSM framework, then reports registration performance on the independent RGB-D Scenes V2 and 7-Scenes benchmarks. No equations, fitted parameters, or self-citations are shown that reduce the claimed gains to quantities defined by the method itself; the SOTA result is obtained by direct comparison against prior methods on held-out test data rather than by construction from internal definitions or ablations that presuppose the target improvement.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Predator: Registration of 3d point clouds with low overlap
Huang, S., Gojcic, Z., Usvyatsov, M., Wieser, A., and Schindler, K. Predator: Registration of 3d point clouds with low overlap. InProceedings of the IEEE/CVF Con- ference on computer vision and pattern recognition, pp. 4267–4276, 2021a. Huang, S., Gojcic, Z., Usvyatsov, M., Wieser, A., and Schindler, K. Predator: Registration of 3d point clouds with low o...
-
[2]
Khairuddin, A. R., Talib, M. S., and Haron, H. Review on simultaneous localization and mapping (slam). In 2015 IEEE international conference on control system, computing and engineering (ICCSCE), pp. 85–90. IEEE,
work page 2015
-
[3]
Ef-3dgs: Event-aided free-trajectory 3d gaussian splatting.arXiv preprint arXiv:2410.15392,
Liao, B., Zhai, W., Wan, Z., Cheng, Z., Yang, W., Zhang, T., Cao, Y ., and Zha, Z.-J. Ef-3dgs: Event-aided free-trajectory 3d gaussian splatting.arXiv preprint arXiv:2410.15392,
-
[4]
Mao, Z., Yang, Y ., Ma, C., Jiang, D., Yao, J., Zhang, Y ., and Wang, Y . Safire: Saccade-fixation reiteration with mamba for referring image segmentation.arXiv preprint arXiv:2510.10160,
-
[5]
Real time localization and 3d reconstruction
Mouragnon, E., Lhuillier, M., Dhome, M., Dekeyser, F., and Sayd, P. Real time localization and 3d reconstruction. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 1, pp. 363–370. IEEE, 2006a. Mouragnon, E., Lhuillier, M., Dhome, M., Dekeyser, F., and Sayd, P. Real time localization and 3d reconstruction...
work page 2006
-
[6]
Pan, Y ., Sun, R., Wang, Y ., Yang, W., Zhang, T., and Zhang, Y . Purify then guide: A bi-directional bridge network for open-vocabulary semantic segmentation.IEEE Trans- actions on Circuits and Systems for Video Technology, 2024a. Pan, Y ., Sun, R., Wang, Y ., Zhang, T., and Zhang, Y . Re- thinking the implicit optimization paradigm with dual alignments ...
work page 2031
-
[7]
Impact of similarity measures on web-page clustering
12 FS-I2P: A Hierarchical Focus–Sweep Registration Network with Dynamically Allocated Depth Strehl, A., Ghosh, J., and Mooney, R. Impact of similarity measures on web-page clustering. InWorkshop on artifi- cial intelligence for web search (AAAI 2000), volume 58, pp. 64,
work page 2000
-
[8]
Tao, X., Wang, C., Ai, Y ., Cheng, Z., Li, Z., Liu, L., Chen, Y ., Li, X., Li, Q., Yang, W., et al. Geoguide: Hierarchi- cal geometric guidance for open-vocabulary 3d semantic segmentation.arXiv preprint arXiv:2603.26260,
-
[9]
Wang, C., Deng, J., He, J., Zhang, T., Zhang, Z., and Zhang, Y . Long-short range adaptive transformer with dynamic sampling for 3d object detection.IEEE Transactions on Circuits and Systems for Video Technology, 33(12): 7616–7629, 2023a. Wang, C., Yang, W., and Zhang, T. Not every side is equal: Localization uncertainty estimation for semi-supervised 3d ...
-
[10]
Wang, Z., Pan, T., Zhou, Q., and Wang, J
doi: 10.1609/aaai.v36i8.20839. Wang, Z., Pan, T., Zhou, Q., and Wang, J. Efficient exploration in resource-restricted reinforcement learn- ing.Proceedings of the AAAI Conference on Artifi- cial Intelligence, 37(8):10279–10287, Jun. 2023e. doi: 10.1609/aaai.v37i8.26224. Wang, Z., Wang, J., Zuo, D., Ji, Y ., Xia, X., Ma, Y ., Hao, J., Yuan, M., Zhang, Y ., ...
-
[11]
Yue, Y ., Yuan, H., Miao, Q., Mao, X., Hamzaoui, R., and Eisert, P. Edgeregnet: Edge feature-based multimodal reg- istration network between images and lidar point clouds. arXiv preprint arXiv:2503.15284,
-
[12]
Zha, Y ., Wang, C., Yang, W., and Zhang, T. Exploring semantic masked autoencoder for self-supervised point cloud understanding.arXiv preprint arXiv:2506.21957, 2025a. Zha, Y ., Wang, C., Yang, W., Zhang, T., and Wu, F. Ex- ploring vision semantic prompt for efficient point cloud understanding. InForty-second International Conference on Machine Learning, ...
-
[13]
is a nonlinear di- mensionality reduction technique used primarily for data visualization. It is particularly effective for visualizing high- dimensional datasets by embedding them into two or three dimensions. t-SNE aims to preserve the local structure of data points by modeling similar objects with nearby points and dissimilar objects with distant point...
work page 2016
-
[14]
, sin(2L−1x),cos(2 L−1x) , (26) where L is the length of the embedding
encodes positional information by transforming it into a sequence of sine and cosine terms: ϕ(x) = x,sin(2 0x),cos(2 0x), . . . , sin(2L−1x),cos(2 L−1x) , (26) where L is the length of the embedding. This transforma- tion incorporates spatial positioning into the features. To facilitate further computations, the first two spatial dimen- sions of the 2D fe...
work page 2021
-
[15]
The margins are set to∆ p = 0.1and∆ n = 1.4
Pairs not meeting these criteria are ignored as the safe region during training. The margins are set to∆ p = 0.1and∆ n = 1.4. D. Addtional ablation study Table 4 studies the effect of interaction depth. For the Trans- former baseline, increasing the number of layers improves RR from 49.8 to 56.4 when going from 1 to 3 layers, but deeper stacking causes pe...
work page 2023
-
[16]
Image-to-Point2.05±3.234.01±6.372D3D-MATR (Li et al., 2023)Image-to-Point1.86±3.792.59±4.46RetrI2P (Bie et al.,
work page 2023
-
[17]
Image-to-Point1.95±2.972.63±3.19FS-I2P (Ours) Image-to-Point1.57±2.752.36±2.58 consistently outperforms Baseline+DINOv2 across all met- rics, improving FMR from 37.8 to 41.2 and IR from 92.4 to 94.5. More importantly, it achieves a large gain in RR (74.2 to 86.3), indicating that our Focus-Sweep interactions convert stronger image semantics into more reli...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.