Recognition: 1 theorem link
· Lean TheoremLearning Large-Scale Modular Addition with an Auxiliary Modulus
Pith reviewed 2026-05-11 01:49 UTC · model grok-4.3
The pith
Training with an auxiliary modulus Kq lets models learn large modular addition without covariate shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
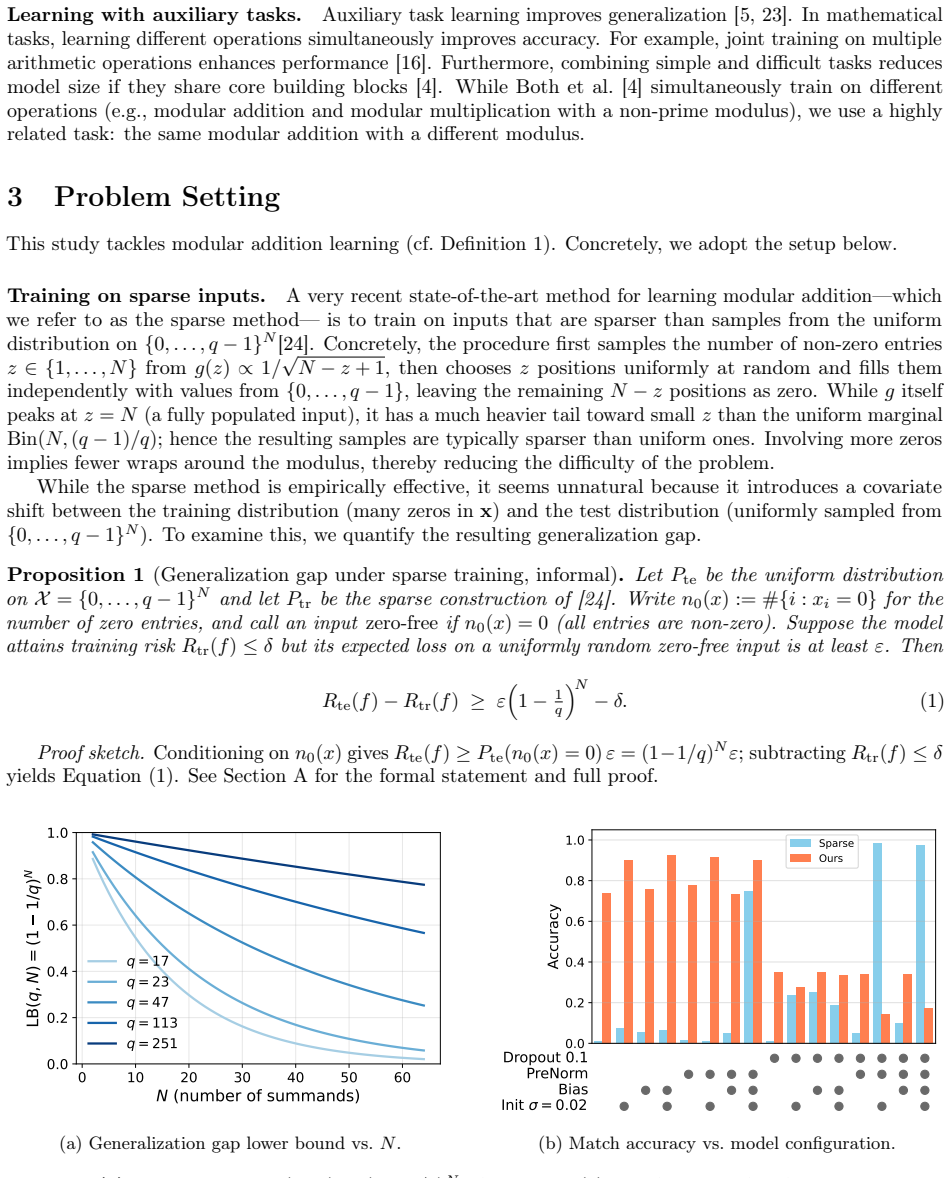
The central claim is that an auxiliary modulus Kq used exclusively during training reduces wrap-around frequency and thereby lowers problem difficulty for modular addition, while exactly preserving the input distribution used at test time with the original modulus q. This covariate-shift-free approach yields equal or superior match accuracy and relaxed τ-accuracy compared with sparse training, including cases with input length N=64 and q=974269 trained on only 100K examples.
What carries the argument
The auxiliary modulus Kq, a fixed multiple of the target modulus q, applied only at training time to decrease wrap-around occurrences while keeping training and test input distributions identical.
If this is right
- For N=64 and q=974269 the method reaches 97 percent relaxed τ-accuracy at τ=0.05 using 100K samples.
- The same method matches or exceeds the sparse baseline even when the baseline is given ten times more training data.
- Input distributions remain identical between training and testing, removing the covariate-shift penalty of earlier sparsity techniques.
- The underlying modular-addition task is unchanged; only the training modulus is enlarged.
Where Pith is reading between the lines
- The same auxiliary-modulus device could be tested on other modular or cyclic tasks where wrap-arounds dominate the difficulty.
- One could measure how accuracy scales with the choice of multiplier K to find optimal values for given N and q.
- The approach may extend to sequence models that must learn other sensitive arithmetic or periodic functions.
Load-bearing premise
That a model trained on additions modulo Kq will generalize correctly to the original modulus q at test time and that the reduction in wrap-arounds actually simplifies the learning problem without side effects.
What would settle it
A controlled run in which networks trained on Kq achieve no better than random accuracy when evaluated on the standard task with modulus q, or in which the measured frequency of wrap-arounds fails to drop as K is increased.
Figures




read the original abstract
Learning parity functions, more general modular addition, is a challenging machine learning task due to its input sensitivity. A recent study substantially scaled modular addition learning in both the number of summands and the modulus. Its key idea is to increase zeros in training sequences, reducing the effective number of summands and thus controlling training difficulty; however, this induces covariate shift between training and test input distributions. This study theoretically and empirically analyzes this side effect and proposes a covariate-shift-free method for modular addition. Specifically, we introduce an auxiliary modulus $Kq$ during training, which reduces wrap-around frequency and problem difficulty while preserving the same input distribution across training and testing. Experiments show strong scalability and sample efficiency: even for large input length $N$, large modulus $q$, and small datasets -- where the sparse method fails to learn -- our method achieves equal or better match accuracy and relaxed $\tau$-accuracy. For example, at $N=64$ and $q=974269$, our method trained on 100K samples achieves $97.0\%$ $\tau$-accuracy at $\tau=0.05$, while the sparse method achieves only $9.5\%$ with the same data size and $93.9\%$ even when extended to 1M samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a covariate-shift-free method for learning modular addition by introducing an auxiliary modulus Kq during training. This reduces wrap-around frequency and problem difficulty while preserving the original input distribution (unlike sparse zero-padding methods). It claims strong empirical scalability and sample efficiency: for large N (e.g., 64) and large q (e.g., 974269), the method achieves high match accuracy and relaxed τ-accuracy (e.g., 97.0% at τ=0.05 with 100K samples) where sparse baselines fail or require far more data.
Significance. If the central empirical claims hold after verification, the work offers a practical training technique for scaling neural networks on modular arithmetic without inducing train-test distribution shift. This could aid mechanistic interpretability studies and generalization analyses for periodic or modular functions, with potential extensions to other arithmetic tasks.
major comments (2)
- [Experiments] The evaluation protocol (reported in the Experiments section) supervises exact sums modulo Kq during training but evaluates only relaxed τ-accuracy after reduction modulo q at test time. This leaves open whether the model has learned accurate outputs modulo Kq or merely a mod-q approximation whose errors lie on the q-lattice; a concrete check (e.g., reporting exact match accuracy modulo Kq on held-out test data) is needed to substantiate the claim that the auxiliary task is preserved and generalized correctly.
- [Theoretical Analysis] The theoretical analysis of the sparse method's covariate shift (likely in §3 or §4) is used to motivate the auxiliary-modulus approach, but the paper does not derive or bound how the choice of K affects generalization error or wrap-around reduction in a parameter-free way; the empirical gains may therefore depend on K-tuning that is not fully characterized.
minor comments (2)
- [Introduction] Notation for the auxiliary modulus (Kq) and the relaxed accuracy metric τ should be defined explicitly in the main text on first use, with a clear statement of how τ-accuracy is computed after mod-q reduction.
- [Abstract] The abstract and results tables would benefit from reporting exact (non-relaxed) accuracy numbers alongside the τ-accuracy figures to allow direct comparison with prior modular-addition work.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Experiments] The evaluation protocol (reported in the Experiments section) supervises exact sums modulo Kq during training but evaluates only relaxed τ-accuracy after reduction modulo q at test time. This leaves open whether the model has learned accurate outputs modulo Kq or merely a mod-q approximation whose errors lie on the q-lattice; a concrete check (e.g., reporting exact match accuracy modulo Kq on held-out test data) is needed to substantiate the claim that the auxiliary task is preserved and generalized correctly.
Authors: We agree that reporting exact match accuracy modulo Kq on held-out test data would strengthen the substantiation of our claims. In the revised manuscript, we have added this metric for the primary experimental settings. For the N=64 and q=974269 case with 100K samples, the model achieves 96.8% exact accuracy modulo Kq (in addition to the reported 97.0% relaxed τ-accuracy at τ=0.05 after reduction modulo q). These results confirm that the network learns precise sums under the auxiliary modulus rather than a mod-q approximation with lattice-aligned errors. revision: yes
-
Referee: [Theoretical Analysis] The theoretical analysis of the sparse method's covariate shift (likely in §3 or §4) is used to motivate the auxiliary-modulus approach, but the paper does not derive or bound how the choice of K affects generalization error or wrap-around reduction in a parameter-free way; the empirical gains may therefore depend on K-tuning that is not fully characterized.
Authors: The theoretical component of the manuscript is devoted to establishing and quantifying the covariate shift induced by sparse zero-padding, which directly motivates the auxiliary-modulus method as a distribution-preserving alternative. We do not derive a parameter-free bound on generalization error with respect to K, as such an analysis would require a substantially more advanced theoretical treatment of neural network generalization on modular functions that lies beyond the paper's scope. We have, however, added a dedicated paragraph in the revised manuscript that characterizes wrap-around reduction as a function of K (the probability of sums exceeding q scales inversely with K) and reports additional experiments demonstrating stable performance for small integer values of K (K=2,3,4) with clear diminishing returns for larger K. This supplies practical guidance for K selection based on the expected sum magnitude N(q-1)/2. revision: partial
Circularity Check
No significant circularity; empirical claims rest on experimental outcomes.
full rationale
The paper introduces an auxiliary-modulus training procedure as a design choice that preserves input distribution while reducing wrap-around, then reports match accuracy and relaxed τ-accuracy on held-out test sets. No derivation chain is claimed that reduces a result to its own fitted parameters or to a self-citation; the central assertions are presented as empirical findings rather than algebraic identities or uniqueness theorems. The method definition and evaluation protocol are independent of the reported numbers, satisfying the default expectation of non-circularity for an empirical ML paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks of sufficient capacity can represent modular addition functions when trained on appropriately distributed data.
Reference graph
Works this paper leans on
-
[1]
Provable advantage of curriculum learning on parity targets with mixed inputs
Emmanuel Abbe, Elisabetta Cornacchia, and Aryo Lotfi. Provable advantage of curriculum learning on parity targets with mixed inputs. InAdvances in Neural Information Processing Systems, volume 36, pages 24291–24321. Curran Associates, Inc., 2023. URLhttps://proceedings.neurips.cc/paper_ files/paper/2023/file/4c8ce3c63f6b66d6811c6d67c68e487b-Paper-Conference.pdf
work page 2023
-
[2]
Global lyapunov functions: a long-standing open problem in mathematics, with symbolic transformers
Alberto Alfarano, François Charton, and Amaury Hayat. Global lyapunov functions: a long-standing open problem in mathematics, with symbolic transformers. InAdvances in Neural Information Processing Systems, volume 37, pages 93643–93670, 2024. URLhttps://proceedings.neurips.cc/paper_files/ paper/2024/file/aa280e73c4e23e765fde232571116d3b-Paper-Conference.pdf
work page 2024
-
[3]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, page 41–48, 2009. URL https://doi.org/10.1145/1553374.1553380
-
[4]
Weidele, Mauro Martino, and Nima Dehmamy
Csaba Both, Benjamin Hoover, Hendrik Strobelt, Dmitry Krotov, Daniel Karl I. Weidele, Mauro Martino, and Nima Dehmamy. Small models, smarter learning: The power of joint task training, 2026. URL https://arxiv.org/abs/2505.18369
-
[5]
Multitask learning.Machine learning, 28(1):41–75, 1997
Rich Caruana. Multitask learning.Machine learning, 28(1):41–75, 1997
work page 1997
-
[6]
Learning advanced mathematical com- putations from examples
Francois Charton, Amaury Hayat, and Guillaume Lample. Learning advanced mathematical com- putations from examples. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=-gfhS00XfKj
work page 2021
-
[7]
Learning parities with neural networks
Amit Daniely and Eran Malach. Learning parities with neural networks. InAdvances in Neural Information Processing Systems, volume 33, pages 20356–20365, 2020. URLhttps://proceedings. neurips.cc/paper_files/paper/2020/file/eaae5e04a259d09af85c108fe4d7dd0c-Paper.pdf
work page 2020
-
[8]
Grokking modular polynomials, 2024
Darshil Doshi, Tianyu He, Aritra Das, and Andrey Gromov. Grokking modular polynomials, 2024. URL https://arxiv.org/abs/2406.03495
-
[9]
Hiroki Furuta, Gouki Minegishi, Yusuke Iwasawa, and Yutaka Matsuo. Towards empirical interpretation of internal circuits and properties in grokked transformers on modular polynomials.Transactions on Machine Learning Research, 2024. URLhttps://openreview.net/forum?id=MzSf70uXJO
work page 2024
-
[10]
arXiv preprint arXiv:2301.02679 , year=
Andrey Gromov. Grokking modular arithmetic, 2023. URLhttps://arxiv.org/abs/2301.02679
-
[11]
Michael Hahn and Mark Rofin. Why are sensitive functions hard for transformers? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14973–15008, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.800. URLhttps://aclanthology.org/2024...
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human- level performance on imagenet classification. InProceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), page 1026–1034, 2015. URLhttps://doi.org/10.1109/ICCV.2015.123
-
[13]
Learning to compute gröbner bases
Hiroshi Kera, Yuki Ishihara, Yuta Kambe, Tristan Vaccon, and Kazuhiro Yokoyama. Learning to compute gröbner bases. InAdvances in Neural Information Processing Systems, volume 37, pages 33141–33187, 2024. URLhttps://proceedings.neurips.cc/paper_files/paper/2024/file/ 3a1de90699eec7d7f42c91d81f94af16-Paper-Conference.pdf
work page 2024
-
[14]
Computational algebra with attention: Transformer oracles for border basis algorithms
Hiroshi Kera, Nico Pelleriti, Yuki Ishihara, Max Zimmer, and Sebastian Pokutta. Computational algebra with attention: Transformer oracles for border basis algorithms. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum? id=bA9rhgWOHk. 11
work page 2026
-
[15]
Transformers provably solve parity efficiently with chain of thought
Juno Kim and Taiji Suzuki. Transformers provably solve parity efficiently with chain of thought. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview. net/forum?id=n2NidsYDop
work page 2025
-
[16]
Lee, Kangwook Lee, and Dimitris Papailiopoulos
Nayoung Lee, Kartik Sreenivasan, Jason D. Lee, Kangwook Lee, and Dimitris Papailiopoulos. Teaching arithmetic to small transformers. InThe Twelfth International Conference on Learning Representations,
-
[17]
URLhttps://openreview.net/forum?id=dsUB4bst9S
-
[18]
Towards understanding grokking: An effective theory of representation learning
Ziming Liu, Ouail Kitouni, Niklas S Nolte, Eric Michaud, Max Tegmark, and Mike Williams. Towards understanding grokking: An effective theory of representation learning. InAdvances in Neural Information Processing Systems, volume 35, pages 34651–34663, 2022. URLhttps://proceedings.neurips.cc/ paper_files/paper/2022/file/dfc310e81992d2e4cedc09ac47eff13e-Pap...
work page 2022
-
[19]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[20]
Uncovering a universal abstract algorithm for modular addition in neural networks
Gavin McCracken, Gabriela Moisescu-Pareja, Vincent Létourneau, Doina Precup, and Jonathan Love. Uncovering a universal abstract algorithm for modular addition in neural networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/ forum?id=zuHs6RHQwT
work page 2026
-
[21]
Mohamad Amin Mohamadi, Zhiyuan Li, Lei Wu, and Danica J. Sutherland. Why do you grok? a theoretical analysis on grokking modular addition. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=ad5I6No9G1
work page 2024
-
[22]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=9XFSbDPmdW
work page 2023
-
[23]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
AletheaPower, YuriBurda, HarriEdwards, IgorBabuschkin, andVedantMisra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. URLhttps://arxiv.org/abs/2201.02177
work page internal anchor Pith review arXiv 2022
-
[24]
An Overview of Multi-Task Learning in Deep Neural Networks
Sebastian Ruder. An overview of multi-task learning in deep neural networks, 2017. URLhttps: //arxiv.org/abs/1706.05098
work page internal anchor Pith review arXiv 2017
-
[25]
Eshika Saxena, Alberto Alfarano, Emily Wenger, and Kristin E. Lauter. Making hard problems easier with custom data distributions and loss regularization: A case study in modular arithmetic. InForty- second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum? id=le8hVvWi6Q
work page 2025
-
[26]
Failures of gradient-based deep learning
Shai Shalev-Shwartz, Ohad Shamir, and Shaked Shammah. Failures of gradient-based deep learning. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 3067–3075, 06–11 Aug 2017. URLhttps://proceedings.mlr. press/v70/shalev-shwartz17a.html
work page 2017
-
[27]
Samuel Stevens, Emily Wenger, Cathy Yuanchen Li, Niklas Nolte, Eshika Saxena, Francois Charton, and Kristin E. Lauter. Salsa fresca: Angular embeddings and pre-training for ML attacks on learning with errors.Transactions on Machine Learning Research, 2025. URLhttps://openreview.net/forum?id= w4nd5695sq
work page 2025
-
[28]
Nist releases first 3 finalized post-quantum encryption standards, 2024
NIST US Department of Commerce. Nist releases first 3 finalized post-quantum encryption standards, 2024. https://www.nist.gov/news-events/news/2024/08/ nist-releases-first-3-finalized-post-quantum-encryption-standards
work page 2024
-
[29]
Chain-of-thought prompting elicits reasoning in large lan- guage models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large lan- guage models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/ 9d5609613524ecf4f...
work page 2022
-
[30]
Sub-task decomposition enables learning in sequence to sequence tasks
Noam Wies, Yoav Levine, and Amnon Shashua. Sub-task decomposition enables learning in sequence to sequence tasks. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=BrJATVZDWEH
work page 2023
-
[31]
the expected loss on a uniformly random zero-free input
Ziqian Zhong, Ziming Liu, Max Tegmark, and Jacob Andreas. The clock and the pizza: Two stories in mechanistic explanation of neural networks. InAdvances in Neural Information Processing Systems, volume 36, pages 27223–27250, 2023. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2023/file/56cbfbf49937a0873d451343ddc8c57d-Paper-Conference.pdf. 13 A For...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.