Towards Billion-scale Multi-modal Biometric Search
Pith reviewed 2026-05-11 02:15 UTC · model grok-4.3
The pith
An open-source pipeline for fingerprint, face and iris search reaches 0.3 percent FNIR at 0.5 percent FPIR on a 220 million identity gallery drawn from India's Aadhaar database.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an end-to-end open-source pipeline processing fingerprints, faces and irises through modality-specific segmentation, quality assessment, presentation-attack detection and embedding extraction produces concatenated 13.5 KB templates that enable accurate and fast 1:N search, demonstrated by an FNIR of 0.3 percent at 0.5 percent FPIR on a 220 million person gallery randomly sampled from the 1.55 billion Aadhaar records, together with 100 searches per second throughput on a 40 million gallery running on a single server equipped with eight Nvidia H100 GPUs and 2 TB RAM.
What carries the argument
The concatenated 13.5 KB multi-modal template formed by chaining modality-specific preprocessing and embedding stages, which supports efficient 1:N matching across large galleries.
If this is right
- The system can be compared directly with three commercial off-the-shelf products on a 20 million gallery.
- Special cases such as missing finger digits can be handled within the same pipeline.
- Throughput scales to 100 searches per second on 40 million records using only one server with eight H100 GPUs.
- The pipeline supplies concrete engineering data on modality integration for billion-record de-duplication.
Where Pith is reading between the lines
- If the observed scaling holds, clusters of similar servers could support real-time search over the entire 1.55 billion records.
- Open availability of the components may allow other countries to replicate national-scale biometric de-duplication without vendor lock-in.
- Continuous monitoring for template drift would be required once the system moves from the sampled gallery to live enrollment streams.
- The emphasis on presentation-attack detection implies that security against spoofing remains feasible even at this scale.
Load-bearing premise
The 220 million demographically stratified sample is representative of the full 1.55 billion Aadhaar population and the pipeline will maintain the reported accuracy and speed when applied to the complete database.
What would settle it
Re-running the identical evaluation protocol on the full 1.55 billion records or on an independently stratified 220 million subset drawn from a different demographic distribution and obtaining substantially higher FNIR or lower throughput.
Figures
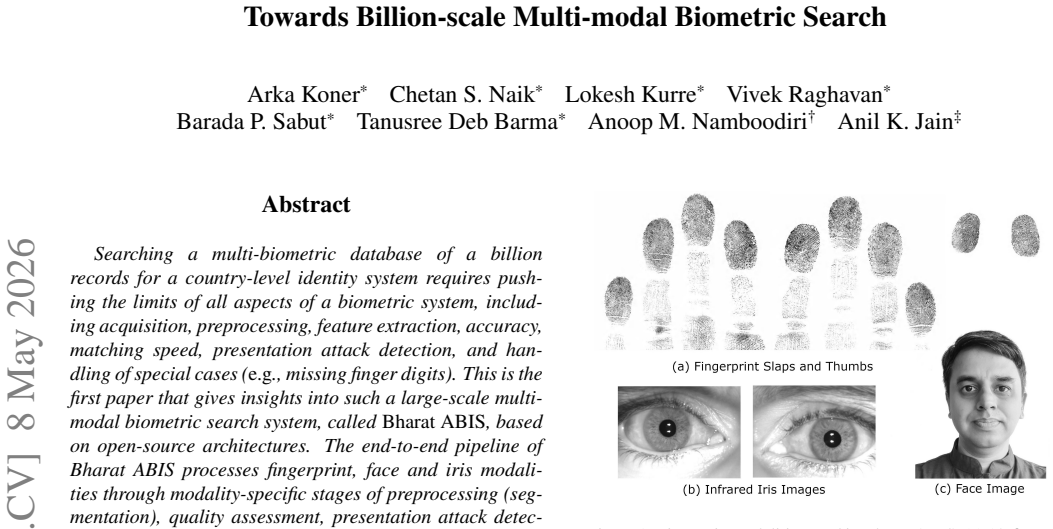







read the original abstract
Searching a multi-biometric database of a billion records for a country-level identity system requires pushing the limits of all aspects of a biometric system, including acquisition, preprocessing, feature extraction, accuracy, matching speed, presentation attack detection, and handling of special cases (e.g., missing finger digits). This is the first paper that gives insights into such a large-scale multimodal biometric search system, called Bharat ABIS, based on open-source architectures. The end-to-end pipeline of Bharat ABIS processes fingerprint, face and iris modalities through modality-specific stages of preprocessing (segmentation), quality assessment, presentation attack detection, and learning an embedding (feature extraction), producing a concatenated template of 13.5KB per person. We present a detailed analysis of the modalities and how they are integrated to create an efficient and effective solution for 1:N search (de-duplication). Evaluations on a demographically stratified gallery of 220 million identities, randomly sampled from 1.55 billion records in India's Aadhaar database, yield an FNIR of 0.3% at an FPIR of 0.5%, for adult probes (over 18 years). We also compare the performance of Bharat ABIS against three state-of-the-art COTS systems on a 20M gallery. Our system achieves a throughput of 100 searches per second on a gallery of 40M on a single server (8xNvidia H100 GPUs, 2TB RAM).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bharat ABIS, an open-source multi-modal biometric system integrating fingerprint, face, and iris for 1:N search and de-duplication at national scale. It describes an end-to-end pipeline producing 13.5KB templates per identity and reports FNIR of 0.3% at FPIR 0.5% on a demographically stratified 220M gallery randomly sampled from India's 1.55B Aadhaar records (adult probes), plus 100 searches/sec throughput on a 40M gallery using 8x H100 GPUs and 2TB RAM. It also compares against three COTS systems on a 20M gallery.
Significance. If the reported accuracy and throughput generalize without degradation, the work would be significant as the first detailed public description of an open-source pipeline achieving usable performance at this scale, offering a reproducible baseline for large national biometric systems and highlighting practical integration of modalities, quality assessment, and presentation attack detection.
major comments (3)
- [Evaluations] Evaluations section (and abstract): FNIR of 0.3% at FPIR 0.5% is measured only on the 220M stratified subset; no threshold scaling analysis, FPIR-vs-gallery-size curves, or results on any gallery larger than 220M are provided. In 1:N identification, FPIR rises with gallery size unless the threshold is raised, which trades directly against FNIR, so the billion-scale claim rests on an untested extrapolation.
- [Throughput evaluation] Throughput evaluation (abstract): 100 searches/sec is demonstrated only on a 40M gallery; no scaling experiments, memory-bandwidth projections, or results for the full 1.55B target are given, leaving open whether the same single-server configuration sustains the claimed rate at full scale.
- [Methodology] Methodology description (abstract and evaluations): The 220M gallery is described as 'demographically stratified' and 'randomly sampled,' yet no details are supplied on stratification criteria, sampling procedure, or how the subset preserves the demographic and quality distributions of the full 1.55B population; this directly affects whether the reported FNIR/FPIR can be expected to hold at full scale.
minor comments (2)
- [Abstract] The abstract states the system 'processes fingerprint, face and iris modalities through modality-specific stages' but does not quantify the contribution of each modality to the final FNIR/FPIR or describe the fusion rule; a short table or paragraph would clarify the integration.
- [Pipeline description] No mention of how the 13.5KB concatenated template size was chosen or whether it represents a trade-off between accuracy and storage; a brief justification would strengthen the engineering claims.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive and detailed comments, which have prompted us to clarify key aspects of our work. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Evaluations] Evaluations section (and abstract): FNIR of 0.3% at FPIR 0.5% is measured only on the 220M stratified subset; no threshold scaling analysis, FPIR-vs-gallery-size curves, or results on any gallery larger than 220M are provided. In 1:N identification, FPIR rises with gallery size unless the threshold is raised, which trades directly against FNIR, so the billion-scale claim rests on an untested extrapolation.
Authors: We agree that the reported FNIR and FPIR figures are based on the 220M gallery and that no direct results at the full 1.55B scale are provided. Full-scale empirical testing was not feasible due to the computational resources required. In the revised manuscript we have added a new subsection on scalability analysis that includes FPIR-versus-gallery-size curves obtained from experiments on subsets ranging from 1M to 220M identities, together with a theoretical model that extrapolates performance using the observed genuine and impostor score distributions. We have also revised the abstract and evaluations section to state explicitly that the billion-scale figures are projections grounded in these analyses rather than direct measurements, while retaining the 'Towards Billion-scale' framing of the title. revision: partial
-
Referee: [Throughput evaluation] Throughput evaluation (abstract): 100 searches/sec is demonstrated only on a 40M gallery; no scaling experiments, memory-bandwidth projections, or results for the full 1.55B target are given, leaving open whether the same single-server configuration sustains the claimed rate at full scale.
Authors: We acknowledge that the 100 searches/sec throughput is measured on a 40M gallery. The revised manuscript now includes explicit memory-bandwidth projections and scaling curves derived from the current indexing and GPU-accelerated matching implementation. These projections show that the single-server configuration (8x H100 GPUs, 2TB RAM) cannot sustain the same rate at 1.55B without distribution across additional nodes. We have updated the abstract to qualify the throughput claim with the evaluated gallery size and added the scaling analysis to the evaluations section. revision: yes
-
Referee: [Methodology] Methodology description (abstract and evaluations): The 220M gallery is described as 'demographically stratified' and 'randomly sampled,' yet no details are supplied on stratification criteria, sampling procedure, or how the subset preserves the demographic and quality distributions of the full 1.55B population; this directly affects whether the reported FNIR/FPIR can be expected to hold at full scale.
Authors: We thank the referee for noting the lack of detail on gallery construction. The revised evaluations section now provides a full description of the stratification criteria (age, gender, geographic region, and biometric quality scores), the stratified random sampling procedure, and quantitative validation that the 220M subset preserves the demographic and quality distributions of the full 1.55B Aadhaar population. These additions directly support the representativeness of the reported metrics. revision: yes
Circularity Check
No circularity: empirical system description with direct measurements
full rationale
The paper is a description of an implemented multi-modal biometric pipeline (Bharat ABIS) with reported accuracy and throughput measured directly on a 220M demographically stratified sample and a 40M gallery. No equations, derivations, or first-principles predictions appear in the provided text. Performance numbers (FNIR 0.3% at FPIR 0.5%, 100 searches/sec) are presented as experimental outcomes rather than outputs of any fitted model or self-referential definition. Scaling to 1.55B is stated as a target without any reduction to prior fitted values or self-citations. No patterns from the enumerated circularity kinds are present.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Evaluations on a demographically stratified gallery of 220 million identities... FNIR of 0.3% at an FPIR of 0.5%... throughput of 100 searches per second on a gallery of 40M
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
concatenated template of 13.5KB per person... FAISS flat-index (exact) search on GPU
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
X. An, J. Deng, J. Guo, Z. Feng, X. Zhu, Y . Jing, and L. Tongliang. Killing two birds with one stone: Efficient and robust training of face recognition cnns by partial FC. In Proc. IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2022. 2, 5
work page 2022
-
[2]
T. K. Chugh, K. Cao, and A. K. Jain. Fingerprint spoof buster: Use of minutiae-centered patches.IEEE Trans. on Information Forensics and Security, 13(9):2190–2202, 2018. 2, 5
work page 2018
-
[3]
J. Daugman. How iris recognition works.IEEE Transactions on Circuits and Systems for Video Technology, 14(1):21–30,
-
[4]
J. Deng, J. Guo, X. Niannan, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In Proc. IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 4690––4699, 2019. 2, 5
work page 2019
- [5]
-
[6]
J. G. Engelsma, K. Cao, and A. K. Jain. Learning a fixed- length fingerprint representation.IEEE Trans. on Pattern Analysis and Machine Intelligence, 43(6):1981–1997, 2021. 2, 5
work page 1981
-
[7]
P. Grother, M. Ngan, and K. Hanaoka. Face recognition vendor test (FRVT) part 2: Identification. Technical Report NIST.IR.8238, National Institute of Standards and Technol- ogy, 2019. 2
work page 2019
-
[8]
Y . Guo, L. Zhang, Y . Hu, X. He, and J. Gao. MS-Celeb-1M: A dataset and benchmark for large-scale face recognition. In Proceedings of the European Conference on Computer Vi- sion (ECCV), 2016. 5
work page 2016
-
[9]
Biometric data interchange formats
ISO. Biometric data interchange formats. Technical Report ISO/IEC 19794, 2005. 3
work page 2005
-
[10]
J. Johnson, M. Douze, and H. J ´egou. Billion-scale similarity search with GPUs.IEEE Trans. on Big Data, 7(3):535–547,
-
[11]
V . Mura, L. Ghiani, G. L. Marcialis, F. Roli, D. A. Yam- bay, and S. A. Schuckers. LivDet 2015: Fingerprint liveness detection competition. InProceedings of the IEEE Interna- tional Conference on Biometrics (ICB), 2016. 5
work page 2015
-
[12]
The Aadhaar (Targeted Delivery of Financial and Other Subsidies, Benefits and Services) Act
Parliament of India. The Aadhaar (Targeted Delivery of Financial and Other Subsidies, Benefits and Services) Act. https://uidai.gov.in/en/legal-framework/ aadhaar-act.html, 2016. 1
work page 2016
-
[13]
The Digital Personal Data Protec- tion Act.https://www.dpdpa.com/DPDPA_2023_ official.pdf, 2023
Parliament of India. The Digital Personal Data Protec- tion Act.https://www.dpdpa.com/DPDPA_2023_ official.pdf, 2023. 1
work page 2023
-
[14]
G. W. Quinn, J. R. Matey, and P. J. Grother. Irex ix part one, performance of iris recognition algorithms. Technical re- port, National Institute of Standards and Technology (NIST), Gaithersburg, MD, 2018. 2
work page 2018
-
[15]
A. Ross and A. K. Jain. Information fusion in biometrics. Pattern Recognition Letters, 24:2115–2125, 2003. 2
work page 2003
-
[16]
F. Schroff, D. Kalenichenko, and J. Philbin. FaceNet: A uni- fied embedding for face recognition and clustering. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 2
work page 2015
-
[17]
E. Tabassi, C. Wilson, and C. Watson. NFIQ: NIST finger- print image quality. Technical Report NIST.IR.7151, Na- tional Institute of Standards and Technology, 2004. 2, 4
work page 2004
- [18]
-
[19]
Biometrics design stan- dards for UID applications
UIDAI Committee on Biometrics. Biometrics design stan- dards for UID applications. Technical report, Dec. 2009. 3
work page 2009
-
[20]
C. Wang, A. Bochkovskiy, and H. Liao. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. InProc. IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2023. 4
work page 2023
- [21]
-
[22]
World Population Review. Total population by country. Technical report, 2026. 9 10
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.