Recognition: 2 theorem links
· Lean TheoremPre-trained Tabular Foundation Models as Versatile Summary Networks for Neural Posterior Estimation
Pith reviewed 2026-05-11 02:56 UTC · model grok-4.3
The pith
A pre-trained TabPFN model serves as an effective fixed summary network for neural posterior estimation across many simulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabPFN can function as a training-free summary network for simulator outputs in simulation-based inference. When combined with normalizing flows as the inference head, this PFN-NPE setup matches or exceeds established posterior approximation techniques, and diagnostic tests confirm that the summaries retain useful information about posterior means and marginal distributions, though joint structure may be harder to capture.
What carries the argument
PFN-NPE recipe that fixes a pre-trained TabPFN encoder to produce summaries of observations and pairs them with a downstream inference head such as normalizing flows.
If this is right
- The summary network does not require retraining when applied to a new inference problem.
- TabPFN summaries often preserve information about posterior location and marginal distributions.
- Performance remains competitive with methods that train summary and inference components jointly.
- The inference head can be swapped depending on the needs of each specific task.
- Summaries may recover marginals well even when they do not fully capture dependencies in the joint posterior.
Where Pith is reading between the lines
- The success of broad tabular pre-training points to features that transfer across different inference settings.
- Modularity opens the possibility of pairing the same summaries with alternative inference heads for varied approximation goals.
- Addressing gaps in joint structure might benefit from adjustments in how summaries are fed to the inference head.
- Application to real-world simulators outside current benchmarks would test how far the training-free property extends.
Load-bearing premise
Summaries produced by TabPFN from its broad pre-training will contain enough relevant information for accurate posterior estimation in a wide variety of simulation-based inference problems.
What would settle it
If PFN-NPE yields substantially higher error in approximating true posteriors than jointly trained summary networks across standard SBI benchmarks, the claim that TabPFN summaries are reliably effective would not hold.
Figures














read the original abstract
In this work, we study TabPFN as a training-free, modular summary network for simulation-based Bayesian inference (SBI). Tabular foundation models such as TabPFN are pretrained on broad families of synthetic tabular data-generating processes and adapt at test time through in-context learning, making them natural candidates for SBI, where posterior estimation often depends on learning informative summaries of simulated observations. We propose PFN-NPE: a general recipe that uses a pretrained TabPFN encoder as a fixed summary network for simulator outputs, then pairs the resulting summaries with a downstream inference head chosen for the problem. With normalizing flows as the default inference head, PFN-NPE matches established posterior approximation methods and sometimes outperforms them. More importantly, diagnostic probes show that the TabPFN-derived summaries often preserve useful posterior location and marginal information. These analyses also reveal a limitation in that TabPFN-derived summaries may struggle to represent the joint posterior structure even when the marginals are well recovered. Still, our experiments show that TabPFN can serve as an effective summary network across a diverse set of SBI settings, with the inference network left modular and task-dependent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PFN-NPE, which uses a pre-trained TabPFN encoder as a fixed, training-free summary network for simulator outputs in simulation-based Bayesian inference. These summaries are paired with a modular downstream inference head (default: normalizing flows). The central claims are that PFN-NPE matches or outperforms established SBI methods on diverse tasks, and that diagnostic probes confirm the summaries preserve useful posterior location and marginal information, while acknowledging that joint posterior structure may be incompletely represented.
Significance. If the empirical results hold, the work demonstrates a practical way to leverage tabular foundation models for SBI summary networks without task-specific training or fine-tuning. The modular design and explicit diagnostic probes on marginal vs. joint information are strengths that could inform future use of pre-trained encoders in inference pipelines.
major comments (2)
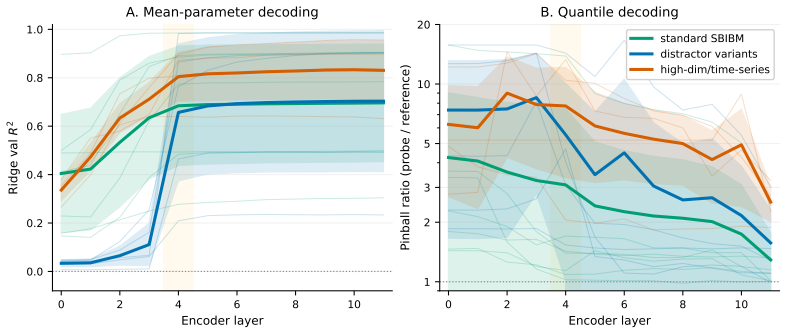
- [Abstract and §4] Abstract and experimental results section: The claim that PFN-NPE 'matches established posterior approximation methods and sometimes outperforms them' is load-bearing for the contribution, yet the abstract provides no quantitative metrics, baseline details, run counts, or error analysis. Given the paper's own statement that summaries 'may struggle to represent the joint posterior structure even when the marginals are well recovered,' direct evidence on joint posterior quality (e.g., via C2ST, MMD, or coverage on full posteriors) is required to substantiate competitiveness with baselines.
- [§3 and §4.2] §3 and §4.2: The assumption that TabPFN embeddings from in-context learning on broad synthetic tabular DGPs are sufficiently informative statistics for arbitrary SBI simulator outputs (without any fine-tuning) is central to the training-free claim. The marginal/location probes are useful but do not address whether lost dependence information prevents the downstream flow from recovering accurate joint posteriors; an ablation or counter-example on a task with strong parameter dependencies would strengthen or qualify this.
minor comments (2)
- [§3] Notation for the TabPFN encoder output and its dimensionality should be introduced explicitly in the method section to improve readability when describing the inference head.
- [§4] Figure captions for the diagnostic probe plots would benefit from explicit mention of which SBI tasks are shown and what 'preservation' thresholds are used.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript to incorporate additional quantitative details and analyses where feasible.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and experimental results section: The claim that PFN-NPE 'matches established posterior approximation methods and sometimes outperforms them' is load-bearing for the contribution, yet the abstract provides no quantitative metrics, baseline details, run counts, or error analysis. Given the paper's own statement that summaries 'may struggle to represent the joint posterior structure even when the marginals are well recovered,' direct evidence on joint posterior quality (e.g., via C2ST, MMD, or coverage on full posteriors) is required to substantiate competitiveness with baselines.
Authors: We agree that the abstract would be strengthened by including key quantitative metrics, baseline information, and run details. In the revised manuscript, we have updated the abstract to report average C2ST scores, log-probability differences, and the number of independent runs across tasks, along with brief baseline descriptions. Regarding joint posterior quality, our original §4.2 already includes marginal and location probes while explicitly noting limitations in joint structure. To provide direct evidence, we have added C2ST, MMD, and coverage metrics for the full joint posteriors in the revised experimental section, which support that PFN-NPE remains competitive with baselines on the evaluated tasks despite the acknowledged limitations. revision: yes
-
Referee: [§3 and §4.2] §3 and §4.2: The assumption that TabPFN embeddings from in-context learning on broad synthetic tabular DGPs are sufficiently informative statistics for arbitrary SBI simulator outputs (without any fine-tuning) is central to the training-free claim. The marginal/location probes are useful but do not address whether lost dependence information prevents the downstream flow from recovering accurate joint posteriors; an ablation or counter-example on a task with strong parameter dependencies would strengthen or qualify this.
Authors: We concur that the marginal and location probes, while informative, leave open questions about dependence structures. The training-free claim rests on TabPFN's broad pretraining enabling useful embeddings without task-specific updates, which our experiments support across diverse simulators. To address the dependence concern directly, we have added an ablation study in the revised §4.2 using a task with strong parameter dependencies (a multivariate Gaussian with high correlations). Results show partial recovery of joint structure by the downstream flow, qualifying that some dependence information may be lost but that the modular design still yields competitive posteriors without fine-tuning the encoder. revision: yes
Circularity Check
No circularity; independent pre-trained model and modular inference head.
full rationale
The paper's central recipe (PFN-NPE) takes a fixed, externally pre-trained TabPFN encoder as summary network and pairs it with a separately trained downstream inference head (e.g., normalizing flow). No derivation step reduces by construction to its own inputs, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation chain. The TabPFN component originates from prior independent work; the present manuscript only evaluates its use as a frozen summary extractor on SBI benchmarks. All reported diagnostics and performance comparisons are external to the construction of the summaries themselves.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose PFN-NPE: a general recipe that uses a pretrained TabPFN encoder as a fixed summary network for simulator outputs, then pairs the resulting summaries with a downstream inference head chosen for the problem.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
diagnostic probes show that the TabPFN-derived summaries often preserve useful posterior location and marginal information... may struggle to represent the joint posterior structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2020, Proceedings of the National Academy of Science, 117, 30055, doi: 10.1073/pnas.1912789117
Kyle Cranmer and Johann Brehmer and Gilles Louppe , title =. Proceedings of the National Academy of Sciences , volume =. 2020 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.1912789117 , abstract =
-
[2]
Papamakarios, George and Murray, Iain , booktitle =. Fast
-
[3]
Proceedings of the 36th International Conference on Machine Learning , pages =
Automatic Posterior Transformation for Likelihood-Free Inference , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
work page 2019
-
[4]
Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =
Benchmarking Simulation-Based Inference , author =. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =. 2021 , editor =
work page 2021
-
[5]
Durkan, Conor and Bekasov, Artur and Murray, Iain and Papamakarios, George , booktitle =. Neural Spline Flows , url =
-
[6]
Flow Matching for Scalable Simulation-Based Inference , url =
Wildberger, Jonas and Dax, Maximilian and Buchholz, Simon and Green, Stephen and Macke, Jakob H and Sch\". Flow Matching for Scalable Simulation-Based Inference , url =. Advances in Neural Information Processing Systems , editor =
- [7]
-
[8]
Amortized In-Context Bayesian Posterior Estimation , author=. 2025 , eprint=
work page 2025
-
[9]
Sequential Neural Likelihood: Fast Likelihood-free Inference with Autoregressive Flows , author =. Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =. 2019 , editor =
work page 2019
-
[10]
Likelihood-free MCMC with Amortized Approximate Ratio Estimators , author=. 2020 , eprint=
work page 2020
-
[11]
Proceedings of the 37th International Conference on Machine Learning , pages =
On Contrastive Learning for Likelihood-free Inference , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
work page 2020
-
[12]
Transactions on Machine Learning Research , issn=
A Crisis In Simulation-Based Inference? Beware, Your Posterior Approximations Can Be Unfaithful , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
work page 2022
-
[13]
Talts, Sean and Betancourt, Michael and Simpson, Daniel and Vehtari, Aki and Gelman, Andrew , journal =. Validating. 2018 , eprint =
work page 2018
-
[14]
Revisiting Classifier Two-Sample Tests
Revisiting Classifier Two-Sample Tests , author =. International Conference on Learning Representations (ICLR) , year =. 1610.06545 , archivePrefix =
-
[15]
Sampling-Based Accuracy Testing of Posterior Estimators for General Inference , author =. arXiv preprint , year =. 2302.03026 , archivePrefix =
-
[16]
Simulation-based Inference for High-dimensional Data using Surjective Sequential Neural Likelihood Estimation , author =. arXiv preprint , year =. 2308.01054 , archivePrefix =
-
[17]
Compositional simulation-based inference for time series , author =. arXiv preprint , year =. 2411.02728 , archivePrefix =
-
[18]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models , author=. ArXiv , year=
-
[19]
Transformers can do bayesian inference, 2024
M. Transformers Can Do. International Conference on Learning Representations (ICLR) , year =. 2112.10510 , archivePrefix =
-
[20]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second , author=. 2023 , eprint=
work page 2023
-
[21]
Accurate predictions on small data with a tabular foundation model , author=. Nature , year=
-
[22]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Qu, Jingang and Holzm\". Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
work page 2025
-
[23]
From Tables to Time: Extending TabPFN-v2 to Time Series Forecasting , author=. 2026 , eprint=
work page 2026
-
[24]
Proceedings of the 40th International Conference on Machine Learning , pages =
Statistical Foundations of Prior-Data Fitted Networks , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[25]
Effortless, Simulation-Efficient Bayesian Inference using Tabular Foundation Models , author=. 2025 , eprint=
work page 2025
-
[26]
TabPFN Through The Looking Glass: An interpretability study of TabPFN and its internal representations , author=. 2026 , eprint=
work page 2026
-
[27]
Interpretable Machine Learning for TabPFN , ISBN=
Rundel, David and Kobialka, Julius and von Crailsheim, Constantin and Feurer, Matthias and Nagler, Thomas and Rügamer, David , year=. Interpretable Machine Learning for TabPFN , ISBN=. doi:10.1007/978-3-031-63797-1_23 , booktitle=
- [28]
-
[29]
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
work page 2018
-
[30]
A Structural Probe for Finding Syntax in Word Representations
Hewitt, John and Manning, Christopher D. A Structural Probe for Finding Syntax in Word Representations. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1419
-
[31]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[32]
Advances in Neural Information Processing Systems 35 , year=
Matryoshka Representation Learning , author=. Advances in Neural Information Processing Systems 35 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.