Recognition: no theorem link
Video Understanding Reward Modeling: A Robust Benchmark and Performant Reward Models
Pith reviewed 2026-05-11 02:14 UTC · model grok-4.3
The pith
A new benchmark and large automated preference dataset enable training of state-of-the-art video understanding reward models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
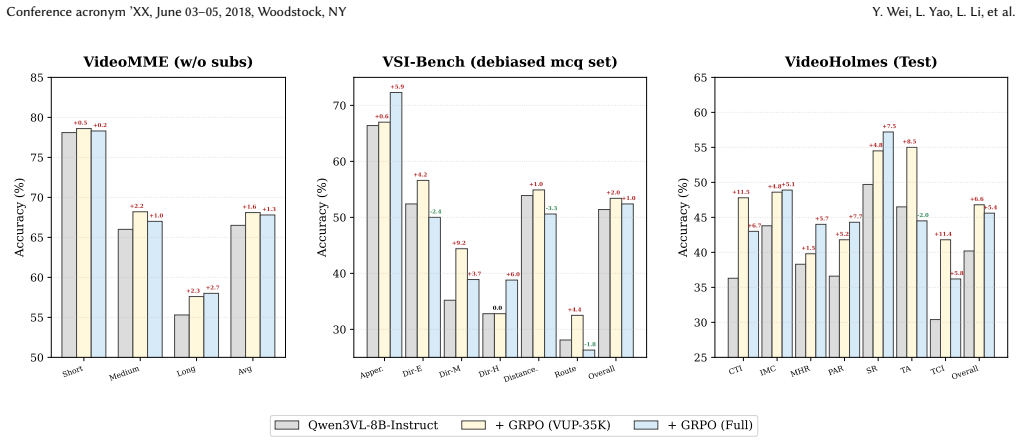
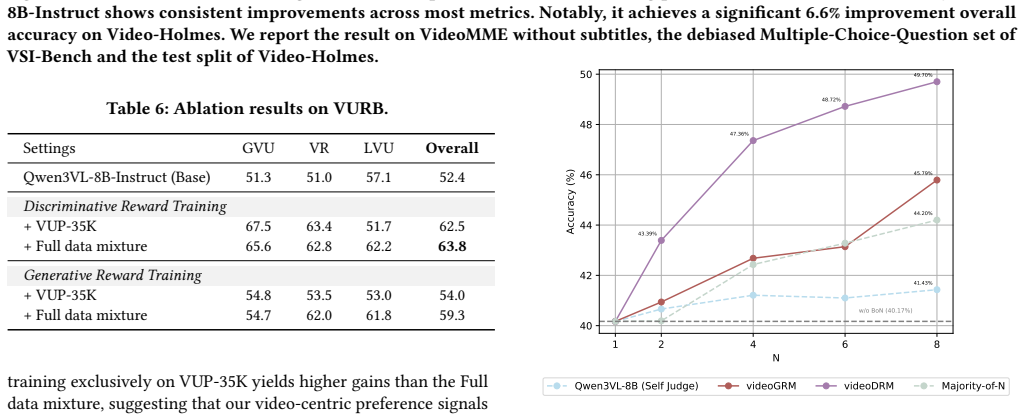
We introduce the Video Understanding Reward Bench (VURB), a benchmark of 2,100 preference pairs equipped with long chain-of-thought reasoning traces averaging 1,143 tokens and evaluated by majority voting across general, long, and reasoning-oriented video tasks. We further construct the Video Understanding Preference Dataset (VUP-35K) through a fully automated pipeline that supplies large-scale, high-quality supervision. Training VideoDRM and VideoGRM on this data produces state-of-the-art performance on both VURB and VideoRewardBench, with additional gains in best-of-N test-time scaling and improved model reasoning capability.
What carries the argument
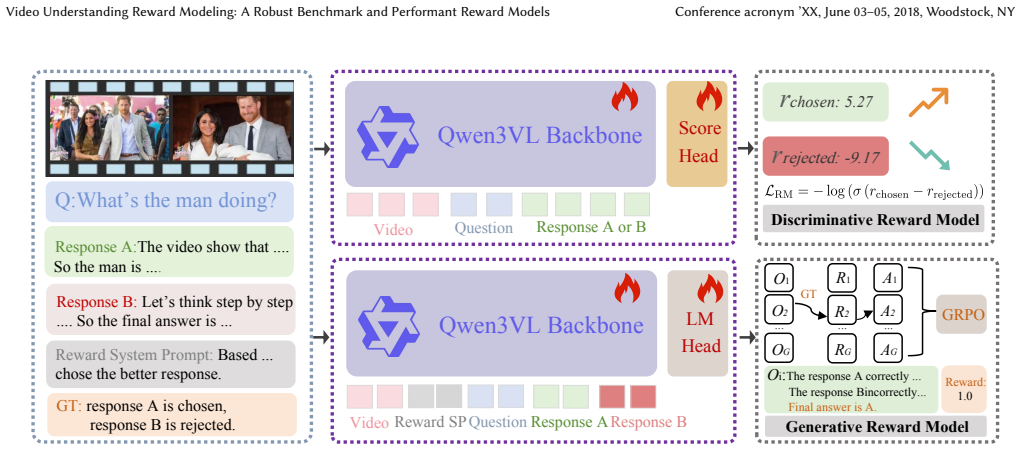
VURB and VUP-35K, which supply structured video preference pairs together with long chain-of-thought traces for training a discriminative reward model (VideoDRM) and a generative reward model (VideoGRM).
If this is right
- VUP-35K data directly improves both reward accuracy and the reasoning capability of the resulting models.
- VideoDRM and VideoGRM deliver measurable gains when used for best-of-N selection at test time.
- The same automated construction method can be applied to expand the dataset size or add new video task categories.
- Majority-voting evaluation on long reasoning traces provides a more stable signal than single-annotator scoring for video reward training.
Where Pith is reading between the lines
- If the automated traces prove reliable, similar pipelines could reduce human annotation costs across other multimodal reward modeling domains.
- The models could be tested as verifiers inside video generation loops to improve output quality without retraining the generator.
- Long CoT traces in preference data may transfer to training video understanding agents that explain their decisions.
Load-bearing premise
The fully automated pipeline produces high-quality, unbiased preference data and reliable long chain-of-thought traces that can train robust reward models without human oversight.
What would settle it
Human raters finding that the automated preference pairs in VUP-35K or VURB systematically disagree with human judgments on the same video understanding tasks would falsify the claim that the trained models are robust.
Figures



read the original abstract
Multimodal reward models have advanced substantially in text and image domains, yet progress in video understanding reward modeling remains severely limited by the lack of robust evaluation benchmarks and high-quality preference data. To address this, we propose a unified framework spanning benchmark design, data construction, and reward model training. We introduce Video Understanding Reward Bench (VURB), a benchmark featuring 2,100 preference pairs with long chain-of-thought reasoning traces (averaging 1,143 tokens) and majority voting evaluation across general, long, and reasoning-oriented video tasks. We further construct Video Understanding Preference Dataset (VUP-35K) via a fully automated pipeline, providing large-scale high-quality supervision for video reward training. Building on the data, we train VideoDRM and VideoGRM, a discriminative and a generative reward model, both achieving state-of-the-art performance on VURB and VideoRewardBench. Further analysis confirms that VUP-35K enhances both reward performance and model reasoning capability, while VideoDRM and VideoGRM yield significant gains under best-of-$N$ test-time scaling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Video Understanding Reward Bench (VURB) containing 2,100 preference pairs with long chain-of-thought traces (avg. 1,143 tokens) and majority-vote evaluation across general, long, and reasoning video tasks. It also presents the VUP-35K preference dataset built via a fully automated pipeline and trains two models—VideoDRM (discriminative) and VideoGRM (generative)—that are reported to achieve state-of-the-art results on both VURB and the external VideoRewardBench. Additional experiments examine best-of-N scaling and reasoning improvements attributable to the new data.
Significance. If the automated preference labels and CoT traces prove reliable, the work would meaningfully advance multimodal reward modeling for video by supplying a dedicated benchmark, a large-scale training resource, and two performant models. The emphasis on long reasoning traces and test-time scaling analysis represents a constructive step beyond standard scalar reward modeling.
major comments (1)
- [§3.2 and Abstract] §3.2 (VUP-35K construction) and Abstract: the headline SOTA claims for VideoDRM and VideoGRM rest entirely on preference pairs and long CoT traces produced by the fully automated pipeline. No quantitative data-quality metrics, inter-annotator agreement figures, or human validation results are reported for either VUP-35K or the VURB test set. Because every performance number, scaling curve, and reasoning improvement flows directly from these labels, the absence of validation constitutes a load-bearing gap that must be addressed before the central claims can be accepted.
minor comments (2)
- [Abstract] The abstract states that VURB uses 'majority voting evaluation' but supplies neither the number of voters nor the exact aggregation protocol; this detail should be added for reproducibility.
- [Results section] Table or figure captions that report SOTA numbers should explicitly state the evaluation split (e.g., VURB test vs. VideoRewardBench) and whether the same automated labels were used for both training and the VURB test set.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback. We address the major comment on data validation below.
read point-by-point responses
-
Referee: [§3.2 and Abstract] §3.2 (VUP-35K construction) and Abstract: the headline SOTA claims for VideoDRM and VideoGRM rest entirely on preference pairs and long CoT traces produced by the fully automated pipeline. No quantitative data-quality metrics, inter-annotator agreement figures, or human validation results are reported for either VUP-35K or the VURB test set. Because every performance number, scaling curve, and reasoning improvement flows directly from these labels, the absence of validation constitutes a load-bearing gap that must be addressed before the central claims can be accepted.
Authors: We agree that the absence of explicit human validation or inter-annotator agreement metrics represents a gap in the current manuscript. The VUP-35K construction relies on a fully automated pipeline using strong multimodal models to generate preference pairs and long CoT traces, while VURB employs majority-vote evaluation for robustness. The SOTA results on the independent external VideoRewardBench provide supporting evidence that the training data yields effective reward models. In the revised manuscript we will add a new subsection in §3.2 reporting human validation on sampled subsets of both VUP-35K and VURB (including agreement rates with automated labels) together with any available consistency metrics from the pipeline. This will directly address the concern. revision: yes
Circularity Check
No circularity: purely empirical ML pipeline with independent benchmark evaluation
full rationale
The paper introduces VURB as a held-out benchmark (2,100 pairs) and VUP-35K as separate training data constructed via automated pipeline, then trains VideoDRM/VideoGRM and reports measured performance on VURB plus the external VideoRewardBench. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. All results are empirical measurements on explicitly separated data splits, satisfying the self-contained criterion with no reductions to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Ralph Allan Bradley and Milton E Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika39, 3/4 (1952), 324–345
work page 1952
- [3]
-
[4]
Zhaorun Chen, Zichen Wen, Yichao Du, Yiyang Zhou, Chenhang Cui, Siwei Han, Zhenzhen Weng, Chaoqi Wang, Zhengwei Tong, Leria HUANG, et al. 2024. MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to- Image Generation?. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
work page 2024
- [5]
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S Liang, and Tatsunori B Hashimoto. 2023. Al- pacafarm: A simulation framework for methods that learn from human feedback. Advances in Neural Information Processing Systems36 (2023), 30039–30069
work page 2023
-
[8]
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Benyou Wang, and Xiangyu Yue. 2025. Video-R1: Reinforcing Video Reasoning in MLLMs.arXiv preprint arXiv:2503.21776(2025)
work page internal anchor Pith review arXiv 2025
-
[9]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24108–24118
work page 2025
-
[10]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al . 2025. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062(2025)
work page internal anchor Pith review arXiv 2025
-
[11]
Wenyi Hong, Yean Cheng, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, and Jie Tang. 2025. Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models. InProceedings of the Computer Vision and Pattern Recognition Conference. 8450–8460
work page 2025
- [12]
-
[13]
Jongwoo Ko, Sungnyun Kim, Sungwoo Cho, and Se-Young Yun. 2025. Flex- Judge: Text-Only Reasoning Unleashes Zero-Shot Multimodal Evaluators. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
work page 2025
-
[14]
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, Lester James Validad Mi- randa, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. 2025. Rewardbench: Evaluating reward models for language modeling. InFindings of the Association for Computational Linguistics: NAACL
work page 2025
-
[15]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. 2024. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22195–22206
work page 2024
-
[16]
Lei Li, Yuancheng Wei, Zhihui Xie, Xuqing Yang, Yifan Song, Peiyi Wang, Chenxin An, Tianyu Liu, Sujian Li, Bill Yuchen Lin, Lingpeng Kong, and Qi Liu. 2025. VL-RewardBench: A Challenging Benchmark for Vision-Language Generative Reward Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 24657–24668
work page 2025
-
[17]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing. 5971–5984
work page 2024
-
[18]
Runtao Liu, Haoyu Wu, Ziqiang Zheng, Chen Wei, Yingqing He, Renjie Pi, and Qifeng Chen. 2025. Videodpo: Omni-preference alignment for video diffusion gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference. 8009–8019
work page 2025
- [19]
- [20]
-
[21]
Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A Smith, Hannaneh Hajishirzi, and Nathan Lambert. 2025. Rewardbench 2: Advancing reward model evaluation.arXiv preprint arXiv:2506.01937(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
work page 2022
-
[23]
Shu Pu, Yaochen Wang, Dongping Chen, Yuhang Chen, Guohao Wang, Qi Qin, Zhongyi Zhang, Zhiyuan Zhang, Zetong Zhou, Shuang Gong, et al. 2025. Judge anything: Mllm as a judge across any modality. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5742–5753
work page 2025
-
[24]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al
-
[26]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Enxin Song, Wenhao Chai, Weili Xu, Jianwen Xie, Yuxuan Liu, and Gaoang Wang. 2025. Video-mmlu: A massive multi-discipline lecture understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision. 6099–6113
work page 2025
- [28]
-
[29]
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, et al. 2024. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9440–9450
work page 2024
-
[30]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. InternVL3. 5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency.arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. 2025. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22958–22967
work page 2025
- [32]
- [33]
- [34]
-
[35]
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. 2025. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236(2025)
work page internal anchor Pith review arXiv 2025
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
work page 2022
- [37]
- [38]
- [39]
-
[40]
Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, and Chunyuan Li. 2025. Llava-critic: Learning to evaluate mul- timodal models. InProceedings of the Computer Vision and Pattern Recognition Conference. 13618–13628
work page 2025
-
[41]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al . 2026. Visionreward: Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Y. Wei, L. Yao, L. Li, et al. Fine-grained multi-dimensional human preference learning for image and video generation. InProceedings of the AAAI Conferenc...
work page 2026
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
-
[44]
InProceedings of the Computer Vision and Pattern Recognition Conference
Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference. 10632–10643
- [45]
-
[46]
Shuyi Zhang, Xiaoshuai Hao, Yingbo Tang, Lingfeng Zhang, Pengwei Wang, Zhongyuan Wang, Hongxuan Ma, and Shanghang Zhang. 2025. Video-cot: A comprehensive dataset for spatiotemporal understanding of videos based on chain-of-thought. InProceedings of the 33rd ACM International Conference on Multimedia. 12745–12752
work page 2025
-
[47]
Yifan Zhang, Tao Yu, Haochen Tian, Chaoyou Fu, Peiyan Li, Jianshu Zeng, Wulin Xie, Yang Shi, Huanyu Zhang, Junkang Wu, et al. 2025. MM-RLHF: The Next Step Forward in Multimodal LLM Alignment. InInternational Conference on Machine Learning. PMLR, 76625–76654
work page 2025
- [48]
- [49]
- [50]
-
[51]
Yilun Zhao, Haowei Zhang, Lujing Xie, Tongyan Hu, Guo Gan, Yitao Long, Zhiyuan Hu, Weiyuan Chen, Chuhan Li, Zhijian Xu, et al. 2025. Mmvu: Measuring expert-level multi-discipline video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference. 8475–8489
work page 2025
- [52]
-
[53]
Haotian Zhou, Tingkai Liu, Qianli Ma, Yufeng Zhang, Jianbo Yuan, Pengfei Liu, Yang You, and Hongxia Yang. 2025. Davir: Data selection via implicit reward for large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9220–9237. Video Understanding Reward Modeling: A Robust Benc...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.