Recognition: no theorem link
Where's the Plan? Locating Latent Planning in Language Models with Lightweight Mechanistic Interventions
Pith reviewed 2026-05-11 03:10 UTC · model grok-4.3
The pith
Only Gemma-3-27B uses future-rhyme signals at line boundaries to causally plan its word choices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
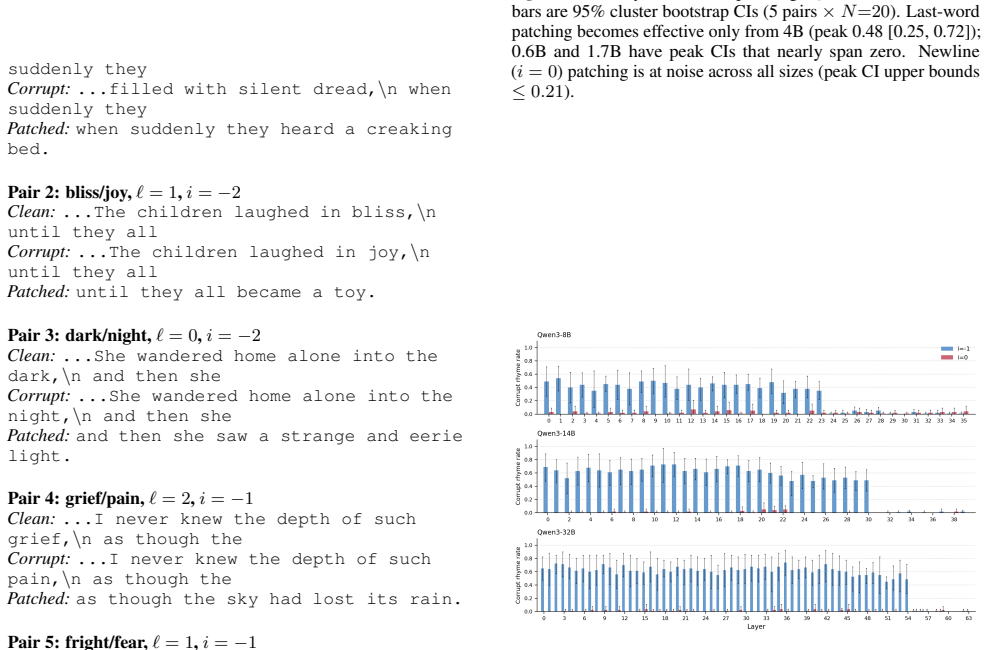
Future rhyme information becomes linearly decodable from activations at line boundaries, strengthening with model scale. Yet only in Gemma-3-27B does this encoding causally drive generation, via a handoff around layer 30 from relying on the rhyme word to relying on the boundary. Two-stage path patching localizes this to five attention heads recovering about 90 percent of the rhyme-routing capacity.
What carries the argument
Activation patching and path patching applied to the rhyming couplet task, revealing the handoff of causal planning to line-boundary encodings in one model.
If this is right
- Models that show strong probe signals may still not use those signals for generation.
- Planning representations may be architecture-specific and scale-dependent.
- Lightweight patching methods can identify planning sites efficiently.
Where Pith is reading between the lines
- This gap between decodability and causality suggests that interpretability should prioritize causal tests over representational ones.
- Similar planning handoffs might exist in other constrained tasks like mathematical reasoning or story coherence.
- Interventions at boundaries could improve model performance on long-form generation if applied during training.
Load-bearing premise
Rhyming-couplet completion acts as a general test of forward-looking structural constraint satisfaction rather than a narrow surface pattern.
What would settle it
If activation patching at the line boundary in Gemma-3-27B fails to affect rhyme accuracy, or if it succeeds in other models, the claim of unique causal reliance would not hold.
Figures


















read the original abstract
We study planning site formation in language models -- where internal representations of structurally-constrained future tokens form during the forward pass, and whether they causally drive generation. Using rhyming-couplet completion as a clean test of forward-looking constraint, we apply two lightweight methods (linear probing and activation patching) across Qwen3, Gemma-3, and Llama-3 at more than ten scales. Probing shows that future-rhyme information is linearly decodable at the line boundary, with signal that strengthens with scale in all three families. Activation patching reveals that only Gemma-3-27B causally relies on this encoding, exhibiting a handoff in which the causal driver migrates from the rhyme word to the line boundary around layer 30. Every other model we test conditions on the rhyme word throughout generation, with near-zero causal effect at the line boundary despite strong probe signal. We localize the Gemma-3-27B handoff to five attention heads through two-stage path patching that recover ~90% of the rhyme-routing capacity at the newline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the formation and causal use of internal representations for structurally constrained future tokens in language models during generation. Using rhyming-couplet completion as a test of forward-looking constraints, it applies linear probing and activation patching across Qwen3, Gemma-3, and Llama-3 families at multiple scales. Probing shows future-rhyme information is linearly decodable at line boundaries with scale-dependent signal strength, while patching reveals that only Gemma-3-27B causally relies on boundary encodings, with a handoff from the rhyme word around layer 30; this is localized to five attention heads via two-stage path patching recovering ~90% of rhyme-routing capacity. Other models show near-zero causal effect at boundaries despite strong probes, instead conditioning on the rhyme word throughout.
Significance. If the causal claims hold after addressing potential confounds, the work offers a lightweight, scalable approach to distinguish probe-detectable information from causally used representations in mechanistic interpretability. It highlights model-specific differences in handling structural constraints and provides concrete localization of planning-like behavior to specific heads in one large model, which could inform targeted interventions and scaling analyses. The cross-family, multi-scale design and use of path patching for head localization are particular strengths.
major comments (2)
- [Abstract] Abstract and task description: the central claim that rhyming-couplet completion provides a 'clean test of forward-looking constraint' is not yet supported, because the rhyme word from the first line remains fully in context. Models can satisfy the constraint via direct attention to that prior token at generation time without ever forming or using a representation of an upcoming constraint at the newline; this alternative is consistent with strong linear probes (which can decode the already-known rhyme) yet near-zero causal effects at the boundary in all models except Gemma-3-27B.
- [Abstract] Abstract: the reported handoff and five-head localization in Gemma-3-27B may reflect model-specific differences in routing an already-present cue rather than differences in latent planning capacity. Additional controls (e.g., ablating or masking the original rhyme token while preserving boundary representations) are needed to establish that the boundary encoding is used as a forward plan rather than a re-encoding of prior context.
minor comments (2)
- The abstract supplies no statistical tests, error bars, or baseline comparisons for the patching effects or the ~90% recovery claim; these should be added to allow assessment of whether the causal effects exceed what would be expected from token-frequency or surface cues.
- Notation for the two-stage path patching procedure and the exact definition of 'rhyme-routing capacity' should be clarified with a short methods diagram or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below, acknowledging where the manuscript requires clarification or additional controls, and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and task description: the central claim that rhyming-couplet completion provides a 'clean test of forward-looking constraint' is not yet supported, because the rhyme word from the first line remains fully in context. Models can satisfy the constraint via direct attention to that prior token at generation time without ever forming or using a representation of an upcoming constraint at the newline; this alternative is consistent with strong linear probes (which can decode the already-known rhyme) yet near-zero causal effects at the boundary in all models except Gemma-3-27B.
Authors: We agree that the rhyme word remains fully in context, so models could satisfy the constraint by direct attention to the prior token without forming a new representation at the newline. Our patching results are consistent with this interpretation for Qwen3, Llama-3, and smaller Gemma models, where causal effects localize to the rhyme word with near-zero boundary effects. The distinctive finding is the handoff observed only in Gemma-3-27B. We will revise the abstract and task description to frame rhyming-couplet completion as a testbed for detecting when models shift from direct cue reliance to boundary-based representations, rather than claiming it as an unequivocally clean test of forward-looking constraints. revision: partial
-
Referee: [Abstract] Abstract: the reported handoff and five-head localization in Gemma-3-27B may reflect model-specific differences in routing an already-present cue rather than differences in latent planning capacity. Additional controls (e.g., ablating or masking the original rhyme token while preserving boundary representations) are needed to establish that the boundary encoding is used as a forward plan rather than a re-encoding of prior context.
Authors: The referee correctly identifies that the handoff and five-head localization could reflect routing of an already-present cue. We will add the suggested controls in the revised manuscript: we will mask or ablate the original rhyme token while preserving boundary activations, then re-run activation patching and two-stage path patching to measure whether boundary representations retain independent causal influence on rhyme routing in Gemma-3-27B. These results will be reported alongside the existing findings. revision: yes
Circularity Check
Purely empirical mechanistic study with no derivation chain
full rationale
The paper reports experimental results from linear probing (to detect decodable future-rhyme information) and activation/path patching (to test causal reliance) across multiple model families and scales on a rhyming-couplet task. No equations, first-principles derivations, or parameter-fitting steps are presented that reduce any central claim to its own inputs by construction. All findings are measured against external model behaviors and interventions; the abstract and described methods contain no self-citations used as load-bearing uniqueness theorems, no ansatzes smuggled via prior work, and no renaming of known results as new organization. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Linear probes can extract causally relevant information from model activations
- domain assumption Activation patching and path patching reveal causal dependencies in the forward pass
Reference graph
Works this paper leans on
-
[1]
Transcoders find interpretable
Jacob Dunefsky and Philippe Chlenski and Neel Nanda , booktitle=. Transcoders find interpretable. 2024 , url=
work page 2024
-
[2]
Circuit Tracing: Revealing Computational Graphs in Language Models , author =. 2025 , howpublished =
work page 2025
-
[3]
The Thirteenth International Conference on Learning Representations , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
- [4]
-
[5]
What's the plan? Metrics for implicit planning in LLMs and their application to rhyme generation and question answering , author=. 2026 , eprint=
work page 2026
-
[6]
The Fourteenth International Conference on Learning Representations , year=
Latent Planning Emerges with Scale , author=. The Fourteenth International Conference on Learning Representations , year=
-
[7]
On the Biology of a Large Language Model , author =. 2025 , howpublished =
work page 2025
-
[8]
ParaScopes: What do Language Models Activations Encode About Future Text? , author=. 2025 , eprint=
work page 2025
-
[9]
McGrath, Thomas and Kapishnikov, Andrei and Tomašev, Nenad and Pearce, Adam and Wattenberg, Martin and Hassabis, Demis and Kim, Been and Paquet, Ulrich and Kramnik, Vladimir , year=. Acquisition of chess knowledge in AlphaZero , volume=. Proceedings of the National Academy of Sciences , publisher=. doi:10.1073/pnas.2206625119 , number=
-
[10]
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task , author=. 2024 , eprint=
work page 2024
-
[11]
Emergent Linear Representations in World Models of Self-Supervised Sequence Models , author=. 2023 , eprint=
work page 2023
-
[12]
Evidence of Learned Look-Ahead in a Chess-Playing Neural Network , author=. 2024 , eprint=
work page 2024
-
[13]
Discovering Latent Knowledge in Language Models Without Supervision , author=. 2023 , eprint=
work page 2023
-
[14]
Designing and Interpreting Probes with Control Tasks , author=. 2019 , eprint=
work page 2019
-
[15]
Locating and Editing Factual Associations in GPT , author=. 2022 , eprint=
work page 2022
- [16]
-
[17]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[18]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others , journal=. The
- [19]
-
[20]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2022 , eprint=
work page 2022
-
[21]
Let's Think Dot by Dot: Hidden Computation in Transformer Language Models , author=. 2024 , eprint=
work page 2024
-
[22]
Training Large Language Models to Reason in a Continuous Latent Space , author=. 2024 , eprint=
work page 2024
-
[23]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , year=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2211.00593 , archivePrefix=
work page internal anchor Pith review arXiv
-
[24]
Steering Language Models With Activation Engineering , author=. 2023 , eprint=
work page 2023
-
[25]
Refusal in Language Models Is Mediated by a Single Direction , author=. 2024 , eprint=
work page 2024
-
[26]
Localizing Model Behavior with Path Patching , author=. 2023 , eprint=
work page 2023
-
[27]
Causal Scrubbing: a method for rigorously testing interpretability hypotheses , author=. 2022 , howpublished=
work page 2022
- [28]
-
[29]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[30]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[31]
M. J. Kearns , title =
-
[32]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[33]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[34]
Suppressed for Anonymity , author=
-
[35]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[36]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.