Recognition: unknown
Deep Dreams Are Made of This: Visualizing Monosemantic Features in Diffusion Models
Pith reviewed 2026-05-12 01:13 UTC · model grok-4.3
The pith
Sparse autoencoders disentangle diffusion model activations so optimization can visualize distinct concepts such as human figures and roses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Latent visualization by optimization (LVO) extends feature visualization to diffusion models by first using sparse autoencoders to isolate monosemantic features from polysemantic layer activations. On Stable Diffusion 1.5 fine-tuned on the Style50 dataset, optimizing for individual SAE features generates clear images of concepts including diagonal compositions, human figures, roses, cables, and waterfall foam. These visualizations correlate with actual dataset examples that trigger the same features. The method includes time-step activity analysis, schedule-matched noise injection, prior initialization through feature steering, and adapted regularization. Regularization techniques transfer,
What carries the argument
Latent visualization by optimization (LVO), which optimizes latent inputs to activate isolated monosemantic features extracted by sparse autoencoders from diffusion model activations.
Load-bearing premise
The sparse autoencoders successfully isolate features that each correspond to one coherent concept rather than mixtures of several.
What would settle it
Optimizing for a given SAE feature produces images that bear no resemblance to the dataset examples known to activate that same feature at high levels.
Figures













read the original abstract
This paper proposes latent visualization by optimization (LVO), a mechanistic interpretability technique that extends feature visualization by optimization - originally developed for convolutional neural networks - to latent diffusion models. LVO employs sparse autoencoders (SAEs) to disentangle polysemantic layer representations into monosemantic features. Key contributions include latent-space optimization, time-step activity analysis, schedule-matched noise injection, prior initialization through feature steering, and suitable regularization strategies. We demonstrate the method on Stable Diffusion 1.5 fine-tuned on the Style50 dataset, showing that SAE features produce clear visualizations of recognizable concepts - including diagonal compositions, human figures, roses, cables, and waterfall foam - that correlate with dataset examples, while the baseline without disentanglement produces less coherent results. We further show that regularization techniques from pixel-space feature visualization transfer to the latent domain, though they require different configurations for the raw-layer and SAE variants. Compared to dataset examples and steering, LVO provides complementary insights by directly revealing what activates a feature rather than its downstream effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces Latent Visualization by Optimization (LVO), extending feature visualization by optimization to latent diffusion models via sparse autoencoders (SAEs) for disentangling polysemantic representations into monosemantic features. The method incorporates latent-space optimization, schedule-matched noise injection, time-step activity analysis, prior initialization through feature steering, and adapted regularization. Demonstrated on Stable Diffusion 1.5 fine-tuned on Style50, SAE features yield coherent visualizations of concepts (diagonal compositions, human figures, roses, cables, waterfall foam) that correlate with dataset examples, outperforming a non-SAE baseline; regularization from pixel-space methods transfers to latent space with adjusted configurations. LVO is positioned as complementary to dataset inspection and steering by directly revealing feature semantics.
Significance. If the visualizations faithfully capture monosemantic features, the work would advance mechanistic interpretability for diffusion models by providing a direct optimization-based inspection tool beyond downstream effects or dataset correlations. It explicitly builds on prior feature visualization and SAE techniques with clearly delineated components (LVO, time-step analysis, regularization transfer), offering qualitative demonstrations on a real fine-tuned model that highlight potential for model understanding and control in generative AI.
major comments (2)
- [§4 (Experiments/Results)] §4 (Experiments/Results): The central claim that SAE features are monosemantic and LVO visualizations faithfully represent specific concepts rests on qualitative image generations and visual correlations with Style50 samples. No quantitative monosemanticity checks (e.g., top-k activation analysis on held-out data, feature ablation/intervention tests, or purity metrics) are reported, which is load-bearing because the optimization pipeline (noise schedule, steering, regularization) could independently bias toward coherent outputs.
- [§3 (Method)] §3 (Method): The LVO pipeline combines schedule-matched noise, prior steering, and regularization transfer with SAE disentanglement, yet no ablation isolates the SAE contribution from these other elements. This undermines attribution of the coherence improvement over the non-SAE baseline specifically to monosemantic features rather than procedural choices.
minor comments (2)
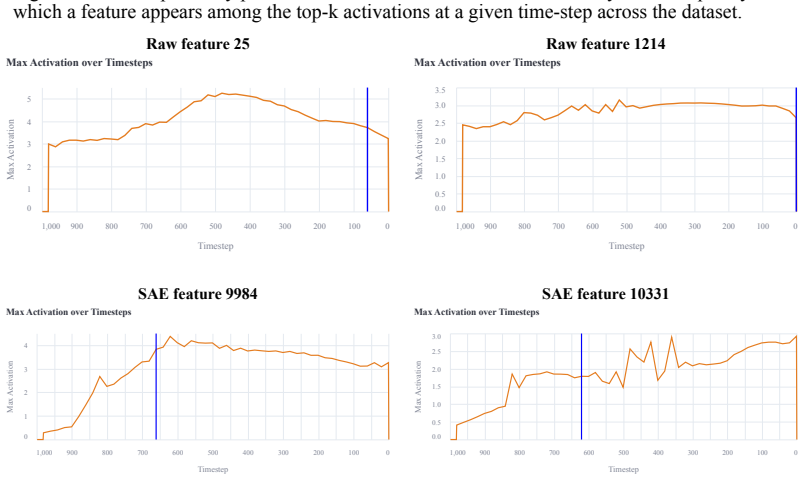
- [Abstract and §3] Abstract and §3: The description of time-step activity analysis is referenced but lacks sufficient detail on exact procedure and quantitative findings to allow independent assessment of its role.
- [Figure captions (throughout)] Figure captions (throughout): Captions could more explicitly label SAE vs. baseline images and note any post-processing to aid direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential of LVO to advance mechanistic interpretability in diffusion models. We address each major comment below, acknowledging the need for stronger evidence, and commit to revisions that will incorporate additional analyses and ablations.
read point-by-point responses
-
Referee: [§4 (Experiments/Results)] §4 (Experiments/Results): The central claim that SAE features are monosemantic and LVO visualizations faithfully represent specific concepts rests on qualitative image generations and visual correlations with Style50 samples. No quantitative monosemanticity checks (e.g., top-k activation analysis on held-out data, feature ablation/intervention tests, or purity metrics) are reported, which is load-bearing because the optimization pipeline (noise schedule, steering, regularization) could independently bias toward coherent outputs.
Authors: We agree that the current evaluation is primarily qualitative and that quantitative monosemanticity checks would provide stronger support for the claims while addressing potential biases from the optimization components. Although qualitative demonstrations align with established practices in feature visualization, we will add quantitative analyses in the revised manuscript, including top-k activation purity metrics on held-out Style50 data and feature intervention tests. These will help confirm that the visualized concepts are specific to the SAE features rather than artifacts of the pipeline. revision: yes
-
Referee: [§3 (Method)] §3 (Method): The LVO pipeline combines schedule-matched noise, prior steering, and regularization transfer with SAE disentanglement, yet no ablation isolates the SAE contribution from these other elements. This undermines attribution of the coherence improvement over the non-SAE baseline specifically to monosemantic features rather than procedural choices.
Authors: The non-SAE baseline employs the identical LVO pipeline components (schedule-matched noise injection, prior steering via feature initialization, and adapted regularization) but without SAE-based disentanglement. This setup isolates the effect of monosemantic features on visualization coherence. To further strengthen attribution, we will include additional ablations in the revision that disable individual pipeline elements (e.g., steering or noise) both with and without the SAE, demonstrating that the primary gains derive from the disentangled representations. revision: yes
Circularity Check
No circularity: method proposal is self-contained with independent components
full rationale
The paper introduces LVO as an explicit extension of prior feature visualization work to diffusion models, using SAEs for disentanglement along with listed components (latent optimization, time-step analysis, schedule-matched noise, prior steering, regularization transfer). These are presented as new procedural elements without any reduction by construction to fitted parameters, self-defined quantities, or load-bearing self-citations. The central demonstration relies on qualitative visual outputs and dataset correlations rather than a mathematical derivation chain that loops back to its inputs. No equations or claims in the abstract or description exhibit self-definitional, fitted-prediction, or uniqueness-imported patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- regularization strengths and types
- SAE sparsity and training hyperparameters
axioms (2)
- domain assumption Sparse autoencoders can reliably disentangle polysemantic activations into monosemantic features in diffusion model layers.
- domain assumption Optimization in latent space with schedule-matched noise produces images that faithfully reflect the feature's meaning.
Reference graph
Works this paper leans on
-
[1]
Russell, Human Compatible: Artificial Intelligence and the Problem of Control
S. Russell, Human Compatible: Artificial Intelligence and the Problem of Control. Viking, 2019
work page 2019
-
[2]
Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases,
C. Olah, “Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases,” Transformer Circuits Thread, 2022
work page 2022
-
[3]
Going deeper into neural networks
A. Mordvintsev, C. Olah, and M. Tyka, “Going deeper into neural networks.” [Online]. Available: https:// research.google/blog/inceptionismgoingdeeperintoneuralnetworks/
-
[4]
C. Olah, A. Mordvintsev, and L. Schubert, “Feature Visualization,” Distill, 2017, doi: 10.23915/ distill.00007
work page 2017
-
[5]
Zoom in: An introduction to circuits
C. Olah, N. Cammarata, L. Schubert, G. Goh, M. Petrov, and S. Carter, “Zoom In: An Introduction to Circuits,” Distill, 2020, doi: 10.23915/distill.00024.001
-
[6]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learn ing,
T. Bricken et al., “Towards Monosemanticity: Decomposing Language Models With Dictionary Learn ing,” Transformer Circuits Thread, 2023
work page 2023
-
[7]
SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
B. Cywiński and K. Deja, “SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders.” [Online]. Available: https://arxiv.org/abs/2501.18052
-
[8]
Denoising Diffusion Probabilistic Models
J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models.” [Online]. Available: https:// arxiv.org/abs/2006.11239
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[9]
High-Resolution Image Synthesis with Latent Diffusion Models
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “HighResolution Image Synthesis with Latent Diffusion Models.” [Online]. Available: https://arxiv.org/abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Deconvolution and Checkerboard Artifacts,
A. Odena, V . Dumoulin, and C. Olah, “Deconvolution and Checkerboard Artifacts,” Distill, 2016, doi: 10.23915/distill.00003
-
[11]
Synthesizing the preferred inputs for neurons in neural networks via deep generator networks,
A. M. Nguyen, A. Dosovitskiy, J. Yosinski, T. Brox, and J. Clune, “Synthesizing the preferred inputs for neurons in neural networks via deep generator networks,” CoRR, 2016, [Online]. Available: http://arxiv. org/abs/1605.09304
-
[12]
A. Nguyen, J. Yosinski, and J. Clune, “Multifaceted Feature Visualization: Uncovering the Different Types of Features Learned By Each Neuron in Deep Neural Networks.” [Online]. Available: https://arxiv.org/ abs/1602.03616
-
[13]
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet,
A. Templeton et al., “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet,” Transformer Circuits Thread, 2024, [Online]. Available: https://transformercircuits.pub/2024/scalingm onosemanticity/index.html
work page 2024
-
[14]
Understanding Deep Image Representations by Inverting Them
A. Mahendran and A. Vedaldi, “Understanding Deep Image Representations by Inverting Them.” [On line]. Available: https://arxiv.org/abs/1412.0035
- [15]
-
[16]
Unlearn Canvas: Style50 finetuned model
OPTMLGroup, “Unlearn Canvas: Style50 finetuned model.” GitHub, 2018
work page 2018
-
[17]
UnlearnCanvas: Stylized Image Dataset for Enhanced Machine Unlearning Evaluation in Diffusion Models
Y . Zhang et al., “UnlearnCanvas: Stylized Image Dataset for Enhanced Machine Unlearning Evaluation in Diffusion Models.” [Online]. Available: https://arxiv.org/abs/2402.11846
-
[18]
Random Search for Hyper Parameter Optimization,
J. Bergstra and Y . Bengio, “Random Search for Hyper Parameter Optimization,” Journal of Machine Learning Research, vol. 13, no. 10, pp. 281–305, 2012, [Online]. Available: http://jmlr.org/papers/v13/ bergstra12a.html
work page 2012
-
[19]
An Overview of Early Vision in InceptionV1,
C. Olah, N. Cammarata, L. Schubert, G. Goh, M. Petrov, and S. Carter, “An Overview of Early Vision in InceptionV1,” Distill, 2020, doi: 10.23915/distill.00024.002. A Steering produces uninformative images The main text claims that steering reveals downstream effects rather than the cause of activation, and was uninformative for the features studied here. ...
-
[20]
All four are addressed in Sections 2–6, and Section 7 explicitly bounds the scope
Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: The abstract and Section 1 list the four contributions (proposing LVO, raw layer baseline, calibration study, complementary insight) and the empirical scope (Stable Diffusion 1.5 finetuned on Styl...
-
[21]
Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer: [Yes] Justification: Section 7 (Limitations) discusses the qualitative only evaluation, the single model / single layer / 30 channel scope, the possibility of multifaceted features, and the dependence on SAE quality
-
[22]
Theory assumptions and proofs Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof? Answer: [NA] Justification: The paper does not contain theoretical results
-
[23]
Code and configuration are released as supplementary material
Experimental result reproducibility Question: Does the paper fully disclose all the information needed to reproduce the main experimental results? Answer: [Yes] Justification: Section 2 specifies the algorithm; Section 3 specifies the model, layer, dataset, evaluation protocol, optimizer, learning rate, number of steps, and hardware; Section 4 reports the...
-
[24]
Open access to data and code Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results? Answer: [Yes] Justification: Source code, configuration files, and reproduction instructions are released at github.com/aszokalski/diffusion-deep-dream-research. All datasets an...
-
[25]
Experimental setting/details Question: Does the paper specify all the training and test details necessary to understand the results? Answer: [Yes] Justification: Section 3 reports the model, layer, dataset, evaluation protocol, optimizer (Adam), learning rate ( 0.05), number of steps ( 100), seed handling, and compute (single A100 GPU). 33 Section 4 repor...
-
[26]
Experiment statistical significance Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments? Answer: [No] Justification: Evaluation is qualitative. We instead report consistency across multiple activity peaks and across random seeds for each feature (S...
-
[27]
SAE training is reused from prior work and was not performed here
Experiments compute resources Question: Does the paper provide sufficient information on the computer resources needed to reproduce the experiments? Answer: [Yes] Justification: Section 3 reports the pervisualization cost ( 1 minute on a single A100 GPU at 100 Adam steps, learning rate 0.05) and notes that the full study, including hyperparameter sweeps,...
-
[28]
Code of ethics Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics? Answer: [Yes] Justification: The work uses publicly released models and datasets, introduces no humansubject component, and releases no new generative capability. See also Section 8
-
[29]
Broader impacts Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed? Answer: [Yes] Justification: Section 8 discusses the defensive profile (auditing, unlearning, content modera tion) and acknowledges the dual use risk that feature level interpretability could in principle help ...
-
[30]
Safeguards Question: Does the paper describe safeguards for responsible release of data or models that have a high risk for misuse? Answer: [NA] Justification: No new pretrained generators, datasets, or other highrisk assets are released. The visualization framework operates on the publicly released SAeUron SAEs and a Style50 fine tune of Stable Diffus...
-
[31]
All assets are cited at the point of use (Section 3) and used under their original licenses
Licenses for existing assets Question: Are the creators or original owners of assets used in the paper properly credited and are the license and terms of use explicitly mentioned and properly respected? Answer: [Yes] 34 Justification: The base Stable Diffusion 1.5 weights are released under the CreativeML Open RAILM license; the UnlearnCanvas dataset a...
-
[32]
No new datasets or pretrained models are released
New assets Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets? Answer: [Yes] Justification: We release the experiment framework as source code at github.com/aszokalski/ diffusion-deep-dream-research under a BSD 3 Clausestyle license, with a README, a Hydra configuration directory docum...
-
[33]
Crowdsourcing and research with human subjects Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants, screenshots, and details about compen sation? Answer: [NA] Justification: The paper does not involve crowdsourcing or research with human subjects
-
[34]
Institutional review board (IRB) approvals Question: Does the paper describe potential risks incurred by study participants and whether IRB approvals were obtained? Answer: [NA] Justification: The paper does not involve research with human subjects
-
[35]
Any LLM use was limited to writing assistance and does not affect scientific rigor or originality
Declaration of LLM usage Question: Does the paper describe the usage of LLMs if it is an important, original, or non standard component of the core methods in this research? Answer: [NA] Justification: No LLM is part of the core methodology. Any LLM use was limited to writing assistance and does not affect scientific rigor or originality. 35
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.