Recognition: 2 theorem links
· Lean TheoremSeBA: Semi-supervised few-shot learning via Separated-at-Birth Alignment for tabular data
Pith reviewed 2026-05-12 01:26 UTC · model grok-4.3
The pith
SeBA generates an output space improving feature-label relationships in semi-supervised few-shot tabular learning by splitting data into two views and aligning representations to nearest-neighbor matches without augmentations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SeBA is a joint-embedding framework that separates tabular inputs into two complementary views and aligns the representation of one view to the nearest-neighbor correspondences present in the other view, thereby constructing an output space whose feature-label relationship is measurably stronger than those obtained by augmentation-based self-supervised baselines.
What carries the argument
Separated-at-Birth Alignment (SeBA), a joint-embedding procedure that partitions each tabular instance into two independent views and forces one view's embeddings to reproduce the nearest-neighbor geometry observed in the second view.
Load-bearing premise
Tabular data admits a split into two independent complementary views that preserves semantics, and mirroring nearest-neighbor structure across views reliably strengthens the feature-label relationship in the resulting output space.
What would settle it
A direct measurement on a held-out tabular benchmark showing that the post-alignment output space exhibits no higher feature-label correlation (or downstream accuracy) than the best augmentation-based semi-supervised baseline.
Figures


read the original abstract
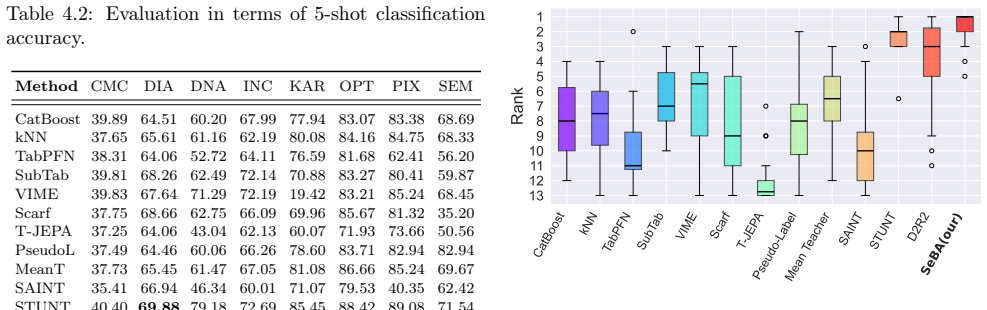
Learning from scarce labeled data with a larger pool of unlabeled samples, known as semi-supervised few-shot learning (SS-FSL), remains critical for applications involving tabular data in domains like medicine, finance, and science. The existing SS-FSL methods often rely on self-supervised learning (SSL) frameworks developed for vision or language, which assume the availability of a natural form of data augmentations. For tabular data, defining meaningful augmentations is non-trivial and can easily distort semantics, limiting the effectiveness of conventional SSL. In this work, we rethink SSL for tabular data and propose Separated-at-Birth Alignment (SeBA), a joint-embedding framework for SS-FSL that eliminates the dependence on augmentations. Our core idea is to separate the data into two independent, but complementary views and align the representations of one view to mirror the nearest-neighbor correspondence of the data in the second view. Our experimental evaluation supported by a theoretical analysis justifies that SeBA generates an output space, which improves the feature-label relationship. An experimental study conducted in various benchmark datasets demonstrates that SeBA achieves the state-of-the-art performance in the majority of cases, opening a new avenue for SS-FSL paradigm in the domain of tabular data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Separated-at-Birth Alignment (SeBA), a joint-embedding framework for semi-supervised few-shot learning (SS-FSL) on tabular data. It splits input features into two independent but complementary views and aligns the learned representation of one view to the nearest-neighbor correspondences observed in the second view, thereby eliminating reliance on data augmentations. The central claims are that a theoretical analysis justifies an improved feature-label relationship in the output space and that experiments on benchmark datasets show SeBA achieving state-of-the-art performance in the majority of cases.
Significance. If the central claims hold, the work offers a meaningful alternative to augmentation-based SSL for tabular SS-FSL, addressing a practical limitation in domains such as medicine and finance where semantic-preserving augmentations are hard to define. The attempt to supply both theoretical justification and empirical comparisons on multiple benchmarks is a positive contribution, though the absence of detailed derivations and experimental controls reduces the immediate strength of the result.
major comments (3)
- [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): The claim that SeBA produces an output space with improved feature-label relationships is undermined by circularity; the alignment objective is defined directly in terms of nearest-neighbor structure that is itself generated from the representations being learned, so the analysis does not independently demonstrate a reduction in any explicit measure such as conditional entropy or margin violation.
- [§3 (Method)] §3 (Method): The procedure for partitioning tabular columns into two independent yet complementary views is not specified (random, type-based, learned, or otherwise), yet this split is load-bearing for the assumption that nearest-neighbor relations in the second view supply a reliable supervisory signal without semantic distortion; for correlated or redundant features the split can readily produce uninformative or harmful correspondences.
- [§5 (Experiments)] §5 (Experiments): The SOTA claim rests on benchmark results, but the manuscript supplies neither error bars, explicit train/validation/test splits, nor a complete enumeration of baselines and hyper-parameter choices, making it impossible to verify robustness or rule out post-hoc selection effects.
minor comments (2)
- [§3] Notation for the two views and the alignment loss should be introduced with explicit equations early in §3 to improve readability.
- [Abstract / §1] The abstract and introduction would benefit from a concise statement of the exact split rule once it is defined in the method section.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments identify important areas for clarification and strengthening. We address each major comment below and will revise the manuscript to incorporate the necessary changes and additional details.
read point-by-point responses
-
Referee: [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): The claim that SeBA produces an output space with improved feature-label relationships is undermined by circularity; the alignment objective is defined directly in terms of nearest-neighbor structure that is itself generated from the representations being learned, so the analysis does not independently demonstrate a reduction in any explicit measure such as conditional entropy or margin violation.
Authors: We appreciate the referee pointing out the risk of circularity. The analysis in §4 is constructed around a cross-view setup: nearest-neighbor correspondences are computed from the second view and used to supervise alignment of the first view's representation. Because the two views are formed by disjoint feature partitions, the supervisory signal is not derived from the same representation being optimized. Nevertheless, we acknowledge that joint training introduces some dependence and that the current derivation does not explicitly bound conditional entropy or margin quantities. In the revision we will expand §4 with a clearer statement of the cross-view independence assumption, an explicit derivation relating the alignment loss to a reduction in label-conditional entropy in the joint output space, and a short discussion of the remaining limitations of the analysis. revision: partial
-
Referee: [§3 (Method)] §3 (Method): The procedure for partitioning tabular columns into two independent yet complementary views is not specified (random, type-based, learned, or otherwise), yet this split is load-bearing for the assumption that nearest-neighbor relations in the second view supply a reliable supervisory signal without semantic distortion; for correlated or redundant features the split can readily produce uninformative or harmful correspondences.
Authors: The referee is correct that the partitioning procedure must be stated explicitly. In the current manuscript the split is performed by randomly assigning columns to two equal-sized groups; the assumption is that tabular data typically contain redundant or correlated features so that each group remains informative. We agree that this choice requires justification and that highly correlated or redundant columns could degrade the supervisory signal. In the revised version we will (i) describe the random partitioning procedure in §3, (ii) add a short discussion of its rationale and potential failure modes, and (iii) include an ablation comparing random, type-based, and correlation-aware splits on the benchmark datasets to demonstrate that performance is not overly sensitive to the exact partitioning strategy. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments): The SOTA claim rests on benchmark results, but the manuscript supplies neither error bars, explicit train/validation/test splits, nor a complete enumeration of baselines and hyper-parameter choices, making it impossible to verify robustness or rule out post-hoc selection effects.
Authors: We fully agree that the experimental section must be made reproducible and that the current presentation is insufficient to support the SOTA claim. In the revision we will add: (i) mean and standard deviation over at least five independent runs with different random seeds, (ii) explicit description of the train/validation/test splits (including any stratification or public split identifiers) for every dataset, (iii) a complete table listing all baselines together with the hyper-parameter values or search ranges used, and (iv) the hyper-parameter grid searched for SeBA itself. These additions will allow readers to assess both statistical significance and the possibility of selection effects. revision: yes
Circularity Check
No significant circularity detected; derivation relies on independent experimental and theoretical support.
full rationale
The abstract and description define SeBA via an explicit split into complementary views followed by NN-based alignment of representations, then assert improved feature-label relationship via separate experimental evaluation plus theoretical analysis. No equations, self-citations, or fitted parameters are shown reducing the central claim to the input definition by construction. Benchmarks provide external grounding, and the split/alignment procedure is presented as a modeling choice rather than a tautology. This is the normal non-circular case.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tabular data can be separated into two independent but complementary views without loss of semantic information.
invented entities (1)
-
Separated-at-Birth Alignment (SeBA)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
separate the data into two independent, but complementary views and align the representations of one view to mirror the nearest-neighbor correspondence of the data in the second view
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
theoretical analysis for Gaussian data, which justifies that SeBA produces meaningful positive pairs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Jingtao Li and Lingjuan Lyu and Daisuke Iso and Chaitali Chakrabarti and Michael Spranger , booktitle=. Moco. 2023 , url=
work page 2023
-
[5]
Deep medicine: how artificial intelligence can make healthcare human again , author=
-
[6]
International Conference on Machine Learning , pages=
Weight uncertainty in neural network , author=. International Conference on Machine Learning , pages=. 2015 , organization=
work page 2015
-
[7]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
OneFlow: One-class flow for anomaly detection based on a minimal volume region , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[8]
2021 International Joint Conference on Neural Networks (IJCNN) , year=
Entropic Out-of-Distribution Detection , author=. 2021 International Joint Conference on Neural Networks (IJCNN) , year=
work page 2021
-
[9]
arXiv preprint arXiv:1906.09686 , year=
Quality of uncertainty quantification for Bayesian neural network inference , author=. arXiv preprint arXiv:1906.09686 , year=
-
[10]
International conference on machine learning , pages=
Probabilistic backpropagation for scalable learning of bayesian neural networks , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[11]
International Conference on Learning Representations , year=
Deep Anomaly Detection with Outlier Exposure , author=. International Conference on Learning Representations , year=
-
[12]
Deep patient: an unsupervised representation to predict the future of patients from the electronic health records , author=. Scientific reports , volume=. 2016 , publisher=
work page 2016
-
[13]
Applied Soft Computing (under review) , year=
Revisiting multiple instance neural networks , author=. Applied Soft Computing (under review) , year=
-
[14]
ICLR 2021-International Conference on Learning Representations , year=
not-MIWAE: Deep Generative Modelling with Missing not at Random Data , author=. ICLR 2021-International Conference on Learning Representations , year=
work page 2021
-
[15]
2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
MisConv: Convolutional Neural Networks for Missing Data , author=. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2022 , organization=
work page 2022
-
[16]
Journal of Chemical Information and Modeling , volume=
Practical applications of deep learning to impute heterogeneous drug discovery data , author=. Journal of Chemical Information and Modeling , volume=. 2020 , publisher=
work page 2020
-
[17]
Advances in neural information processing systems , volume=
A probabilistic u-net for segmentation of ambiguous images , author=. Advances in neural information processing systems , volume=
-
[18]
The Lung Image Database Consortium (LIDC) and Image Database Resource Initiative (IDRI): A completed reference database of lung nodules on CT scans , author=. Medical Physics , volume=
- [19]
-
[20]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer , author=. JAMA , volume=. 2017 , publisher=
work page 2017
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Dimensionality reduction by learning an invariant mapping , author=. CVPR , year=
-
[24]
Big self-supervised models are strong semi-supervised learners , author=. NeurIPS , year=
-
[25]
Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning , url =
Grill, Jean-Bastien and Strub, Florian and Altch\'. Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning , url =. Advances in Neural Information Processing Systems , editor =
-
[26]
Loss-based attention for deep multiple instance learning , author=. AAAI , year=
-
[27]
Nature Biomedical Engineering , year=
Data-efficient and weakly supervised computational pathology on whole-slide images , author=. Nature Biomedical Engineering , year=
-
[28]
Kernel Self-Attention for Weakly-supervised Image Classification using Deep Multiple Instance Learning , author=. WACV , year=
-
[29]
Multiple instance learning with graph neural networks , author=. arXiv:1906.04881 , year=
-
[30]
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classication , author=. arXiv:2106.00908 , year=
- [31]
-
[32]
Revisiting multiple instance neural networks , author=. Pattern Recognition , year=
- [33]
-
[34]
Support Vector Machines for Multiple-Instance Learning , author=. NeurIPS , year=
- [35]
-
[36]
Radiology Objects in COntext (ROCO): a multimodal image dataset , author=. Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis , pages=. 2018 , publisher=
work page 2018
-
[37]
Deep Learning Approach to Description and Classification of Fungi Microscopic Images , author =. PloS one , year =
-
[38]
Deep Learning Approach to Bacterial Colony Classification , author =. PloS one , year =
-
[39]
Deep Learning Classification of Bacteria Clones Explained by Persistence Homology , author =. IJCNN , year =
-
[40]
Three million images and morphological profiles of cells treated with matched chemical and genetic perturbations , author=. bioRxiv , year=
-
[41]
A radiogenomic dataset of non-small cell lung cancer , author=. Scientific data , volume=. 2018 , publisher=
work page 2018
-
[42]
The Cancer Imaging Archive , year=
Radiology data from the cancer genome atlas kidney renal clear cell carcinoma [TCGA-KIRC] collection , author=. The Cancer Imaging Archive , year=
-
[43]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Learning semantics-enriched representation via self-discovery, self-classification, and self-restoration , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2020 , organization=
work page 2020
-
[44]
Advances in Neural Information Processing Systems , volume=
Unsupervised Part Discovery from Contrastive Reconstruction , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
One Explanation Does Not Fit All:
Arya and others , year =. One Explanation Does Not Fit All:
-
[46]
Explanation and Justification in Machine Learning:
Biran and. Explanation and Justification in Machine Learning:
-
[47]
Neural machine translation by jointly learning to align and translate , booktitle =
Bahdanau and. Neural machine translation by jointly learning to align and translate , booktitle =
-
[48]
Selvaraju and. Grad-. 2017 , pages =. doi:10/gfkqbw , file =
work page 2017
-
[49]
Smoothgrad: Removing Noise by Adding Noise , author =. 2017 , journal =
work page 2017
-
[50]
Nucleic Acids Research , volume=
PubChem substance and compound databases , author=. Nucleic Acids Research , volume=. 2016 , publisher=
work page 2016
-
[51]
Expert opinion on drug discovery , volume=
BindingDB and ChEMBL: online compound databases for drug discovery , author=. Expert opinion on drug discovery , volume=. 2011 , publisher=
work page 2011
-
[52]
Annals of Behavioral Medicine , volume=
Compliance with cardiovascular disease prevention strategies: a review of the research , author=. Annals of Behavioral Medicine , volume=. 1997 , publisher=
work page 1997
-
[53]
International Journal of Data Warehousing and Mining (IJDWM) , volume=
Multi-label classification: An overview , author=. International Journal of Data Warehousing and Mining (IJDWM) , volume=. 2007 , publisher=
work page 2007
-
[54]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multi-label image recognition with graph convolutional networks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning a deep convnet for multi-label classification with partial labels , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[56]
Advances in Neural Information Processing Systems , volume=
Exploiting weakly supervised visual patterns to learn from partial annotations , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the AAAI conference on artificial intelligence , volume=
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[58]
International Conference on Learning Representations , year=
Large Scale GAN Training for High Fidelity Natural Image Synthesis , author=. International Conference on Learning Representations , year=
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
A style-based generator architecture for generative adversarial networks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
Semi-supervised learning with deep generative models , author=. Proc. Advances in Neural Information Processing Systems (NIPS) , pages=
-
[61]
arXiv preprint arXiv:1812.06190 , year=
Learning latent subspaces in variational autoencoders , author=. arXiv preprint arXiv:1812.06190 , year=
-
[62]
Conditional Generative Adversarial Nets
Conditional generative adversarial nets , author=. arXiv preprint arXiv:1411.1784 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
IEEE Transactions on Image Processing , volume=
Attgan: Facial attribute editing by only changing what you want , author=. IEEE Transactions on Image Processing , volume=. 2019 , publisher=
work page 2019
-
[64]
Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows , author=. arXiv e-prints , pages=
-
[65]
Engineering Applications of Artificial Intelligence , volume=
A novel purity-based k nearest neighbors imputation method and its application in financial distress prediction , author=. Engineering Applications of Artificial Intelligence , volume=. 2019 , publisher=
work page 2019
-
[66]
arXiv preprint arXiv:1705.02737 , year=
Multiple imputation using deep denoising autoencoders , author=. arXiv preprint arXiv:1705.02737 , year=
-
[67]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Generative face completion , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[68]
Journal of statistical software , volume=
mice: Multivariate imputation by chained equations in R , author=. Journal of statistical software , volume=. 2011 , publisher=
work page 2011
-
[69]
International Conference on Learning Representations , year=
Why Not to Use Zero Imputation? Correcting Sparsity Bias in Training Neural Networks , author=. International Conference on Learning Representations , year=
-
[70]
ICML Workshop on the Art of Learning with Missing Values (Artemiss) , year=
How to deal with missing data in supervised deep learning? , author=. ICML Workshop on the Art of Learning with Missing Values (Artemiss) , year=
-
[71]
Supervised learning from incomplete data via an
Ghahramani, Zoubin and Jordan, Michael I , booktitle=. Supervised learning from incomplete data via an. 1994 , organization=
work page 1994
-
[72]
Analysis of incomplete multivariate data , author=. 1997 , publisher=
work page 1997
-
[73]
Proceedings of the International Conference on Machine Learning , pages=
Learning from incomplete data with infinite imputations , author=. Proceedings of the International Conference on Machine Learning , pages=. 2008 , organization=
work page 2008
-
[74]
Improved Training of Wasserstein GANs , url =
Gulrajani, Ishaan and Ahmed, Faruk and Arjovsky, Martin and Dumoulin, Vincent and Courville, Aaron C , booktitle =. Improved Training of Wasserstein GANs , url =
-
[75]
Advances in Neural Information Processing Systems , pages=
Feature set embedding for incomplete data , author=. Advances in Neural Information Processing Systems , pages=
-
[76]
Proceedings of the International Conference on Machine Learning , pages=
Nightmare at test time: robust learning by feature deletion , author=. Proceedings of the International Conference on Machine Learning , pages=. 2006 , organization=
work page 2006
-
[77]
Learning to classify with missing and corrupted features , author=. Machine Learning , volume=. 2010 , publisher=
work page 2010
- [78]
-
[79]
Journal of chemical information and modeling , volume=
Novel 2D fingerprints for ligand-based virtual screening , author=. Journal of chemical information and modeling , volume=. 2006 , publisher=
work page 2006
-
[80]
Shape matching and object recognition using low distortion correspondences , author=. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition , pages=. 2005 , organization=
work page 2005
-
[81]
ACM Transactions on Intelligent Systems and Technology , volume=
LIBSVM: A Library for Support Vector Machines , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2011 , publisher=
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.