Recognition: no theorem link
ReLibra: Routing-Replay-Guided Load Balancing for MoE Training in Reinforcement Learning
Pith reviewed 2026-05-12 01:33 UTC · model grok-4.3
The pith
ReLibra uses replay of rollout routing decisions to reorder and replicate MoE experts at inter- and intra-batch scales for higher training throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
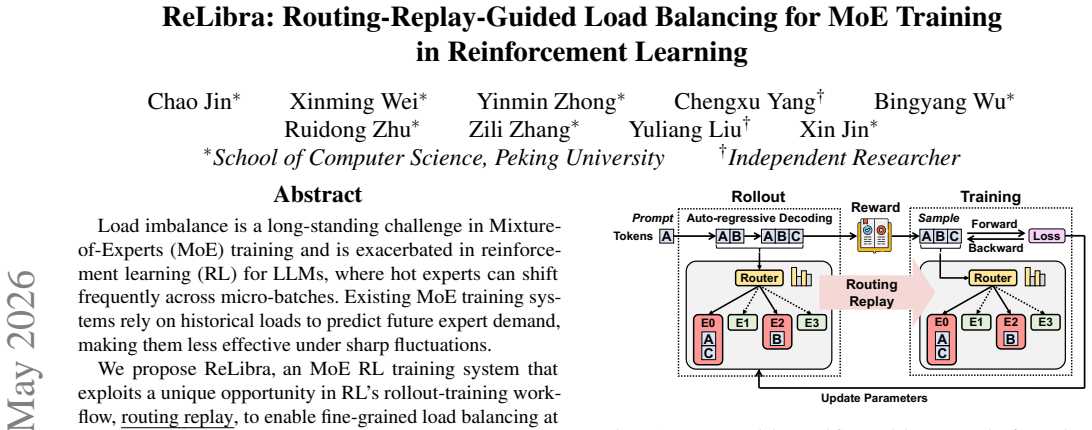
ReLibra exploits the rollout-training workflow in RL, where the same tokens and MoE parameters are used in both phases, to obtain exact advance knowledge of routing decisions. It then performs expert reordering at inter-batch granularity for cross-node balancing and expert replication at intra-batch granularity for micro-batch balancing, matching each mechanism to the available network bandwidth hierarchy.
What carries the argument
Routing-replay-guided load balancing that performs inter-batch expert reordering and intra-batch expert replication.
If this is right
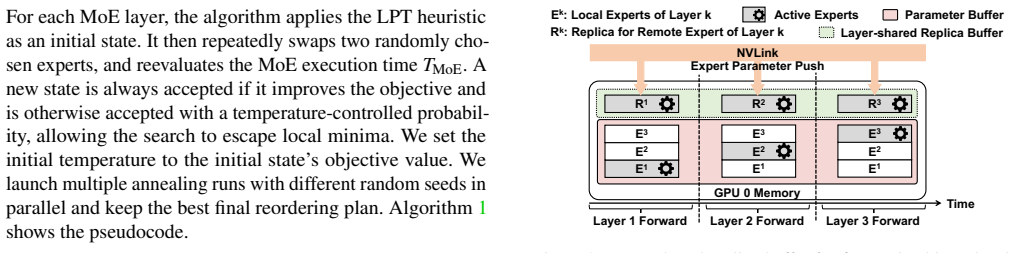
- Training throughput rises by up to 1.6 times versus Megatron-LM on diverse MoE LLMs and RL workloads.
- Throughput exceeds EPLB by up to 1.2 times even when EPLB receives oracle load information.
- Achieved throughput stays within 6-10 percent of an idealized perfectly balanced baseline.
- Balancing operates at micro-batch granularity, directly addressing the frequent expert shifts that characterize RL training.
Where Pith is reading between the lines
- The replay technique could be adapted to supervised fine-tuning of MoE models if a cheap way to predict routing in advance can be found.
- Lower load imbalance may allow practitioners to train larger MoE models with fewer total experts or on hardware with less over-provisioning.
- Similar advance-knowledge mechanisms could be explored for other dynamic properties such as activation sparsity or memory access patterns in future training systems.
- Combining routing replay with adaptive routing policies might further reduce how often load shifts occur.
Load-bearing premise
The token-to-expert routing decisions recorded during rollout remain representative of the loads that will actually occur when the same tokens are processed during training, and the overhead of reordering and replication stays low enough to produce net gains.
What would settle it
Measure whether the reported throughput gains disappear when routing patterns are deliberately altered between rollout and training phases, or when the separate time cost of reordering and replication is subtracted from the observed balance savings.
Figures








read the original abstract
Load imbalance is a long-standing challenge in Mixture-of-Experts (MoE) training and is exacerbated in reinforcement learning (RL) for LLMs, where hot experts can shift frequently across micro-batches. Existing MoE training systems rely on historical loads to predict future expert demand, making them less effective under sharp fluctuations. We propose ReLibra, an MoE RL training system that exploits a unique opportunity in RL's rollout-training workflow, routing replay, to enable fine-grained load balancing at micro-batch granularity. Because rollout and training process the same tokens with the same MoE parameters, the token-to-expert routing decisions are known before training starts. Leveraging this information, ReLibra places two MoE load-balancing mechanisms at inter- and intra-batch timescales, matching their communication patterns to hierarchical network bandwidths. At the inter-batch timescale, ReLibra performs expert reordering to redistribute experts for batch-level cross-node balancing; at the intra-batch timescale, it dynamically performs expert replication within a node to absorb micro-batch-level load fluctuations. Experiments on diverse MoE LLMs and RL workloads show that ReLibra improves training throughput by up to 1.6$\times$ over Megatron-LM and by up to 1.2$\times$ over EPLB, even when EPLB is given oracle loads. Moreover, ReLibra remains within 6%-10% of the throughput of an idealized balanced baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReLibra, an MoE training system for RL workloads that exploits the rollout-training workflow to perform routing replay. Because rollout and training use identical tokens and MoE parameters, precomputed token-to-expert assignments enable inter-batch expert reordering for cross-node balance and intra-batch expert replication for micro-batch fluctuations. Experiments report up to 1.6× throughput over Megatron-LM and 1.2× over oracle EPLB, remaining within 6-10% of an idealized balanced baseline across diverse MoE LLMs and RL tasks.
Significance. If the empirical results and the routing-replay assumption hold under realistic RL training loops, ReLibra would provide a practical, low-overhead mechanism for mitigating load imbalance in large-scale MoE RL, a setting where expert hotness shifts rapidly. The work's strength lies in matching communication patterns to hierarchical network bandwidths and delivering concrete speedups against strong baselines including an oracle prior method.
major comments (2)
- Abstract and §3 (Routing Replay and Load Balancing Mechanisms): The central claim that 'rollout and training process the same tokens with the same MoE parameters' is load-bearing for the reported speedups. In standard PPO-style RL loops, the training phase on a rollout batch performs multiple gradient steps that update router and expert weights; after the first update the precomputed token-to-expert assignments become stale for subsequent micro-batches. The manuscript must clarify whether it assumes a single gradient step, frozen parameters during training, or a non-standard RL regime, and must demonstrate that the 1.2× gain versus oracle EPLB survives under multi-step updates.
- §4 (Experimental Setup) and Table 2: The idealized balanced baseline and the oracle-EPLB comparison are not fully specified with respect to data-exclusion rules, number of independent runs, or variance reporting. Without these details it is impossible to determine whether the 6-10% gap to ideal and the 1.2× gain are robust or sensitive to particular workload characteristics.
minor comments (2)
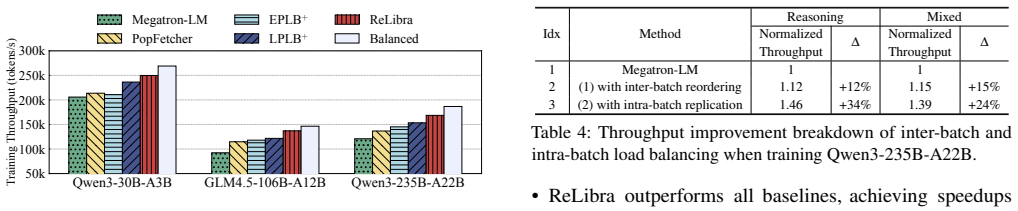
- Figure 3 and §3.2: The overhead of expert reordering and replication (communication volume, synchronization cost) should be quantified separately from the net throughput numbers to allow readers to assess when the technique remains beneficial.
- §2 (Related Work): The comparison to prior MoE load-balancing systems would benefit from an explicit statement of how ReLibra differs from history-based predictors in the presence of the RL-specific replay opportunity.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our paper. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: Abstract and §3 (Routing Replay and Load Balancing Mechanisms): The central claim that 'rollout and training process the same tokens with the same MoE parameters' is load-bearing for the reported speedups. In standard PPO-style RL loops, the training phase on a rollout batch performs multiple gradient steps that update router and expert weights; after the first update the precomputed token-to-expert assignments become stale for subsequent micro-batches. The manuscript must clarify whether it assumes a single gradient step, frozen parameters during training, or a non-standard RL regime, and must demonstrate that the 1.2× gain versus oracle EPLB survives under multi-step updates.
Authors: We thank the referee for highlighting this critical point. The ReLibra design relies on the routing decisions being valid for the training phase, which holds when the MoE parameters remain unchanged during the processing of a given rollout batch. In our experimental setup and the targeted RL workloads, we perform a single gradient update per rollout batch. This avoids staleness within the batch while still allowing the benefits of routing replay. We will revise the abstract and §3 to explicitly state this single-gradient-step assumption and provide a brief discussion on how it relates to standard multi-step PPO. We note that demonstrating the exact 1.2× speedup under multi-step updates would require additional experiments that are outside the scope of the current manuscript; however, the inter- and intra-batch balancing mechanisms can still mitigate imbalance even if routing is only approximately accurate. revision: partial
-
Referee: §4 (Experimental Setup) and Table 2: The idealized balanced baseline and the oracle-EPLB comparison are not fully specified with respect to data-exclusion rules, number of independent runs, or variance reporting. Without these details it is impossible to determine whether the 6-10% gap to ideal and the 1.2× gain are robust or sensitive to particular workload characteristics.
Authors: We agree that more details are needed for reproducibility and robustness assessment. In the revised version, we will expand §4 to specify: (1) the idealized balanced baseline assumes zero expert imbalance and perfect communication scheduling with no overhead; (2) oracle-EPLB is provided with the exact token-to-expert assignments from the rollout phase as input for its load prediction; (3) all throughput numbers are averaged over 5 independent runs using different random seeds for data sampling and initialization; (4) variance is reported as standard deviation in Table 2 and associated figures; (5) data-exclusion rules involve discarding the initial 10% of batches as warmup to stabilize measurements. These additions will clarify that the reported gaps are consistent across runs. revision: yes
- Providing empirical demonstration of the 1.2× gain under multi-step gradient updates, as this would necessitate new experiments not present in the current work.
Circularity Check
No significant circularity; empirical systems evaluation
full rationale
The paper describes a concrete scheduling system (expert reordering at inter-batch scale and replication at intra-batch scale) that exploits the RL rollout-training property that the same tokens and parameters are processed in both phases. All throughput claims (1.6× vs Megatron-LM, 1.2× vs oracle EPLB) are presented as direct measurements against external baselines rather than as outputs of any fitted parameter, self-defined quantity, or self-citation chain. No equations, uniqueness theorems, or ansatzes are introduced that reduce by construction to the inputs; the central result therefore remains independent of the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rollout and training phases process identical tokens with identical MoE parameters, so routing decisions are known before training begins.
Reference graph
Works this paper leans on
-
[1]
Outrageously large neural net- works: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural net- works: The sparsely-gated mixture-of-experts layer,”In- ternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[2]
Gshard: Scaling giant models with conditional computation and auto- matic sharding,
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and auto- matic sharding,”International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[3]
Switch transform- ers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transform- ers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, 2022
work page 2022
-
[4]
Introducing DBRX: A New State-of-the-Art Open LLM,
“Introducing DBRX: A New State-of-the-Art Open LLM,” 2024. https://www.databricks.com/blog/ introducing-dbrx-new-state-art-open-llm
work page 2024
-
[5]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand,et al., “Mixtral of experts,” arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan,et al., “Deepseek-v3 tech- nical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Kimi K2: Open Agentic Intelligence
K. Team, Y . Bai, Y . Bao, Y . Charles, C. Chen, G. Chen, H. Chen, H. Chen, J. Chen, N. Chen,et al., “Kimi k2: Open agentic intelligence,”arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
A. Chen, A. Li, B. Gong, B. Jiang, B. Fei, B. Yang, B. Shan, C. Yu, C. Wang, C. Zhu,et al., “Minimax- m1: Scaling test-time compute efficiently with lightning attention,”arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Glam: Efficient scaling of language models with mixture-of- experts,
N. Du, Y . Huang, A. M. Dai, S. Tong, D. Lepikhin, Y . Xu, M. Krikun, Y . Zhou, A. W. Yu, O. Firat,et al., “Glam: Efficient scaling of language models with mixture-of- experts,” inInternational Conference on Machine Learn- ing (ICML), 2022
work page 2022
-
[11]
S. Rajbhandari, C. Li, Z. Yao, M. Zhang, R. Y . Am- inabadi, A. A. Awan, J. Rasley, and Y . He, “Deepspeed- moe: Advancing mixture-of-experts inference and train- ing to power next-generation ai scale,” inInternational Conference on Machine Learning (ICML), 2022
work page 2022
-
[12]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., “Training language models to follow instructions with human feedback,”Advances in Neural Information Processing Systems, 2022
work page 2022
-
[13]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi,et al., “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,”Nature, 2025
work page 2025
-
[14]
Flexmoe: Scaling large-scale sparse pre-trained model training via dynamic device placement,
X. Nie, X. Miao, Z. Wang, Z. Yang, J. Xue, L. Ma, G. Cao, and B. Cui, “Flexmoe: Scaling large-scale sparse pre-trained model training via dynamic device placement,”ACM SIGMOD, 2023
work page 2023
-
[15]
M. Zhai, J. He, Z. Ma, Z. Zong, R. Zhang, and J. Zhai, “{SmartMoE}: Efficiently training {Sparsely- Activated} models through combining offline and online parallelization,” inUSENIX ATC, 2023
work page 2023
-
[16]
Micromoe: Fine- grained load balancing for mixture-of-experts with token scheduling,
C. Zhao, W. Wu, L. Song, and Y . Xu, “Micromoe: Fine- grained load balancing for mixture-of-experts with token scheduling,”arXiv preprint arXiv:2511.16947, 2025
-
[17]
J. Zhang, C. Ma, X. Wang, Y . Nie, Y . Li, Y . Xu, X. Liao, B. Li, and H. Jin, “ {PopFetcher}: Towards acceler- ated {Mixture-of-Experts} training via popularity based {Expert-Wise}prefetch,” inUSENIX ATC, 2025
work page 2025
-
[18]
Laer-moe: Load-adaptive expert re-layout for efficient mixture-of-experts training,
X. Liu, Y . Wang, F. Fu, X. Xiao, H. Li, J. Li, and B. Cui, “Laer-moe: Load-adaptive expert re-layout for efficient mixture-of-experts training,” inACM ASPLOS, 2026
work page 2026
-
[19]
D. Liu, Z. Yan, X. Yao, T. Liu, V . Korthikanti, E. Wu, S. Fan, G. Deng, H. Bai, J. Chang,et al., “Moe par- allel folding: Heterogeneous parallelism mappings for efficient large-scale moe model training with megatron core,”arXiv preprint arXiv:2504.14960, 2025. 13
-
[20]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong,et al., “Deepseek-v3.2: Push- ing the frontier of open large language models,”arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liu,et al., “Dapo: An open- source llm reinforcement learning system at scale,” arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Competition-level code generation with alphacode,
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrit- twieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lago,et al., “Competition-level code generation with alphacode,”Science, 2022
work page 2022
-
[23]
Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
V . Pyatkin, S. Malik, V . Graf, H. Ivison, S. Huang, P. Dasigi, N. Lambert, and H. Hajishirzi, “Generaliz- ing verifiable instruction following,”arXiv preprint arXiv:2507.02833, 2025
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu,et al., “Deepseek- math: Pushing the limits of mathematical reason- ing in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Expert Parallelism Load Balancer (EPLB),
“Expert Parallelism Load Balancer (EPLB),” 2025. https://github.com/deepseek-ai/eplb
work page 2025
-
[26]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Ve- ness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski,et al., “Human-level control through deep reinforcement learning,”Nature, 2015
work page 2015
-
[27]
Soft actor-critic: Off-policy maximum entropy deep rein- forcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep rein- forcement learning with a stochastic actor,” inInterna- tional Conference on Machine Learning (ICML), 2018
work page 2018
-
[28]
W. Ma, H. Zhang, L. Zhao, Y . Song, Y . Wang, Z. Sui, and F. Luo, “Stabilizing moe reinforcement learning by aligning training and inference routers,”arXiv preprint arXiv:2510.11370, 2025
-
[29]
arXiv preprint arXiv:2512.01374 , year=
C. Zheng, K. Dang, B. Yu, M. Li, H. Jiang, J. Lin, Y . Liu, H. Lin, C. Wu, F. Hu,et al., “Stabilizing reinforcement learning with llms: Formulation and practices,”arXiv preprint arXiv:2512.01374, 2025
-
[30]
Optimization and approximation in determinis- tic sequencing and scheduling: a survey,
R. L. Graham, E. L. Lawler, J. K. Lenstra, and A. R. Kan, “Optimization and approximation in determinis- tic sequencing and scheduling: a survey,” inAnnals of discrete mathematics, 1979
work page 1979
-
[31]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “At- tention is all you need,”Advances in Neural Information Processing Systems, 2017
work page 2017
-
[32]
Zero: Memory optimizations toward training trillion parame- ter models,
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “Zero: Memory optimizations toward training trillion parame- ter models,” inInternational Conference for High Perfor- mance Computing, Networking, Storage and Analysis, 2020
work page 2020
-
[33]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[34]
Gpipe: Efficient training of giant neural networks using pipeline parallelism,
Y . Huang, Y . Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . Wu,et al., “Gpipe: Efficient training of giant neural networks using pipeline parallelism,”Advances in Neural Information Processing Systems, 2019
work page 2019
-
[35]
Pipedream: Generalized pipeline parallelism for dnn training,
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Za- haria, “Pipedream: Generalized pipeline parallelism for dnn training,” inACM SOSP, 2019
work page 2019
-
[36]
Gpqa: A graduate-level google-proof q&a benchmark,
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman, “Gpqa: A graduate-level google-proof q&a benchmark,” inFirst conference on language modeling, 2024
work page 2024
-
[37]
Orca: A distributed serving system for {Transformer-Based} generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.- G. Chun, “Orca: A distributed serving system for {Transformer-Based} generative models,” inUSENIX OSDI, 2022
work page 2022
-
[38]
Fast distributed inference serving for large language models,
B. Wu, Y . Zhong, Z. Zhang, S. Liu, F. Liu, Y . Sun, G. Huang, X. Liu, and X. Jin, “Fast distributed infer- ence serving for large language models,”arXiv preprint arXiv:2305.05920, 2023
-
[39]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Taming the long-tail: Efficient reasoning rl training with adaptive drafter,
Q. Hu, S. Yang, J. Guo, X. Yao, Y . Lin, Y . Gu, H. Cai, C. Gan, A. Klimovic, and S. Han, “Taming the long-tail: Efficient reasoning rl training with adaptive drafter,” in ACM ASPLOS, 2026
work page 2026
-
[41]
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
R. Qin, W. He, W. Huang, Y . Zhang, Y . Zhao, B. Pang, X. Xu, Y . Shan, Y . Wu, and M. Zhang, “Seer: Online context learning for fast synchronous llm reinforcement learning,”arXiv preprint arXiv:2511.14617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Optimizing {RLHF} training for large language models with stage fusion,
Y . Zhong, Z. Zhang, B. Wu, S. Liu, Y . Chen, C. Wan, H. Hu, L. Xia, R. Ming, Y . Zhu,et al., “Optimizing {RLHF} training for large language models with stage fusion,” inUSENIX NSDI, 2025. 14
work page 2025
-
[43]
R. Zhu, M. Han, Y . Zhong, W. Xiao, X. Liu, and X. Jin, “Towards efficient reward service for rlvr with request- level flexibility and batch-level constraint,” inUSENIX NSDI, 2026
work page 2026
-
[44]
On the uncapacitated location problem,
G. Cornuejols, M. Fisher, and G. L. Nemhauser, “On the uncapacitated location problem,” inAnnals of Discrete Mathematics, 1977
work page 1977
-
[45]
Linear-Programming-Based Load Balancer (LPLB),
“Linear-Programming-Based Load Balancer (LPLB),” 2025.https://github.com/deepseek-ai/LPLB
work page 2025
-
[46]
Alibaba hpn: A data center network for large language model training,
K. Qian, Y . Xi, J. Cao, J. Gao, Y . Xu, Y . Guan, B. Fu, X. Shi, F. Zhu, R. Miao,et al., “Alibaba hpn: A data center network for large language model training,” in ACM SIGCOMM, 2024
work page 2024
-
[47]
“NVIDIA GTC: Accelerating Mixture of Experts Train- ing With Rail-Optimized InfiniBand Networking in Cru- soe Cloud,” 2024.https://www.nvidia.com/en-us/ on-demand/session/gtc24-s63014/
work page 2024
- [48]
-
[49]
Optimized primitives for inter-GPU communication,
“Optimized primitives for inter-GPU communication,” 2026.https://github.com/NVIDIA/nccl
work page 2026
-
[50]
DeepEP: an efficient expert-parallel communication library,
“DeepEP: an efficient expert-parallel communication library,” 2025. https://github.com/deepseek-ai/ DeepEP
work page 2025
-
[51]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,” inUSENIX OSDI, 2024
work page 2024
-
[52]
Megascale- infer: Efficient mixture-of-experts model serving with disaggregated expert parallelism,
R. Zhu, Z. Jiang, C. Jin, P. Wu, C. A. Stuardo, D. Wang, X. Zhang, H. Zhou, H. Wei, Y . Cheng,et al., “Megascale- infer: Efficient mixture-of-experts model serving with disaggregated expert parallelism,” inACM SIGCOMM, 2025
work page 2025
-
[53]
Z. Zhang, Y . Zhong, Y . Jiang, H. Hu, J. Sun, Z. Ge, Y . Zhu, D. Jiang, and X. Jin, “Disttrain: Addressing model and data heterogeneity with disaggregated train- ing for multimodal large language models,” inACM SIGCOMM, 2025
work page 2025
-
[54]
Heddle: A distributed orches- tration system for agentic rl rollout,
Z. Zhang, Y . Zhong, C. Yang, C. Jin, B. Wu, X. Wei, Y . Liu, and X. Jin, “Heddle: A distributed orches- tration system for agentic rl rollout,”arXiv preprint arXiv:2603.28101, 2026
-
[55]
Bounds on multiprocessing timing anomalies,
R. L. Graham, “Bounds on multiprocessing timing anomalies,”SIAM journal on Applied Mathematics, 1969
work page 1969
-
[56]
The SCIP optimization suite 9.0
S. Bolusani, M. Besançon, K. Bestuzheva, A. Chmiela, J. Dionísio, T. Donkiewicz, J. van Doornmalen, L. Eifler, M. Ghannam, A. Gleixner,et al., “The scip optimization suite 9.0,”arXiv preprint arXiv:2402.17702, 2024
-
[57]
Slime: An LLM post-training framework for RL Scal- ing,
“Slime: An LLM post-training framework for RL Scal- ing,” 2025.https://github.com/THUDM/slime/
work page 2025
-
[58]
GPU optimized techniques for training transformer models at-scale,
“GPU optimized techniques for training transformer models at-scale,” 2025. https://github.com/ NVIDIA/Megatron-LM
work page 2025
-
[59]
Sglang: Efficient execution of structured lan- guage model programs,
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, et al., “Sglang: Efficient execution of structured lan- guage model programs,”Advances in Neural Informa- tion Processing Systems, 2024
work page 2024
- [60]
- [61]
-
[62]
https://developer.nvidia.com/blog/ nvidia-hopper-architecture-in-depth/
-
[63]
Flashattention-3: Fast and accurate atten- tion with asynchrony and low-precision,
J. Shah, G. Bikshandi, Y . Zhang, V . Thakkar, P. Ramani, and T. Dao, “Flashattention-3: Fast and accurate atten- tion with asynchrony and low-precision,”Advances in Neural Information Processing Systems, 2024
work page 2024
-
[64]
https: //github.com/NVIDIA/TransformerEngine
“A library for accelerating Transformer models on NVIDIA GPUs, including using 8-bit floating point (FP8) precision on Hopper and Ada GPUs, to pro- vide better performance with lower memory utiliza- tion in both training and inference.,” 2026. https: //github.com/NVIDIA/TransformerEngine
work page 2026
-
[65]
Ray: A distributed framework for emerging{AI} applications,
P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Elibol, Z. Yang, W. Paul, M. I. Jordan, et al., “Ray: A distributed framework for emerging{AI} applications,” inUSENIX OSDI, 2018
work page 2018
-
[66]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
A. Zeng, X. Lv, Q. Zheng, Z. Hou, B. Chen, C. Xie, C. Wang, D. Yin, H. Zeng, J. Zhang,et al., “Glm-4.5: Agentic, reasoning, and coding (arc) foundation models,” arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
K. Team, A. Du, B. Gao, B. Xing, C. Jiang, C. Chen, C. Li, C. Xiao, C. Du, C. Liao,et al., “Kimi k1.5: Scal- ing reinforcement learning with llms,”arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Y . Zhong, Z. Zhang, X. Song, H. Hu, C. Jin, B. Wu, N. Chen, Y . Chen, Y . Zhou, C. Wan,et al., “Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation,”arXiv preprint arXiv:2504.15930, 2025. 15
-
[69]
Accelerat- ing distributed {MoE} training and inference with lina,
J. Li, Y . Jiang, Y . Zhu, C. Wang, and H. Xu, “Accelerat- ing distributed {MoE} training and inference with lina,” inUSENIX ATC, 2023
work page 2023
-
[70]
Tutel: Adap- tive mixture-of-experts at scale,
C. Hwang, W. Cui, Y . Xiong, Z. Yang, Z. Liu, H. Hu, Z. Wang, R. Salas, J. Jose, P. Ram,et al., “Tutel: Adap- tive mixture-of-experts at scale,”Proceedings of Ma- chine Learning and Systems, 2023
work page 2023
-
[71]
arXiv preprint arXiv:2203.14685 , year=
X. Nie, P. Zhao, X. Miao, T. Zhao, and B. Cui, “Hetumoe: An efficient trillion-scale mixture-of-expert distributed training system,”arXiv preprint arXiv:2203.14685, 2022
-
[72]
C. Jin, Z. Jiang, Z. Bai, Z. Zhong, J. Liu, X. Li, N. Zheng, X. Wang, C. Xie, Q. Huang,et al., “Megascale- moe: Large-scale communication-efficient training of mixture-of-experts models in production,”arXiv preprint arXiv:2505.11432, 2025
-
[73]
C. Chen, X. Li, Q. Zhu, J. Duan, P. Sun, X. Zhang, and C. Yang, “Centauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning,” inACM ASP- LOS, 2024
work page 2024
-
[74]
{MegaScale}: Scaling large language model training to more than 10,000{GPUs},
Z. Jiang, H. Lin, Y . Zhong, Q. Huang, Y . Chen, Z. Zhang, Y . Peng, X. Li, C. Xie, S. Nong,et al., “{MegaScale}: Scaling large language model training to more than 10,000{GPUs},” inUSENIX NSDI, 2024
work page 2024
-
[75]
Comet: Fine-grained computation-communication overlapping for mixture-of-experts,
S. Zhang, N. Zheng, H. Lin, Z. Jiang, W. Bao, C. Jiang, Q. Hou, W. Cui, S. Zheng, L.-W. Chang,et al., “Comet: Fine-grained computation-communication overlapping for mixture-of-experts,”Proceedings of Machine Learn- ing and Systems, 2025
work page 2025
-
[76]
L.-W. Chang, W. Bao, Q. Hou, C. Jiang, N. Zheng, Y . Zhong, X. Zhang, Z. Song, C. Yao, Z. Jiang, et al., “Flux: fast software-based communication over- lap on gpus through kernel fusion,”arXiv preprint arXiv:2406.06858, 2024
-
[77]
Janus: A unified distributed training framework for sparse mixture-of- experts models,
J. Liu, J. H. Wang, and Y . Jiang, “Janus: A unified distributed training framework for sparse mixture-of- experts models,” inACM SIGCOMM, 2023
work page 2023
-
[78]
Hybridflow: A flexible and efficient rlhf framework,
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu, “Hybridflow: A flexible and efficient rlhf framework,” inEuroSys, 2025
work page 2025
-
[79]
W. Gao, Y . Zhao, T. Wu, S. Xiong, W. Wang, D. An, L. Cao, D. Muhtar, Z. Liu, H. Zhao,et al., “Rollart: Scal- ing agentic rl training via disaggregated infrastructure,” arXiv preprint arXiv:2512.22560, 2025
-
[80]
Fast infer- ence from transformers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast infer- ence from transformers via speculative decoding,” in International Conference on Machine Learning (ICML), 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.