Recognition: no theorem link
Muon Does Not Converge on Convex Lipschitz Functions
Pith reviewed 2026-05-12 02:13 UTC · model grok-4.3
The pith
Muon does not converge on convex Lipschitz functions regardless of learning rate schedule
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Muon and its variants do not converge on the class of convex and Lipschitz functions, regardless of the choice of learning rate schedule. Error feedback can restore convergence for Muon and all non-Euclidean subgradient methods with momentum, yet this fix degrades performance in practice on image classification and language modeling tasks.
What carries the argument
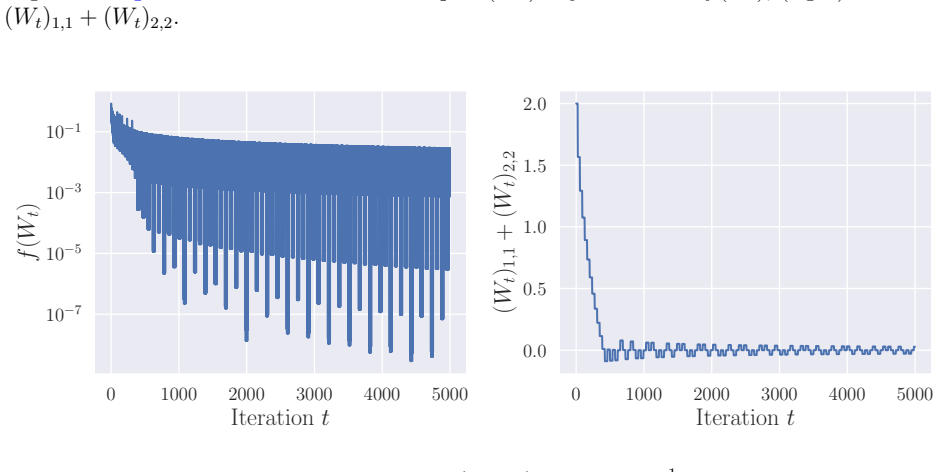
The construction of a convex Lipschitz function on which Muon iterates diverge from the optimum for arbitrary step sizes, together with the error-feedback correction that ensures convergence.
Load-bearing premise
The assumption that the convex Lipschitz class without smoothness is a relevant test case for whether Muon can be understood theoretically.
What would settle it
Finding even one convex Lipschitz function and one learning rate schedule where Muon converges to the solution.
Figures






read the original abstract
Muon and its variants have shown strong empirical performance in a variety of deep learning tasks. Existing convergence analyses of Muon rely on smoothness assumptions, though arguably the most successful function class for developing deep learning methods (such as AdaGrad, Shampoo, Schedule-Free and more) has been the class of convex and Lipschitz functions. In this paper we question whether the classical convex Lipschitz model is a useful one for understanding Muon. Our answer is no. We show that Muon does not converge on the class of convex and Lipschitz functions, regardless of the choice of learning rate schedule. We also show that error feedback restores convergence of Muon and all the non-Euclidean subgradient methods with momentum. However, this theoretical fix using error feedback degrades the performance of Muon in two representative settings for image classification (CIFAR-10) and language modeling (nanoGPT on FineWeb-Edu 10B). Our conclusion is that convex Lipschitz theory, despite having a prominent role in the design of practical methods for deep learning, is not the most suited one for Muon. This suggests that Muon's success must come from structure absent from this model, most plausibly related to smoothness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Muon fails to converge on convex Lipschitz functions for any learning-rate schedule, via a direct counterexample construction. It further shows that error feedback restores convergence for Muon and other non-Euclidean subgradient methods with momentum, but that this modification degrades empirical performance on CIFAR-10 image classification and nanoGPT language modeling on FineWeb-Edu. The conclusion is that the convex Lipschitz model is unsuitable for explaining Muon's success, which must rely on smoothness or other structure absent from the model.
Significance. If the non-convergence result holds, the work is significant because it provides a concrete counterexample separating Muon from the convex Lipschitz setting that has been central to analyses of AdaGrad, Shampoo, and schedule-free methods. The direct (non-circular) nature of the counterexample and the reproducible empirical degradation with error feedback are strengths. The result usefully redirects theoretical attention toward smoothness assumptions that may better capture where Muon succeeds in practice.
major comments (2)
- [main theorem / counterexample construction] The central claim (abstract and main theorem) asserts non-convergence 'regardless of the choice of learning rate schedule.' The counterexample must be shown to defeat every adaptive rule in which the step size at iteration t is an arbitrary positive function of the observed gradient sequence and prior iterates. Because the constructed function is convex and Lipschitz, gradient norms are bounded; it is not immediate that no history-dependent rule can select safe steps that avoid the exhibited oscillation. The proof should explicitly rule out such rules or state the precise class of schedules covered.
- [error feedback section] The error-feedback convergence restoration (section on error feedback) is stated for 'all the non-Euclidean subgradient methods with momentum.' The argument should clarify whether the same step-size restrictions or additional assumptions (e.g., on the momentum parameter or the geometry) are required for each method, and whether the restored convergence rate is comparable to standard subgradient methods.
minor comments (2)
- [preliminaries] Notation for the Muon update (momentum and normalization steps) should be stated once in a single display equation early in the paper to avoid repeated inline definitions.
- [experiments] The experimental section would benefit from reporting the precise error-feedback implementation (e.g., the scaling factor or accumulation rule) used in the CIFAR-10 and nanoGPT runs so that the degradation can be reproduced exactly.
Simulated Author's Rebuttal
Thank you for the detailed and insightful referee report. We appreciate the opportunity to clarify the scope of our results and will revise the manuscript to address the points raised.
read point-by-point responses
-
Referee: [main theorem / counterexample construction] The central claim (abstract and main theorem) asserts non-convergence 'regardless of the choice of learning rate schedule.' The counterexample must be shown to defeat every adaptive rule in which the step size at iteration t is an arbitrary positive function of the observed gradient sequence and prior iterates. Because the constructed function is convex and Lipschitz, gradient norms are bounded; it is not immediate that no history-dependent rule can select safe steps that avoid the exhibited oscillation. The proof should explicitly rule out such rules or state the precise class of schedules covered.
Authors: Our main theorem establishes that on the constructed convex Lipschitz function, the Muon iterates fail to converge for any sequence of positive learning rates. Any adaptive schedule that selects the step size as a positive function of the gradient history and prior iterates will generate some such sequence of positive steps. Consequently, the non-convergence holds for all such adaptive rules. We will revise the statement of the theorem and the surrounding discussion to explicitly indicate that the result applies to arbitrary positive step-size sequences, thereby encompassing all history-dependent adaptive schedules. The bounded gradient norms are leveraged in the construction to ensure the oscillation is independent of the particular step sizes. revision: yes
-
Referee: [error feedback section] The error-feedback convergence restoration (section on error feedback) is stated for 'all the non-Euclidean subgradient methods with momentum.' The argument should clarify whether the same step-size restrictions or additional assumptions (e.g., on the momentum parameter or the geometry) are required for each method, and whether the restored convergence rate is comparable to standard subgradient methods.
Authors: The convergence result with error feedback applies to all considered non-Euclidean subgradient methods with momentum under the standard step-size conditions for subgradient methods, namely that the stepsizes satisfy sum eta_t = infinity and sum eta_t^2 < infinity. The momentum parameter is taken in the open interval (0,1), consistent with typical usage, and the underlying geometry is that of the respective method. The restored convergence rate is the same as that of standard subgradient methods with error feedback, which is O(1/sqrt(T)) in the worst case. We will include an additional remark in the error feedback section to make these conditions and the rate explicit. revision: yes
Circularity Check
No circularity: direct counterexample proof on convex Lipschitz class
full rationale
The paper establishes non-convergence of Muon via an explicit counterexample construction on the convex Lipschitz function class, independent of any fitted parameters, self-referential definitions, or load-bearing self-citations. The central claim follows from the optimizer update rule and the properties of the chosen function, without reducing any derived quantity back to the inputs by construction. Error-feedback restoration is shown separately as a positive result on the same class. The derivation is self-contained as a mathematical negative result and does not invoke prior author work to force uniqueness or smuggle ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is convex and Lipschitz continuous
Reference graph
Works this paper leans on
-
[1]
Bauschke, Heinz H. and Combettes, Patrick L. , year =. Convex analysis and monotone operator theory in
-
[2]
Optimization benchmark for diffusion models on dynamical systems , author =. 2025 , journal =
work page 2025
-
[3]
Gruntkowska, Kaja and Gaponov, Alexander and Tovmasyan, Zhirayr and Richt. Error feedback for. The Fourteenth International Conference on Learning Representations , year =
- [4]
-
[5]
Duchi, John and Hazan, Elad and Singer, Yoram , title =. J. Mach. Learn. Res. , month = jul, pages =. 2011 , publisher =
work page 2011
-
[6]
Golub, Gene H. and van Loan, Charles F. , edition =. Matrix computations , url =
-
[7]
A spectral condition for feature learning , author =. 2024 , journal =
work page 2024
- [8]
-
[9]
Nemirovsky, Arkadi S. and Yudin, David B. , title =. 1983 , publisher =
work page 1983
- [10]
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Root mean square layer normalization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[12]
Karimireddy, Sai Praneeth and Rebjock, Quentin and Stich, Sebastian and Jaggi, Martin , booktitle =. Error feedback fixes. 2019 , volume =
work page 2019
-
[13]
Antonio Orvieto and Robert M. Gower , booktitle =. In search of. 2025 , url =
work page 2025
-
[14]
Lowe and Felix Dangel and Runa Eschenhagen and Zikun Xu and Roger B
Wu Lin and Scott C. Lowe and Felix Dangel and Runa Eschenhagen and Zikun Xu and Roger B. Grosse , booktitle =. Understanding and improving
-
[15]
Nikhil Vyas and Depen Morwani and Rosie Zhao and Mujin Kwun and Itai Shapira and David Brandfonbrener Imber and Lucas Janson and Sham Kakade , booktitle =
-
[16]
arXiv preprint arXiv:1706.06569 , year =
A unified approach to adaptive regularization in online and stochastic optimization , author =. arXiv preprint arXiv:1706.06569 , year =
-
[17]
Forty-second International Conference on Machine Learning , year =
Structured preconditioners in adaptive optimization: A unified analysis , author =. Forty-second International Conference on Machine Learning , year =
- [18]
-
[19]
Proceedings of the 30th International Conference on Machine Learning , year =
Jaggi, Martin , title =. Proceedings of the 30th International Conference on Machine Learning , year =
-
[20]
Optimizing neural networks with
James Martens and Roger Grosse , booktitle =. Optimizing neural networks with. 2015 , organization =
work page 2015
-
[21]
Horn, Roger A. and Johnson, Charles R. , title =. 2013 , publisher =
work page 2013
- [22]
- [23]
-
[24]
and Mahony, Robert and Sepulchre, Rodolphe , title =
Absil, P.-A. and Mahony, Robert and Sepulchre, Rodolphe , title =. 2008 , publisher =
work page 2008
-
[25]
Proceedings of the 36th International Conference on Machine Learning , pages =
Target-based temporal-difference learning , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , volume =
work page 2019
-
[26]
Vineet Gupta and Tomer Koren and Yoram Singer , booktitle =. 2018 , volume =
work page 2018
-
[27]
and Cordonnier, Jean-Baptiste and Jaggi, Martin , year =
Stich, Sebastian U. and Cordonnier, Jean-Baptiste and Jaggi, Martin , year =. Sparsified. Advances in Neural Information Processing Systems , volume =
-
[28]
1-bit stochastic gradient descent and its application to data-parallel distributed training of speech. Interspeech , author =. 2014 , volume =
work page 2014
-
[29]
Proceedings of the 42nd International Conference on Machine Learning , pages =
The surprising agreement between convex optimization theory and learning-rate scheduling for large model training , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , volume =
work page 2025
- [30]
- [31]
-
[32]
Reddi and Satyen Kale and Sanjiv Kumar , booktitle =
Sashank J. Reddi and Satyen Kale and Sanjiv Kumar , booktitle =. On the convergence of
-
[33]
Gower and Aaron Defazio and Mike Rabbat , title =
Robert M. Gower and Aaron Defazio and Mike Rabbat , title =. arXiv preprint arXiv:2106.11851 , year =
-
[34]
Simon Bartels and Jon Cockayne and Ilse C. F. Ipsen and Philipp Hennig , title =. Statistics and Computing , year =
-
[35]
Probabilistic linear algebra , author =
-
[36]
Loizou, Nicolas and Vaswani, Sharan and Laradji, Issam and Lacoste-Julien, Simon , journal =. Stochastic
- [37]
-
[38]
Gower and Othmane Sebbouh and Nicolas Loizou , title =
Robert M. Gower and Othmane Sebbouh and Nicolas Loizou , title =. arXiv preprint arXiv:2006.10311 , year =
-
[39]
Proceedings of the 37th International Conference on Machine Learning , pages =
Training neural networks for and by interpolation , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , volume =
work page 2020
-
[40]
and Blondel, Mathieu and Gazagnadou, Nidham and Pedregosa, Fabian , title =
Gower, Robert M. and Blondel, Mathieu and Gazagnadou, Nidham and Pedregosa, Fabian , title =. arXiv preprint arXiv:2202.12328 , year =
-
[41]
Proceedings of the 32nd International Conference on Machine Learning , pages =
A trust-region method for stochastic variational inference with applications to streaming data , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , volume =
work page 2015
-
[42]
Rui Yuan and Alessandro Lazaric and Robert M. Gower , title =. SIAM Journal on Optimization , year =
-
[43]
Proceedings of The Eleventh Asian Conference on Machine Learning , pages =
Trust region sequential variational inference , author =. Proceedings of The Eleventh Asian Conference on Machine Learning , pages =. 2019 , volume =
work page 2019
- [44]
-
[45]
Modular duality in deep learning , author =. arXiv preprint arXiv:2410.21265 , year =
-
[46]
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , howpublished =
work page 2024
-
[47]
2026 , howpublished =
work page 2026
-
[48]
Training deep learning models with norm-constrained
Pethick, Thomas and Xie, Wanyun and Antonakopoulos, Kimon and Zhu, Zhenyu and Silveti-Falls, Antonio and Cevher, Volkan , booktitle =. Training deep learning models with norm-constrained
- [49]
-
[50]
Fabian Schaipp and Ruben Ohana and Michael Eickenberg and Aaron Defazio and Robert M. Gower , booktitle =
-
[51]
Stochastic spectral descent for restricted
Carlson, David and Cevher, Volkan and Carin, Lawrence , booktitle =. Stochastic spectral descent for restricted. 2015 , volume =
work page 2015
-
[52]
The road less scheduled , volume =
Defazio, Aaron and Yang, Xingyu and Mehta, Harsh and Mishchenko, Konstantin and Khaled, Ahmed and Cutkosky, Ashok , booktitle =. The road less scheduled , volume =
-
[53]
and Collins, Edo and Hsieh, Ya-Ping and Carin, Lawrence and Cevher, Volkan , booktitle =
Carlson, David E. and Collins, Edo and Hsieh, Ya-Ping and Carin, Lawrence and Cevher, Volkan , booktitle =. Preconditioned spectral descent for deep learning , volume =
-
[54]
Generalized gradient norm clipping & non-
Thomas Pethick and Wanyun Xie and Mete Erdogan and Kimon Antonakopoulos and Tony Silveti-Falls and Volkan Cevher , booktitle =. Generalized gradient norm clipping & non-
- [55]
-
[56]
When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
When do spectral gradient updates help in deep learning? , author =. arXiv preprint arXiv:2512.04299 , year =
-
[57]
Michael Timothy Crawshaw and Chirag Modi and Mingrui Liu and Robert M. Gower , title =. arXiv preprint arXiv:2510.09827 , year =
-
[58]
Higham.Functions of Matrices: Theory and Computation
Higham, Nicholas J. , title =. 2008 , pages =. doi:10.1137/1.9780898717778 , url =
-
[59]
Franz Louis Cesista and You Jiacheng and Keller Jordan , title =. 2025 , howpublished =
work page 2025
-
[60]
Liu, Jingyuan and Su, Jianlin and Yao, Xingcheng and Jiang, Zhejun and Lai, Guokun and Du, Yulun and Qin, Yidao and Xu, Weixin and Lu, Enzhe and Yan, Junjie and others , journal =
-
[61]
Lau, Tim Tsz-Kit and Long, Qi and Su, Weijie , journal =
-
[62]
and McAuliffe, Jon , booktitle =
Regier, Jeffrey and Jordan, Michael I. and McAuliffe, Jon , booktitle =. Fast black-box variational inference through stochastic trust-region optimization , volume =
-
[63]
arXiv preprint arXiv:2304.05187 , year =
Automatic gradient descent: Deep learning without hyperparameters , author =. arXiv preprint arXiv:2304.05187 , year =
-
[64]
Understanding gradient orthogonalization for deep learning via
Kovalev, Dmitry , journal =. Understanding gradient orthogonalization for deep learning via
-
[65]
Implicit bias of spectral descent and
Fan, Chen and Schmidt, Mark and Thrampoulidis, Christos , journal =. Implicit bias of spectral descent and
-
[66]
Guilherme Penedo and Hynek Kydl. The. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
-
[67]
and Hestness, Joel and Dey, Nolan , title =
Soboleva, Daria and Al-Khateeb, Faisal and Myers, Robert and Steeves, Jacob R. and Hestness, Joel and Dey, Nolan , title =
-
[68]
Jordan, Keller and Bernstein, Jeremy and Rappazzo, Ben and Boza, Vlado and You, Jiacheng and Cesista, Franz and Koszarsky, Braden , year =
- [69]
-
[70]
Noah Amsel and David Persson and Christopher Musco and Robert M. Gower , booktitle =. The
-
[71]
The Thirteenth International Conference on Learning Representations , year =
Flavors of margin: Implicit bias of steepest descent in homogeneous neural networks , author =. The Thirteenth International Conference on Learning Representations , year =
-
[72]
Advances in Neural Information Processing Systems , volume =
Scalable optimization in the modular norm , author =. Advances in Neural Information Processing Systems , volume =
-
[73]
Artem Riabinin and Egor Shulgin and Kaja Gruntkowska and Peter Richt. From. Proceedings of the 43rd International Conference on Machine Learning , series =
-
[74]
Learning multiple layers of features from tiny images , author =. 2009 , publisher =
work page 2009
-
[75]
Isotropic curvature model for understanding deep learning optimization: Is gradient orthogonalization optimal? , author =. 2025 , journal =
work page 2025
-
[76]
Visualizing the loss landscape of neural nets , volume =
Li, Hao and Xu, Zheng and Taylor, Gavin and Studer, Christoph and Goldstein, Tom , booktitle =. Visualizing the loss landscape of neural nets , volume =
-
[77]
Advances in Neural Information Processing Systems , volume =
Robust, accurate stochastic optimization for variational inference , author =. Advances in Neural Information Processing Systems , volume =
-
[78]
International Conference on Machine Learning , pages =
Yes, but did it work?: Evaluating variational inference , author =. International Conference on Machine Learning , pages =
-
[79]
arXiv preprint arXiv:2203.15945 , year =
Robust, automated, and accurate black-box variational inference , author =. arXiv preprint arXiv:2203.15945 , year =
-
[80]
and Kucukelbir, Alp and McAuliffe, Jon D
Blei, David M. and Kucukelbir, Alp and McAuliffe, Jon D. , journal =. Variational inference:. 2017 , publisher =
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.