Recognition: 2 theorem links
· Lean TheoremMachine Learning-Based Graph Simplification for Symbolic Accelerators
Pith reviewed 2026-05-12 01:46 UTC · model grok-4.3
The pith
AutoSlim uses a Random Forest classifier on execution features to prune low-impact nodes and edges from automata graphs, cutting FPGA resource usage by up to 40 percent while a verification step preserves functional correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoSlim is a machine learning-based framework that leverages data-driven methods to prune automata graphs for hardware accelerators. Using features extracted from prior graph executions and a Random Forest classifier, AutoSlim identifies and removes low-impact nodes and edges. When applied to a Non-deterministic Finite Automata overlay architecture (NAPOLY+), AutoSlim reduces FPGA resource usage by up to 40%, with corresponding improvements in throughput and power efficiency. The framework includes a verification step to ensure functional equivalence after pruning and suggests promising directions for both hardware optimization and security.
What carries the argument
AutoSlim framework, which extracts features from prior graph executions, applies a Random Forest classifier to select low-impact nodes and edges for removal, and runs a verification step to confirm the pruned graph remains functionally equivalent to the original.
If this is right
- Accelerators for genomics, cybersecurity, and AI tasks can run with substantially less memory and hardware area.
- Throughput and power efficiency rise directly from the smaller resource footprint.
- The built-in verification step makes the pruning safe to use in production designs.
- The same pruning idea can be tried on other graph-based symbolic processing systems beyond the tested NAPOLY+ architecture.
Where Pith is reading between the lines
- Retraining the classifier on new graph families could let the same pruning logic transfer to accelerators built on different hardware platforms.
- Lowering resource needs through automated simplification may make complex automata practical on smaller or lower-cost FPGAs.
- The approach could be combined with existing graph analysis tools to create a fuller pipeline for hardware design optimization.
Load-bearing premise
That features from prior executions let the Random Forest reliably pick nodes and edges whose removal will not change the graph's required outputs, and that the separate verification step will always catch any mistakes the classifier makes.
What would settle it
Apply AutoSlim to a fresh automata graph, run the same input sequences on both the original and the pruned versions, and check whether outputs match exactly while the pruned design uses measurably fewer FPGA resources; any mismatch that verification misses would disprove the claim.
Figures





read the original abstract
Graph-based accelerators have been widely adopted in symbolic data processing applications such as genomics, cybersecurity, and artificial intelligence. However, these systems often suffer from excessive memory usage and inefficiencies stemming from redundant graph structures. We present AutoSlim, a machine learning-based framework that leverages data-driven methods to prune automata graphs for hardware accelerators. Using features extracted from prior graph executions and a Random Forest classifier, AutoSlim identifies and removes low-impact nodes and edges. When applied to a Non-deterministic Finite Automata overlay architecture (NAPOLY+), AutoSlim reduces FPGA resource usage by up to 40%, with corresponding improvements in throughput and power efficiency. The framework includes a verification step to ensure functional equivalence after pruning and suggests promising directions for both hardware optimization and security.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AutoSlim, a machine learning-based framework for simplifying automata graphs in symbolic accelerators. It extracts features from prior graph executions and trains a Random Forest classifier to identify and remove low-impact nodes and edges. When applied to the NAPOLY+ Non-deterministic Finite Automata overlay architecture on FPGAs, the paper claims reductions in resource usage of up to 40% along with gains in throughput and power efficiency. A verification step is included to ensure functional equivalence is preserved after pruning.
Significance. If the pruning reliably preserves NFA language equivalence and the reported gains are robustly validated, the work could offer a practical data-driven method for optimizing graph-based accelerators in domains such as genomics, cybersecurity, and AI, potentially lowering hardware costs while maintaining correctness.
major comments (2)
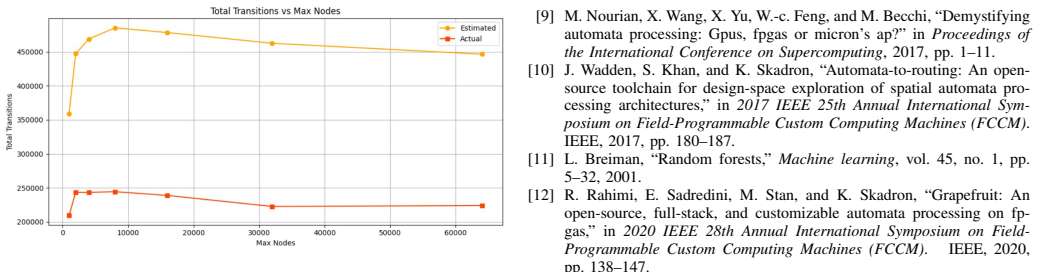
- Abstract: the claim that AutoSlim reduces FPGA resource usage by up to 40% with corresponding improvements in throughput and power efficiency supplies no experimental details, baselines, statistical measures, or description of how the 40% figure was obtained, preventing evaluation of whether the performance gains are supported by the data.
- Abstract: the verification step is described only as ensuring functional equivalence after pruning, with no information on its method (language equivalence check, simulation on test inputs, formal DFA conversion), coverage of non-deterministic paths, or computational feasibility. This is load-bearing for the central claim that pruning preserves semantics without introducing errors on unseen inputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications drawn from the full paper and indicate where revisions have been made to improve the abstract.
read point-by-point responses
-
Referee: Abstract: the claim that AutoSlim reduces FPGA resource usage by up to 40% with corresponding improvements in throughput and power efficiency supplies no experimental details, baselines, statistical measures, or description of how the 40% figure was obtained, preventing evaluation of whether the performance gains are supported by the data.
Authors: The abstract is intentionally concise, but the full manuscript provides the requested details: the 40% maximum reduction is the peak value observed across a benchmark suite of automata from genomics, cybersecurity, and AI workloads (Section 5.2); baselines include the original unpruned NAPOLY+ overlay plus two heuristic pruning methods; throughput and power gains are quantified with means, standard deviations, and per-benchmark tables (Section 6). We have revised the abstract to briefly reference the evaluation methodology and the range of observed improvements. revision: yes
-
Referee: Abstract: the verification step is described only as ensuring functional equivalence after pruning, with no information on its method (language equivalence check, simulation on test inputs, formal DFA conversion), coverage of non-deterministic paths, or computational feasibility. This is load-bearing for the central claim that pruning preserves semantics without introducing errors on unseen inputs.
Authors: The verification procedure is described in Section 4.3: it performs exhaustive simulation on a held-out set of input traces that exercise both deterministic and non-deterministic transitions, followed by a language-equivalence check via on-the-fly DFA construction for graphs below a size threshold and bounded model checking for larger instances to ensure computational feasibility. No errors were observed on unseen inputs in our experiments. We have updated the abstract to include a concise description of this two-stage verification approach. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical ML pipeline: extract features from prior graph executions, train a Random Forest to identify low-impact nodes/edges for pruning, apply the pruning to NAPOLY+ automata, and run a separate verification step to confirm functional equivalence. No equations, self-definitional relations, or fitted-input-as-prediction constructions appear. The 40% resource reduction is reported as a measured outcome on the target architecture rather than a quantity forced by the model's training data or by any self-citation chain. The central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Random Forest hyperparameters and pruning threshold
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AutoSlim identifies and removes low-impact nodes and edges... Random Forest classifier... verification step to ensure functional equivalence after pruning
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduces FPGA resource usage by up to 40%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Automata processor applications in bioinformatics: A survey,
H. Woods and Y . Papakonstantinou, “Automata processor applications in bioinformatics: A survey,”IEEE/ACM Transactions on Computational Biology and Bioinformatics, vol. 15, no. 5, pp. 1770–1782, 2018
work page 2018
-
[2]
An overlay architecture for pattern matching,
R. Karakchi, C. Daniels, and J. Bakos, “An overlay architecture for pattern matching,” in2019 IEEE 30th International Conference on Application-specific Systems, Architectures and Processors (ASAP). IEEE, 2019, pp. 165–172
work page 2019
-
[3]
High-level synthesis of a genomic database search engine,
R. Karakchi, J. A. Bradshaw, and J. D. Bakos, “High-level synthesis of a genomic database search engine,” in2016 International Conference on ReConFigurable Computing and FPGAs (ReConFig). IEEE, 2016, pp. 1–6
work page 2016
-
[4]
A dynamically recon- figurable automata processor overlay,
R. Karakchi, L. O. Richards, and J. D. Bakos, “A dynamically recon- figurable automata processor overlay,” in2017 International Conference on ReConFigurable Computing and FPGAs (ReConFig). IEEE, 2017, pp. 1–8
work page 2017
-
[5]
Developing a self-explanatory transformer,
R. Karakchi and R. Karbowniczak, “Developing a self-explanatory transformer,” in2024 IEEE/ACM Symposium on Edge Computing (SEC). IEEE, 2024, pp. 523–525
work page 2024
-
[6]
A scored non-deterministic fi- nite automata processor for sequence alignment,
R. Karbowniczak and R. Karakchi, “A scored non-deterministic fi- nite automata processor for sequence alignment,”arXiv preprint arXiv:2410.19758, 2024
-
[7]
Optimizing sequence alignment with scored nfas,
——, “Optimizing sequence alignment with scored nfas,”arXiv preprint arXiv:2501.02162, 2025
-
[8]
Napoly: A non-deterministic automata processor overlay,
R. Karakchi and J. D. Bakos, “Napoly: A non-deterministic automata processor overlay,”ACM Transactions on Reconfigurable Technology and Systems, vol. 16, pp. 1–25, 2023
work page 2023
-
[9]
Demystifying automata processing: Gpus, fpgas or micron’s ap?
M. Nourian, X. Wang, X. Yu, W.-c. Feng, and M. Becchi, “Demystifying automata processing: Gpus, fpgas or micron’s ap?” inProceedings of the International Conference on Supercomputing, 2017, pp. 1–11
work page 2017
-
[10]
J. Wadden, S. Khan, and K. Skadron, “Automata-to-routing: An open- source toolchain for design-space exploration of spatial automata pro- cessing architectures,” in2017 IEEE 25th Annual International Sym- posium on Field-Programmable Custom Computing Machines (FCCM). IEEE, 2017, pp. 180–187
work page 2017
-
[11]
L. Breiman, “Random forests,”Machine learning, vol. 45, no. 1, pp. 5–32, 2001
work page 2001
-
[12]
Grapefruit: An open-source, full-stack, and customizable automata processing on fp- gas,
R. Rahimi, E. Sadredini, M. Stan, and K. Skadron, “Grapefruit: An open-source, full-stack, and customizable automata processing on fp- gas,” in2020 IEEE 28th Annual International Symposium on Field- Programmable Custom Computing Machines (FCCM). IEEE, 2020, pp. 138–147
work page 2020
-
[13]
X. Wang, L. Gong, J. Cao, W. Lou, W. Wang, C. Wang, and X. Zhou, “Hap: A spatial-von neumann heterogeneous automata processor with optimized resource and io overhead on fpga,” inProceedings of the 2023 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, 2023, pp. 185–196
work page 2023
-
[14]
A cellular automata system with fpga,
T. Kobori, T. Maruyama, and T. Hoshino, “A cellular automata system with fpga,” inThe 9th Annual IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM’01). IEEE, 2001, pp. 120–129
work page 2001
-
[15]
A. Subramaniyan and R. Das, “Parallel automata processor,” inPro- ceedings of the 44th Annual International Symposium on Computer Architecture, 2017, pp. 600–612
work page 2017
-
[16]
Fra-fpga: Fast reconfigurable automata processing on fpgas,
P. Zhang, S. Zhang, S. Li, J. Zhang, S. Liu, and Y . Bu, “Fra-fpga: Fast reconfigurable automata processing on fpgas,” in2022 32nd In- ternational Conference on Field-Programmable Logic and Applications (FPL). IEEE, 2022, pp. 313–321
work page 2022
-
[17]
J. Wadden, V . Dang, N. Brunelle, T. Tracy II, D. Guo, E. Sadredini, K. Wang, C. Bo, G. Robins, M. Stanet al., “Anmlzoo: a benchmark suite for exploring bottlenecks in automata processing engines and architectures,” in2016 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 2016, pp. 1–12
work page 2016
-
[18]
Two-hit filter synthesis for genomic database search,
J. A. Bradshaw, R. Karakchi, and J. D. Bakos, “Two-hit filter synthesis for genomic database search,” in2016 IEEE 24th Annual Interna- tional Symposium on Field-Programmable Custom Computing Machines (FCCM). IEEE, 2016, pp. 165–172
work page 2016
-
[19]
Deep forest: Towards an alternative to deep neural networks,
Z.-H. Zhou and J. Feng, “Deep forest: Towards an alternative to deep neural networks,” inProceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), 2017, pp. 3553–3559
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.