Recognition: 2 theorem links
· Lean TheoremPractical Scaling Laws: Converting Compute into Performance in a Data-Constrained World
Pith reviewed 2026-05-12 02:53 UTC · model grok-4.3
The pith
A new scaling law form accounts for data limits and repeated training to optimize compute allocation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central proposal is the loss function L(N, D, T) = E + (L_0 - E) h / (1 + h) where h = a/N^α + b/T^β + c N^γ / D^δ. This expression isolates the effects of model size N, total tokens seen T, and unique data D while ensuring the loss saturates at physically meaningful bounds. It recovers the Chinchilla form as a special case and, once fitted to data, supports cost-sensitive optimization of the training configuration.
What carries the argument
The variable h that combines power-law terms in model size, total training tokens, and unique data inside a saturating loss expression.
If this is right
- When data costs nothing the optimal allocation matches the Chinchilla recommendation for model size and data volume.
- Higher data costs shift the optimum toward smaller unique datasets trained over additional epochs.
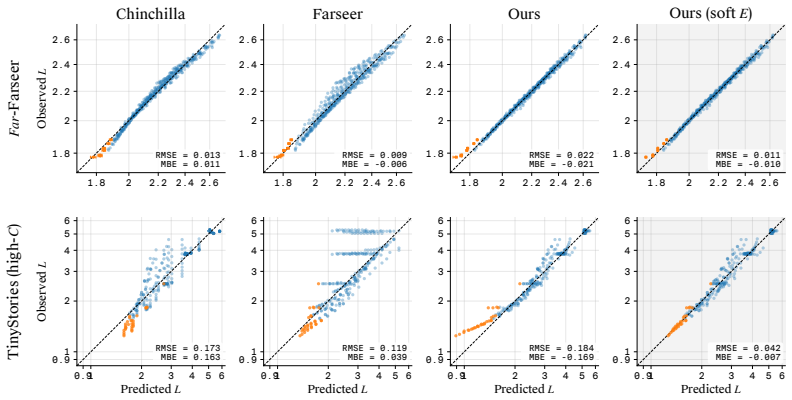
- The formula yields lower extrapolation error than prior forms on published LLM scaling grids and new multi-epoch experiments.
- The same functional form works for MLPs, ResNets, Fourier operators, and transformers across vision, science, and language tasks.
Where Pith is reading between the lines
- This allocation rule could be used to set data acquisition targets for future large training runs where web-scale unique data is finite.
- The separation of terms offers a way to attribute performance gains to changes in model size, training duration, or data diversity.
- Testing the form on reinforcement learning or multimodal models would check whether the same decomposition applies beyond supervised pretraining.
Load-bearing premise
The chosen decomposition of loss into undercapacity, undertraining, and overfitting terms with power-law dependencies continues to describe behavior accurately at scales and data regimes beyond those tested.
What would settle it
A direct test would be to measure validation loss for a set of models trained at compute levels several times larger than the fitting set, with controlled variation in unique data size and epoch count, and verify agreement with the formula's predictions.
Figures











read the original abstract
The scaling laws guiding modern model training were calibrated for a single regime: data-rich, single-epoch pretraining. The dominant such scaling law form, Chinchilla's $L = E + A/N^\alpha + B/D^\beta$, has three structural limitations outside that regime: it diverges as unique data shrinks instead of saturating at the uninformed baseline; it cannot represent overfitting when capacity exceeds the data; and it conflates total examples seen with unique examples available. We propose a closed-form extension, $L(N, D, T) = E + (L_0 - E)\,h/(1+h)$ with $h = a/N^\alpha + b/T^\beta + c\,N^\gamma/D^\delta$, that decomposes loss into undercapacity, undertraining, and overfitting terms. It saturates between the irreducible loss $E$ and an uninformed baseline $L_0$ fixed by the loss type, and reduces to Chinchilla in the data-rich, single-epoch limit. We validate it on four multi-epoch experiments spanning four architecture families (MLPs, ResNets, Fourier neural operators, and transformers) across vision, scientific ML, and language domains, and refit it to five published LLM scaling-law grids. Extrapolating to higher compute and larger unique data than seen at fit time, our form achieves state-of-the-art RMSE on every published LLM grid we evaluate and on most cells of our constructed experiments. Once calibrated, the form admits a cost-aware allocation that recovers Chinchilla's optimum when data is free and shifts toward smaller corpora and more epochs as data grows expensive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a closed-form extension to Chinchilla scaling laws, L(N, D, T) = E + (L0 - E) h/(1+h) with h = a/N^α + b/T^β + c N^γ/D^δ, to handle data-constrained regimes by decomposing loss into undercapacity, undertraining, and overfitting terms. It saturates at an uninformed baseline L0, reduces to Chinchilla when T=D and the overfitting term vanishes, and is validated on multi-epoch experiments across four architecture families plus refits to five published LLM grids, claiming superior RMSE on extrapolations to higher compute and unique data.
Significance. If the functional form and its decomposition generalize, the work would be significant for practical scaling in data-limited settings by enabling cost-aware allocation of compute that shifts toward more epochs on smaller corpora as data becomes expensive. The explicit reduction to Chinchilla, saturation property, and validation across vision, scientific ML, and language domains are clear strengths.
major comments (2)
- [Abstract] Abstract, proposed equation: The headline claim of state-of-the-art RMSE on extrapolation to higher compute and larger unique data than seen at fit time is evaluated after fitting parameters to the same grids; this creates a circularity risk for the extrapolation advantage, as the specific additive structure inside h and the nine free parameters (E, L0, a, b, c, α, β, γ, δ) are chosen empirically rather than derived.
- [Validation experiments] Validation on published LLM grids: While the form recovers Chinchilla in the appropriate limit and improves RMSE on the tested grids, the central extrapolation claim rests on post-fit performance within or near the fitting range; independent verification on new architectures, data distributions, or substantially larger regimes (beyond the four families and five grids) is needed to support generalization of the decomposition.
minor comments (1)
- The nine free parameters and their roles in the functional form would benefit from a dedicated table or explicit listing in the methods section for reader clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with point-by-point responses. Revisions have been made to clarify the extrapolation procedure and to discuss validation limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract, proposed equation: The headline claim of state-of-the-art RMSE on extrapolation to higher compute and larger unique data than seen at fit time is evaluated after fitting parameters to the same grids; this creates a circularity risk for the extrapolation advantage, as the specific additive structure inside h and the nine free parameters (E, L0, a, b, c, α, β, γ, δ) are chosen empirically rather than derived.
Authors: We appreciate the concern about potential circularity. The extrapolation procedure fits parameters only on subsets corresponding to lower compute budgets and smaller unique data sizes, then evaluates RMSE on held-out points with higher compute and larger unique data. This split is described in the validation sections. The functional form is empirical but deliberately constructed to enforce saturation between E and L0 and exact reduction to the Chinchilla law when T = D and the overfitting term vanishes; these constraints provide structure beyond pure curve-fitting. We have revised the abstract and added an explicit paragraph in the methods section detailing the train/test splits and fitting protocol to eliminate ambiguity. The nine parameters are fitted per dataset, consistent with other scaling-law literature. revision: partial
-
Referee: [Validation experiments] Validation on published LLM grids: While the form recovers Chinchilla in the appropriate limit and improves RMSE on the tested grids, the central extrapolation claim rests on post-fit performance within or near the fitting range; independent verification on new architectures, data distributions, or substantially larger regimes (beyond the four families and five grids) is needed to support generalization of the decomposition.
Authors: We agree that broader independent verification would strengthen claims of generalization. The current validation covers multi-epoch runs across four architecture families (MLPs, ResNets, Fourier neural operators, transformers) in vision, scientific ML, and language, plus refits to five published LLM grids. These already exceed the scope of most prior scaling-law studies. We acknowledge, however, that the tested regimes do not include entirely new architectures or substantially larger scales beyond the available published grids. We have added a limitations subsection in the discussion that explicitly notes the current validation scope and outlines the need for future tests on larger regimes and new distributions. revision: partial
- Independent verification on new architectures, data distributions, or substantially larger regimes beyond the four families and five grids
Circularity Check
No significant circularity in the proposed scaling-law extension
full rationale
The paper proposes an empirical closed-form extension to Chinchilla scaling that is deliberately constructed to recover the original law in the data-rich single-epoch limit and to saturate at an uninformed baseline; this is a design choice, not a derivation that collapses to its inputs. Parameters are fitted to held-out subsets of multi-epoch experiments and published LLM grids, with performance claims tied to extrapolation beyond the fitting range (higher compute and unique data). No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked. The central result is therefore an independent functional ansatz whose predictive advantage is measured on data points outside the fit, satisfying the requirement for self-contained empirical validation rather than any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- E, L0, a, b, c, alpha, beta, gamma, delta
axioms (1)
- domain assumption Loss can be expressed as a saturating function of undercapacity, undertraining, and overfitting terms that reduces to Chinchilla form in the data-rich single-epoch limit.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L(N, D, T) = E + (L0 − E) h/(1 + h) with h = a/N^α + b/T^β + c N^γ/D^δ ... decomposes loss into undercapacity, undertraining, and overfitting terms
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
recovers Chinchilla in the data-rich, single-epoch limit ... cost-aware allocation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alabdulmohsin, Behnam Neyshabur, and Xiaohua Zhai
Ibrahim M. Alabdulmohsin, Behnam Neyshabur, and Xiaohua Zhai. Revisiting neural scaling laws in language and vision. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[2]
Claude Code: Anthropic’s agentic coding system
Anthropic. Claude Code: Anthropic’s agentic coding system. https://www.anthropic. com/product/claude-code, 2026
work page 2026
-
[3]
Anthropic. Claude Opus 4.7 System Card. https://www.anthropic.com/ claude-opus-4-7-system-card, April 2026
work page 2026
-
[4]
Neil Ashton, Johannes Brandstetter, and Siddhartha Mishra. Fluid intelligence: A forward look on AI foundation models in computational fluid dynamics.arXiv preprint arXiv:2511.20455, 2025
-
[5]
Explaining neural scaling laws , volume=
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27), 2024. doi: 10.1073/pnas.2311878121
-
[6]
Hritik Bansal, Arian Hosseini, Rishabh Agarwal, Vinh Q. Tran, and Mehran Kazemi. Smaller, weaker, yet better: Training LLM reasoners via compute-optimal sampling.arXiv preprint arXiv:2408.16737, 2024
-
[7]
Peter L. Bartlett, Philip M. Long, Gábor Lugosi, and Alexander Tsigler. Benign overfitting in linear regression.Proceedings of the National Academy of Sciences, 117(48):30063–30070, 2020
work page 2020
-
[8]
doi:10.1073/pnas.1903070116 , year = 2019, month =
Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal. Reconciling modern machine- learning practice and the classical bias-variance trade-off.Proceedings of the National Academy of Sciences, 116(32):15849–15854, 2019. doi: 10.1073/pnas.1903070116
-
[9]
Tamay Besiroglu, Ege Erdil, Matthew Barnett, and Josh You. Chinchilla scaling: A replication attempt.arXiv preprint arXiv:2404.10102, 2024
-
[10]
A dynamical model of neural scaling laws
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[11]
Neural scaling laws rooted in the data distribution.arXiv preprint arXiv:2412.07942, 2024
Ari Brill. Neural scaling laws rooted in the data distribution.arXiv preprint arXiv:2412.07942, 2024
-
[12]
Ethan Caballero, Kshitij Gupta, Irina Rish, and David Krueger. Broken neural scaling laws. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[13]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramèr, and Chiyuan Zhang. Quantifying memorization across neural language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[14]
A hitchhiker’s guide to scaling law estimation
Leshem Choshen, Yang Zhang, and Jacob Andreas. A hitchhiker’s guide to scaling law estimation. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[15]
Tinystories: How small can language models be and still speak coherent english?
Ronen Eldan and Yuanzhi Li. TinyStories: How small can language models be and still speak coherent English?arXiv preprint arXiv:2305.07759, 2023
-
[16]
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Ni...
work page 2025
-
[17]
Scaling laws and compute-optimal training beyond fixed training durations
Alexander Hägele, Elie Bakouch, Atli Kosson, Loubna Ben Allal, Leandro V on Werra, and Martin Jaggi. Scaling laws and compute-optimal training beyond fixed training durations. In Advances in Neural Information Processing Systems (NeurIPS), 2024. 10
work page 2024
-
[18]
Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J. Tibshirani. Surprises in high- dimensional ridgeless least squares interpolation.Annals of Statistics, 50(2):949–986, 2022
work page 2022
-
[19]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InConference on Computer Vision and Pattern Recognition (CVPR), pages 770– 778, 2016
work page 2016
-
[20]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. InEuropean Conference on Computer Vision (ECCV), pages 630–645, 2016
work page 2016
-
[21]
Early stopping in deep networks: Double descent and how to eliminate it
Reinhard Heckel and Fatih Furkan Yilmaz. Early stopping in deep networks: Double descent and how to eliminate it. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[22]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, Chris Hallacy, Benjamin Mann, Alec Radford, Aditya Ramesh, Nick Ryder, Daniel M. Ziegler, John Schulman, Dario Amodei, and Sam McCandlish. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010....
work page internal anchor Pith review arXiv 2010
-
[23]
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer.arXiv preprint arXiv:2102.01293, 2021
-
[24]
Danny Hernandez, Tom B. Brown, Tom Conerly, Nova DasSarma, Dawn Drain, Sheer El- Showk, Nelson Elhage, Zac Hatfield-Dodds, Tom Henighan, Tristan Hume, Scott Johnston, Ben Mann, Chris Olah, Catherine Olsson, Dario Amodei, Nicholas Joseph, Jared Kaplan, and Sam McCandlish. Scaling laws and interpretability of learning from repeated data.arXiv preprint arXiv...
-
[25]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review arXiv 2017
-
[26]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page 2022
-
[27]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[28]
Tanishq Kumar, Zachary Ankner, Benjamin F. Spector, Blake Bordelon, Niklas Muennighoff, Mansheej Paul, Cengiz Pehlevan, Christopher Ré, and Aditi Raghunathan. Scaling laws for precision. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[29]
Farseer: A refined scaling law in large language models
Houyi Li, Wenzhen Feng, Qiufeng Hu, Zili Zhou, Shuigeng Zhang, Haoyu Xu, Xiangyu Zhang, Jinyang Jiao, Peng Wang, Jing Liu, Xiaolong Jin, Zhi-Hua Ling, Yi Zhang, and Zhiyuan Fan. Farseer: A refined scaling law in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[30]
(Mis)Fitting: A survey of scaling laws
Margaret Li, Sneha Kudugunta, and Luke Zettlemoyer. (Mis)Fitting: A survey of scaling laws. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[31]
Fourier neural operator for parametric partial differen- tial equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[32]
arXiv preprint arXiv:2510.06548 , year=
Seng Pei Liew and Takuya Kato. Reusing overtrained language models saturates scaling.arXiv preprint arXiv:2510.06548, 2025. 11
-
[33]
Can language models discover scaling laws?arXiv preprint arXiv:2507.21184, 2025
Haowei Lin, Haotian Ye, Wenzheng Feng, Quzhe Huang, Yujun Li, Hubert Lim, Zhengrui Li, Xiangyu Wang, Jianzhu Ma, Yitao Liang, and James Zou. Can language models discover scaling laws?arXiv preprint arXiv:2507.21184, 2025
-
[34]
arXiv preprint arXiv:2210.16859 , year=
Alexander Maloney, Daniel A. Roberts, and James Sully. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
-
[35]
Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and the double descent curve.Communications on Pure and Applied Mathematics, 75(4):667–766, 2022
work page 2022
-
[36]
Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[37]
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003, 2021. doi: 10.1088/1742-5468/ac3a74
-
[38]
Reconciling Kaplan and Chinchilla scaling laws.Transactions on Machine Learning Research, 2024
Tim Pearce and Jinyeop Song. Reconciling Kaplan and Chinchilla scaling laws.Transactions on Machine Learning Research, 2024
work page 2024
-
[39]
Scaling laws for pre-training agents and world models
Tim Pearce, Tabish Rashid, Dave Bignell, Raluca Georgescu, Sam Devlin, and Katja Hofmann. Scaling laws for pre-training agents and world models. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
work page 2025
-
[40]
Data scaling laws for radiology foundation models.arXiv preprint arXiv:2509.12818, 2025
Chantal Pellegrini et al. Data scaling laws for radiology foundation models.arXiv preprint arXiv:2509.12818, 2025
-
[41]
Resolv- ing discrepancies in compute-optimal scaling of language models
Tomer Porian, Mitchell Wortsman, Jenia Jitsev, Ludwig Schmidt, and Yair Carmon. Resolv- ing discrepancies in compute-optimal scaling of language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[42]
Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit
Jonathan S. Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit. A constructive prediction of the generalization error across scales. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[43]
Beyond Chinchilla- Optimal: Accounting for inference in language model scaling laws
Nikhil Sardana, Jacob Portes, Sasha Doubov, and Jonathan Frankle. Beyond Chinchilla- Optimal: Accounting for inference in language model scaling laws. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[44]
Shashank Subramanian, Peter Harrington, Kurt Keutzer, Wahid Bhimji, Dmitriy Morozov, Michael W. Mahoney, and Amir Gholami. Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[45]
PDEBench: An extensive benchmark for scientific machine learning
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. PDEBench: An extensive benchmark for scientific machine learning. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2022
work page 2022
-
[46]
Markosyan, Luke Zettlemoyer, and Armen Aghajanyan
Kushal Tirumala, Aram H. Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. Memo- rization without overfitting: Analyzing the training dynamics of large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[47]
Position: Will we run out of data? limits of LLM scaling based on human-generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of LLM scaling based on human-generated data. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
work page 2024
-
[48]
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transform- ers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[49]
Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. When scaling meets LLM finetuning: The effect of data, model and finetuning method. InInternational Conference on Learning Representations (ICLR), 2024. 12 Appendix Contents A The uninformed baselineL 0 15 B Limit verification 15 C Chinchilla recovery 16 D Choice of saturating wrapper 17 E Remarks o...
work page 2024
-
[50]
Calibrate the form on a domain-specific training grid to obtain (E, a, b, c, α, β, γ, δ) and L0 (Section 3)
-
[51]
Specify the price pair (ρD, ρC) for the deployment setting and an architecture-dependent FLOP-per-step constantk
-
[52]
Solve Equation (10) (for P1) or (11) (for P2) jointly with the active constraint over(N, D, T) until the stationarity conditions hold to tolerance
-
[53]
Read off the dual quantities: B∗ and (N ∗, D∗, T ∗, T ∗/D∗) for P1, or L∗ and the same allocation for P2. Cost ratios and the data-constrained regime.A useful summary statistic is the dollar-cost ratio η=ρ D/ρC. For LLM pretraining on web-scraped data η is small (data is cheap, compute domi- nates) and the Chinchilla-style optimum approximates both (P1) a...
-
[54]
Sweep A (contamination threshold).Restricting training to D≥50 keeps ours competitive with Muennighoff on theD= 60,000 holdout (RMSE inside bootstrap CIs throughk= 5–8 , with ours winning cleanly at k= 6 ). Adding D= 20 lets Muennighoff edge ahead, and adding D= 10 flips the comparison cleanly (ours 0.126±0.004 vs. Muennighoff 0.109±0.001). The contaminat...
-
[55]
Sweep B (range of over-extrapolation).With the smallest- D cells fixed in training, ours’ held-out MBE is +0.17 to +0.21 on every held-out target from D= 1,000 to D= 31,600 (four orders of magnitude); Chinchilla and Muennighoff hold at [+0.02,+0.04] and [+0.03,+0.07] respectively. The over-prediction collapses only when training contains neighbors of the ...
work page 1942
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.