Recognition: no theorem link
Sparsity Moves Computation: How FFN Architecture Reshapes Attention in Small Transformers
Pith reviewed 2026-05-12 02:53 UTC · model grok-4.3
The pith
Sparse MoE routing in the FFN block shifts computation into the attention layers of one-layer Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In one-layer Transformers trained on digit addition with carry, modular arithmetic, and histogram counting, sparse MoE routing in the FFN shifts computation to attention; this redistribution arises from reduced per-token FFN capacity and sparse partitioning across experts, as shown by frozen random routing nearly matching the effects of learned routing.
What carries the argument
Sparse MoE routing in the FFN, which lowers per-token capacity and partitions tokens across experts, thereby forcing attention to handle more of the overall computation.
If this is right
- Attention layers learn to perform operations such as carry propagation that would otherwise be handled inside the FFN.
- The same sparsity-induced redistribution occurs under random fixed routing, showing that learned router specialization is not required.
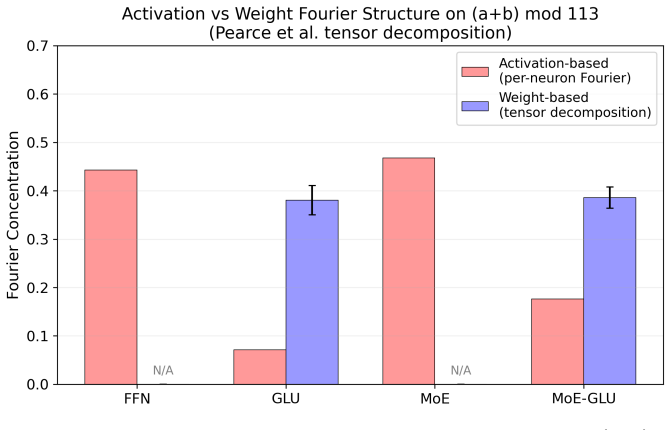
- GLU multiplicative gating moves structured Fourier components out of individual neuron bases and into distributed subspaces.
- The effect is strongest on carry-based addition and weaker on modular arithmetic and counting tasks.
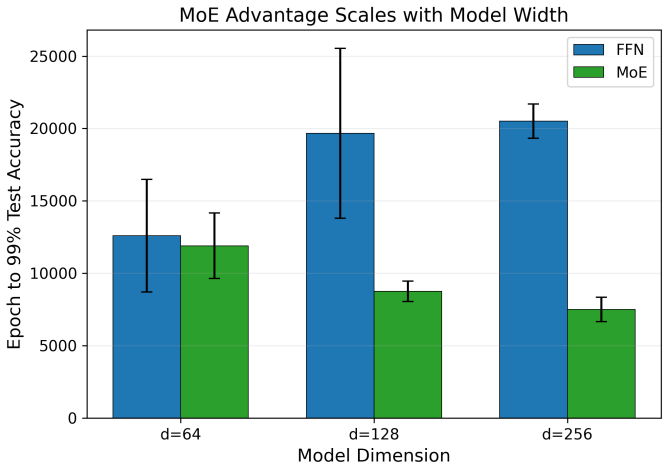
- Parameter-matched narrow FFNs and top-2 MoE variants reproduce the same pattern of attention compensation.
Where Pith is reading between the lines
- Designers of larger sparse models may need to monitor attention capacity when increasing FFN sparsity, since the compensation effect observed here could scale.
- Interpretability methods that inspect single FFN neurons may miss task structure once GLU gating is used, requiring instead analysis of attention or combined subspaces.
- The finding raises the possibility that sparsity in one block systematically alters the division of labor across all blocks, a pattern worth testing on sequence modeling tasks beyond arithmetic.
Load-bearing premise
The observed shift of computation can be cleanly measured and attributed to reduced per-token FFN capacity and sparse expert partitioning without unaccounted interactions from training dynamics or multi-layer effects.
What would settle it
A controlled run in which widening the FFN experts or switching to dense routing eliminates the measured increase in attention-layer activity on carry-addition examples while keeping total parameters fixed.
Figures
























read the original abstract
Architectural choices inside the Transformer feedforward network (FFN) block do not merely affect the block itself; they reshape the computations learned by the rest of the model. We study this effect in one-layer Transformers trained on digit addition with carry, modular arithmetic, and histogram counting. Comparing dense FFNs, gated linear units (GLUs), mixture-of-experts (MoE), and MoE-GLUs, we find that sparse MoE routing can shift computation from FFN to attention, with the strongest ablation-visible effect on carry-based addition. We decompose this redistribution into reduced per-token FFN capacity and sparse partitioning across experts. Critically, frozen random routing nearly matches learned routing, suggesting that redistribution is driven largely by architectural sparsity rather than router-learned specialization. As a secondary finding, GLU-style multiplicative gating rotates task-relevant Fourier structure out of the per-neuron basis and into distributed subspaces, making neuron-level interpretability less informative while preserving structured computation. We validate these conclusions with random-routing, narrow-FFN, and top-2 MoE controls, plus parameter-matching, activation-function, and width-scaling analyses. Together, these results show that local FFN design choices can have nonlocal consequences for Transformer computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in one-layer Transformers trained on carry-based addition, modular arithmetic, and histogram counting, sparse MoE FFN architectures shift computation from the FFN to attention layers. This redistribution is driven primarily by reduced per-token FFN capacity and sparse expert partitioning rather than learned router specialization, as frozen random routing nearly matches learned routing. A secondary claim is that GLU multiplicative gating rotates task-relevant Fourier structure into distributed subspaces, reducing neuron-level interpretability. These conclusions are supported by ablations including random-routing, narrow-FFN, top-2 MoE, parameter-matching, activation-function, and width-scaling controls.
Significance. If the results hold, they establish that local FFN design choices have measurable nonlocal effects on Transformer computation allocation, with implications for interpretability and architecture search in small models. The empirical strength comes from the explicit set of controls (random routing, parameter matching, width scaling) that isolate architectural sparsity as the driver, providing reproducible evidence for the redistribution hypothesis on simple tasks where effects are visible.
major comments (1)
- [Abstract and §3-4] Abstract and experimental sections: the central claim that sparse MoE 'shifts computation from FFN to attention' depends on a precise, reproducible definition of the shift metric (e.g., changes in attention output norms, head-wise activation magnitudes, or task-specific attribution). Without an explicit formula or procedure for this quantification, it is difficult to evaluate the magnitude of the effect or confirm that the ablations (random routing, narrow-FFN) correctly attribute it to sparsity rather than other factors.
minor comments (2)
- [Methods] Expand the description of how 'frozen random routing' is implemented (e.g., whether the router is replaced by fixed random weights or sampling) and confirm it preserves the same parameter count and sparsity pattern as learned routing.
- [§4 (Ablations)] The width-scaling and parameter-matching analyses should report exact parameter counts and FLOPs for each variant to allow direct verification that controls are fair.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the recommendation of minor revision, and the careful identification of a clarity issue in our central claim. We address the point below and will revise the manuscript to incorporate an explicit definition of the shift metric.
read point-by-point responses
-
Referee: [Abstract and §3-4] Abstract and experimental sections: the central claim that sparse MoE 'shifts computation from FFN to attention' depends on a precise, reproducible definition of the shift metric (e.g., changes in attention output norms, head-wise activation magnitudes, or task-specific attribution). Without an explicit formula or procedure for this quantification, it is difficult to evaluate the magnitude of the effect or confirm that the ablations (random routing, narrow-FFN) correctly attribute it to sparsity rather than other factors.
Authors: We agree that an explicit, reproducible definition strengthens the paper. In the current manuscript the redistribution is quantified via two complementary measures reported in §3–4: (1) the relative L2 norm of the attention-block output versus the FFN-block output, normalized by the total residual-stream norm at each token (averaged over the test set), and (2) head-wise mean activation magnitudes in attention together with per-expert activation frequencies in the MoE FFN. These quantities are compared across dense, GLU, MoE, and MoE-GLU architectures under identical training protocols. To address the concern we will add a dedicated subsection titled “Quantifying Computation Redistribution” immediately before the experimental results. It will contain the exact formulas, the aggregation procedure over tokens and heads, and a short pseudocode block showing how the same metric is applied to the random-routing and narrow-FFN ablations. This addition will make it straightforward to verify that the observed shift is driven by capacity reduction and partitioning rather than router specialization. revision: yes
Circularity Check
No significant circularity; empirical study with independent experimental controls
full rationale
The paper is an empirical investigation of FFN architecture effects on attention in one-layer Transformers, relying on direct ablation experiments (random routing, narrow FFN, parameter-matched, width-scaling) across tasks like carry addition and modular arithmetic. No mathematical derivation chain, self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the claims or abstract. The redistribution findings are grounded in observable ablation differences rather than any reduction to inputs by construction, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training on synthetic arithmetic and counting tasks reveals general principles of Transformer computation redistribution
Reference graph
Works this paper leans on
-
[1]
Searching for Activation Functions
URL http://arxiv.org/abs/1710.05941. 530 citations (Semantic Scholar/arXiv) [2024-05-16] arXiv:1710.05941 [cs]. Noam Shazeer. GLU Variants Improve Transformer, February 2020. URL http://arxiv.org/ abs/2002.05202. 390 citations (Semantic Scholar/arXiv) [2024-05-16] arXiv:2002.05202 [cs, stat] version: 1. Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Train/test: 30%/70% of all 1132 pairs
Loss at position 2. Train/test: 30%/70% of all 1132 pairs. Full-batch training, 40k epochs, weight decay 1.0. Networks develop discrete Fourier circuits with per-neuron frequency selectivity [Nanda et al., 2023]. Histogram counting.Given L=10 tokens from alphabet T=32 , predict each token’s count. Illus- trative L=6 example (the full task uses L=10): [2,0...
work page 2023
-
[3]
This reveals each component’s contribution to the final prediction
Component ablation: Zero attention or FFN output at inference and measure per-token output accuracy degradation. This reveals each component’s contribution to the final prediction
-
[4]
Each term’s projection through WU gives that component’s contribution to the correct output logit
Direct logit attribution (DLA): Decompose output logits into additive contributions via the residual stream [Nanda et al., 2023, Quirke and Barez, 2023]: logits=W U(xembed +x attn + xffn). Each term’s projection through WU gives that component’s contribution to the correct output logit
work page 2023
-
[5]
This provides causalevidence for which component carries the decision [Meng et al., 2022]
Activation patching: For pairs of inputs requiring different operations at the same position, swap attention or FFN activations and measure whether the prediction flips. This provides causalevidence for which component carries the decision [Meng et al., 2022]
work page 2022
-
[6]
Linear probes: Train a single layer (logistic regression) to predict the operation type (+7/+1/+0) from attention or FFN outputs. Trained with Adam ( lr=10−3, no weight decay), cross-entropy loss, batch size 128, for 500 steps on a 70/30 train/test split of the 1000 examples. This is the weakest possible probe, so 100% accuracy means the features are line...
-
[7]
High concentration means the neuron responds cleanly to one frequency
Fourier analysis (activation-based): For modular addition, compute per-neuron Fourier concentration as the fraction of spectral power at the dominant frequency when activations are viewed as a function of (a+b) modp[Nanda et al., 2023] . High concentration means the neuron responds cleanly to one frequency. For add-7, where there is no canonical cyclic gr...
work page 2023
-
[8]
22 as a weight-space analogue of the activation-based metric above
Fourier analysis (weight-based, GLU only): Used in Fig. 22 as a weight-space analogue of the activation-based metric above. The pipeline: (a) Bilinear tensor .Following the bilinear interpretation of GLU [Pearce et al., 2024], form the third-order tensor Tijk = P m Wdown[i, m]W gate[m, j]W up[m, k] from the raw weight matrices, so that GLU(x)i ≈ P j,k Tij...
work page 2024
-
[9]
Ablate individual experts and measure per-operation accuracy drops
Routing analysis(MoE): Compute normalized mutual information between expert assign- ment and operation type. Ablate individual experts and measure per-operation accuracy drops. C Redistribution Supporting Evidence C.1 Norm vs. No-Norm Comparison We train without RMSNorm following standard practice in mechanistic interpretability [Nanda et al., 2023, Quirk...
work page 2023
-
[10]
On add-7, per-active matching more than halves the redistribution( 41.7%→18.3% ). Increasing per-token capacity from 1/E of dense to full dense, while keeping the sparse- partitioning architecture, removes most of the no-FFN gap. This is consistent with the narrow-dense-FFN control in the main text (Sec. 4.2), which attributes a substantial fraction of th...
-
[11]
1.6%, both close to dense FFN’s1.3%)
On modular addition, both conventions give negligible redistribution( 2.6% vs. 1.6%, both close to dense FFN’s1.3%). Modular addition’s reliance on Fourier circuits exceeds attention’s expressive capacity[Nanda et al., 2023], so attention cannot absorb FFN compu- tation regardless of bottleneck severity, and the matching convention has little effect
work page 2023
-
[12]
MoE-GLU does better only because it has more total parameters
On histogram, both conventions give identical no-FFN( 10.4% vs. 10.2%, both at the chance line for L=10 tokens). Histogram is the non-substitutable control: both matching conventions leave no-FFN accuracy at chance. Appendix H shows that histogram strategies can shift internally, especially in the FFN-family, but the FFN remains necessary for the count re...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.