Recognition: no theorem link
Rethinking Constraint Awareness for Efficient State Embedding of Neural Routing Solver
Pith reviewed 2026-05-12 03:38 UTC · model grok-4.3
The pith
Constraint-Aware Residual Modulation lets neural routing solvers use global observation spaces without losing constraint sensitivity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
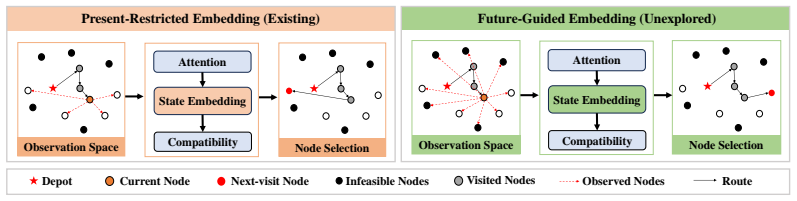
Current state-embedding mechanisms in neural routing solvers restrict the observation space seen by attention at each decoding step, creating a bottleneck that prevents high-quality solutions once constraints become non-trivial. Preserving the full global observation space removes this restriction but makes the embedding constraint-agnostic. The Constraint-Aware Residual Modulation module overcomes the second problem by adaptively scaling the context embedding with a small set of constraint-relevant variables, thereby allowing the decoder to exploit the global space while remaining sensitive to active constraints.
What carries the argument
Constraint-Aware Residual Modulation (CARM) module, which adaptively scales the context embedding by a vector computed from current constraint variables before compatibility scores are calculated.
If this is right
- Equipping existing single-task and multi-task neural solvers with CARM produces measurable gains on large-scale instances without architectural overhaul.
- The same module improves generalization when a solver trained on one VRP variant is applied to another variant it has never seen.
- Global observation spaces become usable once constraint sensitivity is restored through lightweight residual modulation.
- The approach is architecture-agnostic enough to be dropped into multiple decoder designs while preserving their original encoder structure.
Where Pith is reading between the lines
- Similar residual-modulation tricks could be inserted at the encoder stage to propagate constraint information earlier in the network.
- The same observation-space analysis may apply to other neural combinatorial solvers that rely on sequential decoding, such as those for scheduling or packing.
- If CARM generalizes, future work can treat constraint variables as an explicit modulation channel rather than relying solely on learned attention weights.
Load-bearing premise
The observation-space bottleneck and the effectiveness of residual modulation with constraint variables will continue to appear in solvers and VRP variants outside the six architectures and problem families tested.
What would settle it
Run any of the baseline solvers on a new VRP variant with tighter or qualitatively different constraints at scales larger than those reported; if solution quality does not improve or degrades after CARM is added, the central claim is falsified.
Figures



read the original abstract
Heavy-Encoder-Light-Decoder (HELD) neural routing solvers have emerged as a promising paradigm due to their broad applicability across multiple vehicle routing problems (VRPs). However, they typically struggle with VRP variants with complex constraints. To address this limitation, this paper systematically revisits existing neural solvers from the perspective of the generation mechanism for state embeddings (i.e., query vector prior to compatibility calculation) during decoding. We identify that current mechanisms restrict the observation space during attention computation, introducing a key bottleneck to achieving high-quality solutions. Through detailed empirical analysis, we demonstrate the necessity of preserving a global observation space. To overcome the constraint-agnostic drawback inherent to global observation spaces, we propose a simple yet powerful Constraint-Aware Residual Modulation (CARM) module. By adaptively modulating the context embedding with constraint-relevant variables, CARM effectively enhances constraint awareness, enabling the neural solver to fully leverage the global observation space and generate an efficient state embedding. Extensive experimental results across two single-task and five multi-task neural routing solvers confirm that the CARM module consistently boosts baseline performance. Notably, solvers equipped with our CARM achieve substantial improvements in scaling to large-scale instances and in generalizing to unseen VRP variants. These findings provide valuable insights for the architectural design of neural routing solvers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Heavy-Encoder-Light-Decoder neural routing solvers suffer from restricted observation space during attention-based state embedding generation in the decoder, which limits performance on VRPs with complex constraints. It identifies the need to preserve global observation space and proposes the Constraint-Aware Residual Modulation (CARM) module to adaptively modulate context embeddings with constraint-relevant variables, thereby enhancing constraint awareness. Extensive experiments across two single-task and five multi-task solvers show that adding CARM yields consistent performance gains, particularly in scaling to large instances and generalizing to unseen VRP variants.
Significance. If the results hold, the work provides a simple, plug-in module that addresses a practical limitation in neural VRP solvers by reconciling global observation spaces with constraint sensitivity. The breadth of validation across multiple solver architectures is a strength, offering concrete evidence that targeted modulation can improve solution quality without redesigning the core attention mechanism.
major comments (2)
- [Experiments section (and associated ablation tables)] The causal attribution of performance gains to the specific residual modulation mechanism in CARM (rather than to increased input dimensionality or parameter count) is not isolated. No ablation compares CARM against a control that simply appends constraint variables as extra channels to the context embedding without the modulation step; such a control is required to establish that the proposed adaptive modulation is necessary for the observed improvements in scaling and generalization.
- [§3 (CARM module) and §5 (empirical analysis)] The paper does not report attention-map statistics, embedding-norm comparisons, or query-vector analyses before and after CARM application. Without these, the claim that CARM overcomes the 'constraint-agnostic drawback' of global observation spaces remains correlational rather than mechanistic.
minor comments (2)
- [Abstract] The abstract states results across 'two single-task and five multi-task neural routing solvers' but does not name the specific solvers or VRP variants used; adding these names would improve reproducibility and context.
- [Figures and Tables] Ensure that all experimental figures include error bars or statistical significance indicators, and that table captions explicitly define the metrics (e.g., optimality gap, runtime) and baseline configurations.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and rigor of our work. We address each major comment below, and have made revisions to the manuscript to incorporate additional experiments and analyses as suggested.
read point-by-point responses
-
Referee: [Experiments section (and associated ablation tables)] The causal attribution of performance gains to the specific residual modulation mechanism in CARM (rather than to increased input dimensionality or parameter count) is not isolated. No ablation compares CARM against a control that simply appends constraint variables as extra channels to the context embedding without the modulation step; such a control is required to establish that the proposed adaptive modulation is necessary for the observed improvements in scaling and generalization.
Authors: We agree with the referee that a control experiment isolating the residual modulation from mere dimensionality increase is necessary to establish causality. We have performed and included in the revised manuscript an ablation where constraint variables are appended as extra channels to the context embedding without the modulation step. The results, now reported in the updated Experiments section and ablation tables, show that this control underperforms CARM, especially on large instances and unseen variants, confirming that the adaptive modulation is key to the gains. revision: yes
-
Referee: [§3 (CARM module) and §5 (empirical analysis)] The paper does not report attention-map statistics, embedding-norm comparisons, or query-vector analyses before and after CARM application. Without these, the claim that CARM overcomes the 'constraint-agnostic drawback' of global observation spaces remains correlational rather than mechanistic.
Authors: We acknowledge the value of mechanistic analyses to support our claims. In the revised manuscript, we have added in §5 attention-map statistics, embedding-norm comparisons, and query-vector analyses comparing before and after CARM. These reveal that CARM results in attention distributions more aligned with constraint satisfaction and normalized embeddings that better encode constraint information, providing mechanistic evidence for overcoming the constraint-agnostic nature of global observation spaces. revision: yes
Circularity Check
No significant circularity; central claims rest on empirical results
full rationale
The paper identifies an observation-space bottleneck via empirical analysis of attention mechanisms in HELD solvers, then introduces the CARM module as an architectural addition whose value is demonstrated through performance gains on single- and multi-task VRP instances. No equations, uniqueness theorems, or derivations are presented that reduce by construction to fitted parameters, self-citations, or renamed inputs. The load-bearing steps are experimental comparisons rather than analytical predictions that loop back to the original data or assumptions, leaving the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention computation in decoders benefits from preserving full global observation space for state embeddings
invented entities (1)
-
Constraint-Aware Residual Modulation (CARM) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Krishna Veer Tiwari and Satyendra Kumar Sharma. An optimization model for vehicle routing problem in last-mile delivery.Expert Systems with Applications, 222:119789, 2023
work page 2023
-
[2]
Kubra Sar and Pezhman Ghadimi. A systematic literature review of the vehicle routing problem in reverse logistics operations.Computers & Industrial Engineering, 177:109011, 2023
work page 2023
-
[3]
Keld Helsgaun. An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems.Roskilde: Roskilde University, 12, 2017
work page 2017
-
[4]
Hybrid genetic search for the cvrp: Open-source implementation and swap* neighborhood
Thibaut Vidal. Hybrid genetic search for the cvrp: Open-source implementation and swap* neighborhood. Computers & Operations Research, 140:105643, 2022
work page 2022
-
[5]
Yoshua Bengio, Andrea Lodi, and Antoine Prouvost. Machine learning for combinatorial optimization: a methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, 2021
work page 2021
-
[6]
Survey on neural routing solvers.arXiv preprint arXiv:2602.21761, 2026
Yunpeng Ba, Xi Lin, Changliang Zhou, Ruihao Zheng, Zhenkun Wang, Xinyan Liang, Zhichao Lu, Jianyong Sun, Yuhua Qian, and Qingfu Zhang. Survey on neural routing solvers.arXiv preprint arXiv:2602.21761, 2026
-
[7]
Yang Li, Jinpei Guo, Runzhong Wang, Hongyuan Zha, and Junchi Yan. Fast t2t: Optimization consistency speeds up diffusion-based training-to-testing solving for combinatorial optimization.Advances in Neural Information Processing Systems, 37:30179–30206, 2024
work page 2024
-
[8]
Difusco: Graph-based diffusion solvers for combinatorial optimization
Zhiqing Sun and Yiming Yang. Difusco: Graph-based diffusion solvers for combinatorial optimization. Advances in Neural Information Processing Systems, 36:3706–3731, 2023
work page 2023
-
[9]
Ruizhong Qiu, Zhiqing Sun, and Yiming Yang. Dimes: A differentiable meta solver for combinatorial optimization problems.Advances in Neural Information Processing Systems, 35:25531–25546, 2022
work page 2022
-
[10]
Invit: A generalizable routing problem solver with invariant nested view transformer
Han Fang, Zhihao Song, Paul Weng, and Yutong Ban. Invit: A generalizable routing problem solver with invariant nested view transformer. InInternational Conference on Machine Learning, 2024
work page 2024
-
[11]
Changliang Zhou, Xi Lin, Zhenkun Wang, and Qingfu Zhang. Learning to reduce search space for generalizable neural routing solver.arXiv preprint arXiv:2503.03137, 2025
-
[12]
Destroy and repair using hyper-graphs for routing
Ke Li, Fei Liu, Zhenkun Wang, and Qingfu Zhang. Destroy and repair using hyper-graphs for routing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18341–18349, 2025
work page 2025
-
[13]
Haoran Ye, Jiarui Wang, Helan Liang, Zhiguang Cao, Yong Li, and Fanzhang Li. Glop: Learning global partition and local construction for solving large-scale routing problems in real-time. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 20284–20292, 2024
work page 2024
-
[14]
Haoran Ye, Jiarui Wang, Zhiguang Cao, Helan Liang, and Yong Li. Deepaco: Neural-enhanced ant systems for combinatorial optimization.Advances in neural information processing systems, 36:43706–43728, 2023
work page 2023
-
[15]
Zhi Zheng, Changliang Zhou, Tong Xialiang, Mingxuan Yuan, and Zhenkun Wang. Udc: A unified neural divide-and-conquer framework for large-scale combinatorial optimization problems. InThirty-eighth Conference on Neural Information Processing Systems, 2024. 10
work page 2024
-
[16]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[17]
Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! In International Conference on Learning Representations, 2019
work page 2019
-
[18]
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in Neural Information Processing Systems, 33:21188–21198, 2020
work page 2020
-
[19]
Changliang Zhou, Xi Lin, Zhenkun Wang, Xialiang Tong, Mingxuan Yuan, and Qingfu Zhang. Instance- conditioned adaptation for large-scale generalization of neural routing solver.IEEE Transactions on Intelligent Transportation Systems, 2026
work page 2026
-
[20]
Neural combinatorial optimization with heavy decoder: Toward large scale generalization
Fu Luo, Xi Lin, Fei Liu, Qingfu Zhang, and Zhenkun Wang. Neural combinatorial optimization with heavy decoder: Toward large scale generalization. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[21]
Bq-nco: Bisimulation quotienting for efficient neural combinatorial optimization
Darko Drakulic, Sofia Michel, Florian Mai, Arnaud Sors, and Jean-Marc Andreoli. Bq-nco: Bisimulation quotienting for efficient neural combinatorial optimization. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[22]
Boosting neural combinatorial optimization for large-scale vehicle routing problems
Fu Luo, Xi Lin, Yaoxin Wu, Zhenkun Wang, Tong Xialiang, Mingxuan Yuan, and Qingfu Zhang. Boosting neural combinatorial optimization for large-scale vehicle routing problems. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[23]
Chengrui Gao, Haopu Shang, Ke Xue, Dong Li, and Chao Qian. Towards generalizable neural solvers for vehicle routing problems via ensemble with transferrable local policy. InInternational Joint Conference on Artificial Intelligence, 2024
work page 2024
-
[24]
Pointerformer: Deep reinforced multi-pointer transformer for the traveling salesman problem
Yan Jin, Yuandong Ding, Xuanhao Pan, Kun He, Li Zhao, Tao Qin, Lei Song, and Jiang Bian. Pointerformer: Deep reinforced multi-pointer transformer for the traveling salesman problem. InThe Thirty-Seventh AAAI Conference on Artificial Intelligence, 2023
work page 2023
-
[25]
Yeong-Dae Kwon, Jinho Choo, Iljoo Yoon, Minah Park, Duwon Park, and Youngjune Gwon. Matrix encoding networks for neural combinatorial optimization.Advances in Neural Information Processing Systems, 34:5138–5149, 2021
work page 2021
-
[26]
Minsu Kim, Junyoung Park, and Jinkyoo Park. Sym-nco: Leveraging symmetricity for neural combinatorial optimization.Advances in Neural Information Processing Systems, 35:1936–1949, 2022
work page 1936
-
[27]
Federico Berto, Chuanbo Hua, Nayeli Gast Zepeda, André Hottung, Niels Wouda, Leon Lan, Junyoung Park, Kevin Tierney, and Jinkyoo Park. Routefinder: Towards foundation models for vehicle routing problems.Transactions on Machine Learning Research, 2025
work page 2025
-
[28]
Cada: Cross-problem routing solver with constraint-aware dual-attention
Han Li, Fei Liu, Zhi Zheng, Yu Zhang, and Zhenkun Wang. Cada: Cross-problem routing solver with constraint-aware dual-attention. InProceedings of the 42nd International Conference on Machine Learning, 2025
work page 2025
-
[29]
Changliang Zhou, Canhong Yu, Shunyu Yao, Xi Lin, Zhenkun Wang, Yu Zhou, and Qingfu Zhang. Urs: A unified neural routing solver for cross-problem zero-shot generalization.arXiv preprint arXiv:2509.23413, 2025
-
[30]
Multi-task learning for routing problem with cross-problem zero-shot generalization
Fei Liu, Xi Lin, Zhenkun Wang, Qingfu Zhang, Tong Xialiang, and Mingxuan Yuan. Multi-task learning for routing problem with cross-problem zero-shot generalization. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1898–1908, 2024
work page 1908
-
[31]
Mvmoe: multi-task vehicle routing solver with mixture-of-experts
Jianan Zhou, Zhiguang Cao, Yaoxin Wu, Wen Song, Yining Ma, Jie Zhang, and Chi Xu. Mvmoe: multi-task vehicle routing solver with mixture-of-experts. InProceedings of the 41st International Conference on Machine Learning, pages 61804–61824, 2024
work page 2024
-
[32]
Ziwei Huang, Jianan Zhou, Zhiguang Cao, and Yixin Xu. Rethinking light decoder-based solvers for vehicle routing problems.International Conference on Learning Representations, 2025
work page 2025
-
[33]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. 11
work page 2018
-
[34]
PARTONOMY: Large multimodal models with part-level visual understanding
Ansel Blume, Jeonghwan Kim, Hyeonjeong Ha, Elen Chatikyan, Xiaomeng Jin, Khanh Duy Nguyen, Nanyun Peng, Kai-Wei Chang, Derek Hoiem, and Heng Ji. PARTONOMY: Large multimodal models with part-level visual understanding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[35]
Firebolt-VL: Efficient Vision-Language Understanding with Cross-Modality Modulation
Quoc-Huy Trinh, Mustapha Abdullahi, Bo Zhao, and Debesh Jha. Firebolt-vl: Efficient vision-language understanding with cross-modality modulation.arXiv preprint arXiv:2604.04579, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Jason Jordan, Mohammadreza Akbari Lor, Peter Koulen, Mei-Ling Shyu, and Shu-Ching Chen. Mdf-mllm: Deep fusion through cross-modal feature alignment for contextually aware fundoscopic image classification. arXiv preprint arXiv:2509.21358, 2025
-
[37]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[38]
Yuepeng Zheng, Fu Luo, Zhenkun Wang, Yaoxin Wu, and Yu Zhou. Mtl-kd: Multi-task learning via knowledge distillation for generalizable neural vehicle routing solver.Advances in Neural Information Processing Systems, 2025
work page 2025
-
[39]
Towards omni-generalizable neural methods for vehicle routing problems
Jianan Zhou, Yaoxin Wu, Wen Song, Zhiguang Cao, and Jie Zhang. Towards omni-generalizable neural methods for vehicle routing problems. InInternational Conference on Machine Learning, 2023
work page 2023
-
[40]
Liang Xin, Wen Song, Zhiguang Cao, and Jie Zhang. Step-wise deep learning models for solving routing problems.IEEE Transactions on Industrial Informatics, 17(7):4861–4871, 2020
work page 2020
-
[41]
Nathan Grinsztajn, Daniel Furelos-Blanco, Shikha Surana, Clément Bonnet, and Tom Barrett. Winner takes it all: Training performant rl populations for combinatorial optimization.Advances in Neural Information Processing Systems, 36:48485–48509, 2023
work page 2023
-
[42]
Sirui Li, Zhongxia Yan, and Cathy Wu. Learning to delegate for large-scale vehicle routing.Advances in Neural Information Processing Systems, 34:26198–26211, 2021
work page 2021
-
[43]
Generalize learned heuristics to solve large-scale vehicle routing problems in real-time
Qingchun Hou, Jingwei Yang, Yiqiang Su, Xiaoqing Wang, and Yuming Deng. Generalize learned heuristics to solve large-scale vehicle routing problems in real-time. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[44]
Jingwen Li, Yining Ma, Ruize Gao, Zhiguang Cao, Andrew Lim, Wen Song, and Jie Zhang. Deep rein- forcement learning for solving the heterogeneous capacitated vehicle routing problem.IEEE Transactions on Cybernetics, 52(12):13572–13585, 2022
work page 2022
-
[45]
Enhancing generalization in large-scale hcvrp: A rank-augmented neural solver
Qidong Liu, Jiurui Lian, Chaoyue Liu, and Zhiguang Cao. Enhancing generalization in large-scale hcvrp: A rank-augmented neural solver. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 1845–1856, 2025
work page 2025
-
[46]
Jingwen Li, Liang Xin, Zhiguang Cao, Andrew Lim, Wen Song, and Jie Zhang. Heterogeneous attentions for solving pickup and delivery problem via deep reinforcement learning.IEEE Transactions on Intelligent Transportation Systems, 23(3):2306–2315, 2021
work page 2021
-
[47]
Conghui Wang, Zhiguang Cao, Yaoxin Wu, Long Teng, and Guohua Wu. Deep reinforcement learning for solving vehicle routing problems with backhauls.IEEE Transactions on Neural Networks and Learning Systems, 36(3):4779–4793, 2024
work page 2024
-
[48]
Dpn: Decoupling partition and navigation for neural solvers of min-max vehicle routing problems
Zhi Zheng, Shunyu Yao, Zhenkun Wang, Xialiang Tong, Mingxuan Yuan, and Ke Tang. Dpn: Decoupling partition and navigation for neural solvers of min-max vehicle routing problems. InProceedings of the 41st International Conference on Machine Learning, pages 61559–61592, 2024
work page 2024
-
[49]
Neural combinatorial optimization for real-world routing.arXiv preprint arXiv:2503.16159, 2025
Jiwoo Son, Zhikai Zhao, Federico Berto, Chuanbo Hua, Changhyun Kwon, and Jinkyoo Park. Neural combinatorial optimization for real-world routing.arXiv preprint arXiv:2503.16159, 2025
-
[50]
Radar: Learning to route with asymmetry-aware distance representations
Hang Yi, Ziwei Huang, Zhiguang Cao, and Yining Ma. Radar: Learning to route with asymmetry-aware distance representations. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[51]
Multi-task vehicle routing solver via mixture of specialized experts under state-decomposable mdp
Yuxin Pan, Zhiguang Cao, Liu Liu, Peilin Zhao, Yize Chen, Fangzhen Lin, et al. Multi-task vehicle routing solver via mixture of specialized experts under state-decomposable mdp. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[52]
Suyu Liu, Zhiguang Cao, Nan Yin, and Yew-Soon Ong. Scale-net: A hierarchical u-net framework for cross-scale generalization in multi-task vehicle routing problems. InAAAI, 2026. 12
work page 2026
-
[53]
Jonathan Pirnay and Dominik G Grimm. Self-improvement for neural combinatorial optimization: Sample without replacement, but improvement.Transactions on Machine Learning Research, 2024
work page 2024
-
[54]
Yuanyao Chen, Rongsheng Chen, Fu Luo, and Zhenkun Wang. Improving generalization of neural combinatorial optimization for vehicle routing problems via test-time projection learning.arXiv preprint arXiv:2506.02392, 2025
-
[55]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational Conference on Machine Learning, pages 448–456. PMLR, 2015
work page 2015
-
[56]
Instance Normalization: The Missing Ingredient for Fast Stylization
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Instance normalization: The missing ingredient for fast stylization.arXiv preprint arXiv:1607.08022, 2016
work page Pith review arXiv 2016
-
[57]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine Learning, 8:229–256, 1992
work page 1992
-
[58]
Laurent Perron and Vincent Furnon. Or-tools, 2023. URL https://developers.google.com/ optimization/
work page 2023
-
[59]
Pyvrp: A high-performance vrp solver package.INFORMS Journal on Computing, 36(4):943–955, 2024
Niels A Wouda, Leon Lan, and Wouter Kool. Pyvrp: A high-performance vrp solver package.INFORMS Journal on Computing, 36(4):943–955, 2024. 13 A Related Work A.1 HELD-based Single-Task Neural Routing Solvers NCO has emerged as the dominant paradigm for solving various VRP variants. As foundational work, the Attention Model (AM) [17] adapted the Transformer ...
work page 2024
-
[60]
Given that 2 √ 2<3 , this configuration inherently guarantees the existence of feasible solutions. In the RouteFinder setting, the duration limit is sampled from a uniform distribution U(2 maxi d0i, lmax), where d0i denotes the distance from the depot to customer i, and lmax = 3 serves as the predefined upper bound. For multi-depot variants, the term maxi...
-
[61]
and employ PyVRP[59] as the classical baseline. To account for the increased complexity, the runtime limits for PyVRP are dynamically scaled to 300, 600, and 1200 seconds for problem sizes of N= 200,500, and1000, respectively. 20 G Training Settings All retrained baselines in this study strictly follow the hyperparameter configurations from their respecti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.