Recognition: no theorem link
Empty SPACE: Cross-Attention Sparsity for Concept Erasure in Diffusion Models
Pith reviewed 2026-05-12 03:15 UTC · model grok-4.3
The pith
Sparsifying cross-attention parameters lets closed-form updates erase target concepts from large diffusion models more effectively than dense methods while using 70% less storage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPACE iteratively modifies the cross-attention parameters of a diffusion model with a closed-form update that jointly induces sparsity and erases target concepts by concentrating the concept mapping to a lower-dimensional subspace, thereby achieving superior erasure efficacy and robustness against adversarial prompts compared to dense baselines while attaining 80%-90% cross-attention sparsity.
What carries the argument
The iterative closed-form update applied to cross-attention parameters that jointly erases a target concept and induces sparsity by restricting mappings to a lower-dimensional subspace.
If this is right
- Closed-form erasure scales to larger models such as Stable Diffusion XL without loss of effectiveness.
- Adversarial prompts become less successful at regenerating erased concepts.
- Edited models require 70% less storage for the modified cross-attention parameters.
- Erasure can be performed without retraining or gradient-based optimization.
Where Pith is reading between the lines
- The same sparsity-inducing update might be adapted to edit other controllable behaviors in attention-based generative models beyond concept removal.
- High cross-attention sparsity could reduce memory footprint in deployed image generators while preserving safety filters.
- If the subspace concentration generalizes, similar closed-form edits might apply to other attention layers or modalities.
Load-bearing premise
That imposing 80-90% sparsity on cross-attention layers will not degrade overall image quality, coherence, or the model's ability to generate non-target concepts without introducing new artifacts.
What would settle it
After applying SPACE, generate images from prompts that previously produced the erased concept and check whether the concept reappears at rates comparable to the dense baseline or whether visual quality metrics drop measurably.
Figures


















read the original abstract
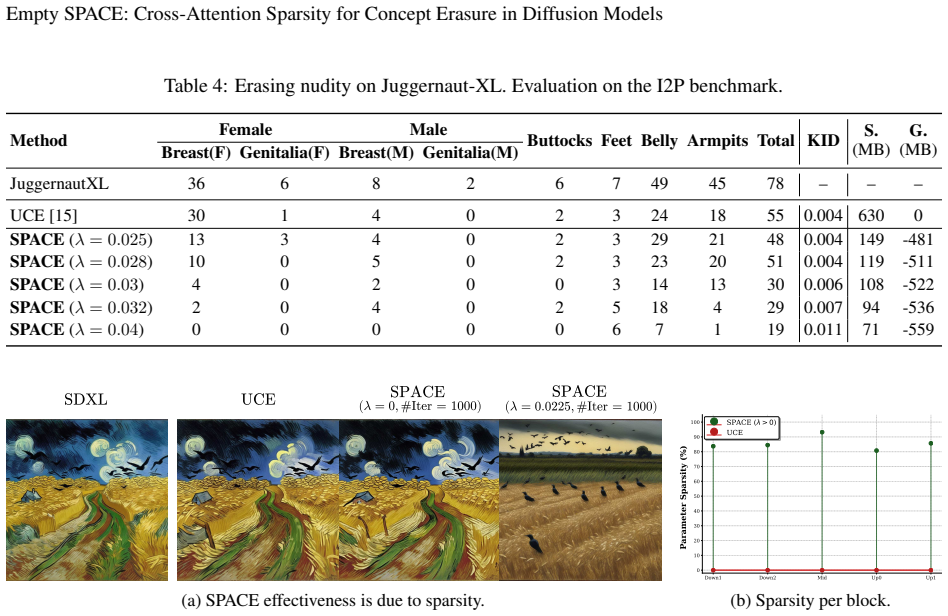
Erasing specific concepts from text-to-image diffusion models is essential for avoiding the generation of copyrighted and explicit content. Closed-form concept erasure methods offer a fast alternative to backpropagation-based techniques, but they become less effective when scaling from smaller models such as Stable Diffusion 1.5 to larger models like Stable Diffusion XL. To maintain erasure effectiveness in these larger-scale architectures, we propose SParse cross-Attention-based Concept Erasure (SPACE). SPACE iteratively modifies the cross-attention parameters of a model with a closed-form update that jointly induces sparsity and erases target concepts. By concentrating the concept mapping to a lower-dimensional subspace, SPACE achieves superior erasure efficacy compared to dense baselines. Extensive experimental results show improvements in erasure effectiveness and robustness against adversarial prompts. Furthermore, SPACE achieves 80\%-90\% cross-attention sparsity, reducing the storage requirements for saving the modified parameters by 70\%, demonstrating its memory efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SParse cross-Attention-based Concept Erasure (SPACE), which iteratively applies a closed-form update to the cross-attention parameters of text-to-image diffusion models. The update jointly induces sparsity and erases target concepts by concentrating mappings in a lower-dimensional subspace. The central claims are superior erasure efficacy and adversarial robustness relative to dense baselines (especially on SDXL-scale models), plus 80-90% cross-attention sparsity that reduces storage of modified parameters by 70%.
Significance. If the experimental results and stability analysis hold, SPACE would be a practically useful advance for concept erasure in large diffusion models: it retains the speed of closed-form methods while adding memory efficiency through sparsity and potentially stronger robustness. This combination addresses a clear scaling limitation of prior closed-form erasure techniques.
major comments (2)
- [Abstract] Abstract: the claims of 'superior erasure efficacy', 'improvements in erasure effectiveness and robustness', and '80%-90% cross-attention sparsity' are asserted without any quantitative metrics, baseline tables, ablation results, or trade-off discussion. Because the central contribution rests on these unspecified experiments, the superiority and memory-efficiency assertions cannot be evaluated from the provided text.
- [Method] Method (iterative closed-form update): the joint sparsity+erasure update is applied iteratively, yet no convergence analysis, Lipschitz bound, iteration-count ablation, or check that the linear/orthogonality assumptions remain valid after the first step is referenced. This directly bears on the skeptic's concern that drift could degrade non-target generation or introduce artifacts, undermining the stability premise required for the efficacy and sparsity claims on SDXL-scale models.
minor comments (1)
- [Abstract] The 70% storage-reduction figure should explicitly state the baseline (dense modified parameters vs. original model) and whether sparsity is measured only in cross-attention or across the full parameter set.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and have revised the manuscript to incorporate additional details and experiments where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'superior erasure efficacy', 'improvements in erasure effectiveness and robustness', and '80%-90% cross-attention sparsity' are asserted without any quantitative metrics, baseline tables, ablation results, or trade-off discussion. Because the central contribution rests on these unspecified experiments, the superiority and memory-efficiency assertions cannot be evaluated from the provided text.
Authors: We agree that the abstract would benefit from explicit quantitative support for the central claims. In the revised version, we will incorporate specific metrics drawn from our experimental results, including the observed improvements in erasure effectiveness and adversarial robustness on SDXL-scale models relative to dense baselines, the achieved cross-attention sparsity range of 80-90%, and the corresponding 70% reduction in modified-parameter storage. A brief reference to the trade-offs (e.g., negligible impact on non-target generation quality) will also be added to give readers an immediate sense of the empirical gains. revision: yes
-
Referee: [Method] Method (iterative closed-form update): the joint sparsity+erasure update is applied iteratively, yet no convergence analysis, Lipschitz bound, iteration-count ablation, or check that the linear/orthogonality assumptions remain valid after the first step is referenced. This directly bears on the skeptic's concern that drift could degrade non-target generation or introduce artifacts, undermining the stability premise required for the efficacy and sparsity claims on SDXL-scale models.
Authors: We appreciate this observation on the iterative procedure. The current manuscript provides extensive empirical validation that the method remains stable on large models, with no observable degradation in non-target outputs after the reported number of iterations. In the revision we will add (i) an ablation table showing erasure efficacy and generation quality as a function of iteration count and (ii) empirical verification that the linear mapping and orthogonality conditions continue to hold across iterations. A formal convergence analysis including Lipschitz bounds is not included, as deriving such guarantees for the joint sparsity-erasure objective would require substantial additional theoretical work outside the present scope; we instead rely on the observed rapid stabilization in practice. revision: partial
Circularity Check
No significant circularity; derivation remains independent of target outcomes
full rationale
The paper extends prior closed-form concept erasure techniques by introducing an iterative update that jointly enforces sparsity in cross-attention parameters while erasing target concepts. The claimed efficacy, robustness, and 80-90% sparsity levels are presented as outcomes of this update rule applied to diffusion models, supported by experimental results rather than by redefining or fitting the metrics themselves. No load-bearing equation reduces the final performance claims to a self-referential fit, renamed ansatz, or self-citation chain that presupposes the result. The iterative closed-form step is derived from the joint objective and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-attention parameters admit closed-form updates that can erase concepts while inducing sparsity
Reference graph
Works this paper leans on
-
[1]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 9 Empty SPACE: Cross-Attention Sparsity for Concept Erasure in Diffusion Models
work page 2022
-
[3]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
work page 2022
-
[5]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
work page 2022
-
[6]
Ai art and its impact on artists
Harry H Jiang, Lauren Brown, Jessica Cheng, Mehtab Khan, Abhishek Gupta, Deja Workman, Alex Hanna, Johnathan Flowers, and Timnit Gebru. Ai art and its impact on artists. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pages 363–374, 2023
work page 2023
-
[7]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22522–22531, 2023
work page 2023
-
[8]
Robin Rombach. Stable diffusion 2.0 release. https://stability.ai/news/ stable-diffusion-v2-release, 2022
work page 2022
-
[9]
Jaehong Yoon, Shoubin Yu, Vaidehi Patil, Huaxiu Yao, and Mohit Bansal. Safree: Training-free and adaptive guard for safe text-to-image and video generation.International Conference on Learning Representations, 2025
work page 2025
-
[10]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2426–2436, 2023
work page 2023
-
[11]
Ablating concepts in text-to-image diffusion models
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating concepts in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22691–22702, 2023
work page 2023
-
[12]
Anh Bui, Trang Vu, Long Vuong, Trung Le, Paul Montague, Tamas Abraham, Junae Kim, and Dinh Phung. Fantastic targets for concept erasure in diffusion models and where to find them.arXiv preprint arXiv:2501.18950, 2025
-
[13]
Fine-grained erasure in text-to-image diffusion-based foundation models
Kartik Thakral, Tamar Glaser, Tal Hassner, Mayank Vatsa, and Richa Singh. Fine-grained erasure in text-to-image diffusion-based foundation models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9121–9130, 2025
work page 2025
-
[14]
Nicola Novello, Federico Fontana, Luigi Cinque, Deniz Gunduz, and Andrea M Tonello. A unified framework for diffusion model unlearning with f-divergence.International Conference on Machine Learning, 2026
work page 2026
-
[15]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5111–5120, 2024
work page 2024
-
[16]
Reliable and efficient concept erasure of text-to-image diffusion models
Chao Gong, Kai Chen, Zhipeng Wei, Jingjing Chen, and Yu-Gang Jiang. Reliable and efficient concept erasure of text-to-image diffusion models. InEuropean Conference on Computer Vision, pages 73–88. Springer, 2024
work page 2024
-
[17]
Cure: Concept unlearning via orthogonal representation editing in diffusion models
Shristi Das Biswas, Arani Roy, and Kaushik Roy. Cure: Concept unlearning via orthogonal representation editing in diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[18]
Ouxiang Li, Yuan Wang, Xinting Hu, Houcheng Jiang, Tao Liang, Yanbin Hao, Guojun Ma, and Fuli Feng. Speed: Scalable, precise, and efficient concept erasure for diffusion models.International Conference on Learning Representations, ICLR, 2026
work page 2026
-
[19]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021
work page 2021
-
[21]
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes.International Conference on Learning Representations, ICLR, 2018. 10 Empty SPACE: Cross-Attention Sparsity for Concept Erasure in Diffusion Models
work page 2018
-
[22]
Torsten Hoefler, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, and Alexandra Peste. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks.Journal of Machine Learning Research, 22(241):1–124, 2021
work page 2021
-
[23]
A fast iterative shrinkage-thresholding algorithm for linear inverse problems
Amir Beck and Marc Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences, 2(1):183–202, 2009
work page 2009
-
[24]
Jinghan Jia, Jiancheng Liu, Parikshit Ram, Yuguang Yao, Gaowen Liu, Yang Liu, Pranay Sharma, and Sijia Liu. Model sparsity can simplify machine unlearning.Advances in Neural Information Processing Systems, 36:51584–51605, 2023
work page 2023
-
[25]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation.International Conference on Learning Representations, 2024
work page 2024
-
[26]
Scissorhands: Scrub data influence via connection sensitivity in networks
Jing Wu and Mehrtash Harandi. Scissorhands: Scrub data influence via connection sensitivity in networks. In European Conference on Computer Vision, pages 367–384. Springer, 2024
work page 2024
-
[27]
Yu-Lin Tsai, Chia-Yi Hsu, Chulin Xie, Chih-Hsun Lin, Jia-You Chen, Bo Li, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Ring-a-bell! how reliable are concept removal methods for diffusion models?arXiv preprint arXiv:2310.10012, 2023
-
[28]
Mma-diffusion: Multimodal attack on diffusion models
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu. Mma-diffusion: Multimodal attack on diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7737–7746, 2024
work page 2024
-
[29]
Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, and Wei-Chen Chiu. Prompting4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts.arXiv preprint arXiv:2309.06135, 2023
-
[30]
Unlearning concepts in diffusion model via concept domain correction and concept preserving gradient
Yongliang Wu, Shiji Zhou, Mingzhuo Yang, Lianzhe Wang, Heng Chang, Wenbo Zhu, Xinting Hu, Xiao Zhou, and Xu Yang. Unlearning concepts in diffusion model via concept domain correction and concept preserving gradient. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8496–8504, 2025
work page 2025
-
[31]
Anh Bui, Long Vuong, Khanh Doan, Trung Le, Paul Montague, Tamas Abraham, and Dinh Phung. Erasing undesirable concepts in diffusion models with adversarial preservation.arXiv preprint arXiv:2410.15618, 2024
-
[32]
Beyond l2: Divergence-driven concept unlearning in diffusion models.Available at SSRN 5705580
Umakanta Maharana, Aakash Sen Sharma, Yash Sinha, Praveen Kumar Chandaliya, Mohan S Kankanhalli, Ankur Mali, and Murari Mandal. Beyond l2: Divergence-driven concept unlearning in diffusion models.Available at SSRN 5705580
-
[33]
Editing implicit assumptions in text-to-image diffusion models
Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. Editing implicit assumptions in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7053–7061, 2023
work page 2023
-
[34]
Mass-Editing Memory in a Transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer.arXiv preprint arXiv:2210.07229, 2022
work page internal anchor Pith review arXiv 2022
-
[35]
Chaitanya Malaviya, Pedro Ferreira, and André FT Martins. Sparse and constrained attention for neural machine translation.arXiv preprint arXiv:1805.08241, 2018
-
[36]
Sparse Sequence-to-Sequence Models
Ben Peters, Vlad Niculae, and André FT Martins. Sparse sequence-to-sequence models.arXiv preprint arXiv:1905.05702, 2019
work page Pith review arXiv 1905
-
[37]
Fabio Giampaolo, Stefano Izzo, Edoardo Prezioso, and Francesco Piccialli
Gonçalo M Correia, Vlad Niculae, and André FT Martins. Adaptively sparse transformers.arXiv preprint arXiv:1909.00015, 2019
-
[38]
Sparse attention with linear units.arXiv preprint arXiv:2104.07012, 2021
Biao Zhang, Ivan Titov, and Rico Sennrich. Sparse attention with linear units.arXiv preprint arXiv:2104.07012, 2021
-
[39]
From softmax to sparsemax: A sparse model of attention and multi-label classification
Andre Martins and Ramon Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label classification. InInternational conference on machine learning, pages 1614–1623. PMLR, 2016
work page 2016
-
[40]
Vlad Niculae and Mathieu Blondel. A regularized framework for sparse and structured neural attention.Advances in neural information processing systems, 30, 2017
work page 2017
-
[41]
Kwanyoung Kim and Byeongsu Sim. Pladis: Pushing the limits of attention in diffusion models at inference time by leveraging sparsity.International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[42]
Gonzalez, Jun Zhu, and Jianfei Chen
Jintao Zhang, Haoxu Wang, Kai Jiang, Shuo Yang, Kaiwen Zheng, Haocheng Xi, Ziteng Wang, Hongzhou Zhu, Min Zhao, Ion Stoica, et al. Sla: Beyond sparsity in diffusion transformers via fine-tunable sparse-linear attention. arXiv preprint arXiv:2509.24006, 2025. 11 Empty SPACE: Cross-Attention Sparsity for Concept Erasure in Diffusion Models
-
[43]
Peiyuan Zhang, Yongqi Chen, Haofeng Huang, Will Lin, Zhengzhong Liu, Ion Stoica, Eric Xing, and Hao Zhang. Vsa: Faster video diffusion with trainable sparse attention.Advances in Neural Information Processing Systems, 2025
work page 2025
-
[44]
SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
Bartosz Cywi´nski and Kamil Deja. Saeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders.arXiv preprint arXiv:2501.18052, 2025
-
[45]
Enrico Cassano, Riccardo Renzulli, Marco Nurisso, Mirko Zaffaroni, Alan Perotti, and Marco Grangetto. Saem- nesia: Erasing concepts in diffusion models with sparse autoencoders.arXiv preprint arXiv:2509.21379, 2025
-
[46]
Qinqin He, Jiaqi Weng, Jialing Tao, and Hui Xue. A single neuron works: Precise concept erasure in text-to-image diffusion models.arXiv preprint arXiv:2509.21008, 2025
-
[47]
Sauce: Selective concept unlearning in vision-language models with sparse autoencoders
Jiahui Geng and Qing Li. Sauce: Selective concept unlearning in vision-language models with sparse autoencoders. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3023–3033, 2025
work page 2025
-
[48]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[49]
Mace: Mass concept erasure in diffusion models
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. Mace: Mass concept erasure in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6430–6440, 2024
work page 2024
-
[50]
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7559–7568, 2024
work page 2024
-
[51]
Editing massive concepts in text-to-image diffusion models.arXiv preprint arXiv:2403.13807, 2024
Tianwei Xiong, Yue Wu, Enze Xie, Zhenguo Li, and Xihui Liu. Editing massive concepts in text-to-image diffusion models.arXiv preprint arXiv:2403.13807, 2024
-
[52]
Byung Hyun Lee, Sungjin Lim, and Se Young Chun. Localized concept erasure for text-to-image diffusion models using training-free gated low-rank adaptation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18596–18606, 2025
work page 2025
-
[53]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635, 2018
work page Pith review arXiv 2018
-
[54]
Sparsity-aware unlearning for large language models.arXiv preprint arXiv:2602.00577, 2026
Yuze Wang, Yujia Tong, Ke Xu, Jingling Yuan, Jiawei Jiang, and Chuang Hu. Sparsity-aware unlearning for large language models.arXiv preprint arXiv:2602.00577, 2026
-
[55]
Conceptprune: Concept editing in diffusion models via skilled neuron pruning.ICLR, 2025
Ruchika Chavhan, Da Li, and Timothy Hospedales. Conceptprune: Concept editing in diffusion models via skilled neuron pruning.ICLR, 2025
work page 2025
-
[56]
Efficient fine-tuning and concept suppression for pruned diffusion models
Reza Shirkavand, Peiran Yu, Shangqian Gao, Gowthami Somepalli, Tom Goldstein, and Heng Huang. Efficient fine-tuning and concept suppression for pruned diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18619–18629, 2025
work page 2025
-
[57]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
work page 2015
-
[58]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[59]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[60]
Francis Bach, Rodolphe Jenatton, Julien Mairal, Guillaume Obozinski, et al. Convex optimization with sparsity- inducing norms.Optimization for machine learning, 5(19-53):8, 2011
work page 2011
-
[61]
Ingrid Daubechies, Michel Defrise, and Christine De Mol. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint.Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 57(11):1413–1457, 2004
work page 2004
-
[62]
Yujie Zhao and Xiaoming Huo. A survey of numerical algorithms that can solve the lasso problems.Wiley Interdisciplinary Reviews: Computational Statistics, 15(4):e1602, 2023
work page 2023
-
[63]
Jerome H Friedman, Trevor Hastie, and Rob Tibshirani. Regularization paths for generalized linear models via coordinate descent.Journal of statistical software, 33:1–22, 2010
work page 2010
-
[64]
Fast optimization methods for l1 regularization: A comparative study and two new approaches
Mark Schmidt, Glenn Fung, and Rómer Rosales. Fast optimization methods for l1 regularization: A comparative study and two new approaches. InEuropean Conference on Machine Learning, pages 286–297. Springer, 2007
work page 2007
-
[65]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning.arXiv preprint arXiv:2104.08718, 2021. 12 Empty SPACE: Cross-Attention Sparsity for Concept Erasure in Diffusion Models
work page internal anchor Pith review arXiv 2021
-
[66]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[67]
Sutherland, Michael Arbel, and Arthur Gretton
Mikołaj Bi´nkowski, Dougal J. Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GANs. In International Conference on Learning Representations, 2018
work page 2018
-
[68]
Nudenet: Neural nets for nudity classification, detection and selective censoring, 2019
notAI tech. Nudenet: Neural nets for nudity classification, detection and selective censoring, 2019
work page 2019
-
[69]
Juggernaut-xl v9,https://huggingface.co/RunDiffusion/Juggernaut-XL-v9, 2024
RunDiffusion. Juggernaut-xl v9,https://huggingface.co/RunDiffusion/Juggernaut-XL-v9, 2024
work page 2024
-
[70]
U-repa: Aligning diffu- sion u-nets to vits.arXiv preprint arXiv:2503.18414, 2025
Yuchuan Tian, Hanting Chen, Mengyu Zheng, Yuchen Liang, Chao Xu, and Yunhe Wang. U-repa: Aligning diffusion u-nets to vits.arXiv preprint arXiv:2503.18414, 2025. 13 Empty SPACE: Cross-Attention Sparsity for Concept Erasure in Diffusion Models A Appendix: Pseudocode for SPACE In this section, we report the pseudocode for SPACE in Algorithm 1. Algorithm 1:S...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.