Recognition: 2 theorem links
· Lean TheoremPaMoSplat: Part-Aware Motion-Guided Gaussian Splatting for Dynamic Scene Reconstruction
Pith reviewed 2026-05-12 05:15 UTC · model grok-4.3
The pith
PaMoSplat models dynamic scenes as rigid parts initialized from 3D-lifted masks and guided by optical flow to improve Gaussian splatting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PaMoSplat initializes Gaussian primitives as coherent 3D parts by lifting multi-view segmentation masks through graph clustering, estimates the rigid motion of each part at later times using a differential evolutionary algorithm driven by multi-view optical flow cues to provide a warm start, and optimizes the entire model with an adaptive iteration schedule, an internal learnable rigidity parameter, and a flow-supervised rendering loss, thereby achieving higher-fidelity rendering and tracking than prior dynamic Gaussian splatting approaches.
What carries the argument
Graph clustering that lifts 2D segmentation masks to coherent 3D Gaussian parts, together with differential evolutionary rigid-motion estimation guided by multi-view optical flow.
If this is right
- Higher rendering quality than existing dynamic Gaussian methods across synthetic and real scenes
- More precise part-level tracking enabled by the motion-guided initialization
- Faster training convergence through the adaptive iteration count and auxiliary losses
- Direct support for part-level 4D editing applications
Where Pith is reading between the lines
- The rigid-part assumption could be relaxed to allow small non-rigid deformations inside each part without changing the overall pipeline.
- Replacing the graph-clustering step with a learned 3D segmentation network might reduce dependence on accurate 2D masks.
- The same motion-warm-start strategy could be tested on other deformable representations such as neural radiance fields.
Load-bearing premise
Lifting multi-view segmentation masks into 3D via graph clustering yields coherent Gaussian parts whose motions can be captured by rigid-body estimation informed by optical flow.
What would settle it
A dynamic scene in which cross-view mask consistency is low and part motions deviate strongly from rigid transformations, after which the reported gains in PSNR, tracking accuracy, and convergence speed disappear.
Figures













read the original abstract
Dynamic scene reconstruction represents a fundamental yet demanding challenge in computer vision and robotics. While recent progress in 3DGS-based methods has advanced dynamic scene modeling, obtaining high-fidelity rendering and accurate tracking in scenarios with substantial, intricate motions remains significantly challenging. To address these challenges, we propose PaMoSplat, a novel dynamic Gaussian splatting framework incorporating part awareness and motion priors. Our approach is grounded in two key observations: 1) Parts serve as primitives for scene deformation, and 2) Motion cues from optical flow can effectively guide part motion. Specifically, PaMoSplat initializes by lifting multi-view segmentation masks into 3D space via graph clustering, establishing coherent Gaussian parts. For subsequent timestamps, we leverage a differential evolutionary algorithm to estimate the rigid motion of these parts using multi-view optical flow cues, providing a robust warm-start for further optimization. Additionally, PaMoSplat introduces an adaptive iteration count mechanism, internal learnable rigidity, and flow-supervised rendering loss to accelerate and optimize the training process. Comprehensive evaluations across diverse scenes, including real-world environments, demonstrate that PaMoSplat delivers superior rendering quality, improved tracking precision, and faster convergence compared to existing methods. Furthermore, it enables multiple part-level downstream applications, such as 4D scene editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PaMoSplat, a part-aware dynamic Gaussian splatting framework for reconstructing scenes with substantial and intricate motions. It initializes by lifting multi-view segmentation masks into 3D Gaussian parts via graph clustering, then applies differential evolution on multi-view optical flow to estimate rigid per-part motions as a warm-start. The method further incorporates an adaptive iteration count, internal learnable rigidity, and a flow-supervised rendering loss to accelerate optimization. Evaluations on diverse scenes, including real-world data, are reported to show gains in rendering quality, tracking precision, and convergence speed over existing methods, while enabling downstream tasks such as 4D scene editing.
Significance. If the graph-clustered parts reliably correspond to approximately rigid entities, the combination of motion-prior initialization and flow supervision could meaningfully advance 3DGS-based dynamic reconstruction in challenging regimes. The use of differential evolution for warm-starting rigid motions and the flow-supervised loss constitute concrete, testable contributions that build on standard optimization techniques. The paper's emphasis on part-level applications also opens clear avenues for downstream use.
major comments (3)
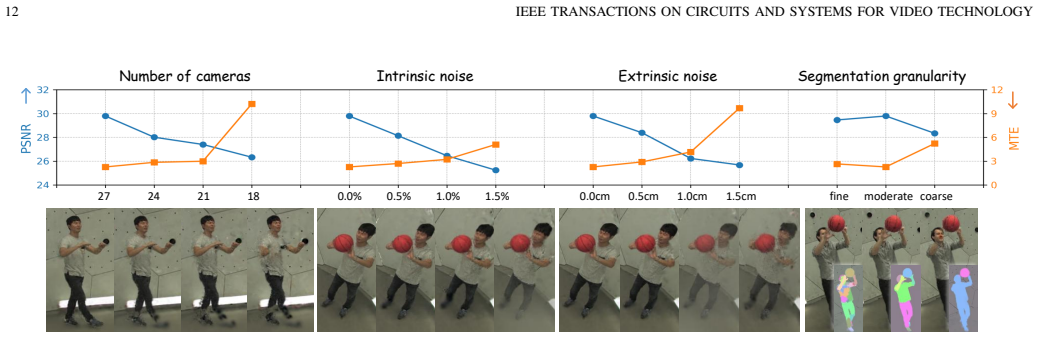
- [Abstract and Method (initialization procedure)] The initialization step that lifts multi-view segmentation masks into 3D via graph clustering is presented as producing coherent Gaussian parts suitable for rigid-motion modeling. However, no quantitative validation—such as part-label stability across frames, agreement with synthetic ground-truth decompositions, or failure-case analysis on noisy 2D segmentations—is reported. This assumption is load-bearing for the subsequent differential-evolution motion estimation and the claimed improvements in tracking precision.
- [Abstract and Experiments section] The abstract states that comprehensive evaluations demonstrate superior rendering quality, improved tracking precision, and faster convergence. Yet the provided description supplies no specific metrics (e.g., PSNR, SSIM, tracking error), baseline comparisons, or ablation results isolating the contribution of the graph-clustering step versus the flow-supervised loss. Without these, the central performance claims cannot be assessed for robustness.
- [Method (optimization components)] The learnable rigidity and adaptive iteration count are introduced to optimize training, but their effect on convergence is not isolated from the warm-start provided by differential evolution. If these mechanisms are central to the faster-convergence claim, an ablation removing them while keeping the motion prior should be shown.
minor comments (3)
- The abstract would be strengthened by including one or two key quantitative results (e.g., average PSNR gain or iteration reduction) rather than purely qualitative statements of superiority.
- [Related Work] Ensure that all cited prior dynamic Gaussian splatting works are compared in a dedicated related-work section with explicit differences highlighted.
- Figure captions should clearly label visualized elements such as part decompositions, estimated motion fields, and rendered outputs versus ground truth.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, outlining the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and Method (initialization procedure)] The initialization step that lifts multi-view segmentation masks into 3D via graph clustering is presented as producing coherent Gaussian parts suitable for rigid-motion modeling. However, no quantitative validation—such as part-label stability across frames, agreement with synthetic ground-truth decompositions, or failure-case analysis on noisy 2D segmentations—is reported. This assumption is load-bearing for the subsequent differential-evolution motion estimation and the claimed improvements in tracking precision.
Authors: We agree that quantitative validation of part coherence would strengthen the load-bearing assumption. In the revised manuscript we will add experiments on synthetic scenes with available ground-truth decompositions, reporting part-label stability (e.g., frame-to-frame IoU) and robustness under controlled noise in the 2D masks. We will also include a qualitative and quantitative discussion of failure cases where graph clustering yields non-rigid parts. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that comprehensive evaluations demonstrate superior rendering quality, improved tracking precision, and faster convergence. Yet the provided description supplies no specific metrics (e.g., PSNR, SSIM, tracking error), baseline comparisons, or ablation results isolating the contribution of the graph-clustering step versus the flow-supervised loss. Without these, the central performance claims cannot be assessed for robustness.
Authors: The Experiments section reports quantitative results with PSNR, SSIM, LPIPS, and tracking-error metrics together with baseline comparisons; however, to make the claims more readily assessable we will revise the abstract to cite the key numerical improvements and add an explicit ablation table isolating the graph-clustering initialization from the flow-supervised loss. revision: partial
-
Referee: [Method (optimization components)] The learnable rigidity and adaptive iteration count are introduced to optimize training, but their effect on convergence is not isolated from the warm-start provided by differential evolution. If these mechanisms are central to the faster-convergence claim, an ablation removing them while keeping the motion prior should be shown.
Authors: We concur that isolating the contribution of learnable rigidity and adaptive iteration count from the differential-evolution warm-start is required. The revised manuscript will include an ablation that disables these two components while retaining the motion prior and reports the resulting convergence curves and final rendering/tracking metrics. revision: yes
Circularity Check
No circularity: framework assembles external priors and standard optimization into a pipeline without reducing outputs to inputs by construction.
full rationale
The paper's core steps—lifting 2D segmentation masks to 3D parts via graph clustering, using differential evolution on optical flow for rigid-motion warm-start, and adding learnable rigidity plus flow-supervised loss—are presented as engineering choices that consume independent inputs (masks, flow fields) and produce optimized Gaussians. No equation or claim equates a derived quantity (e.g., part motion or rendering quality) back to a fitted parameter or self-citation by definition. The claimed improvements are asserted via external evaluations on diverse scenes rather than by algebraic identity with the initialization. This is the normal non-circular case for a method paper whose load-bearing assumptions are stated as testable (coherent rigid parts) rather than smuggled in as tautologies.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable rigidity
- adaptive iteration count
axioms (2)
- domain assumption Parts serve as primitives for scene deformation
- domain assumption Motion cues from optical flow can effectively guide part motion
Reference graph
Works this paper leans on
-
[1]
C. Wen, et al., “Any-point trajectory modeling for policy learning,”arXiv preprint arXiv:2401.00025, 2023
-
[2]
W. Huang, et al., “Rekep: Spatio-temporal reasoning of rela- tional keypoint constraints for robotic manipulation,”arXiv preprint arXiv:2409.01652, 2024
-
[3]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, et al., “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
work page 2021
-
[4]
K-planes: Explicit radiance fields in space, time, and appearance,
S. Fridovich-Keil, et al., “K-planes: Explicit radiance fields in space, time, and appearance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12 479–12 488, 2023
work page 2023
-
[5]
Hexplane: A fast representation for dynamic scenes,
A. Cao and J. Johnson, “Hexplane: A fast representation for dynamic scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 130–141, 2023
work page 2023
-
[6]
Dynibar: Neural dynamic image-based rendering,
Z. Li, et al., “Dynibar: Neural dynamic image-based rendering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4273–4284, 2023
work page 2023
-
[7]
Neural 3d video synthesis from multi-view video,
T. Li, et al., “Neural 3d video synthesis from multi-view video,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5521–5531, 2022
work page 2022
-
[8]
Tensor4d: Efficient neural 4d decomposition for high- fidelity dynamic reconstruction and rendering,
R. Shao, et al., “Tensor4d: Efficient neural 4d decomposition for high- fidelity dynamic reconstruction and rendering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16 632–16 642, 2023
work page 2023
-
[9]
D-nerf: Neural radiance fields for dynamic scenes,
A. Pumarola, et al., “D-nerf: Neural radiance fields for dynamic scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10 318–10 327, 2021
work page 2021
-
[10]
Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields,
K. Park, et al., “Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields,”ACM Transactions on Graphics (ToG), vol. 40, no. 6, Dec. 2021
work page 2021
-
[11]
Nerfplayer: A streamable dynamic scene representation with decomposed neural radiance fields,
L. Song, et al., “Nerfplayer: A streamable dynamic scene representation with decomposed neural radiance fields,”IEEE Transactions on Visual- ization and Computer Graphics, vol. 29, no. 5, pp. 2732–2742, 2023
work page 2023
-
[12]
Hyperreel: High-fidelity 6-dof video with ray- conditioned sampling,
B. Attal, et al., “Hyperreel: High-fidelity 6-dof video with ray- conditioned sampling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16 610–16 620, 2023
work page 2023
-
[13]
Dynamic mesh-aware radiance fields,
Y .-L. Qiao, et al., “Dynamic mesh-aware radiance fields,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 385–396, 2023
work page 2023
-
[14]
High-fidelity and real-time novel view synthesis for dynamic scenes,
H. Lin, et al., “High-fidelity and real-time novel view synthesis for dynamic scenes,” inSIGGRAPH Asia 2023 Conference Papers, pp. 1– 9, 2023
work page 2023
-
[15]
Mixed neural voxels for fast multi-view video syn- thesis,
F. Wang, et al., “Mixed neural voxels for fast multi-view video syn- thesis,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 19 706–19 716, 2023
work page 2023
-
[16]
3d gaussian splatting for real-time radiance field rendering,
B. Kerbl, et al., “3d gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, vol. 42, no. 4, pp. 1–14, 2023
work page 2023
-
[17]
4k4d: Real-time 4d view synthesis at 4k resolution,
Z. Xu, et al., “4k4d: Real-time 4d view synthesis at 4k resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20 029–20 040, 2024
work page 2024
-
[18]
Z. Yang, et al., “Real-time photorealistic dynamic scene represen- tation and rendering with 4d gaussian splatting,”arXiv preprint arXiv:2310.10642, 2023
-
[19]
Spacetime gaussian feature splatting for real-time dy- namic view synthesis,
Z. Li, et al., “Spacetime gaussian feature splatting for real-time dy- namic view synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8508–8520, 2024
work page 2024
-
[20]
4d-rotor gaussian splatting: towards efficient novel view synthesis for dynamic scenes,
Y . Duan, et al., “4d-rotor gaussian splatting: towards efficient novel view synthesis for dynamic scenes,” inACM SIGGRAPH 2024 Conference Papers, pp. 1–11, 2024
work page 2024
-
[21]
J. Yan, et al., “4d gaussian splatting with scale-aware residual field and adaptive optimization for real-time rendering of temporally complex dynamic scenes,” inACM Multimedia 2024, 2024
work page 2024
-
[22]
Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes,
Y .-H. Huang, et al., “Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4220–4230, 2024
work page 2024
-
[23]
Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle,
Y . Lin, et al., “Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21 136–21 145, 2024
work page 2024
-
[24]
4d gaussian splatting for real-time dynamic scene rendering,
G. Wu, et al., “4d gaussian splatting for real-time dynamic scene rendering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20 310–20 320, 2024
work page 2024
-
[25]
Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction,
Z. Yang, et al., “Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pp. 20 331–20 341, 2024
work page 2024
-
[26]
3d geometry-aware deformable gaussian splatting for dynamic view synthesis,
Z. Lu, et al., “3d geometry-aware deformable gaussian splatting for dynamic view synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8900–8910, 2024
work page 2024
-
[27]
Superpoint gaussian splatting for real-time high-fidelity dynamic scene reconstruction,
D. Wan, R. Lu, and G. Zeng, “Superpoint gaussian splatting for real-time high-fidelity dynamic scene reconstruction,”arXiv preprint arXiv:2406.03697, 2024
-
[28]
Gaussianprediction: Dynamic 3d gaussian prediction for motion extrapolation and free view synthesis,
B. Zhao, et al., “Gaussianprediction: Dynamic 3d gaussian prediction for motion extrapolation and free view synthesis,” inACM SIGGRAPH 2024 Conference Papers, pp. 1–12, 2024
work page 2024
-
[29]
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis,
J. Luiten, et al., “Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis,” in3DV, 2024
work page 2024
-
[30]
Physically embodied gaussian splatting: A realtime correctable world model for robotics,
J. Abou-Chakra, et al., “Physically embodied gaussian splatting: A realtime correctable world model for robotics,”arXiv preprint arXiv:2406.10788, 2024
-
[31]
Panoptic studio: A massively multiview system for social motion capture,
H. Joo, et al., “Panoptic studio: A massively multiview system for social motion capture,” inProceedings of the IEEE international conference on computer vision, pp. 3334–3342, 2015
work page 2015
-
[32]
Motion-aware 3d gaussian splatting for efficient dynamic scene reconstruction,
Z. Guo, et al., “Motion-aware 3d gaussian splatting for efficient dynamic scene reconstruction,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2024
work page 2024
-
[33]
arXiv preprint arXiv:2403.12365 (2024)
Q. Gao, et al., “Gaussianflow: Splatting gaussian dynamics for 4d content creation,”arXiv preprint arXiv:2403.12365, 2024
-
[34]
A. Kirillov, et al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4015–4026, 2023
work page 2023
-
[35]
Raft: Recurrent all-pairs field transforms for op- tical flow,
Z. Teed and J. Deng, “Raft: Recurrent all-pairs field transforms for op- tical flow,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pp. 402–
work page 2020
-
[36]
Aleth-nerf: Illumination adaptive nerf with concealing field assumption,
Z. Cui, et al., “Aleth-nerf: Illumination adaptive nerf with concealing field assumption,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 2, pp. 1435–1444, 2024
work page 2024
-
[37]
M. Zhenxing and D. Xu, “Switch-nerf: Learning scene decomposition with mixture of experts for large-scale neural radiance fields,” inThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[38]
F2-nerf: Fast neural radiance field training with free camera trajectories,
P. Wang, et al., “F2-nerf: Fast neural radiance field training with free camera trajectories,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4150–4159, 2023
work page 2023
-
[39]
Depth-guided robust point cloud fusion nerf for sparse input views,
S. Guo, et al., “Depth-guided robust point cloud fusion nerf for sparse input views,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[40]
Semantic is enough: Only semantic information for nerf reconstruction,
R. Wang, et al., “Semantic is enough: Only semantic information for nerf reconstruction,” in2023 IEEE International Conference on Unmanned Systems (ICUS), pp. 906–912. IEEE, 2023
work page 2023
-
[41]
Openobj: Open-vocabulary object-level neural radiance fields with fine-grained understanding,
Y . Deng, et al., “Openobj: Open-vocabulary object-level neural radiance fields with fine-grained understanding,”arXiv preprint arXiv:2406.08009, 2024
-
[42]
Macim: Multi-agent collaborative implicit mapping,
Y . Deng, et al., “Macim: Multi-agent collaborative implicit mapping,” IEEE Robotics and Automation Letters, 2024
work page 2024
-
[43]
Lgsdf: Continual global learning of signed distance fields aided by local updating,
Y . Yue, et al., “Lgsdf: Continual global learning of signed distance fields aided by local updating,”arXiv preprint arXiv:2404.05187, 2024
-
[44]
Lightspeed: light and fast neural light fields on mobile devices,
A. Gupta, et al., “Lightspeed: light and fast neural light fields on mobile devices,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[45]
Hashpoint: Accelerated point searching and sampling for neural rendering,
J. Ma, et al., “Hashpoint: Accelerated point searching and sampling for neural rendering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4462–4472, 2024
work page 2024
-
[46]
Generative neural fields by mixtures of neural implicit functions,
T. You, et al., “Generative neural fields by mixtures of neural implicit functions,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[47]
Instant neural graphics primitives with a multireso- lution hash encoding,
T. M ¨uller, et al., “Instant neural graphics primitives with a multireso- lution hash encoding,”ACM transactions on graphics (TOG), vol. 41, no. 4, pp. 1–15, 2022
work page 2022
-
[48]
Dynamic view synthesis from dynamic monocular video,
C. Gao, et al., “Dynamic view synthesis from dynamic monocular video,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5712–5721, 2021
work page 2021
-
[49]
Space-time neural irradiance fields for free-viewpoint video,
W. Xian, et al., “Space-time neural irradiance fields for free-viewpoint video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9421–9431, 2021
work page 2021
-
[50]
Non-local guided neural fields for 4d ct reconstruction,
Q. Zhou, et al., “Non-local guided neural fields for 4d ct reconstruction,” IEEE Transactions on Circuits and Systems for Video Technology, 2025. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY 15
work page 2025
-
[51]
Neural deformable voxel grid for fast optimization of dynamic view synthesis,
X. Guo, et al., “Neural deformable voxel grid for fast optimization of dynamic view synthesis,” inProceedings of the Asian Conference on Computer Vision, pp. 3757–3775, 2022
work page 2022
-
[52]
Robust dynamic radiance fields,
Y .-L. Liu, et al., “Robust dynamic radiance fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13–23, 2023
work page 2023
-
[53]
Nerfies: Deformable neural radiance fields,
K. Park, et al., “Nerfies: Deformable neural radiance fields,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, pp. 5865–5874, 2021
work page 2021
-
[54]
Dynamicsurf: Dynamic neural rgb- d surface reconstruction with an optimizable feature grid,
M. Mohamed and L. Agapito, “Dynamicsurf: Dynamic neural rgb- d surface reconstruction with an optimizable feature grid,” in2024 International Conference on 3D Vision (3DV), pp. 820–830. IEEE, 2024
work page 2024
-
[55]
Dynamic appearance particle neural radiance field,
A. Lin, et al., “Dynamic appearance particle neural radiance field,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[56]
Factorized fields for fast sparse input dynamic view synthesis,
N. Somraj, et al., “Factorized fields for fast sparse input dynamic view synthesis,” inACM SIGGRAPH 2024 Conference Papers, pp. 1–12, 2024
work page 2024
-
[57]
Forward flow for novel view synthesis of dynamic scenes,
X. Guo, et al., “Forward flow for novel view synthesis of dynamic scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16 022–16 033, 2023
work page 2023
-
[58]
Evdnerf: Reconstructing event data with dy- namic neural radiance fields,
A. Bhattacharya, et al., “Evdnerf: Reconstructing event data with dy- namic neural radiance fields,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 5846–5855, 2024
work page 2024
-
[59]
Dynpoint: Dynamic neural point for view synthesis,
K. Zhou, et al., “Dynpoint: Dynamic neural point for view synthesis,” Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[60]
Per-gaussian embedding-based deformation for de- formable 3d gaussian splatting,
J. Bae, et al., “Per-gaussian embedding-based deformation for de- formable 3d gaussian splatting,” inEuropean Conference on Computer Vision, pp. 321–335. Springer, 2024
work page 2024
-
[61]
D. Li, et al., “St-4dgs: Spatial-temporally consistent 4d gaussian splat- ting for efficient dynamic scene rendering,” inACM SIGGRAPH 2024 Conference Papers, pp. 1–11, 2024
work page 2024
-
[62]
J. Wu, et al., “Swift4d: Adaptive divide-and-conquer gaussian splatting for compact and efficient reconstruction of dynamic scene,”arXiv preprint arXiv:2503.12307, 2025
-
[63]
J. Sun, et al., “3dgstream: On-the-fly training of 3d gaussians for efficient streaming of photo-realistic free-viewpoint videos,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20 675–20 685, 2024
work page 2024
-
[64]
Hicom: Hierarchical coherent motion for dynamic streamable scenes with 3d gaussian splatting,
Q. Gao, et al., “Hicom: Hierarchical coherent motion for dynamic streamable scenes with 3d gaussian splatting,”Advances in Neural Information Processing Systems, vol. 37, pp. 80 609–80 633, 2024
work page 2024
-
[65]
Fast unfolding of communities in large networks,
V . D. Blondel, et al., “Fast unfolding of communities in large networks,” Journal of statistical mechanics: theory and experiment, vol. 2008, no. 10, p. P10008, 2008
work page 2008
-
[66]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[67]
Particlenerf: A particle-based encoding for online neural radiance fields,
J. Abou-Chakra, F. Dayoub, and N. S ¨underhauf, “Particlenerf: A particle-based encoding for online neural radiance fields,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 5975–5984, 2024
work page 2024
-
[68]
Realtime multi-person 2d pose estimation using part affinity fields,
Z. Cao, et al., “Realtime multi-person 2d pose estimation using part affinity fields,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 7291–7299, 2017
work page 2017
-
[69]
SAM 2: Segment Anything in Images and Videos
N. Ravi, et al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Sea-raft: Simple, efficient, accurate raft for optical flow,
Y . Wang, L. Lipson, and J. Deng, “Sea-raft: Simple, efficient, accurate raft for optical flow,” inEuropean Conference on Computer Vision, pp. 36–54. Springer, 2024. Yinan Deng(Student Member, IEEE) received the B.Eng. degree in automation from Beijing Institute of Technology, Beijing, China, in 2021. He is cur- rently pursuing his Ph.D. degree in Control...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.