Recognition: 2 theorem links
· Lean TheoremTMAS: Scaling Test-Time Compute via Multi-Agent Synergy
Pith reviewed 2026-05-12 04:30 UTC · model grok-4.3
The pith
TMAS scales test-time compute for LLMs by organizing multi-agent collaboration with hierarchical memories and hybrid rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TMAS organizes inference as a collaborative process among specialized agents, enabling structured information flow across agents, trajectories, and refinement iterations. To support effective cross-trajectory collaboration, TMAS introduces hierarchical memories: the experience bank reuses low-level reliable intermediate conclusions and local feedback, while the guideline bank records previously explored high-level strategies to steer subsequent rollouts away from redundant reasoning patterns. A hybrid reward reinforcement learning scheme jointly preserves basic reasoning capability, enhances experience utilization, and encourages exploration beyond previously attempted solution strategies.
What carries the argument
Hierarchical memories consisting of an experience bank for reliable conclusions and a guideline bank for strategies, combined with a hybrid reward reinforcement learning scheme in a multi-agent setup.
If this is right
- TMAS achieves stronger iterative scaling than existing test-time scaling baselines on reasoning benchmarks.
- Hybrid reward training improves scaling effectiveness and stability across iterations.
- The framework enables better balance between exploration and exploitation in reasoning processes.
- Structured information flow reduces redundant reasoning patterns in multi-agent trajectories.
Where Pith is reading between the lines
- If the memory banks prove effective, similar hierarchical structures could be applied to other multi-agent systems beyond language models.
- The approach might allow for more efficient use of compute in long-horizon reasoning tasks by reusing past experiences.
- Testing on a wider range of tasks could reveal whether the synergy generalizes to areas like mathematical proof generation or code debugging.
- Dynamic adjustment of agent roles based on the guideline bank could further enhance adaptability.
Load-bearing premise
The hierarchical memories and hybrid reward reinforcement learning scheme will reliably balance exploration and exploitation in practice, and the chosen benchmarks and baselines are representative of broader reasoning performance.
What would settle it
Observing that TMAS fails to outperform baselines in iterative scaling on the tested reasoning benchmarks, or shows unstable performance with increasing iterations despite hybrid rewards.
Figures







read the original abstract
Test-time scaling has become an effective paradigm for improving the reasoning ability of large language models by allocating additional computation during inference. Recent structured approaches have further advanced this paradigm by organizing inference across multiple trajectories, refinement rounds, and verification-based feedback. However, existing structured test-time scaling methods either weakly coordinate parallel reasoning trajectories or rely on noisy historical information without explicitly deciding what should be retained and reused, limiting their ability to balance exploration and exploitation. In this work, we propose TMAS, a framework for scaling test-time compute via multi-agent synergy. TMAS organizes inference as a collaborative process among specialized agents, enabling structured information flow across agents, trajectories, and refinement iterations. To support effective cross-trajectory collaboration, TMAS introduces hierarchical memories: the experience bank reuses low-level reliable intermediate conclusions and local feedback, while the guideline bank records previously explored high-level strategies to steer subsequent rollouts away from redundant reasoning patterns. Furthermore, we design a hybrid reward reinforcement learning scheme tailored to TMAS, which jointly preserves basic reasoning capability, enhances experience utilization, and encourages exploration beyond previously attempted solution strategies. Extensive experiments on challenging reasoning benchmarks demonstrate that TMAS achieves stronger iterative scaling than existing test-time scaling baselines, while hybrid reward training further improves scaling effectiveness and stability across iterations. Code and data are available at https://github.com/george-QF/TMAS-code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TMAS, a multi-agent framework for scaling test-time compute in LLMs via collaborative agents with hierarchical memories (experience bank for low-level reliable conclusions and guideline bank for high-level strategies) and a hybrid reward RL scheme that preserves reasoning capability, enhances experience utilization, and encourages exploration. It claims that this design enables stronger iterative scaling on reasoning benchmarks than prior test-time scaling methods, with the hybrid reward further improving effectiveness and stability; code is released for reproducibility.
Significance. If the results hold under rigorous controls, the work would advance test-time scaling by providing an explicit mechanism for cross-trajectory information retention and reuse, addressing weak coordination in existing multi-trajectory approaches. The hierarchical memory distinction and hybrid RL objectives are conceptually clear contributions that could generalize to other agentic reasoning systems. Public code availability is a clear strength supporting verification and extension.
major comments (3)
- [Experiments] The central claim that TMAS plus hybrid reward produces measurably better iterative scaling curves than baselines (abstract and Experiments section) requires explicit confirmation that total token budget, number of trajectories, and rollout length are strictly matched across methods. Without such controls, stability gains cannot be attributed to the proposed synergy or hybrid reward rather than simply increased effective compute or agent count, as noted in the stress-test concern.
- [Method (Hybrid Reward)] The hybrid reward scheme (described in the method as jointly optimizing capability preservation, experience utilization, and exploration) lacks reported ablations on component weights or removal of individual terms. This is load-bearing for the stability claim, as it is unclear whether the balance is achieved in practice or if one term (e.g., exploration) dominates on the chosen benchmarks.
- [Method (Hierarchical Memories)] Details on update/query mechanisms for the experience bank and guideline bank, including how information flows across refinement iterations and agents, should be formalized with algorithms or pseudocode. Current description leaves open whether the hierarchical separation reliably prevents redundant patterns without introducing new failure modes.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments demonstrate...' but supplies no numerical results, benchmark names, or baseline identifiers; including one or two key quantitative highlights would improve the summary paragraph.
- [Figures] Figure captions and axis labels in scaling plots should explicitly state whether x-axis represents matched compute or raw iteration count to aid interpretation.
Simulated Author's Rebuttal
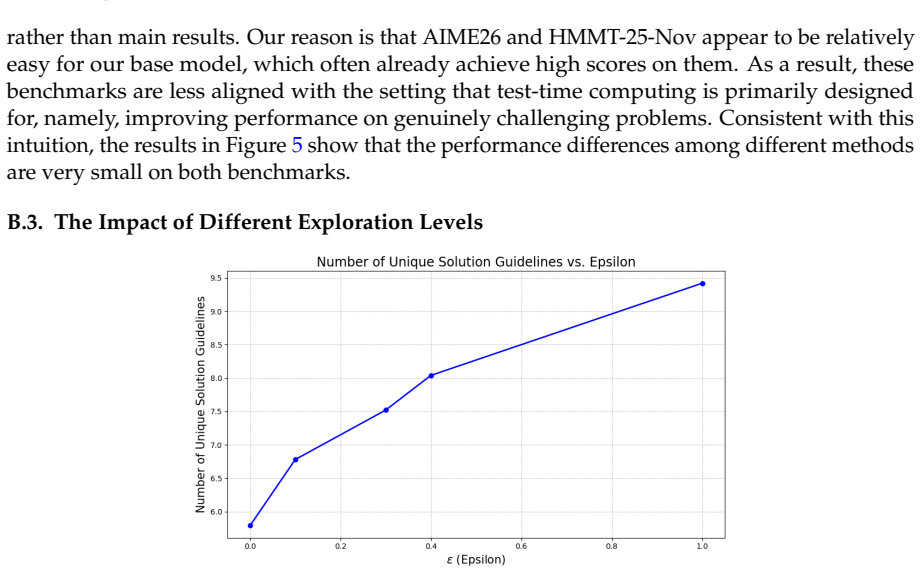
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our contributions on multi-agent test-time scaling. We address each major point below, providing clarifications where the manuscript already contains the requested controls and committing to targeted revisions for improved rigor and reproducibility.
read point-by-point responses
-
Referee: [Experiments] The central claim that TMAS plus hybrid reward produces measurably better iterative scaling curves than baselines (abstract and Experiments section) requires explicit confirmation that total token budget, number of trajectories, and rollout length are strictly matched across methods. Without such controls, stability gains cannot be attributed to the proposed synergy or hybrid reward rather than simply increased effective compute or agent count, as noted in the stress-test concern.
Authors: We agree that explicit confirmation of matched compute is essential for attributing gains to the proposed mechanisms. In the original experiments, total token budgets were controlled by fixing the number of parallel trajectories (e.g., 4–8 depending on benchmark) and rollout lengths (maximum 4 refinement iterations) identically for TMAS and all baselines, including single-trajectory and multi-trajectory methods; this is stated in Section 4.1 and the appendix compute tables. To eliminate any ambiguity, we will add a dedicated subsection titled 'Compute Matching Controls' in the Experiments section that tabulates token counts, trajectory counts, and rollout lengths per method and benchmark, along with a brief stress-test analysis varying agent count while holding total tokens fixed. This revision will directly address the concern and strengthen the attribution to synergy. revision: yes
-
Referee: [Method (Hybrid Reward)] The hybrid reward scheme (described in the method as jointly optimizing capability preservation, experience utilization, and exploration) lacks reported ablations on component weights or removal of individual terms. This is load-bearing for the stability claim, as it is unclear whether the balance is achieved in practice or if one term (e.g., exploration) dominates on the chosen benchmarks.
Authors: We acknowledge that component ablations would further substantiate the hybrid reward design. While the main paper reports the full hybrid objective and its effect on scaling stability, we did not include weight sweeps or term-removal ablations in the submitted version. We will add these in a new subsection of the Experiments (with a supplementary table showing performance when each term is removed or re-weighted by factors of 0.5/1.0/2.0). Preliminary internal runs indicate that removing the exploration term reduces diversity and iterative gains, while the capability-preservation term prevents degradation; the balanced weights yield the reported stability. These results will be included in the revision. revision: yes
-
Referee: [Method (Hierarchical Memories)] Details on update/query mechanisms for the experience bank and guideline bank, including how information flows across refinement iterations and agents, should be formalized with algorithms or pseudocode. Current description leaves open whether the hierarchical separation reliably prevents redundant patterns without introducing new failure modes.
Authors: We agree that formalizing the memory mechanisms will improve clarity and allow readers to verify the absence of new failure modes. The current textual description in Section 3.2 outlines the distinction (experience bank for low-level conclusions, guideline bank for high-level strategies) and the query/update logic, but lacks pseudocode. We will insert Algorithm 1 (Experience Bank Update/Query) and Algorithm 2 (Guideline Bank Update/Query) in the Method section, explicitly showing the cross-agent and cross-iteration information flow, deduplication checks, and retrieval scoring. These additions will also include a short discussion of potential failure modes (e.g., over-generalization in guidelines) and how the hierarchical separation mitigates them. revision: yes
Circularity Check
No circularity; framework design and empirical validation are independent of self-defined inputs
full rationale
The paper proposes TMAS as a new multi-agent framework with hierarchical memories (experience bank, guideline bank) and a hybrid reward RL scheme, then validates stronger iterative scaling via experiments on external reasoning benchmarks. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation. Claims rest on benchmark comparisons rather than internal consistency by construction, making the result self-contained against external data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TMAS introduces hierarchical memories: the experience bank reuses low-level reliable intermediate conclusions … while the guideline bank records previously explored high-level strategies … hybrid reward reinforcement learning scheme … preserves basic reasoning capability, enhances experience utilization, and encourages exploration beyond previously attempted solution strategies.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TMAS … runs for T iterations … ε-greedy generation … experience agent … guideline agent …
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Numerical: 0.5 is equivalent to 1/2. 1000 is equivalent to 1,000
-
[2]
\frac{1}{\sqrt{2}} is equivalent to \frac{\sqrt {2}}{2}
Algebraic: x+1 is equivalent to 1+x. \frac{1}{\sqrt{2}} is equivalent to \frac{\sqrt {2}}{2}
-
[3]
Formatting: Ignore Markdown formatting (bold, italic), latex styling (\text{}, \ mathrm{}), or whitespace differences
-
[4]
Ignore the student’s reasoning steps unless the result is embedded within them
Content: Focus ONLY on the final result value. Ignore the student’s reasoning steps unless the result is embedded within them
-
[5]
Output Format: Respond strictly in JSON format
Units: If the reference implies units and the student omits them (or vice versa) but the number is correct, count it as correct unless the problem explicitly demands unit conversion. Output Format: Respond strictly in JSON format. Do not output markdown code blocks. LLM-as-Judge User Prompt <problem> {problem} </problem> <reference> {reference} </referenc...
-
[6]
Analyze the mathematical value of both answers
-
[7]
Determine if they represent the same solution (equivalent). 17
-
[8]
If the student answer contains a derivation, look for the final result. Respond in JSON: { "reasoning": "Brief explanation...", "equivalent": true/false } A.3. Implementation Details of Baseline Methods For Self-Refine, we generate 8 solutions in parallel, and each solution is refined independently in subsequent rounds without any interaction across diffe...
-
[9]
A 2 × 1 tile is treated as covering exactly one full column
-
[10]
A 2 × 2 block is therefore assumed to have only two tilings: 𝑇(2)=2
-
[11]
The model derives 𝑇(𝑛)=𝑇(𝑛−1) +𝑇(𝑛−2) +𝑇(𝑛−4)
-
[12]
Therefore, 𝑇(4)=𝑇(3) +𝑇(2) +𝑇(0)=3+2+1=6. Diagnostic error.The solution explicitly or im- plicitly rules out horizontal placements of the 2 × 1 tile. By iteration 19, the no-experience baseline even states that horizontal placement is invalid, thereby reinforcing rather than cor- recting the original mistake. 6 wrong Correct solution pattern: rotation-awa...
-
[13]
A 2 × 1 rectangular tile can be placed either vertically or horizontally
-
[14]
Hence a 2×2 block has three tilings: 𝑇(2)=3, namely two vertical 2 × 1 tiles, one 2 × 2 square tile, or two horizontal 2×1 tiles
-
[15]
The correct recurrence is 𝑇(𝑛)=𝑇(𝑛−1) +2𝑇(𝑛−2) +𝑇(𝑛−4)
-
[16]
Therefore, 𝑇(4)=𝑇(3) +2𝑇(2) +𝑇(0)=5+6+1=12. Key correction.The model explicitly identi- fies the prior error: the wrong solutions under- count because they assume 𝑇( 2)= 2 and ignore the horizontal-pair tiling. 12 correct Figure 8. Comparison of wrong solution pattern and correct solution pattern. against ground-truth correctness, or employing stronger an...
-
[19]
Merely citing a result without showing why it applies or how it works is considered a failure
**Self-Containment:** Referencing external papers/theorems is allowed **IF AND ONLY IF** you also present a valid proof or clear derivation of the referenced argument . Merely citing a result without showing why it applies or how it works is considered a failure. **Process:**
-
[20]
Reason carefully about how to solve the problem
-
[21]
Draft your solution mentally or in your scratchpad
-
[22]
**Refine your solution** by fixing any potential logical gaps, ambiguity, or "hand- waving" arguments until it meets the highest standard of mathematical proof
-
[23]
**Output Format:** Your response should follow this exact markdown format: ## Solution
Present *only* your best, finalized version. **Output Format:** Your response should follow this exact markdown format: ## Solution ... // Your final, rigorous solution to the problem here. Ensure all steps are explicitly shown and justified. --- Here is your task input: ## Problem {question} Verification Prompt ## Instruction 25 Your task is to evaluate ...
-
[24]
Do NOT repeat logic that has already been identified as incorrect
**Error Correction:** You must explicitly address the flaws pointed out in the verification summaries. Do NOT repeat logic that has already been identified as incorrect
-
[25]
If minor details are omitted, it is considered imperfect
**Completeness:** The solution must cover all cases and steps. If minor details are omitted, it is considered imperfect
-
[26]
**Rigour:** Fatal errors or severe omissions are unacceptable
-
[27]
**Self-Containment:** Referencing external papers/theorems is allowed **IF AND ONLY IF** you also present a valid proof or clear derivation of the referenced argument . **Process:**
-
[28]
Read the **Problem** carefully
-
[29]
Identify exactly what went wrong, what was incomplete, and what (if anything) was correct
Study each **Previous Attempt** and its **Verification Summary**. Identify exactly what went wrong, what was incomplete, and what (if anything) was correct
-
[30]
Reason about how to fix the specific issues while retaining any correct sub-results from previous attempts
-
[31]
Draft your refined solution, ensuring it does not repeat the confirmed errors
-
[32]
**Output Format:** Your response should follow this exact markdown format: ## Solution
Present *only* your best, finalized, and fully corrected version. **Output Format:** Your response should follow this exact markdown format: ## Solution ... // Your final, rigorous, and corrected solution to the problem here. Ensure all steps are explicitly shown and justified. --- Here is your task input: ## Problem {question} Experience Context Appended...
-
[33]
**Non-trivial**: It must involve meaningful mathematical work -- a derivation, a transformation, a non-obvious equivalence, or a structural observation. Trivial arithmetic evaluations (e.g., "2025 == 2 mod 7") do NOT qualify unless the congruence itself is the key insight that unlocks a deeper argument. 28
work page 2025
-
[34]
Prefer results that establish structure over results that are dead ends
**Reusable**: It must be a stepping stone -- something a future solver can directly cite and proceed from, without needing to redo the work. Prefer results that establish structure over results that are dead ends
-
[35]
**Verifier-backed**: It must be explicitly confirmed correct by the verification summary. If verifiers are split on a step, do not add it as an Anchor. Verified Anchors fall into the following sub-types (use these to guide what you extract ): - **Structural Reduction**: A transformation that rewrites the problem or a sub-problem into a simpler or more tra...
work page 2025
-
[36]
Prioritize insights confirmed consistently across multiple rollouts
**ADD**: Extract new Verified Anchors or Error Avoidance Heuristics that are not already covered by the existing bank. Prioritize insights confirmed consistently across multiple rollouts
-
[37]
**KEEP**: Retain all existing entries that remain valid and are not contradicted by the new rollouts
-
[38]
Only merge entries that say the exact same thing about the exact same step
**REFINE**: If a new rollout provides a more precise version of an existing entry, rewrite it to be clearer. Only merge entries that say the exact same thing about the exact same step
-
[39]
**DELETE**: Remove entries explicitly revealed as incorrect by the verification summary. Remove entries that become fully subsumed after refinement. ## Quantity Guideline Aim for **20-35 entries** in total across both categories. Do NOT aggressively compress -- fine-grained, specific entries are more useful than over-generalized ones. Only merge entries t...
-
[40]
**Memory of exploration**: It records which broad strategic directions have already been tried, so the solver does not waste computation repeating the same approach
-
[41]
**Diversity enforcement**: When the solver is about to generate a new solution, it will be shown this bank and instructed to pursue a direction that is ** fundamentally different** from everything listed here. The bank therefore acts as the primary mechanism for controlling exploration -- the richer and more precise this log is, the better the solver can ...
-
[42]
**Identify** the high-level strategy used in the student’s solution (mathematical framework, key structural insight, angle of attack)
-
[43]
**Compare** it against each entry in <already_attempted_strategies>
-
[44]
**Classify**: - **1**: The student’s strategy is genuinely different from ALL listed strategies. - **0**: The student’s strategy is essentially the same as at least one listed strategy. - **-1**: Cannot determine the student’s strategy (solution too vague/incomplete). Respond in a JSON code block: ‘‘‘json {{ "identified_strategy": "Brief description of th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.