Recognition: 2 theorem links
· Lean TheoremActive Learning for Gaussian Process Regression Under Self-Induced Boltzmann Weights
Pith reviewed 2026-05-12 04:18 UTC · model grok-4.3
The pith
A Gaussian process acquisition function learns functions under self-induced Boltzmann weights without estimating the partition function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose AB-SID-iVAR, a Gaussian Process-based acquisition function that approximates the intractable Bayesian target distribution in closed form while avoiding partition function estimation, and is applicable to both discrete and continuous input domains. Despite the unknown target, under mild conditions, we establish that the terminal prediction error vanishes with high probability, and provide a tighter average-case guarantee.
What carries the argument
AB-SID-iVAR, a Gaussian Process-based acquisition function that approximates the intractable Bayesian target distribution in closed form while avoiding partition function estimation
Load-bearing premise
The mild conditions required for the vanishing prediction error guarantee must hold, and the closed-form approximation to the Bayesian target must be sufficiently accurate.
What would settle it
Observe whether the prediction error under the self-induced Boltzmann distribution reaches near zero after a finite number of queries on a real potential energy surface task, or if it plateaus at a positive value.
Figures










read the original abstract
We consider the active learning problem where the goal is to learn an unknown function with low prediction error under an unknown Boltzmann distribution induced by the function itself. This self-induced weighting arises naturally in problems such as potential energy surface (PES) modeling in computational chemistry, yet poses unique challenges as the target distribution is unknown and its partition function is intractable. We propose \texttt{AB-SID-iVAR}, a Gaussian Process-based acquisition function that approximates the intractable Bayesian target distribution in closed form while avoiding partition function estimation, and is applicable to both discrete and continuous input domains. We also analyze a Thompson sampling alternative (\texttt{TS-SID-iVAR}) as a higher variance Monte Carlo variant. Despite the unknown target, under mild conditions, we establish that the terminal prediction error vanishes with high probability, and provide a tighter average-case guarantee. We demonstrate consistent improvements over existing approaches in this setting on synthetic benchmarks and real-world PES modeling and drug discovery tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses active learning for Gaussian process regression when the target distribution is a self-induced Boltzmann weight depending on the unknown function itself (as in PES modeling). It proposes AB-SID-iVAR, a closed-form GP acquisition function that approximates the intractable Bayesian target without estimating the partition function Z, together with a Thompson-sampling variant TS-SID-iVAR. Under unspecified mild conditions the authors prove that terminal prediction error vanishes with high probability and supply a tighter average-case bound; empirical results on synthetic benchmarks and real PES/drug-discovery tasks show consistent gains over baselines.
Significance. If the closed-form approximation remains sufficiently faithful to the true f-dependent target throughout the active-learning loop and the mild conditions can be verified in practice, the work would be significant for domains where the sampling distribution is induced by the unknown function. The avoidance of partition-function estimation and the provision of both high-probability and average-case consistency results are notable strengths; the empirical validation on chemistry-relevant tasks further supports potential utility.
major comments (2)
- [Abstract and §4] Abstract and §4 (theoretical analysis): the central guarantee that 'the terminal prediction error vanishes with high probability' under 'mild conditions' is load-bearing for the contribution, yet the abstract and the statement of the theorem provide neither an explicit list of those conditions nor a quantitative bound on the approximation error between the closed-form AB-SID-iVAR target and the true self-induced posterior. Without such a bound it is unclear whether the approximation error contracts at a rate compatible with the GP consistency argument when the posterior is still diffuse.
- [§3.2] §3.2 (definition of AB-SID-iVAR): the claim that the acquisition function 'approximates the intractable Bayesian target distribution in closed form while avoiding partition function estimation' requires a precise statement of the approximation (e.g., which moments or variational family are used) and a proof that the resulting acquisition remains sufficiently close to the true expected information gain for the consistency result to carry through.
minor comments (2)
- [§2] Notation for the self-induced Boltzmann weight and the induced measure should be introduced once and used consistently; several passages switch between p(f) and the normalized weight without explicit re-definition.
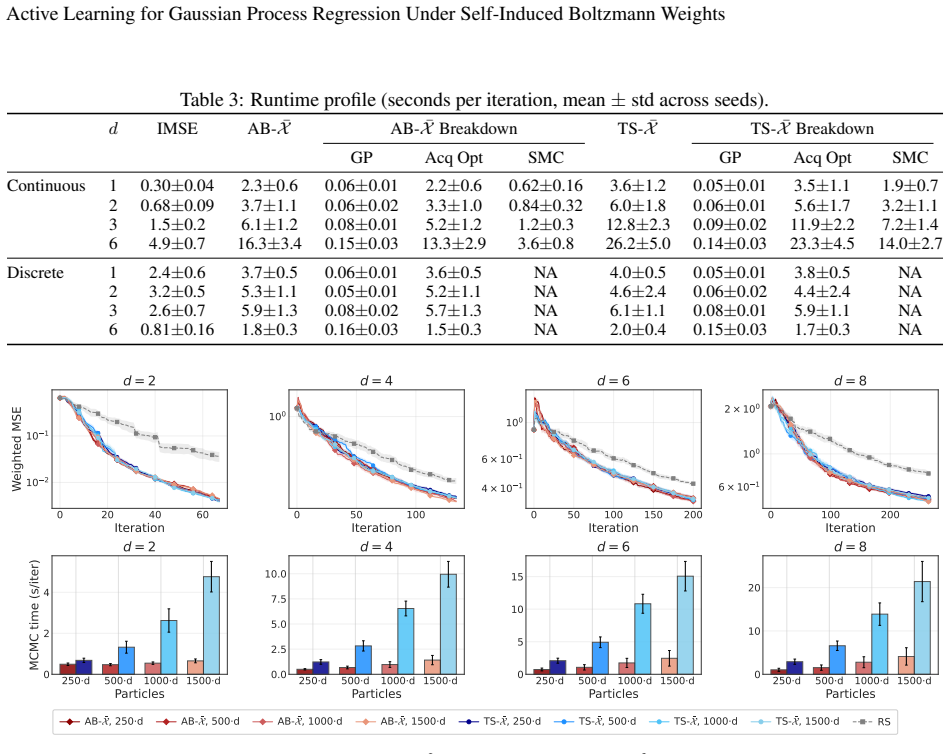
- [§5] Figure captions for the PES and drug-discovery experiments should state the number of independent runs, the precise definition of 'prediction error', and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify areas where the theoretical presentation can be strengthened for clarity. We address each point below and will revise the manuscript to incorporate explicit conditions, bounds, and proofs as detailed in our responses.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (theoretical analysis): the central guarantee that 'the terminal prediction error vanishes with high probability' under 'mild conditions' is load-bearing for the contribution, yet the abstract and the statement of the theorem provide neither an explicit list of those conditions nor a quantitative bound on the approximation error between the closed-form AB-SID-iVAR target and the true self-induced posterior. Without such a bound it is unclear whether the approximation error contracts at a rate compatible with the GP consistency argument when the posterior is still diffuse.
Authors: We agree that the mild conditions should be stated explicitly and that a quantitative bound on the approximation error is needed to fully support the consistency claim. In the revised version we will list the conditions explicitly in the abstract and in the theorem statement of §4 (compact input domain, continuous kernel with bounded variance, and Lipschitz continuity of the target function). We will also add a supporting lemma bounding the pointwise difference between the AB-SID-iVAR acquisition and the true self-induced expected information gain by a term proportional to the maximum posterior standard deviation; this term contracts as the GP posterior concentrates, ensuring compatibility with the high-probability vanishing-error argument even while the posterior remains diffuse early in the loop. revision: yes
-
Referee: [§3.2] §3.2 (definition of AB-SID-iVAR): the claim that the acquisition function 'approximates the intractable Bayesian target distribution in closed form while avoiding partition function estimation' requires a precise statement of the approximation (e.g., which moments or variational family are used) and a proof that the resulting acquisition remains sufficiently close to the true expected information gain for the consistency result to carry through.
Authors: We will revise §3.2 to give a precise definition: AB-SID-iVAR replaces the intractable self-induced Boltzmann weights with a moment-matched Gaussian approximation constructed from the current GP posterior mean and variance at each candidate point, thereby avoiding any estimation of the partition function Z. We will add a proposition proving that the resulting acquisition differs from the true expected information gain by an error controlled by the GP posterior variance; under the mild conditions already used for consistency, this error is small enough that the high-probability terminal-error guarantee continues to hold. The proof will be placed immediately after the definition in §3.2 and referenced in §4. revision: yes
Circularity Check
No circularity: novel closed-form approximation and consistency result are independently derived
full rationale
The paper defines a new acquisition function AB-SID-iVAR that constructs a closed-form approximation to the self-induced Boltzmann target without using partition functions, then separately states a consistency theorem that the terminal GP error vanishes whp under mild conditions. Neither the approximation nor the guarantee is obtained by fitting a parameter to data and relabeling it a prediction, nor by self-citation that reduces the central claim to an unverified prior result of the same authors. The derivation chain therefore remains self-contained against external GP theory and active-learning benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Physical Chemistry Chemical Physics , volume=
Ab initio investigation of the role of the d-states occupation on the adsorption properties of H 2, CO, CH 4 and CH 3 OH on the Fe 13, Co 13, Ni 13 and Cu 13 clusters , author=. Physical Chemistry Chemical Physics , volume=. 2021 , publisher=
work page 2021
-
[2]
Modern quantum chemistry: introduction to advanced electronic structure theory , author=. 2012 , publisher=
work page 2012
-
[3]
The Journal of Chemical Physics , volume=
The quantum dynamics of H2 on Cu (111) at a surface temperature of 925 K: Comparing state-of-the-art theory to state-of-the-art experiments 2 , author=. The Journal of Chemical Physics , volume=. 2023 , publisher=
work page 2023
-
[4]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[5]
New Journal of Physics , volume=
Properties of metal--water interfaces studied from first principles , author=. New Journal of Physics , volume=
-
[6]
Computer simulation of local order in condensed phases of silicon , author=. Physical review B , volume=. 1985 , publisher=
work page 1985
-
[7]
The Journal of chemical physics , volume=
A foundation model for atomistic materials chemistry , author=. The Journal of chemical physics , volume=. 2025 , publisher=
work page 2025
-
[8]
Machine Learning: Science and Technology , volume=
Benchmarking of machine learning interatomic potentials for reactive hydrogen dynamics at metal surfaces , author=. Machine Learning: Science and Technology , volume=. 2024 , publisher=
work page 2024
-
[9]
The Journal of chemical physics , volume=
Structure and shape variations in intermediate-size copper clusters , author=. The Journal of chemical physics , volume=. 2006 , publisher=
work page 2006
-
[10]
arXiv preprint arXiv:2409.09787 , year=
Bnem: A boltzmann sampler based on bootstrapped noised energy matching , author=. arXiv preprint arXiv:2409.09787 , year=
-
[11]
arXiv preprint arXiv:2603.17579 , year=
One-Step Sampler for Boltzmann Distributions via Drifting , author=. arXiv preprint arXiv:2603.17579 , year=
-
[12]
Understanding molecular simulation: from algorithms to applications , author=. 2023 , publisher=
work page 2023
-
[13]
Journal of artificial intelligence research , volume=
Active learning with statistical models , author=. Journal of artificial intelligence research , volume=
-
[14]
Information-based objective functions for active data selection , author=. Neural computation , volume=. 1992 , publisher=
work page 1992
-
[15]
npj Computational Materials , volume=
Hyperactive learning for data-driven interatomic potentials , author=. npj Computational Materials , volume=. 2023 , publisher=
work page 2023
-
[16]
Computational Statistics & Data Analysis , volume=
Gaussian processes and limiting linear models , author=. Computational Statistics & Data Analysis , volume=. 2008 , publisher=
work page 2008
-
[17]
Advances in Neural Information Processing Systems , volume=
Bayesian active learning with fully Bayesian Gaussian processes , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Bayesian active learning for classification and preferenc e learning,
Bayesian active learning for classification and preference learning , author=. arXiv preprint arXiv:1112.5745 , year=
-
[19]
Gaussian process optimization in the bandit setting: No regret and experimental design,
Gaussian process optimization in the bandit setting: No regret and experimental design , author=. arXiv preprint arXiv:0912.3995 , year=
-
[20]
arXiv preprint arXiv:2502.16870 , year=
Distributionally Robust Active Learning for Gaussian Process Regression , author=. arXiv preprint arXiv:2502.16870 , year=
-
[21]
Advances in neural information processing systems , volume=
Sampling for inference in probabilistic models with fast Bayesian quadrature , author=. Advances in neural information processing systems , volume=
-
[22]
arXiv preprint arXiv:2506.16471 , year=
Progressive Inference-Time Annealing of Diffusion Models for Sampling from Boltzmann Densities , author=. arXiv preprint arXiv:2506.16471 , year=
-
[23]
arXiv preprint arXiv:2104.02822 , year=
Low-regret active learning , author=. arXiv preprint arXiv:2104.02822 , year=
-
[24]
the Annals of Probability , pages=
On tail probabilities for martingales , author=. the Annals of Probability , pages=. 1975 , publisher=
work page 1975
-
[25]
The journal of chemical physics , volume=
Equation of state calculations by fast computing machines , author=. The journal of chemical physics , volume=. 1953 , publisher=
work page 1953
-
[26]
International conference on neural information processing , pages=
Contextual bandit for active learning: Active thompson sampling , author=. International conference on neural information processing , pages=. 2014 , organization=
work page 2014
-
[27]
Exponential convergence of Langevin distributions and their discrete approximations , author=
-
[28]
Advances in Neural Information Processing Systems , volume=
Unexpected improvements to expected improvement for bayesian optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
arXiv preprint arXiv:2402.02229 , year=
Vanilla Bayesian optimization performs great in high dimensions , author=. arXiv preprint arXiv:2402.02229 , year=
-
[30]
Uncertainty in Artificial Intelligence , pages=
No-regret approximate inference via Bayesian optimisation , author=. Uncertainty in Artificial Intelligence , pages=. 2021 , organization=
work page 2021
-
[31]
International conference on artificial intelligence and statistics , pages=
Prediction-oriented bayesian active learning , author=. International conference on artificial intelligence and statistics , pages=. 2023 , organization=
work page 2023
-
[32]
Journal of Computational Physics , volume=
Bayesian optimization with output-weighted optimal sampling , author=. Journal of Computational Physics , volume=. 2021 , publisher=
work page 2021
-
[33]
Advances in neural information processing systems , volume=
Adversarially robust optimization with Gaussian processes , author=. Advances in neural information processing systems , volume=
-
[34]
Journal of Machine Learning Research , volume=
Convergence guarantees for Gaussian process means with misspecified likelihoods and smoothness , author=. Journal of Machine Learning Research , volume=
-
[35]
International Conference on Machine Learning , pages=
Efficiently sampling functions from Gaussian process posteriors , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[36]
arXiv preprint arXiv:2510.23681 , year=
Informed Initialization for Bayesian Optimization and Active Learning , author=. arXiv preprint arXiv:2510.23681 , year=
-
[37]
Modern Bayesian experimental design , author=. Statistical Science , volume=. 2024 , publisher=
work page 2024
-
[38]
arXiv preprint arXiv:2311.14645 , year=
A general framework for user-guided Bayesian optimization , author=. arXiv preprint arXiv:2311.14645 , year=
-
[39]
Journal of Machine Learning Research , volume=
Pathwise conditioning of Gaussian processes , author=. Journal of Machine Learning Research , volume=
-
[40]
Adaptive estimation of a quadratic functional by model selection , author=. Annals of statistics , pages=. 2000 , publisher=
work page 2000
-
[41]
Conference On Learning Theory , pages=
Information directed sampling and bandits with heteroscedastic noise , author=. Conference On Learning Theory , pages=. 2018 , organization=
work page 2018
- [42]
-
[43]
arXiv preprint arXiv:2506.17366 , year=
Gaussian Processes and Reproducing Kernels: Connections and Equivalences , author=. arXiv preprint arXiv:2506.17366 , year=
-
[44]
Targeted Variance Reduction: Effective Bayesian Optimization of Black-Box Simulators with Noise Parameters , author=. Technometrics , number=. 2025 , publisher=
work page 2025
-
[45]
Journal of Machine Learning Research , year =
Mert Gurbuzbalaban and Yuanhan Hu and Lingjiong Zhu , title =. Journal of Machine Learning Research , year =
-
[46]
Communications in Statistics-Theory and Methods , volume=
Posterior contraction rates for constrained deep Gaussian processes in density estimation and classification , author=. Communications in Statistics-Theory and Methods , volume=. 2025 , publisher=
work page 2025
-
[47]
Journal of statistical planning and inference , volume=
Posterior consistency of logistic Gaussian process priors in density estimation , author=. Journal of statistical planning and inference , volume=. 2007 , publisher=
work page 2007
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Kernelized normalizing constant estimation: bridging Bayesian quadrature and Bayesian optimization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
Advances in Neural Information Processing Systems , volume=
Tanimoto random features for scalable molecular machine learning , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning , author=. arXiv preprint arXiv:1910.00177 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[51]
International Conference on Machine Learning , pages=
Loss-guided diffusion models for plug-and-play controllable generation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[52]
Journal of chemical information and modeling , volume=
GuacaMol: benchmarking models for de novo molecular design , author=. Journal of chemical information and modeling , volume=. 2019 , publisher=
work page 2019
-
[53]
Journal of chemical theory and computation , volume=
Exploration, sampling, and reconstruction of free energy surfaces with Gaussian process regression , author=. Journal of chemical theory and computation , volume=. 2016 , publisher=
work page 2016
-
[54]
arXiv preprint arXiv:2403.03816 , year=
Targeted variance reduction: Robust Bayesian optimization of black-box simulators with noise parameters , author=. arXiv preprint arXiv:2403.03816 , year=
-
[55]
Posterior consistency of Gaussian process prior for nonparametric binary regression , author=
-
[56]
Advances in neural information processing systems , volume=
Bayesian optimization with exponential convergence , author=. Advances in neural information processing systems , volume=
-
[57]
Gaussian processes for machine learning , author=. 2006 , publisher=
work page 2006
-
[58]
arXiv preprint arXiv:2106.11719 , year=
Test distribution-aware active learning: A principled approach against distribution shift and outliers , author=. arXiv preprint arXiv:2106.11719 , year=
-
[59]
Engineering with Computers , volume=
Adaptive sampling with automatic stopping for feasible region identification in engineering design , author=. Engineering with Computers , volume=. 2022 , publisher=
work page 2022
-
[60]
Jasra, Ajay and Stephens, David A and Doucet, Arnaud and Tsagaris, Theodoros , journal=. Inference for L. 2011 , publisher=
work page 2011
-
[61]
Statistics and Computing , volume=
Sequential Monte Carlo on large binary sampling spaces , author=. Statistics and Computing , volume=. 2013 , publisher=
work page 2013
-
[62]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Sequential monte carlo samplers , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2006 , publisher=
work page 2006
- [63]
-
[64]
Design and analysis of computer experiments , author=. Statistical science , volume=. 1989 , publisher=
work page 1989
-
[65]
Forschungsbericht- Deutsche Forschungs- und Versuchsanstalt fur Luft- und Raumfahrt , year=
A software package for sequential quadratic programming , author=. Forschungsbericht- Deutsche Forschungs- und Versuchsanstalt fur Luft- und Raumfahrt , year=
-
[66]
Iterated denoising energy matching for sampling from boltzmann densities
Iterated denoising energy matching for sampling from boltzmann densities , author=. arXiv preprint arXiv:2402.06121 , year=
-
[67]
The Journal of Physical Chemistry Letters , volume=
On-the-fly active learning of interatomic potentials for large-scale atomistic simulations , author=. The Journal of Physical Chemistry Letters , volume=. 2020 , publisher=
work page 2020
-
[68]
npj Computational Materials , volume=
On-the-fly active learning of interpretable Bayesian force fields for atomistic rare events , author=. npj Computational Materials , volume=. 2020 , publisher=
work page 2020
-
[69]
Computational Materials Science , volume=
Active learning of linearly parametrized interatomic potentials , author=. Computational Materials Science , volume=. 2017 , publisher=
work page 2017
-
[70]
Physical review letters , volume=
Molecular dynamics with on-the-fly machine learning of quantum-mechanical forces , author=. Physical review letters , volume=. 2015 , publisher=
work page 2015
-
[71]
Advances in Neural Information Processing Systems , volume=
Transductive active learning: Theory and applications , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Proceedings of the 23rd international conference on Machine learning , pages=
Active learning via transductive experimental design , author=. Proceedings of the 23rd international conference on Machine learning , pages=
-
[73]
Optimal experimental design: Formulations and computations , author=. Acta Numerica , volume=. 2024 , publisher=
work page 2024
-
[74]
npj Computational Materials , volume=
Uncertainty driven active learning of coarse grained free energy models , author=. npj Computational Materials , volume=. 2024 , publisher=
work page 2024
-
[75]
Frogner, Charlie and Claici, Sebastian and Chien, Edward and Solomon, Justin , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2021 , issue_date =
work page 2021
- [76]
-
[77]
arXiv preprint arXiv:2502.09198 , year=
Understanding high-dimensional bayesian optimization , author=. arXiv preprint arXiv:2502.09198 , year=
work page internal anchor Pith review arXiv
-
[78]
arXiv preprint arXiv:2402.02746 , year=
Standard gaussian process is all you need for high-dimensional bayesian optimization , author=. arXiv preprint arXiv:2402.02746 , year=
-
[79]
Advances in neural information processing systems , volume=
Scalable Thompson sampling using sparse Gaussian process models , author=. Advances in neural information processing systems , volume=
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.