Recognition: no theorem link
RelFlexformer: Efficient Attention 3D-Transformers for Integrable Relative Positional Encodings
Pith reviewed 2026-05-12 05:21 UTC · model grok-4.3
The pith
RelFlexformers integrate arbitrary integrable relative positional encodings via non-uniform Fourier transforms to deliver O(L log L) attention for 3D points at irregular locations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RelFlexformers are 3D-Transformer models that flexibly integrate universal 3D Relative Positional Encoding methods given by arbitrary integrable modulation functions f, achieve O(L log L) attention complexity by leveraging the Non-Uniform Fourier Transform, and generalize existing RPE-attention techniques from homogeneous grid settings to arbitrary heterogeneous 3D position distributions such as point clouds.
What carries the argument
The Non-Uniform Fourier Transform (NU-FFT) applied to integrable modulation functions, which modulates attention scores for tokens at arbitrarily distributed 3D coordinates.
If this is right
- Point-cloud modeling becomes directly feasible without forcing tokens onto uniform grids.
- Attention for long 3D sequences remains practical because cost grows as O(L log L) rather than O(L squared).
- Existing RPE methods for grid data extend automatically to heterogeneous 3D layouts.
- Empirical tests on multiple 3D datasets show measurable quality gains from the flexible encodings.
Where Pith is reading between the lines
- The same NU-FFT construction could be tested in 2D or 4D settings to check whether the efficiency pattern generalizes beyond three dimensions.
- Hybrid models that combine RelFlexformer blocks with other fast attention primitives might further reduce constants in practice.
- Applications such as 3D scene reconstruction or molecular modeling could benefit from the removal of grid assumptions.
- Error bounds on the NU-FFT approximation for specific families of modulation functions remain open for tighter analysis.
Load-bearing premise
Integrable modulation functions exist that can be evaluated via NU-FFT on arbitrary 3D positions without extra structure or approximation errors large enough to erase the claimed speed or quality gains.
What would settle it
Measure wall-clock attention time and downstream accuracy on a large irregular point-cloud dataset while scaling sequence length L; the claim holds if runtime stays linearithmic and accuracy does not drop below standard quadratic-attention baselines.
Figures
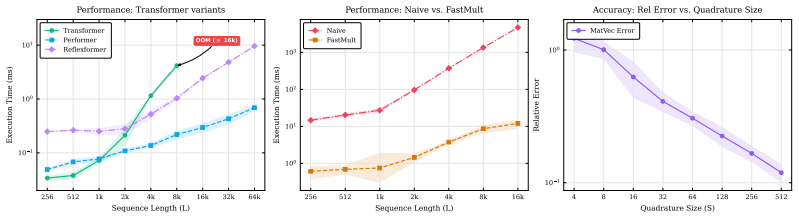


read the original abstract
We present a new class of efficient attention mechanisms applying universal 3D Relative Positional Encoding (RPE) methods given by arbitrary integrable modulation functions $f$. They lead to the new class of 3D-Transformer models, called \textit{RelFlexformers}, flexibly integrating those RPEs, and characterized by the $O(L \log L)$ time complexity of the attention computation for the $L$-length input sequences. RelFlexformers builds on the theory of the Non-Uniform Fourier Transform (NU-FFT), naturally generalizing several existing efficient RPE-attention methods from structured settings with tokens homogeneously embedded in unweighted grids into general non-structured heterogeneous scenarios, where tokens' positions are arbitrarily distributed in the corresponding 3D spaces. As such, RelFlexformers can be applied in particular to model point clouds. Our extensive empirical evaluation on a large portfolio of 3D datasets confirms quality improvements provided by the NU-FFT-driven attention modulation techniques in the RelFlexformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RelFlexformers, a new class of 3D-Transformer models that integrate arbitrary integrable relative positional encodings (RPEs) defined by modulation functions f via the Non-Uniform Fast Fourier Transform (NU-FFT). This yields O(L log L) attention complexity for L-length sequences with arbitrarily distributed 3D token positions, generalizing prior efficient RPE methods from homogeneous grid settings to heterogeneous unstructured point clouds, with empirical quality gains demonstrated on a portfolio of 3D datasets.
Significance. If the NU-FFT approximation errors can be rigorously bounded to preserve both the stated complexity and performance, the work would meaningfully advance efficient attention for unstructured 3D data by unifying and extending grid-based RPE techniques into a flexible framework applicable to point clouds. The manuscript earns credit for grounding the approach in established NU-FFT theory and for conducting extensive empirical evaluation across multiple 3D datasets.
major comments (2)
- [§3] §3 (NU-FFT-based RPE integration): The central claim of exact O(L log L) complexity for arbitrary 3D position distributions rests on representing integrable modulation functions f via NU-FFT, yet the manuscript provides no explicit error bounds or analysis for the approximation parameters (oversampling factor, kernel support, grid size) specific to these f; this is load-bearing for the generalization from structured grids to heterogeneous scenarios and for the claimed complexity-quality tradeoff.
- [§5] §5 (Empirical evaluation): The reported quality improvements lack ablation or sensitivity analysis on the NU-FFT approximation parameters, leaving open whether the gains hold under varying point densities or when error is controlled to machine precision, which directly affects the practical validity of the heterogeneous 3D claims.
minor comments (3)
- [§2] The definition and integrability conditions on the modulation function f are introduced late; an explicit early statement with an example would improve readability.
- [Figure 2] Figure 2 (attention visualization): The caption does not specify the exact NU-FFT parameters used, making it difficult to reproduce the depicted modulation effects.
- [§1] Several citations to prior grid-based RPE methods (e.g., in §1) could be expanded with direct complexity comparisons to highlight the precise generalization achieved.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments highlight important aspects of rigor in the theoretical claims and empirical validation. We address each point below and outline revisions that will strengthen the manuscript while preserving its core contributions on flexible 3D RPE via NU-FFT.
read point-by-point responses
-
Referee: [§3] §3 (NU-FFT-based RPE integration): The central claim of exact O(L log L) complexity for arbitrary 3D position distributions rests on representing integrable modulation functions f via NU-FFT, yet the manuscript provides no explicit error bounds or analysis for the approximation parameters (oversampling factor, kernel support, grid size) specific to these f; this is load-bearing for the generalization from structured grids to heterogeneous scenarios and for the claimed complexity-quality tradeoff.
Authors: We agree that a dedicated error analysis is necessary to fully support the generalization to heterogeneous 3D positions. The NU-FFT framework (as established in the literature, e.g., Greengard et al.) provides general error bounds controlled by the oversampling factor, kernel support width, and grid resolution, which can be made arbitrarily small for integrable f without changing the asymptotic O(L log L) complexity. However, the manuscript does not tailor these bounds explicitly to the modulation functions f used in RelFlexformers. In the revision, we will add a new subsection in §3 that (i) recalls the relevant NU-FFT error theorems, (ii) derives parameter-dependent bounds specific to the integrable f considered (including examples for common RPE kernels), and (iii) discusses how the approximation error trades off against the claimed complexity for unstructured point clouds. This will make the load-bearing assumptions explicit. revision: yes
-
Referee: [§5] §5 (Empirical evaluation): The reported quality improvements lack ablation or sensitivity analysis on the NU-FFT approximation parameters, leaving open whether the gains hold under varying point densities or when error is controlled to machine precision, which directly affects the practical validity of the heterogeneous 3D claims.
Authors: We acknowledge that the current empirical section does not include sensitivity analysis on the NU-FFT hyperparameters. To close this gap, the revised §5 will incorporate additional ablation studies that (i) vary the oversampling factor, kernel support, and grid size across the portfolio of 3D datasets (including point clouds with heterogeneous densities), (ii) report performance when the NU-FFT approximation error is driven to near machine precision, and (iii) compare against the default parameters used in the main results. These experiments will demonstrate that the observed quality gains are robust and not artifacts of particular approximation settings, thereby reinforcing the practical validity of the heterogeneous 3D claims. revision: yes
Circularity Check
No circularity: derivation relies on external NU-FFT theory for O(L log L) complexity
full rationale
The paper defines RelFlexformers via application of integrable modulation functions f through NU-FFT to achieve O(L log L) attention for arbitrary 3D point distributions. This builds directly on established non-uniform FFT properties (external to the paper) rather than re-deriving or fitting them from the model's own outputs. No equations reduce a claimed prediction to a fitted parameter by construction, no self-citation forms the load-bearing uniqueness argument, and the generalization from grid RPEs is presented as an extension using prior NU-FFT results. The abstract and description contain no self-referential definitions or renamings that collapse the central claim.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Modulation functions f are integrable
- domain assumption NU-FFT can be applied to arbitrarily distributed token positions in 3D without loss of the stated complexity
Reference graph
Works this paper leans on
-
[1]
3d semantic parsing of large-scale indoor spaces
Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, Ioannis Brilakis, Martin Fischer, and Silvio Savarese. 3d semantic parsing of large-scale indoor spaces. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1534–1543, 2016
work page 2016
-
[2]
Point convolutional neural networks by extension operators.arXiv preprint arXiv:1803.10091, 2018
Matan Atzmon, Haggai Maron, and Yaron Lipman. Point convolutional neural networks by extension operators.arXiv preprint arXiv:1803.10091, 2018
-
[3]
Multimae: Multi-modal multi-task masked autoencoders
Roman Bachmann, David Mizrahi, Andrei Atanov, and Amir Zamir. Multimae: Multi-modal multi-task masked autoencoders. InEuropean conference on computer vision, pages 348–367. Springer, 2022
work page 2022
-
[4]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document trans- former.arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[5]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
work page 2020
-
[6]
Shapeconv: Shape-aware convolutional layer for indoor rgb-d semantic segmentation
Jinming Cao, Hanchao Leng, Dani Lischinski, Daniel Cohen-Or, Changhe Tu, and Yangyan Li. Shapeconv: Shape-aware convolutional layer for indoor rgb-d semantic segmentation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7088–7097, 2021
work page 2021
-
[7]
Lin-Zhuo Chen, Zheng Lin, Ziqin Wang, Yong-Liang Yang, and Ming-Ming Cheng. Spatial information guided convolution for real-time rgbd semantic segmentation.IEEE Transactions on Image Processing, 30:2313–2324, 2021. 10
work page 2021
-
[8]
Xiaokang Chen, Kwan-Yee Lin, Jingbo Wang, Wayne Wu, Chen Qian, Hongsheng Li, and Gang Zeng. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for rgb-d semantic segmentation. InEuropean conference on computer vision, pages 561–577. Springer, 2020
work page 2020
-
[9]
Scaling up kernels in 3d cnns.arXiv preprint arXiv:2206.10555, 1(2):5, 2022
Yukang Chen, Jianhui Liu, Xiaojuan Qi, Xiangyu Zhang, Jian Sun, and Jiaya Jia. Scaling up kernels in 3d cnns.arXiv preprint arXiv:2206.10555, 1(2):5, 2022
-
[10]
A unified point- based framework for 3d segmentation
Hung-Yueh Chiang, Yen-Liang Lin, Yueh-Cheng Liu, and Winston H Hsu. A unified point- based framework for 3d segmentation. In2019 International Conference on 3D Vision (3DV), pages 155–163. IEEE, 2019
work page 2019
-
[11]
Krzysztof Choromanski, Han Lin, Haoxian Chen, Tianyi Zhang, Arijit Sehanobish, Valerii Likhosherstov, Jack Parker-Holder, Tamás Sarlós, Adrian Weller, and Thomas Weingarten. From block-toeplitz matrices to differential equations on graphs: towards a general theory for scalable masked transformers. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Sz...
work page 2022
-
[12]
Rethinking attention with performers
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, An- dreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. InInternational Conference on Learning Representations, 2021
work page 2021
-
[13]
Fast tree-field integra- tors: From low displacement rank to topological transformers
Krzysztof Marcin Choromanski, Arijit Sehanobish, Somnath Basu Roy Chowdhury, Han Lin, Kumar Avinava Dubey, Tamas Sarlos, and Snigdha Chaturvedi. Fast tree-field integra- tors: From low displacement rank to topological transformers. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[14]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3075–3084, 2019
work page 2019
-
[15]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
work page 2017
-
[16]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Fast kernel methods: Sobolev, physics-informed, and additive models, 2025
Nathan Doumèche, Francis Bach, Gérard Biau, and Claire Boyer. Fast kernel methods: Sobolev, physics-informed, and additive models, 2025
work page 2025
-
[18]
Siqi Du, Weixi Wang, Renzhong Guo, Ruisheng Wang, and Shengjun Tang. Asymformer: Asymmetrical cross-modal representation learning for mobile platform real-time rgb-d se- mantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7608–7615, 2024
work page 2024
-
[19]
American Mathematical Soc., 2009
Gerald B Folland.Fourier analysis and its applications, volume 4. American Mathematical Soc., 2009
work page 2009
-
[20]
Omnivore: A single model for many visual modalities
Rohit Girdhar, Mannat Singh, Nikhila Ravi, Laurens Van Der Maaten, Armand Joulin, and Ishan Misra. Omnivore: A single model for many visual modalities. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16102–16112, 2022
work page 2022
-
[21]
3d semantic segmentation with submanifold sparse convolutional networks
Benjamin Graham, Martin Engelcke, and Laurens Van Der Maaten. 3d semantic segmentation with submanifold sparse convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9224–9232, 2018
work page 2018
-
[22]
Accelerating the nonuniform fast fourier transform.SIAM Review, 46(3):443–454, 2004
Leslie Greengard and June-Yub Lee. Accelerating the nonuniform fast fourier transform.SIAM Review, 46(3):443–454, 2004. 11
work page 2004
-
[23]
Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R. Martin, and Shi-Min Hu. Pct: Point cloud transformer.Computational Visual Media, 7(2):187–199, Apr 2021
work page 2021
-
[24]
Learning rich features from rgb-d images for object detection and segmentation
Saurabh Gupta, Ross Girshick, Pablo Arbeláez, and Jitendra Malik. Learning rich features from rgb-d images for object detection and segmentation. InEuropean conference on computer vision, pages 345–360. Springer, 2014
work page 2014
-
[25]
Deberta: Decoding-enhanced bert with disentangled attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention. InInternational Conference on Learning Representations, 2021
work page 2021
-
[26]
Point-to-voxel knowledge distillation for lidar semantic segmentation
Yuenan Hou, Xinge Zhu, Yuexin Ma, Chen Change Loy, and Yikang Li. Point-to-voxel knowledge distillation for lidar semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022
work page 2022
-
[27]
Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation
Xinxin Hu, Kailun Yang, Lei Fei, and Kaiwei Wang. Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation. In2019 IEEE international conference on image processing (ICIP), pages 1440–1444. IEEE, 2019
work page 2019
-
[28]
Fourier position embedding: enhancing atten- tion’s periodic extension for length generalization
Ermo Hua, Che Jiang, Xingtai Lv, Kaiyan Zhang, Youbang Sun, Yuchen Fan, Xuekai Zhu, Biqing Qi, Ning Ding, and Bowen Zhou. Fourier position embedding: enhancing atten- tion’s periodic extension for length generalization. InProceedings of the 42nd International Conference on Machine Learning, ICML’25. JMLR.org, 2025
work page 2025
-
[29]
Hierarchical point-edge interaction network for point cloud semantic segmentation
Li Jiang, Hengshuang Zhao, Shu Liu, Xiaoyong Shen, Chi-Wing Fu, and Jiaya Jia. Hierarchical point-edge interaction network for point cloud semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
work page 2019
-
[30]
Transformers are rnns: fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: fast autoregressive transformers with linear attention. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020
work page 2020
-
[31]
Reformer: The efficient transformer
Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In International Conference on Learning Representations, 2020
work page 2020
-
[32]
Rethinking range view representation for lidar segmentation
Lingdong Kong, Youquan Liu, Runnan Chen, Yuexin Ma, Xinge Zhu, Yikang Li, Yuenan Hou, Yu Qiao, and Ziwei Liu. Rethinking range view representation for lidar segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[33]
Spherical transformer for lidar-based 3d recognition
Xin Lai, Yukang Chen, Fanbin Lu, Jianhui Liu, and Jiaya Jia. Spherical transformer for lidar-based 3d recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023
work page 2023
-
[34]
Stratified transformer for 3d point cloud segmentation
Xin Lai, Jianhui Liu, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, and Jiaya Jia. Stratified transformer for 3d point cloud segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8500–8509, 2022
work page 2022
-
[35]
Large-scale point cloud semantic segmentation with superpoint graphs
Loic Landrieu and Martin Simonovsky. Large-scale point cloud semantic segmentation with superpoint graphs. InProceedings of the IEEE conference on computer vision and pattern recognition, 2018
work page 2018
-
[36]
Pointgrid: A deep network for 3d shape understanding
Truc Le and Ye Duan. Pointgrid: A deep network for 3d shape understanding. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9204–9214, 2018
work page 2018
-
[37]
Seggcn: Efficient 3d point cloud segmentation with fuzzy spherical kernel
Huan Lei, Naveed Akhtar, and Ajmal Mian. Seggcn: Efficient 3d point cloud segmentation with fuzzy spherical kernel. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020
work page 2020
-
[38]
Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. Pointcnn: Convolution on x-transformed points.Advances in neural information processing systems, 31, 2018. 12
work page 2018
-
[39]
Pamba: enhancing global interaction in point clouds via state space model
Zhuoyuan Li, Yubo Ai, Jiahao Lu, ChuXin Wang, Jiacheng Deng, Hanzhi Chang, Yanzhe Liang, Wenfei Yang, Shifeng Zhang, and Tianzhu Zhang. Pamba: enhancing global interaction in point clouds via state space model. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5092–5100, 2025
work page 2025
-
[40]
Dingkang Liang, Xin Zhou, Wei Xu, Xingkui Zhu, Zhikang Zou, Xiaoqing Ye, Xiao Tan, and Xiang Bai. Pointmamba: A simple state space model for point cloud analysis.Advances in neural information processing systems, 37:32653–32677, 2024
work page 2024
-
[41]
Meta architecture for point cloud analysis
Haojia Lin, Xiawu Zheng, Lijiang Li, Fei Chao, Shanshan Wang, Yan Wang, Yonghong Tian, and Rongrong Ji. Meta architecture for point cloud analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17682–17691, 2023
work page 2023
-
[42]
Masked discrimination for self-supervised learning on point clouds
Haotian Liu, Mu Cai, and Yong Jae Lee. Masked discrimination for self-supervised learning on point clouds. InEuropean Conference on Computer Vision, pages 657–675. Springer, 2022
work page 2022
-
[43]
Jiuming Liu, Ruiji Yu, Yian Wang, Yu Zheng, Tianchen Deng, Weicai Ye, and Hesheng Wang. Point mamba: A novel point cloud backbone based on state space model with octree-based ordering strategy.arXiv preprint arXiv:2403.06467, 2024
-
[44]
Xinhai Liu, Zhizhong Han, Yu-Shen Liu, and Matthias Zwicker. Point2sequence: Learning the shape representation of 3d point clouds with an attention-based sequence to sequence network. InProceedings of the AAAI conference on artificial intelligence, pages 8778–8785, 2019
work page 2019
-
[45]
Relation-shape convolutional neural network for point cloud analysis
Yongcheng Liu, Bin Fan, Shiming Xiang, and Chunhong Pan. Relation-shape convolutional neural network for point cloud analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8895–8904, 2019
work page 2019
-
[46]
Multi-space alignments towards universal lidar segmentation
Youquan Liu, Lingdong Kong, Xiaoyang Wu, Runnan Chen, Xin Li, Liang Pan, Ziwei Liu, and Yuexin Ma. Multi-space alignments towards universal lidar segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
work page 2024
-
[47]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[48]
Transformers in 3d point clouds: A survey.arXiv preprint arXiv:2205.07417, 2022
Dening Lu, Qian Xie, Mingqiang Wei, Kyle Gao, Linlin Xu, and Jonathan Li. Transformers in 3d point clouds: A survey.arXiv preprint arXiv:2205.07417, 2022
-
[49]
Stable, fast and accurate: Kernelized attention with relative positional encoding
Shengjie Luo, Shanda Li, Tianle Cai, Di He, Dinglan Peng, Shuxin Zheng, Guolin Ke, Liwei Wang, and Tie-Yan Liu. Stable, fast and accurate: Kernelized attention with relative positional encoding. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 22795–...
work page 2021
-
[50]
arXiv preprint arXiv:2202.07123 , year=
Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, and Yun Fu. Rethinking network design and local geometry in point cloud: A simple residual mlp framework.arXiv preprint arXiv:2202.07123, 2022
-
[51]
Indoor segmentation and support inference from rgbd images
Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor segmentation and support inference from rgbd images. InECCV, 2012
work page 2012
-
[52]
Yatian Pang, Eng Hock Francis Tay, Li Yuan, and Zhenghua Chen. Masked autoencoders for 3d point cloud self-supervised learning.World Scientific Annual Review of Artificial Intelligence, 1:2440001, 2023
work page 2023
-
[53]
Oa-cnns: Omni-adaptive sparse cnns for 3d semantic segmentation
Bohao Peng, Xiaoyang Wu, Li Jiang, Yukang Chen, Hengshuang Zhao, Zhuotao Tian, and Jiaya Jia. Oa-cnns: Omni-adaptive sparse cnns for 3d semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
work page 2024
-
[54]
Pointcept: A codebase for point cloud perception research
Pointcept Contributors. Pointcept: A codebase for point cloud perception research. https: //github.com/Pointcept/Pointcept, 2023. 13
work page 2023
-
[55]
Train short, test long: Attention with linear biases enables input length extrapolation
Ofir Press, Noah Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InInternational Conference on Learning Representations, 2022
work page 2022
-
[56]
Qi, Hao Su, Kaichun Mo, and Leonidas J
Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660, 2017
work page 2017
-
[57]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
work page 2017
-
[58]
Guocheng Qian, Yuchen Li, Houwen Peng, Jinjie Mai, Hasan Hammoud, Mohamed Elhoseiny, and Bernard Ghanem. Pointnext: Revisiting pointnet++ with improved training and scaling strategies.Advances in neural information processing systems, 35:23192–23204, 2022
work page 2022
-
[59]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.J. Mach. Learn. Res., 21(1), January 2020
work page 2020
-
[60]
Turner, René Wagner, Adrian Weller, and Krzysztof Marcin Choromanski
Isaac Reid, Kumar Avinava Dubey, Deepali Jain, William F Whitney, Amr Ahmed, Joshua Ainslie, Alex Bewley, Mithun George Jacob, Aranyak Mehta, David Rendleman, Connor Schenck, Richard E. Turner, René Wagner, Adrian Weller, and Krzysztof Marcin Choromanski. Linear transformer topological masking with graph random features. InThe Thirteenth International Con...
work page 2025
-
[61]
Efficient 3d semantic segmentation with su- perpoint transformer
Damien Robert, Hugo Raguet, and Loic Landrieu. Efficient 3d semantic segmentation with su- perpoint transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[62]
Language-grounded indoor 3d semantic segmentation in the wild
David Rozenberszki, Or Litany, and Angela Dai. Language-grounded indoor 3d semantic segmentation in the wild. InEuropean conference on computer vision, pages 125–141. Springer, 2022
work page 2022
-
[63]
Connor Schenck, Isaac Reid, Mithun George Jacob, Alex Bewley, Joshua Ainslie, David Rendleman, Deepali Jain, Mohit Sharma, Kumar Avinava Dubey, Ayzaan Wahid, Sumeet Singh, René Wagner, Tianli Ding, Chuyuan Fu, Arunkumar Byravan, Jake Varley, Alexey A. Gritsenko, Matthias Minderer, Dmitry Kalashnikov, Jonathan Tompson, Vikas Sindhwani, and Krzysztof Marcin...
work page 2025
-
[64]
Efficient multi-task rgb-d scene analysis for indoor environments
Daniel Seichter, Söhnke Benedikt Fischedick, Mona Köhler, and Horst-Michael Groß. Efficient multi-task rgb-d scene analysis for indoor environments. In2022 International joint conference on neural networks (IJCNN), pages 1–10. IEEE, 2022
work page 2022
-
[65]
Efficient rgb-d semantic segmentation for indoor scene analysis
Daniel Seichter, Mona Köhler, Benjamin Lewandowski, Tim Wengefeld, and Horst-Michael Gross. Efficient rgb-d semantic segmentation for indoor scene analysis. In2021 IEEE international conference on robotics and automation (ICRA), pages 13525–13531. IEEE, 2021
work page 2021
-
[66]
Self-attention with relative position representations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. In Marilyn Walker, Heng Ji, and Amanda Stent, editors,Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464–468, New Orleans, Lo...
work page 2018
-
[67]
Sun rgb-d: A rgb-d scene under- standing benchmark suite
Shuran Song, Samuel P Lichtenberg, and Jianxiong Xiao. Sun rgb-d: A rgb-d scene under- standing benchmark suite. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 567–576, 2015
work page 2015
-
[68]
Roformer: Enhanced transformer with rotary position embedding.Neurocomput., 568(C), February 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomput., 568(C), February 2024. 14
work page 2024
-
[69]
Searching efficient 3d architectures with sparse point-voxel convolution
Haotian Tang, Zhijian Liu, Shengyu Zhao, Yujun Lin, Ji Lin, Hanrui Wang, and Song Han. Searching efficient 3d architectures with sparse point-voxel convolution. InEuropean confer- ence on computer vision, 2020
work page 2020
-
[70]
Tangent convolutions for dense prediction in 3d
Maxim Tatarchenko, Jaesik Park, Vladlen Koltun, and Qian-Yi Zhou. Tangent convolutions for dense prediction in 3d. InProceedings of the IEEE conference on computer vision and pattern recognition, 2018
work page 2018
-
[71]
Segcloud: Semantic segmentation of 3d point clouds
Lyne Tchapmi, Christopher Choy, Iro Armeni, Jun Young Gwak, and Silvio Savarese. Segcloud: Semantic segmentation of 3d point clouds. InProceedings of the International Conference on 3D Vision (3DV), 2017
work page 2017
-
[72]
Kpconv: Flexible and deformable convolution for point clouds
Hugues Thomas, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, François Goulette, and Leonidas J Guibas. Kpconv: Flexible and deformable convolution for point clouds. InProceedings of the IEEE/CVF international conference on computer vision, pages 6411–6420, 2019
work page 2019
-
[73]
Mikaela Angelina Uy, Quang-Hieu Pham, Binh-Son Hua, Thanh Nguyen, and Sai-Kit Yeung. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. InProceedings of the IEEE/CVF international conference on computer vision, pages 1588–1597, 2019
work page 2019
-
[74]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA, 2017. Curran Associates Inc
work page 2017
-
[75]
Graph attention convo- lution for point cloud semantic segmentation
Lei Wang, Yuchun Huang, Yaolin Hou, Shenman Zhang, and Jie Shan. Graph attention convo- lution for point cloud semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019
work page 2019
-
[76]
Peng-Shuai Wang. Octformer: Octree-based transformers for 3d point clouds.ACM Transac- tions on Graphics (TOG), 42(4):1–11, 2023
work page 2023
-
[77]
Deep parametric continuous convolutional neural networks
Shenlong Wang, Simon Suo, Wei-Chiu Ma, Andrei Pokrovsky, and Raquel Urtasun. Deep parametric continuous convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition, 2018
work page 2018
-
[78]
Multimodal token fusion for vision transformers
Yikai Wang, Xinghao Chen, Lele Cao, Wenbing Huang, Fuchun Sun, and Yunhe Wang. Multimodal token fusion for vision transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12186–12195, 2022
work page 2022
-
[79]
Yikai Wang, Wenbing Huang, Fuchun Sun, Tingyang Xu, Yu Rong, and Junzhou Huang. Deep multimodal fusion by channel exchanging.Advances in neural information processing systems, 33:4835–4845, 2020
work page 2020
-
[80]
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E. Sarma, Michael M. Bronstein, and Justin M. Solomon. Dynamic graph cnn for learning on point clouds. InACM Transactions on Graphics (SIGGRAPH Asia) 38(5), pages 146:1–146:12, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.