Recognition: no theorem link
MATRA: Modeling the Attack Surface of Agentic AI Systems -- OpenClaw Case Study
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
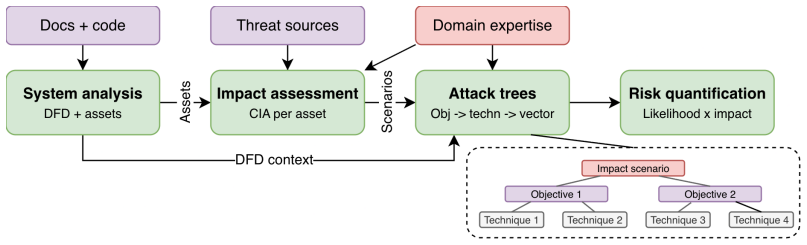
MATRA is a threat modeling framework that uses asset assessment and attack trees to quantify how controls like sandboxing reduce risks from LLM threats in agentic AI systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MATRA begins with an asset-based impact assessment and utilizes attack trees to determine the likelihood of impacts occurring within the system architecture, as demonstrated in a personal AI agent deployment using OpenClaw where architectural controls reduce risk by limiting the blast radius of successful injections.
What carries the argument
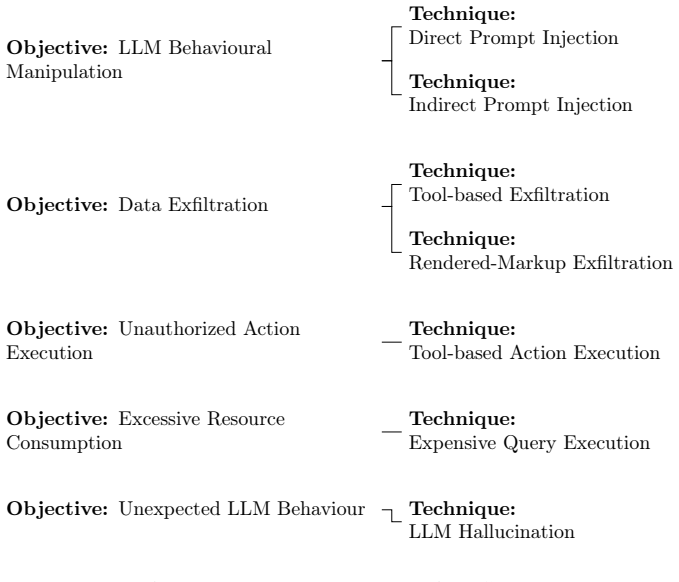
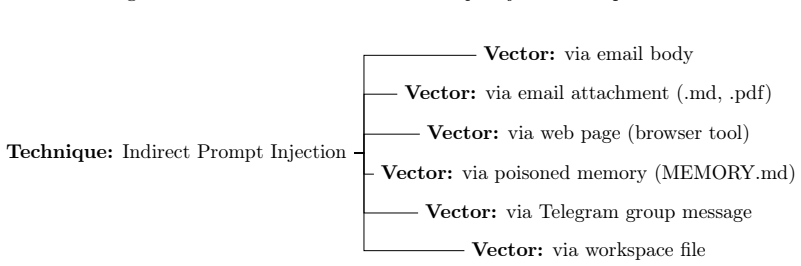
Attack trees that map LLM threat classes to deployment-specific impacts and evaluate the mitigating effects of architectural controls.
If this is right
- Practitioners can systematically identify which assets in an agentic AI system are most vulnerable to known LLM threats.
- Network sandboxing and least-privilege access demonstrably limit the blast radius of injection attacks.
- The framework allows quantification of risk reduction from specific controls in concrete deployments.
- Agentic AI systems can be designed with security in mind from the start using this modeling approach.
Where Pith is reading between the lines
- The MATRA approach could be applied to other agent frameworks to compare their security profiles.
- It highlights the importance of architectural choices over solely relying on LLM alignment techniques.
- Future work might integrate MATRA with automated tools for dynamic risk assessment in evolving agent systems.
- Adoption could lead to industry standards for securing personal AI assistants.
Load-bearing premise
That known LLM threat classes can be directly translated into concrete, quantifiable risks for a given agentic architecture using attack trees without missing important interactions or overestimating control effectiveness.
What would settle it
Observing a successful attack in an OpenClaw-like deployment that the attack tree model predicted as low likelihood, or finding a threat interaction not captured by the modeled attack trees.
Figures










read the original abstract
LLMs are increasingly deployed as autonomous agents with access to tools, databases, and external services, yet practitioners (across different sectors) lack systematic methods to assess how known threat classes translate into concrete risks within a specific agentic deployment. We present MATRA, a pragmatic threat modeling framework for agentic AI systems that adapts established risk assessment methodology to systematically assess how known LLM threats translate into deployment-specific risks. MATRA begins with an asset-based impact assessment and utilizes attack trees to determine the likelihood of these impacts occurring within the system architecture. We demonstrate MATRA on a personal AI agent deployment using OpenClaw, quantifying how architectural controls such as network sandboxing and least-privilege access reduce risk by limiting the blast radius of successful injections.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MATRA, a pragmatic threat modeling framework for agentic AI systems. It adapts established risk assessment methods by beginning with an asset-based impact assessment and then constructing attack trees to quantify the likelihood of impacts arising from known LLM threat classes (such as prompt injection) within a concrete system architecture. The framework is demonstrated via a case study on the OpenClaw personal AI agent deployment, with the central claim that architectural controls including network sandboxing and least-privilege access reduce overall risk by limiting the blast radius of successful attacks.
Significance. If the attack-tree likelihood assignments and risk calculations prove accurate and exhaustive, MATRA would supply practitioners with a systematic, architecture-specific method for translating general LLM threats into quantifiable deployment risks and for evaluating the effectiveness of controls. This could aid prioritization of security measures in agentic systems where tool access and autonomy amplify potential impacts.
major comments (3)
- [Case study] Case study section: The manuscript claims to quantify risk reductions from controls such as network sandboxing and least-privilege access, yet provides no attack tree structures, leaf-node likelihood values, or before/after risk metrics for the OpenClaw deployment. Without these concrete elements, the reported risk reductions cannot be verified or reproduced.
- [Framework] Framework description: Attack trees are applied to translate LLM threats into deployment risks, but the presentation does not address how stateful memory, iterative tool-calling loops, or adaptive multi-step behaviors in agentic systems could create unmodeled attack paths that standard static attack trees routinely omit; this directly affects the completeness of the likelihood estimates.
- [Case study] Validation of likelihoods: The assigned probabilities for leaf nodes appear to rest on qualitative expert judgment with no empirical calibration, red-team validation, or comparison to observed incidents reported; given the skeptic's concern about emergent interactions, this is load-bearing for the claim that controls reduce risk by a quantifiable factor.
minor comments (2)
- [Abstract] The abstract would benefit from stating the specific numerical risk reduction achieved in the OpenClaw example rather than describing the outcome only qualitatively.
- Consider adding a summary table of attack tree nodes, probabilities, and computed risks to improve clarity and allow readers to follow the quantification.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript introducing the MATRA framework. We have carefully considered each point and provide detailed responses below, along with plans for revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Case study] Case study section: The manuscript claims to quantify risk reductions from controls such as network sandboxing and least-privilege access, yet provides no attack tree structures, leaf-node likelihood values, or before/after risk metrics for the OpenClaw deployment. Without these concrete elements, the reported risk reductions cannot be verified or reproduced.
Authors: We agree that the current manuscript presents the risk quantification at a summary level without the detailed attack tree structures, specific leaf-node likelihood values, or explicit before-and-after metrics. This limits verifiability. In the revised version, we will include these concrete elements: we will add figures showing the attack tree structures for the primary threats in the OpenClaw deployment, tables with the assigned likelihood values for leaf nodes, and calculated risk scores before and after applying controls such as network sandboxing and least-privilege access. This will enable verification and reproduction of the reported risk reductions. revision: yes
-
Referee: [Framework] Framework description: Attack trees are applied to translate LLM threats into deployment risks, but the presentation does not address how stateful memory, iterative tool-calling loops, or adaptive multi-step behaviors in agentic systems could create unmodeled attack paths that standard static attack trees routinely omit; this directly affects the completeness of the likelihood estimates.
Authors: This is a valid observation regarding the limitations of static attack trees when applied to agentic systems. The framework as presented focuses on translating known LLM threat classes into architecture-specific risks using standard attack tree methods. To address this, we will revise the framework description to explicitly discuss potential unmodeled attack paths arising from stateful memory, iterative tool-calling, and adaptive behaviors. We will also propose extensions to MATRA, such as incorporating dynamic attack tree variants or multi-stage scenario analysis, to better capture these aspects and improve the robustness of likelihood estimates. revision: partial
-
Referee: [Case study] Validation of likelihoods: The assigned probabilities for leaf nodes appear to rest on qualitative expert judgment with no empirical calibration, red-team validation, or comparison to observed incidents reported; given the skeptic's concern about emergent interactions, this is load-bearing for the claim that controls reduce risk by a quantifiable factor.
Authors: We acknowledge that the leaf-node probabilities in the OpenClaw case study are derived from qualitative expert judgment rather than empirical data or red-team experiments, which is a common starting point in threat modeling for emerging technologies like agentic AI where comprehensive incident data is still developing. To mitigate concerns about this being load-bearing, we will update the manuscript to provide more transparency on how these judgments were formed, including cross-references to existing LLM threat literature and reported incidents. Additionally, we will include a sensitivity analysis showing the impact of varying these probabilities on the overall risk reduction and add a section on future work for empirical calibration and red-teaming validation. revision: yes
Circularity Check
MATRA applies standard attack-tree methodology to agentic systems with no self-referential derivations or fitted predictions
full rationale
The paper presents MATRA as an adaptation of established risk assessment techniques (asset-based impact assessment plus attack trees) to translate known LLM threats into deployment-specific risks for the OpenClaw case study. No equations, parameters fitted to data subsets, or derivations appear in the provided text. Likelihood assignments to attack-tree leaves are described as arising from qualitative reasoning on known threat classes rather than from any self-citation chain, uniqueness theorem, or renaming of prior results. The central claim—that controls such as network sandboxing reduce risk by limiting blast radius—is framed as an application of the framework, not a result forced by construction from the paper's own inputs. Per the hard rules, absence of any quotable reduction (e.g., Eq. X defined in terms of Y or a prediction that is the fit itself) yields score 0. The skeptic concern about unvalidated expert judgments is a correctness/empirical-validation issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Known LLM threats translate into deployment-specific risks that can be systematically modeled with asset-based impact assessment and attack trees.
Reference graph
Works this paper leans on
-
[1]
Agents rule of two: A practical ap- proach to AI agent security
Meta AI, “Agents rule of two: A practical ap- proach to AI agent security.” Meta AI Blog, Oct
-
[2]
Accessed: 2026-03-16
work page 2026
-
[3]
Fine-tuned DeBERTa-v3-base for prompt injection detection
ProtectAI.com, “Fine-tuned DeBERTa-v3-base for prompt injection detection.” Hugging Face Model Hub, 2024
work page 2024
-
[4]
Google, “Model armor overview.” Google Cloud Documentation, 2025
work page 2025
-
[5]
LlamaFirewall: An open source guardrail sys- tem for building secure AI agents
S. Chennabasappa, C. Nikolaidis, D. Song, D. Molnar, S. Ding, S. Wan, S. Whitman, L. Deason, N. Doucette, A. Montilla, A. Gampa, B.dePaola, D.Gabi, J.Crnkovich, J.-C.Testud, K. He, R. Chaturvedi, W. Zhou, and J. Saxe, “LlamaFirewall: An open source guardrail sys- tem for building secure AI agents.” arXiv preprint, May 2025
work page 2025
-
[6]
Tree of attacks: Jailbreaking black- box LLMs automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. S. Anderson, Y. Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black- box LLMs automatically,” inThe Thirty-eighth Annual Conference on Neural Information Pro- cessing Systems, 2024. 2https://www.dagstuhl.de/25461
work page 2024
-
[7]
garak: A framework for security probing large language models,
L. Derczynski, E. Galinkin, J. Martin, S. Ma- jumdar, and N. Inie, “garak: A framework for security probing large language models,” 2024
work page 2024
-
[8]
Universal and transferable adversarial at- tacks on aligned language models,
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrik- son, “Universal and transferable adversarial at- tacks on aligned language models,” 2023
work page 2023
-
[9]
Agentdojo: A dynamic environment to evalu- ate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tramèr, “Agentdojo: A dynamic environment to evalu- ate prompt injection attacks and defenses for LLM agents,” inThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
work page 2024
-
[10]
Jail- breakbench: An open robustness benchmark for jailbreaking large language models,
P. Chao, E. Debenedetti, A. Robey, M. An- driushchenko, F. Croce, V. Sehwag, E. Do- briban, N. Flammarion, G. J. Pappas, F. Tramèr, H. Hassani, and E. Wong, “Jail- breakbench: An open robustness benchmark for jailbreaking large language models,” inNeurIPS Datasets and Benchmarks Track, 2024
work page 2024
-
[11]
Inside CVE-2025-32711 (Ec- hoLeak): Prompt injection meets AI exfiltra- tion
Hack The Box, “Inside CVE-2025-32711 (Ec- hoLeak): Prompt injection meets AI exfiltra- tion.” HackTheBoxBlog, 2025. Accessed: 2026- 03-16
work page 2025
-
[12]
The summer of johann: Prompt in- jections as far as the eye can see
S. Willison, “The summer of johann: Prompt in- jections as far as the eye can see.” Simon Willi- son’s Weblog, Aug. 2025. Part of the series Prompt Injection. Accessed: 2026-03-16
work page 2025
-
[13]
M. Nasr, N. Carlini, C. Sitawarin, S. V. Schul- hoff, J. Hayes, M. Ilie, J. Pluto, S. Song, H. Chaudhari, I. Shumailov, A. Thakurta, K. Y. Xiao, A. Terzis, and F. Tramèr, “The At- tacker Moves Second: Stronger Adaptive At- tacks Bypass Defenses Against LLM Jailbreaks and Prompt Injections.”https://arxiv.org/ abs/2510.09023, 2025
-
[14]
K. Greshake, S. Abdelnabi, S. Mishra, C. En- dres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm- integrated applications with indirect prompt injection,” inProceedings of the 16th ACM 7 Workshop on Artificial Intelligence and Security, AISec ’23, (New York, NY, USA), p. 79–90, As- sociation for Computing Machinery, 2023
work page 2023
-
[15]
Can llms separate instruc- tions from data? and what do we even mean by that?,
E. Zverev, S. Abdelnabi, S. Tabesh, M. Fritz, and C. H. Lampert, “Can llms separate instruc- tions from data? and what do we even mean by that?,” inThirteenth International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[16]
Prompt injection attack to tool se- lection in LLM agents,
J. Shi, Z. Yuan, G. Tie, P. Zhou, N. Z. Gong, and L. Sun, “Prompt injection attack to tool se- lection in LLM agents,” inNDSS, 2026
work page 2026
-
[17]
ObliIn- jection: Order-Oblivious Prompt Injection At- tack to LLM Agents with Multi-source Data,
R. Wang, Y. Jia, and N. Z. Gong, “ObliIn- jection: Order-Oblivious Prompt Injection At- tack to LLM Agents with Multi-source Data,” inNDSS, 2026
work page 2026
-
[18]
N. V. Pandya, A. Labunets, S. Gao, and E. Fer- nandes, “May I have your attention? breaking fine-tuning based prompt injection defenses us- ing architecture-aware attacks,”arXiv preprint arXiv:2507.07417, 2025
-
[19]
Getmydrift? catching llm task drift with activation deltas,
S. Abdelnabi, A. Fay, G. Cherubin, A. Salem, M.Fritz, andA.Paverd, “Getmydrift? catching llm task drift with activation deltas,” inIEEE Conference on Secure and Trustworthy Machine Learning (SaTML), 2025
work page 2025
-
[20]
New hack uses prompt injection to corrupt Gemini’s long-term memory
D. Goodin, “New hack uses prompt injection to corrupt Gemini’s long-term memory.” Ars Tech- nica, Feb. 2025. Accessed: 2026-03-16
work page 2025
-
[21]
OWASP Top 10 for Large Language Model Applications,
OWASP Foundation, “OWASP Top 10 for Large Language Model Applications,” 2025. A community-driven standard awareness doc- ument identifying the top 10 most critical se- curity risks to Large Language Model (LLM) applications, including prompt injection, sensi- tive information disclosure, supply chain vulner- abilities, data poisoning, improper output han-...
work page 2025
-
[22]
Agentic AI – Threats and Mitigations,
OWASP Agentic Security Initiative, “Agentic AI – Threats and Mitigations,” security guide, OWASP Foundation, February 2025. First guide from the OWASP Agentic Security Initia- tive providing a threat-model-based reference of emerging agentic threats and mitigations. Cov- ers autonomous AI systems enabled by large lan- guage models, with structured threat ...
work page 2025
-
[23]
Artificial intelligence risk management frame- work: Generative artificial intelligence profile,
National Institute of Standards and Technology, “Artificial intelligence risk management frame- work: Generative artificial intelligence profile,” Tech. Rep. NIST AI 600-1, National Institute of Standards and Technology, July 2024
work page 2024
-
[24]
Guide for conducting risk assessments,
NIST, “Guide for conducting risk assessments,” Tech. Rep. SP 800-30 Rev. 1, National Institute of Standards and Technology, 2012
work page 2012
-
[25]
OpenClaw: Your own personal AI assistant. any OS. any platform
P. Steinberger and OpenClaw Contributors, “OpenClaw: Your own personal AI assistant. any OS. any platform..”https://github.com /openclaw/openclaw, 2025. Accessed: 2026-03- 16
work page 2025
- [26]
-
[27]
OWASP top 10 for agentic applications for 2026
OWASP GenAI Security Project, “OWASP top 10 for agentic applications for 2026.” OWASP Foundation,https://genai.owasp.org/reso urce/owasp-top-10-for-agentic-applicati ons-for-2026/, Dec. 2025. Developed through collaboration with more than 100 industry ex- perts. Accessed: 2026-03-16
work page 2026
-
[28]
MITRE ATLAS™: Adversarial threat landscape for artificial- intelligence systems
MITRE Corporation, “MITRE ATLAS™: Adversarial threat landscape for artificial- intelligence systems.” MITRE Corporation,
-
[29]
Living knowledge base; accessed: 2026- 03-16. 8
work page 2026
-
[30]
Introductory guidance to AICM: The AI controls matrix
Cloud Security Alliance, “Introductory guidance to AICM: The AI controls matrix.” Cloud Secu- rity Alliance, Nov. 2025. Accessed: 2026-03-16
work page 2025
-
[31]
Cisco AI defense: Integrated AI security and safety framework
Cisco, “Cisco AI defense: Integrated AI security and safety framework.” Cisco Systems, Inc.,ht tps://www.cisco.com/site/us/en/learn/t opics/artificial-intelligence/ai-secur ity-safety-framework.html, 2025. Accessed: 2026-03-16
work page 2025
-
[32]
Why OpenClaw poses new AI-era se- curity risks
A. Zhao, “Why OpenClaw poses new AI-era se- curity risks.”https://aaronzhao123.substac k.com/p/why-openclaw-poses-new-ai-era-s ecurity, 2025. Substack
work page 2025
-
[33]
Defeating Prompt Injections by Design
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tramèr, “Defeating prompt injections by design.”https://arxiv.org/abs/2503.18813, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
Se- curing ai agents with information-flow control,
M. Costa, B. Köpf, A. Kolluri, A. Paverd, M. Russinovich, A. Salem, S. Tople, L. Wutschitz, and S. Zanella-Béguelin, “Se- curing ai agents with information-flow control,” 2025
work page 2025
-
[35]
Robust and reusable linddun pri- vacy threat knowledge,
L. Sion, D. Van Landuyt, K. Wuyts, and W. Joosen, “Robust and reusable linddun pri- vacy threat knowledge,”Computers & Security, vol. 154, p. 104419, 2025. A Risk Quantification Matrices Table 1: Capability fit lookup: adversary capability (rows) versus vector skill requirement (columns). Capability Skill Req. Low Mod High High High High High Mod High Hig...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.