Recognition: no theorem link
MMTB: Evaluating Terminal Agents on Multimedia-File Tasks
Pith reviewed 2026-05-13 00:59 UTC · model grok-4.3
The pith
MMTB and Terminus-MM enable studies showing how multimedia access shapes terminal agents' task outcomes and workflow evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMTB provides 105 tasks across five meta-categories for terminal agents operating on audio and video files, while Terminus-MM extends prior harnesses with audio and video perception capabilities. Used together, they support controlled experiments that reveal how varying multimedia access methods influence task success rates and determine which auditory or visual evidence agents rely on when constructing executable terminal workflows.
What carries the argument
MMTB benchmark of 105 multimedia-file tasks and Terminus-MM perception harness, which supply structured tasks plus audio-video perception tools so agents can convert file content into terminal actions.
If this is right
- Task success rates differ according to the specific form of multimedia access granted to the agent.
- Agents draw on distinct auditory versus visual evidence when building executable terminal workflows.
- The five meta-categories isolate separate aspects of multimedia handling that affect overall performance.
- Controlled comparisons become possible between agents with and without direct multimedia perception.
Where Pith is reading between the lines
- Designers could use MMTB results to prioritize which perception features to add first when extending agents to new file types.
- The public release of media and metadata allows independent teams to add tasks or test new agent architectures against the same baseline.
- Insights on evidence reliance might transfer to improving agents that combine terminal commands with other non-text inputs such as sensor data.
Load-bearing premise
Terminal agents supplied with the multimedia perception tools can turn auditory and visual file evidence into correct terminal commands without needing extra human guidance or outside context.
What would settle it
Run the 105 MMTB tasks with agents given full audio-video access via Terminus-MM and observe whether success rates remain near zero or show no difference from agents denied such access.
Figures




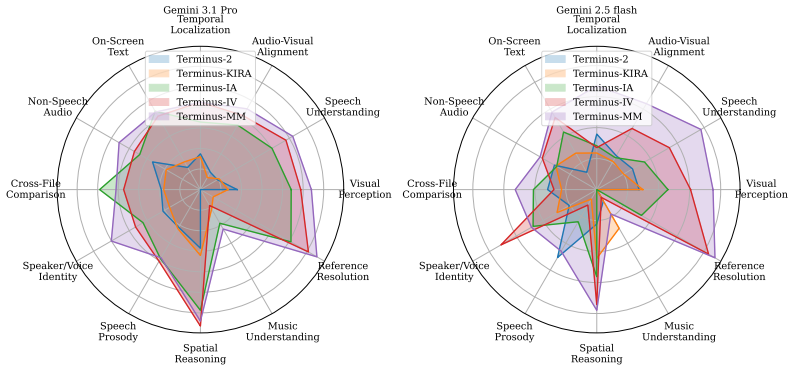

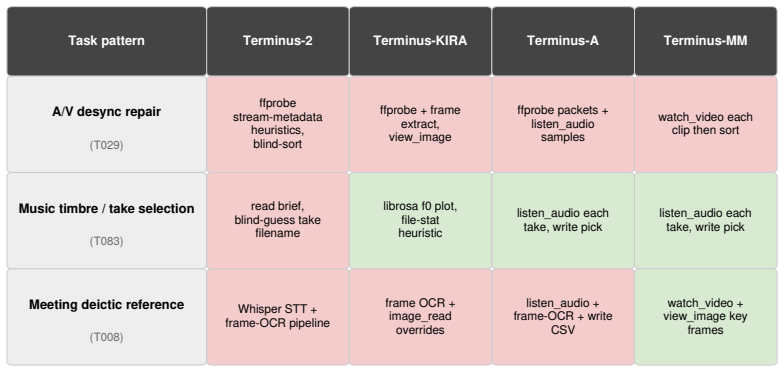
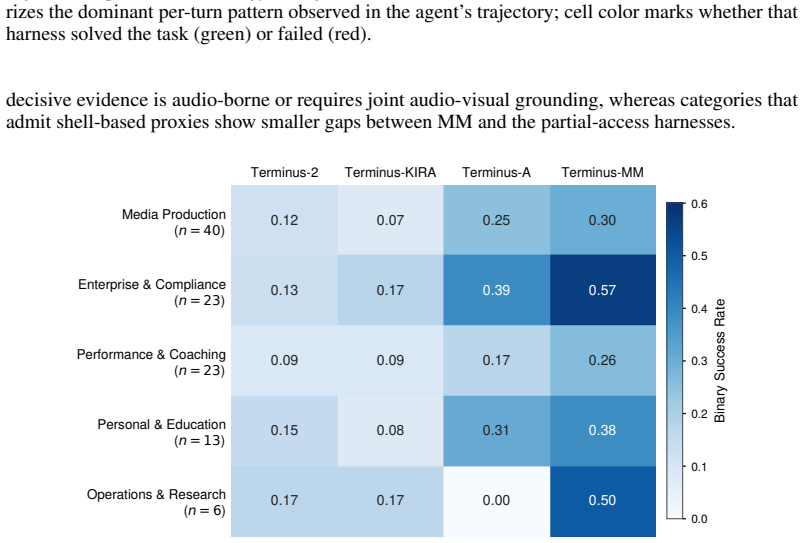
read the original abstract
Terminals provide a powerful interface for AI agents by exposing diverse tools for automating complex workflows, yet existing terminal-agent benchmarks largely focus on tasks grounded in text, code, and structured files. However, many real-world workflows require practitioners to work directly with audio and video files. Working with such multimedia files calls for terminal agents not only to understand multimedia content, but also to convert auditory and visual evidence across related files into appropriate actions. To evaluate terminal agents on multimedia-file tasks, we introduce MultiMedia-TerminalBench (MMTB), a benchmark of 105 tasks across 5 meta-categories where terminal agents directly operate with audio and video files. Alongside MMTB, we propose Terminus-MM, a multimedia harness that extends Terminus-KIRA with audio and video perception for terminal agents. Together, MMTB and Terminus-MM support a controlled study of multimedia terminal agents, revealing how different forms of multimedia access shape task outcomes and determine which evidence agents rely on to construct executable terminal workflows. MMTB media and metadata are released at https://huggingface.co/datasets/mm-tbench/mmtb-media
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiMedia-TerminalBench (MMTB), a benchmark of 105 tasks across 5 meta-categories for evaluating terminal AI agents on workflows involving audio and video files. It also proposes Terminus-MM, an extension of the Terminus-KIRA harness that adds audio and video perception tools. The central contribution is the benchmark and data release to enable controlled studies of how multimedia access modes affect agent outcomes and the evidence agents use to build executable terminal commands. Media and metadata are released on Hugging Face.
Significance. If the tasks prove diverse, well-validated, and the harness enables reliable isolation of multimedia perception effects, the work could be significant for advancing terminal-agent research beyond text/code domains. The public data release supports reproducibility and community follow-up studies on real-world multimedia workflows.
major comments (2)
- [Abstract and §1] Abstract and Introduction: the claim that MMTB and Terminus-MM 'reveal how different forms of multimedia access shape task outcomes and determine which evidence agents rely on' is not supported by any agent evaluations, baseline results, success metrics, or error analysis. The manuscript describes benchmark construction and tool extension but provides no empirical data or controlled-study findings.
- [§3] Benchmark description (likely §3): no details are supplied on task creation, validation procedures, inter-annotator agreement, definition of the 5 meta-categories, or concrete success criteria for converting auditory/visual evidence into terminal actions. Without these, it is impossible to assess whether the 105 tasks support the claimed insights.
minor comments (2)
- [§2] A diagram or pseudocode example illustrating how Terminus-MM integrates audio/video perception into the terminal workflow would improve clarity of the harness extension.
- [Related Work] Ensure the related-work section cites recent multimodal agent benchmarks and terminal-agent papers to properly situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting areas where the manuscript can be strengthened. We agree that the current draft would benefit from more precise language about the scope of our contributions and expanded details on benchmark construction. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and Introduction: the claim that MMTB and Terminus-MM 'reveal how different forms of multimedia access shape task outcomes and determine which evidence agents rely on' is not supported by any agent evaluations, baseline results, success metrics, or error analysis. The manuscript describes benchmark construction and tool extension but provides no empirical data or controlled-study findings.
Authors: We acknowledge that the manuscript is a benchmark and harness introduction paper and does not include agent evaluations, baselines, or empirical findings. The abstract and introduction phrasing was intended to describe the design purpose of MMTB and Terminus-MM (i.e., to enable controlled studies of multimedia access effects). We agree the current wording risks overstating the contribution. In revision we will change the language to state that the resources 'support' or 'enable' such studies rather than claiming they 'reveal' specific outcomes or evidence-use patterns. This revision will be made in both the abstract and §1. revision: yes
-
Referee: [§3] Benchmark description (likely §3): no details are supplied on task creation, validation procedures, inter-annotator agreement, definition of the 5 meta-categories, or concrete success criteria for converting auditory/visual evidence into terminal actions. Without these, it is impossible to assess whether the 105 tasks support the claimed insights.
Authors: We agree that the current §3 lacks sufficient methodological detail. In the revised manuscript we will expand this section to include: (i) the task creation process (real-world workflow sourcing, expert curation, and iterative refinement); (ii) validation procedures used; (iii) inter-annotator agreement statistics where multiple annotators participated; (iv) explicit definitions and representative examples for each of the five meta-categories; and (v) concrete, measurable success criteria that specify how auditory/visual evidence must be translated into correct terminal commands. These additions will allow readers to evaluate the benchmark's validity and the soundness of the claimed insights. revision: yes
Circularity Check
No significant circularity; empirical benchmark with no derivations
full rationale
The paper introduces MMTB (105 tasks across 5 meta-categories) and Terminus-MM harness as an empirical benchmark and tool extension for evaluating terminal agents on multimedia files. No equations, fitted parameters, predictions, or derivations appear in the abstract or described content. The central claim—that MMTB and Terminus-MM enable controlled studies of multimedia access modes—is supported directly by the benchmark's construction and data release, without reducing to self-citation chains or self-definitional loops. This is a standard data-contribution paper; the setup is falsifiable by running agents on the released media. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. Claude code. https://code.claude.com/docs/en/overview, 2026. Accessed: 2026-05-06. 2, 5
work page 2026
-
[2]
Anthropic. Claude Sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6 ,
-
[3]
Accessed: 2026-05-06. 5
work page 2026
-
[4]
Expertaf: Expert actionable feedback from video
Kumar Ashutosh, Tushar Nagarajan, Georgios Pavlakos, Kris Kitani, and Kristen Grauman. Expertaf: Expert actionable feedback from video. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13582–13594, 2025. 2
work page 2025
-
[5]
Fuqing Bie, Shiyu Huang, Xijia Tao, Zhiqin Fang, Leyi Pan, Junzhe Chen, Min Ren, Liuyu Xiang, and Zhaofeng He. Omniplay: Benchmarking omni-modal models on omni-modal game playing.arXiv preprint arXiv:2508.04361, 2025. 2, 9
-
[6]
Mle-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M ˛ adry. Mle-bench: Evaluating machine learning agents on machine learning engineering. In International Conference on Learning Representations (ICLR), 2025. 9
work page 2025
-
[7]
Jianghan Chao, Jianzhang Gao, Wenhui Tan, Yuchong Sun, Ruihua Song, and Liyun Ru. Jointavbench: A benchmark for joint audio-visual reasoning evaluation.arXiv preprint arXiv:2512.12772, 2025. 2, 9
work page internal anchor Pith review arXiv 2025
-
[8]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Video-holmes: Can MLLM think like holmes for complex video reasoning?CoRR, abs/2505.21374, 2025
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-holmes: Can mllm think like holmes for complex video reasoning?arXiv preprint arXiv:2505.21374,
-
[10]
Avtrustbench: Assessing and enhancing reliability and robustness in audio-visual llms
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Yaoting Wang, Mohamed Elhoseiny, Ruohan Gao, and Dinesh Manocha. Avtrustbench: Assessing and enhancing reliability and robustness in audio-visual llms. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1590–1601, October 2025. 2, 9
work page 2025
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Audio set: An ontology and human-labeled dataset for audio events
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 776–780. IEEE, 2017. 2
work page 2017
-
[14]
Google DeepMind. Gemini 3.1 Pro — Model Card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/, 2026. Accessed: 2026-05-06. 5
work page 2026
-
[15]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 9
work page 2017
-
[16]
Meetingbank: A benchmark dataset for meeting summarization
Yebowen Hu, Timothy Ganter, Hanieh Deilamsalehy, Franck Dernoncourt, Hassan Foroosh, and Fei Liu. Meetingbank: A benchmark dataset for meeting summarization. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 16409–16423, 2023. 2 10
work page 2023
-
[17]
Lawrence Jang, Yinheng Li, Dan Zhao, Charles Ding, Justin Lin, Paul Pu Liang, Rogerio Bonatti, and Kazuhito Koishida. Videowebarena: Evaluating long context multimodal agents with video understanding web tasks.arXiv preprint arXiv:2410.19100, 2024. 2, 9
-
[18]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations (ICLR), 2024. 9
work page 2024
-
[19]
arXiv preprint arXiv:2401.13649 , year=
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks.arXiv preprint arXiv:2401.13649,
-
[20]
Terminus-kira: Boosting frontier model performance on terminal-bench with minimal harness
KRAFTON AI and Ludo Robotics. Terminus-kira: Boosting frontier model performance on terminal-bench with minimal harness. https://github.com/krafton-ai/KIRA, 2026. 2, 4, 6
work page 2026
-
[21]
Omnibench: Towards the future of universal omni-language models, 2025
Yizhi Li, Yinghao Ma, Ge Zhang, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Zekun Wang, Jian Yang, et al. Omnibench: Towards the future of universal omni-language models.arXiv preprint arXiv:2409.15272, 2024. 2
-
[22]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026. 2, 4, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [23]
-
[24]
Update to GPT-5 system card: GPT-5.2
OpenAI. Update to GPT-5 system card: GPT-5.2. https://openai.com/index/ gpt-5-system-card-update-gpt-5-2/, 2026. Accessed: 2026-05-06. 5
work page 2026
-
[25]
Mmsum: A dataset for multimodal summa- rization and thumbnail generation of videos
Jielin Qiu, Jiacheng Zhu, William Han, Aditesh Kumar, Karthik Mittal, Claire Jin, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Ding Zhao, et al. Mmsum: A dataset for multimodal summa- rization and thumbnail generation of videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21909–21921, 2024. 2
work page 2024
-
[26]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5. 5
work page 2026
-
[27]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2024. 9
work page 2024
-
[28]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972,
work page internal anchor Pith review arXiv
-
[29]
InterCode: Standard- izing and benchmarking interactive coding with execution feedback
John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao. InterCode: Standard- izing and benchmarking interactive coding with execution feedback. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023. 2
work page 2023
-
[30]
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
work page internal anchor Pith review arXiv 2024
-
[31]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2024. 9 11 A Implementation Details A.1 Harness Implementation Details This appendix supports Sec...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.