Recognition: 2 theorem links
· Lean TheoremACSAC: Adaptive Chunk Size Actor-Critic with Causal Transformer Q-Network
Pith reviewed 2026-05-13 00:44 UTC · model grok-4.3
The pith
A causal Transformer critic selects variable action chunk sizes on the fly to improve long-horizon sparse-reward reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ACSAC uses a causal Transformer critic to evaluate expected returns across multiple chunk sizes at each boundary and selects the size that maximizes the estimated return; the ACSAC Bellman operator is a contraction whose unique fixed point is the action-value function of the induced adaptive policy.
What carries the argument
The causal Transformer Q-network that evaluates returns for candidate chunk sizes and drives argmax selection of the adaptive length.
If this is right
- Chunk length becomes state-dependent rather than a fixed hyperparameter, removing the need for task-specific tuning.
- Bootstrapping error accumulation is reduced because value backups occur over longer, temporally consistent segments chosen by the critic.
- The contraction property guarantees that repeated application of the operator converges to the value function of the adaptive policy.
- The same architecture supports both pure offline learning and the offline-to-online regime without additional modifications.
Where Pith is reading between the lines
- The same multi-size evaluation idea could be applied to other temporal abstractions such as options or skill libraries.
- By removing chunk-size search, the method lowers the practical barrier to deploying RL on new long-horizon problems.
- Attention mechanisms inside the critic might be replaceable by lighter recurrent or state-space models while preserving the adaptive selection property.
Load-bearing premise
The causal Transformer critic produces accurate and stable return estimates for different chunk sizes so that selecting the highest-value size yields a coherent adaptive policy.
What would settle it
If training the adaptive policy produces lower actual returns than the best fixed chunk size on the same tasks, or if the Q-network estimates diverge from observed returns across chunk lengths, the contraction and performance claims would not hold.
Figures





read the original abstract
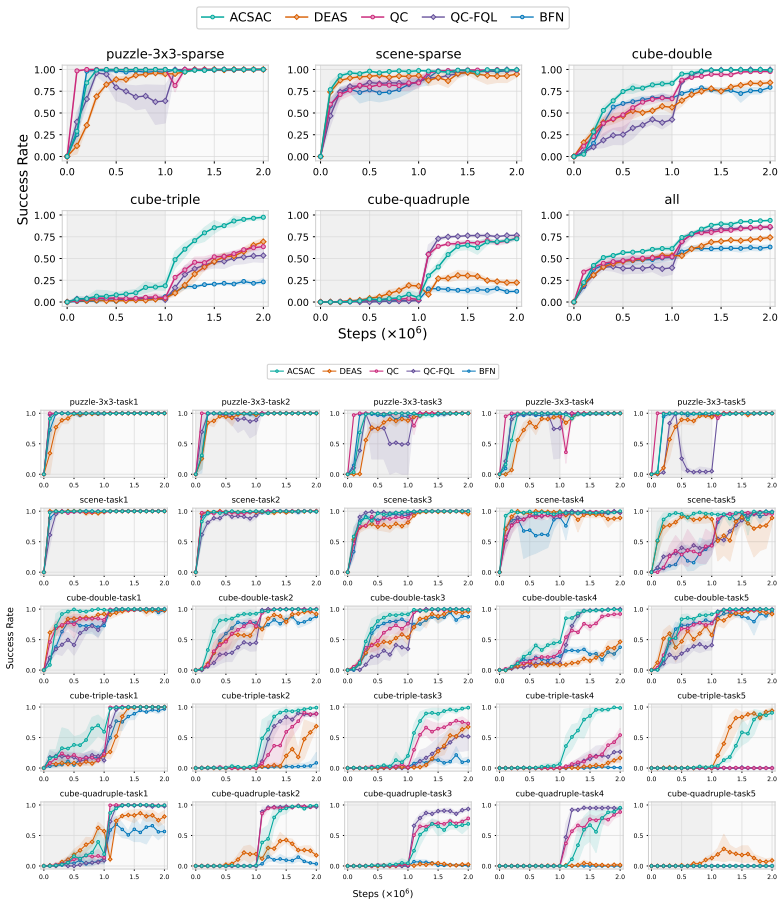
Long-horizon, sparse-reward tasks pose a fundamental challenge for reinforcement learning, since single-step TD learning suffers from bootstrapping error accumulation across successive Bellman updates. Actor-critic methods with action chunking address this by operating over temporally extended actions, which reduce the effective horizon, enable fast value backups, and support temporally consistent exploration. However, existing methods rely on a fixed chunk size and therefore cannot adaptively balance reactivity against temporal consistency. A large fixed chunk size reduces responsiveness to new observations, while a small one produces incoherent motions, forcing task-specific tuning of the chunk size. To address this limitation, we propose Adaptive Chunk Size Actor-Critic (ACSAC). ACSAC leverages a causal Transformer critic to evaluate expected returns for action chunks of different sizes. At each chunk boundary, it adaptively selects the chunk size that maximizes the expected return, supporting flexible, state-dependent chunk sizes without task-specific tuning. We prove that the ACSAC Bellman operator is a contraction whose unique fixed point is the action-value function of the adaptive policy. Experiments on OGBench demonstrate that ACSAC achieves state-of-the-art performance on long-horizon, sparse-reward manipulation tasks across both offline RL and offline-to-online RL settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Chunk Size Actor-Critic (ACSAC), an actor-critic algorithm that employs a causal Transformer Q-network to evaluate expected returns for action chunks of multiple sizes. At each chunk boundary the method selects the size k that maximizes the critic's estimate, yielding a state-dependent adaptive policy. The central theoretical claim is that the ACSAC Bellman operator is a contraction whose unique fixed point is exactly the action-value function of this adaptive policy. Experiments on OGBench report state-of-the-art results for long-horizon, sparse-reward manipulation tasks in both offline RL and offline-to-online RL regimes.
Significance. If the contraction result is rigorously established, ACSAC supplies a principled mechanism for removing the need for task-specific fixed chunk-size tuning while retaining the benefits of temporally extended actions. The combination of causal-Transformer multi-chunk evaluation with an adaptive selection rule is technically distinctive and, if empirically robust, could improve sample efficiency and stability on sparse-reward domains.
major comments (1)
- [§4 (Contraction Proof)] §4 (Contraction Proof): The manuscript asserts that the ACSAC Bellman operator is a contraction whose unique fixed point is the Q-function of the adaptive policy. Because the adaptive policy is defined by k* = argmax_k Q(s, chunk_k) using the same critic whose values are being updated, the operator is an optimality operator over a discrete set of chunked actions rather than a fixed-policy operator. The proof must therefore demonstrate explicitly that the state-dependent max over chunk sizes preserves a uniform contraction modulus ≤ γ < 1 without additional assumptions on the Transformer outputs or reward structure. The current derivation does not appear to supply this reduction or bound.
minor comments (2)
- [Experiments] Table 1 and Figure 3: report standard errors or confidence intervals alongside mean returns so that the SOTA claims can be statistically assessed.
- [Preliminaries] Notation: the definition of the adaptive policy π_acsac and the chunked action space should be stated once in a single display equation before the proof to avoid repeated inline definitions.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The feedback on the contraction proof is well-taken, and we will revise the manuscript to make the argument fully explicit. We address the single major comment below.
read point-by-point responses
-
Referee: The manuscript asserts that the ACSAC Bellman operator is a contraction whose unique fixed point is the Q-function of the adaptive policy. Because the adaptive policy is defined by k* = argmax_k Q(s, chunk_k) using the same critic whose values are being updated, the operator is an optimality operator over a discrete set of chunked actions rather than a fixed-policy operator. The proof must therefore demonstrate explicitly that the state-dependent max over chunk sizes preserves a uniform contraction modulus ≤ γ < 1 without additional assumptions on the Transformer outputs or reward structure. The current derivation does not appear to supply this reduction or bound.
Authors: We agree that the current derivation would benefit from an explicit reduction to the standard contraction property of the Bellman optimality operator. In the revised §4 we will first define the finite discrete set of macro-actions A = {a_k | k ∈ K}, where each a_k denotes the action chunk of length k. Each macro-action induces a k-step cumulative discounted reward R(s, a_k) and a transition to a successor state s' after exactly k steps. The ACSAC Bellman operator is then (T Q)(s, a_k) = E[R(s, a_k) + γ^k max_{k'} Q(s', a_{k'})]. This is exactly the optimality operator for an MDP whose action space is the finite set A. For any two bounded Q-functions Q1 and Q2 we have |max_{k'} Q1(s', a_{k'}) − max_{k'} Q2(s', a_{k'})| ≤ max_{k'} |Q1(s', a_{k'}) − Q2(s', a_{k'})| ≤ ||Q1 − Q2||_∞. Consequently ||T Q1 − T Q2||_∞ ≤ γ ||Q1 − Q2||_∞, showing that T is a contraction with modulus γ < 1. The unique fixed point is the optimal action-value function of the adaptive macro-action policy. The argument uses only the standard assumptions of bounded rewards and γ < 1; no further restrictions on the Transformer outputs or reward structure are required. We will insert this reduction and the accompanying bound into the revised manuscript. revision: yes
Circularity Check
No circularity: contraction proof is standard optimality operator over discrete chunk sizes
full rationale
The abstract states that ACSAC defines an adaptive policy via argmax over chunk sizes evaluated by the causal Transformer critic, then claims to prove the corresponding Bellman operator is a contraction with unique fixed point equal to the action-value function of that policy. This is exactly the standard optimality operator T* over a finite discrete action set (the possible chunk sizes), whose contraction property for γ < 1 is a textbook result independent of the specific critic architecture or the paper's own definitions. No equations, self-citations, fitted parameters, or ansatzes are shown reducing the claimed result to its inputs by construction. The experimental claims on OGBench are separate empirical statements and do not participate in the derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that the ACSAC Bellman operator is a contraction whose unique fixed point is the action-value function of the adaptive policy.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ACSAC leverages a causal Transformer critic to evaluate expected returns for action chunks of different sizes... prefix-conditioned Q-values
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InInternational Conference on Learning Representations, 2023. URL https: //openreview.net/forum?id=li7qeBbCR1t
work page 2023
-
[2]
Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine
Philip J. Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
work page 2023
-
[3]
Q-transformer: Scalable offline reinforcement learning via autoregressive Q-functions
Yevgen Chebotar, Quan Ho Vuong, Karol Hausman, Fei Xia, Yao Lu, Alex Irpan, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, Keerthana Gopalakrishnan, Julian Ibarz, Sergey Levine, Adrian Salazar, and Chelsea Finn. Q-transformer: Scalable offline reinforcement learning via autoregressive Q-functions. InConference on Robot Learning, pages 3909–3928....
work page 2023
-
[4]
Offline reinforcement learning via high-fidelity generative behavior modeling
Huayu Chen, Cheng Lu, Chengyang Ying, Hang Su, and Jun Zhu. Offline reinforcement learning via high-fidelity generative behavior modeling. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=42zs3qa2kpy
work page 2023
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. doi: 10.1177/ 02783649241273668
work page 2025
-
[6]
Diffusion-based reinforcement learning via q-weighted variational policy op- timization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy op- timization. InAdvances in Neural Information Processing Systems, volume 37, pages 53945–53968, 2024. URL https://proceedings.neurips.cc/paper_files/paper/ 2024/hash/6111371a868af8dcfba0...
-
[7]
Consistency models as a rich and efficient policy class for reinforcement learning
Zihan Ding and Chi Jin. Consistency models as a rich and efficient policy class for reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8jdwkUNXb
work page 2024
-
[8]
Perry Dong, Kuo-Han Hung, Alexander Swerdlow, Dorsa Sadigh, and Chelsea Finn. TQL: Scaling q-functions with transformers by preventing attention collapse.arXiv preprint arXiv:2602.01439, 2026
-
[9]
A minimalist approach to offline reinforcement learning
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 34, pages 20132–20145, 2021
work page 2021
-
[10]
EMaQ: Expected-max q-learning operator for simple yet effective offline and online RL
Seyed Kamyar Seyed Ghasemipour, Dale Schuurmans, and Shixiang Shane Gu. EMaQ: Expected-max q-learning operator for simple yet effective offline and online RL. InInternational Conference on Machine Learning, pages 3682–3691. PMLR, 2021
work page 2021
-
[11]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. IDQL: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Aligniql: Policy alignment in implicit q-learning through constrained optimization
Longxiang He, Li Shen, Junbo Tan, and Xueqian Wang. AlignIQL: Policy alignment in implicit q-learning through constrained optimization.arXiv preprint arXiv:2405.18187, 2024
-
[13]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[14]
Dongchi Huang, Zhirui Fang, Tianle Zhang, Yihang Li, Lin Zhao, and Chunhe Xia. CO-RFT: Efficient fine-tuning of vision-language-action models through chunked offline reinforcement learning.arXiv preprint arXiv:2508.02219, 2025
-
[15]
Efficient diffusion policies for offline reinforcement learning
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient diffusion policies for offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, pages 67195–67212, 2023. 10
work page 2023
-
[16]
DEAS: Detached value learning with action sequence for scalable offline RL
Changyeon Kim, Haeone Lee, Younggyo Seo, Kimin Lee, and Yuke Zhu. DEAS: Detached value learning with action sequence for scalable offline RL. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=bVTaAXeBmE
work page 2026
-
[17]
Offline reinforcement learning with implicit q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. InInternational Conference on Learning Representations, 2022. URL https: //openreview.net/forum?id=68n2s9ZJWF8
work page 2022
-
[18]
Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble
Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble. InConference on Robot Learning, pages 1702–1712. PMLR, 2022
work page 2022
-
[19]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[20]
TOP-ERL: Transformer-based off-policy episodic reinforcement learning
Ge Li, Dong Tian, Hongyi Zhou, Xinkai Jiang, Rudolf Lioutikov, and Gerhard Neumann. TOP-ERL: Transformer-based off-policy episodic reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=N4NhVN30ph
work page 2025
-
[21]
Reinforcement learning with action chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview. net/forum?id=XUks1Y96NR
work page 2025
-
[22]
Qiyang Li, Seohong Park, and Sergey Levine. Decoupled q-chunking. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=aqGNdZQL9l
work page 2026
-
[23]
Adaptive action chunking at inference-time for vision-language-action models
Yuanchang Liang, Xiaobo Wang, Kai Wang, Shuo Wang, Xiaojiang Peng, Haoyu Chen, David Kim Huat Chua, and Prahlad Vadakkepat. Adaptive action chunking at inference-time for vision-language-action models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
work page 2026
-
[24]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations,
-
[25]
URLhttps://openreview.net/forum?id=PqvMRDCJT9t
-
[26]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations,
-
[27]
URLhttps://openreview.net/forum?id=XVjTT1nw5z
-
[28]
Energy-guided diffusion sampling for offline-to-online reinforcement learning
Xu-Hui Liu, Tian-Shuo Liu, Shengyi Jiang, Ruifeng Chen, Zhilong Zhang, Xinwei Chen, and Yang Yu. Energy-guided diffusion sampling for offline-to-online reinforcement learning. In International Conference on Machine Learning, pages 31541–31565. PMLR, 2024. URL https://proceedings.mlr.press/v235/liu24ao.html
work page 2024
-
[29]
Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. InInternational Conference on Machine Learning, pages 22825–22855. PMLR, 2023
work page 2023
- [30]
-
[31]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. AW AC: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review arXiv 2006
-
[32]
Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning
Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning. InAdvances in Neural Information Processing Systems, volume 36, pages 62244–62269, 2023. 11
work page 2023
-
[33]
Scalable offline model- based RL with action chunks
Kwanyoung Park, Seohong Park, Youngwoon Lee, and Sergey Levine. Scalable offline model- based RL with action chunks. InThe Fourteenth International Conference on Learning Repre- sentations, 2026. URLhttps://openreview.net/forum?id=WXGb9unEHo
work page 2026
-
[34]
OGBench: Bench- marking offline goal-conditioned RL
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. OGBench: Bench- marking offline goal-conditioned RL. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=M992mjgKzI
work page 2025
-
[35]
Horizon reduction makes RL scalable
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon reduction makes RL scalable. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=hguaupzLCU
work page 2025
-
[36]
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning. InInternational Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=KVf2SFL1pi
work page 2025
-
[37]
Coarse-to-fine q-network with action sequence for data- efficient reinforcement learning
Younggyo Seo and Pieter Abbeel. Coarse-to-fine q-network with action sequence for data- efficient reinforcement learning. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=VoFXUNc9Zh
work page 2025
-
[38]
Chunk-guided q-learning.arXiv preprint arXiv:2603.13971, 2026
Gwanwoo Song, Kwanyoung Park, and Youngwoon Lee. Chunk-guided q-learning.arXiv preprint arXiv:2603.13971, 2026
-
[39]
Andrew Bagnell, Akshay Krishnamurthy, and Wen Sun
Yuda Song, Yifei Zhou, Ayush Sekhari, J. Andrew Bagnell, Akshay Krishnamurthy, and Wen Sun. Hybrid RL: Using both offline and online data can make RL efficient. InInternational Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=yyBis80iUuU
work page 2023
-
[40]
Revisiting the minimalist approach to offline reinforcement learning
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, pages 11592–11620, 2023
work page 2023
-
[41]
Chunking the critic: A transformer-based soft actor-critic with N-step returns
Dong Tian, Onur Celik, and Gerhard Neumann. Chunking the critic: A transformer-based soft actor-critic with N-step returns. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=rb5eTktqbc
work page 2026
-
[42]
Zhendong Wang, Jonathan J. Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=AHvFDPi-FA
work page 2023
-
[43]
Jiarui Yang, Bin Zhu, Jingjing Chen, and Yu-Gang Jiang. Actor-critic for continuous action chunks: A reinforcement learning framework for long-horizon robotic manipulation with sparse reward.Proceedings of the AAAI Conference on Artificial Intelligence, 40(22):18692–18700,
-
[44]
doi: 10.1609/aaai.v40i22.38937
-
[45]
Actor-critic alignment for offline-to-online reinforcement learning
Zishun Yu and Xinhua Zhang. Actor-critic alignment for offline-to-online reinforcement learning. InInternational Conference on Machine Learning, pages 40452–40474. PMLR, 2023
work page 2023
-
[46]
Understand- ing, predicting and better resolving Q-value divergence in offline-RL
Yang Yue, Rui Lu, Bingyi Kang, Shiji Song, and Gao Huang. Understand- ing, predicting and better resolving Q-value divergence in offline-RL. InAd- vances in Neural Information Processing Systems, volume 36, pages 60247–60277,
-
[47]
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ bd6bb13e78da078d8adcabbe6d9ca737-Abstract-Conference.html
work page 2023
-
[48]
Energy-weighted flow matching for offline reinforcement learning
Shiyuan Zhang, Weitong Zhang, and Quanquan Gu. Energy-weighted flow matching for offline reinforcement learning. InThe Thirteenth International Conference on Learning Representa- tions, 2025. URLhttps://openreview.net/forum?id=HA0oLUvuGI
work page 2025
-
[49]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023
work page 2023
-
[50]
Efficient online reinforcement learning fine-tuning need not retain offline data
Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online reinforcement learning fine-tuning need not retain offline data. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=HN0CYZbAPw. 12 A Limitations We highlight three limitations of ACSAC and corresponding direc...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.