Recognition: 2 theorem links
· Lean TheoremSampling More, Getting Less: Calibration is the Diversity Bottleneck in LLMs
Pith reviewed 2026-05-13 03:59 UTC · model grok-4.3
The pith
Miscalibration in how LLMs rank and weight valid tokens causes diversity to collapse during generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
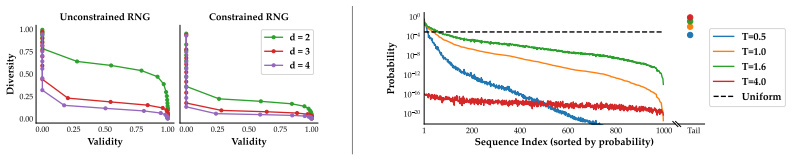
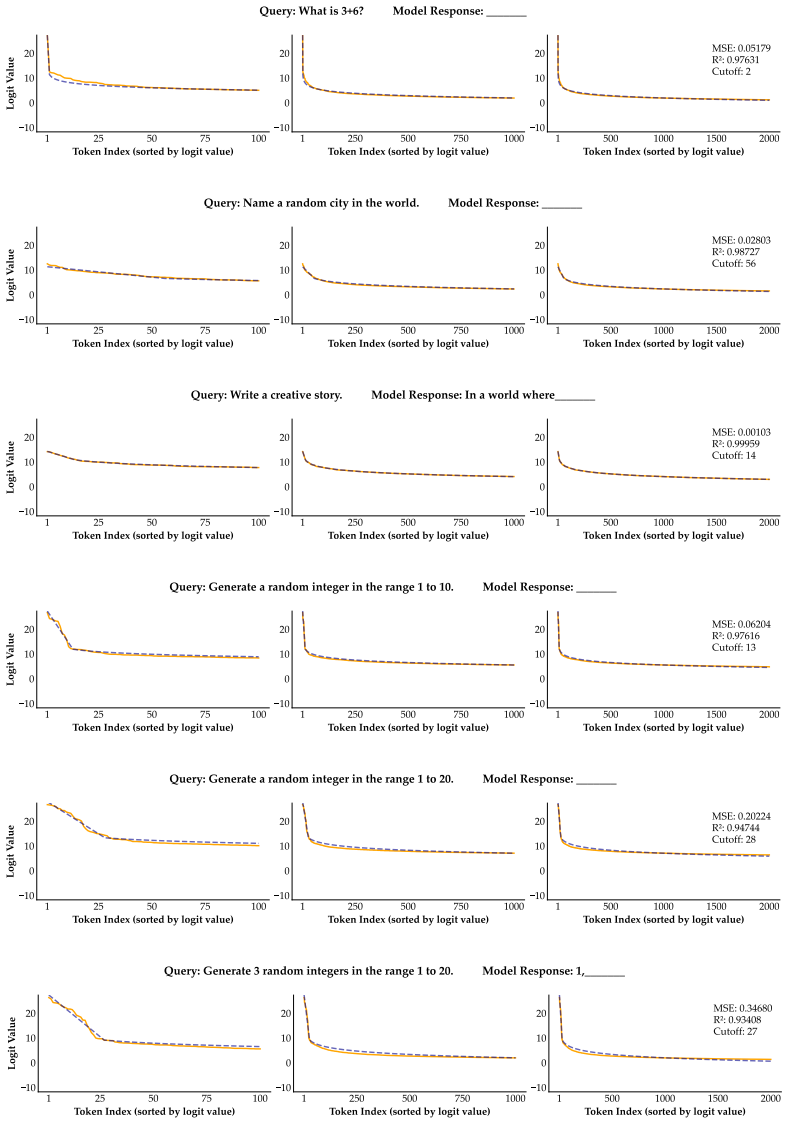
Diversity collapse arises because LLMs exhibit order miscalibration, where valid tokens are not reliably ranked above invalid ones, and shape miscalibration, where probability concentrates on few valid continuations amid heavy tails containing mixed validity; these failures at individual steps accumulate into large sequence-level diversity losses.
What carries the argument
The validity-diversity framework that decomposes diversity collapse into order calibration (ranking of valid over invalid tokens) and shape calibration (allocation of probability mass across valid continuations).
If this is right
- Sampling rules that only use rank or probability thresholds cannot escape the validity-diversity trade-off created by miscalibration.
- Fixing the underlying distribution calibration would allow higher diversity at the same validity level.
- Local ranking and mass-allocation errors multiply across decoding steps to create the observed global collapse.
- Tasks with fully known valid sets can isolate these distribution flaws from other generation issues.
Where Pith is reading between the lines
- Training objectives that penalize incorrect ranking or over-concentration on few valid tokens might reduce the bottleneck without changing inference.
- The same order and shape issues could limit diversity in non-text generation domains where validity is easier to define.
- Post-training calibration methods targeting token-level ranking and tail behavior could be tested as a direct remedy.
- Models that appear well-calibrated on standard benchmarks may still fail on diversity because those benchmarks do not separate order from shape errors.
Load-bearing premise
That the set of valid continuations can be defined objectively and exhaustively for the diagnostic tasks so that miscalibration effects can be measured separately from other factors.
What would settle it
A model that produces high sequence-level diversity on the controlled diagnostic tasks while keeping validity near the oracle cutoff level, without any post-hoc adjustment to its token probabilities.
Figures












read the original abstract
Diversity is essential for language-model applications ranging from creative generation to scientific discovery, yet modern LLMs often collapse into a narrow subset of plausible outputs. While prior work has developed benchmarks for measuring this lack of diversity, less is known about how the step-by-step probability distributions at inference time cause the problem. We introduce a validity--diversity framework that attributes diversity collapse to how an LLM allocates probability mass across valid and invalid continuations during decoding. This framework decomposes the bottleneck into two complementary forms of miscalibration. First, order calibration: valid tokens are not reliably ranked above invalid tokens, so rank-based cutoff rules must trade off between recovering valid continuations and admitting invalid ones. Second, shape calibration: probability mass is overly concentrated only on few valid continuations while having a heavy-tail of mixed valid and invalid tokens, so maintaining high validity limits diversity. We formalize both mechanisms and show that local failures compound across decoding steps, producing strong sequence-level losses in diversity. Empirically, we develop controlled diagnostics for probing these bottlenecks, including tasks with exactly known valid sets and oracle cutoff baselines. Across 14 language models spanning multiple families and scales, we find that diversity collapse is not merely a limitation of particular sampling heuristics, but a consequence of order and shape miscalibration in the LLM distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a validity-diversity framework that decomposes LLM diversity collapse into order miscalibration (valid tokens not reliably ranked above invalid ones, forcing trade-offs in rank-based cutoffs) and shape miscalibration (probability mass overly concentrated on few valid continuations amid heavy tails of mixed tokens). It formalizes these mechanisms, shows local failures compound across decoding steps to produce sequence-level diversity losses, and supports the attribution via controlled diagnostics on tasks with exactly known valid sets plus oracle baselines. Experiments across 14 models from multiple families and scales conclude that the bottleneck is inherent to the LLM distribution's calibration rather than sampling heuristics.
Significance. If the central attribution holds, the work offers a diagnostic lens for why diversity remains limited despite advances in sampling, with potential to redirect efforts toward better-calibrated next-token distributions for applications like creative generation. Credit is due for the multi-model evaluation spanning scales and families, the use of oracle cutoffs as baselines, and the explicit decomposition into order and shape components that enables targeted probing.
major comments (2)
- [§4] §4 (Controlled Diagnostics): The claim that diversity collapse is isolated to order and shape miscalibration rests on tasks having 'exactly known valid sets' that are objective and exhaustive. However, the manuscript does not provide explicit verification that these partitions (e.g., syntactic or string-match rules) are defined independently of patterns in the models' training data; any correlation would confound the attribution of ranking failures and heavy tails to calibration rather than task artifacts. This is load-bearing for the conclusion that miscalibration—not heuristics—is the primary bottleneck.
- [§5] §5 (Empirical Results): The reported sequence-level diversity losses and cross-model patterns lack error bars, confidence intervals, or details on data-exclusion rules and run-to-run variability. Without these, it is difficult to evaluate the robustness of the claim that local miscalibration effects reliably compound across 14 models.
minor comments (2)
- [§3] Notation for the validity-diversity decomposition (around Eq. 3-5) could be clarified with an explicit table mapping symbols to their definitions to aid readers in following the compounding argument.
- [§5] Figure 2 (example generation traces) would benefit from annotations highlighting the exact points of order vs. shape miscalibration to make the local-to-global compounding more visually immediate.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below, indicating where revisions will be made and where limitations remain.
read point-by-point responses
-
Referee: [§4] §4 (Controlled Diagnostics): The claim that diversity collapse is isolated to order and shape miscalibration rests on tasks having 'exactly known valid sets' that are objective and exhaustive. However, the manuscript does not provide explicit verification that these partitions (e.g., syntactic or string-match rules) are defined independently of patterns in the models' training data; any correlation would confound the attribution of ranking failures and heavy tails to calibration rather than task artifacts. This is load-bearing for the conclusion that miscalibration—not heuristics—is the primary bottleneck.
Authors: The valid sets are constructed from objective, a priori rules that do not depend on model outputs or training patterns. In the syntactic task, validity is defined by formal grammar constraints (e.g., balanced parentheses, valid JSON syntax) specified independently of any corpus. In the string-match task, validity requires exact matching to a manually enumerated set of templates. These definitions are exhaustive by construction and predate any model evaluation. Oracle baselines further isolate miscalibration by demonstrating that perfect order and shape calibration recovers full diversity. We will add an appendix subsection in the revision that explicitly lists the rule definitions for each task and argues their independence from training-data patterns. A quantitative overlap analysis with proprietary training corpora is not feasible for all 14 models. revision: partial
-
Referee: [§5] §5 (Empirical Results): The reported sequence-level diversity losses and cross-model patterns lack error bars, confidence intervals, or details on data-exclusion rules and run-to-run variability. Without these, it is difficult to evaluate the robustness of the claim that local miscalibration effects reliably compound across 14 models.
Authors: We agree that statistical details on variability are needed. The revised manuscript will report standard deviations across five independent runs for all sequence-level metrics, add 95% confidence intervals to the cross-model plots, document prompt sampling and exclusion criteria (e.g., discarding prompts with zero valid tokens), and include a variability analysis in the appendix. These additions will directly support the claim that local effects compound reliably. revision: yes
- Full empirical verification that valid-set partitions have zero correlation with patterns in the proprietary training data of all 14 evaluated models.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a validity-diversity framework defined from first principles that decomposes diversity collapse into order and shape miscalibration, using externally specified valid sets and oracle baselines for controlled diagnostics. Empirical measurements across 14 models are obtained by applying these independent partitions and baselines rather than by fitting parameters whose outputs are then renamed as predictions. No equations or central claims reduce by construction to quantities defined inside the same experiment, and no load-bearing steps invoke self-citations or uniqueness theorems that would force the result. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Validity of token continuations can be objectively defined for the chosen diagnostic tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce a validity–diversity framework that attributes diversity collapse to how an LLM allocates probability mass across valid and invalid continuations... order calibration... shape calibration... geometric decaying... Zipf-like behavior
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearTheorem 4.2 (Compounding effect of decoding steps)... Theorem 5.2 (Validity–Diversity trade-off)... Assumption 5.1 (Invariant valid branching)
Reference graph
Works this paper leans on
-
[1]
David H. Ackley, Geoffrey E. Hinton, and Terrence J. Sejnowski. A learning algorithm for boltzmann machines.Cognitive Science, 9(1):147–169, 1985
work page 1985
-
[2]
Jointly measuring diversity and quality in text generation models
Danial Alihosseini, Ehsan Montahaei, and Mahdieh Soleymani Baghshah. Jointly measuring diversity and quality in text generation models. InProceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation, pages 90–98, 2019
work page 2019
-
[3]
Epsvec: Efficient and private synthetic data generation via dataset vectors, 2026
Amin Banayeeanzade, Qingchuan Yang, Deqing Fu, Spencer Hong, Erin Babinsky, Alfy Samuel, Anoop Kumar, Robin Jia, and Sai Praneeth Karimireddy. Epsvec: Efficient and private synthetic data generation via dataset vectors, 2026
work page 2026
- [4]
-
[5]
Softmax bottleneck makes language models unable to represent multi-mode word distributions
Haw-Shiuan Chang and Andrew McCallum. Softmax bottleneck makes language models unable to represent multi-mode word distributions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8048–8073, 2022
work page 2022
-
[6]
Dlcrec: A novel approach for managing diversity in llm-based recommender systems
Jiaju Chen, Chongming Gao, Shuai Yuan, Shuchang Liu, Qingpeng Cai, and Peng Jiang. Dlcrec: A novel approach for managing diversity in llm-based recommender systems. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, page 857–865, 2025
work page 2025
-
[7]
Modifying large language model post-training for diverse creative writing
John Joon Young Chung, Vishakh Padmakumar, Melissa Roemmele, Yuqian Sun, and Max Kreminski. Modifying large language model post-training for diverse creative writing. In Second Conference on Language Modeling, 2025
work page 2025
-
[8]
Hierarchical neural story generation
Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. InProceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, 2018
work page 2018
-
[9]
Closing the curious case of neural text degeneration
Matthew Finlayson, John Hewitt, Alexander Koller, Swabha Swayamdipta, and Ashish Sab- harwal. Closing the curious case of neural text degeneration. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[10]
The variance paradox: How ai reduces diversity but increases novelty, 2026
Bijean Ghafouri. The variance paradox: How ai reduces diversity but increases novelty, 2026
work page 2026
-
[11]
A survey on llm-as-a-judge.The Innovation, page 101253, 2026
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Zhouchi Lin, Bowen Zhang, Lionel Ni, Wen Gao, Yuanzhuo Wang, and Jian Guo. A survey on llm-as-a-judge.The Innovation, page 101253, 2026
work page 2026
-
[12]
Yanzhu Guo, Guokan Shang, and Chloé Clavel. Benchmarking linguistic diversity of large language models.Transactions of the Association for Computational Linguistics, 13:1507–1526, 2025
work page 2025
-
[13]
Truncation sampling as language model desmoothing
John Hewitt, Christopher Manning, and Percy Liang. Truncation sampling as language model desmoothing. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 3414–3427, 2022
work page 2022
-
[14]
M. O. Hill. Diversity and evenness: A unifying notation and its consequences.Ecology, 54(2): 427–432, 1973
work page 1973
-
[15]
The curious case of neural text degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. InInternational Conference on Learning Representations, 2020
work page 2020
-
[16]
Luchini, Reet Patel, Antoine Bosselut, Lonneke Van Der Plas, and Roger E
Mete Ismayilzada, Antonio Laverghetta Jr., Simone A. Luchini, Reet Patel, Antoine Bosselut, Lonneke Van Der Plas, and Roger E. Beaty. Creative preference optimization. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 9580–9609, 2025. 10
work page 2025
-
[17]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[18]
Artificial hivemind: The open-ended homogeneity of language models (and beyond)
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, and Yejin Choi. Artificial hivemind: The open-ended homogeneity of language models (and beyond). InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
work page 2025
-
[19]
Entropy and diversity.Oikos, 113(2):363–375, 2006
Lou Jost. Entropy and diversity.Oikos, 113(2):363–375, 2006
work page 2006
-
[20]
Reasoning with sampling: Your base model is smarter than you think
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[21]
Evaluating the quality of randomness and entropy in tasks supported by large language models, 2025
Rabimba Karanjai, Yang Lu, Ranjith Chodavarapu, Lei Xu, and Weidong Shi. Evaluating the quality of randomness and entropy in tasks supported by large language models, 2025
work page 2025
-
[22]
Understanding the effects of RLHF on LLM generalisation and diversity
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. Understanding the effects of RLHF on LLM generalisation and diversity. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[23]
Content analysis: An introduction to its methodology
Klaus Krippendorff. Content analysis: An introduction to its methodology. 1980
work page 1980
-
[24]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[25]
Jointly reinforcing diversity and quality in language model generations, 2025
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations, 2025
work page 2025
-
[26]
Preserving diversity in supervised fine-tuning of large language models
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Zhi-Quan Luo, and Ruoyu Sun. Preserving diversity in supervised fine-tuning of large language models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[27]
Clara Meister, Tiago Pimentel, Gian Wiher, and Ryan Cotterell. Locally typical sampling. Transactions of the Association for Computational Linguistics, 11, 2023
work page 2023
-
[28]
Turning up the heat: Min-p sampling for creative and coherent LLM outputs
Nguyen Nhat Minh, Andrew Baker, Clement Neo, Allen G Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. Turning up the heat: Min-p sampling for creative and coherent LLM outputs. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[29]
String seed of thought: Prompting LLMs for distribution- faithful and diverse generation
Kou Misaki and Takuya Akiba. String seed of thought: Prompting LLMs for distribution- faithful and diverse generation. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[30]
One fish, two fish, but not the whole sea: Alignment reduces language models’ conceptual diversity
Sonia Krishna Murthy, Tomer Ullman, and Jennifer Hu. One fish, two fish, but not the whole sea: Alignment reduces language models’ conceptual diversity. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025
work page 2025
-
[31]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, 2002
work page 2002
-
[32]
Max Peeperkorn, Tom Kouwenhoven, Dan Brown, and Anna Jordanous. Mind the gap: Con- formative decoding to improve output diversity of instruction-tuned large language models, 2025
work page 2025
-
[33]
Top-h decoding: Adapting the creativity and coherence with bounded entropy in text generation
Erfan Baghaei Potraghloo, Seyedarmin Azizi, Souvik Kundu, and Massoud Pedram. Top-h decoding: Adapting the creativity and coherence with bounded entropy in text generation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. 11
work page 2026
-
[34]
Min-p, max exaggeration: A critical analysis of min-p sampling in language models, 2025
Rylan Schaeffer, Joshua Kazdan, and Yegor Denisov-Blanch. Min-p, max exaggeration: A critical analysis of min-p sampling in language models, 2025
work page 2025
-
[35]
Evaluating the diversity and quality of LLM generated content
Alexander Shypula, Shuo Li, Botong Zhang, Vishakh Padmakumar, Kayo Yin, and Osbert Bastani. Evaluating the diversity and quality of LLM generated content. InSecond Conference on Language Modeling, 2025
work page 2025
-
[36]
The shrinking landscape of linguistic diversity in the age of large language models, 2025
Zhivar Sourati, Farzan Karimi-Malekabadi, Meltem Ozcan, Colin McDaniel, Alireza Ziabari, Jackson Trager, Ala Tak, Meng Chen, Fred Morstatter, and Morteza Dehghani. The shrinking landscape of linguistic diversity in the age of large language models, 2025
work page 2025
-
[37]
Contrastive search is what you need for neural text generation
Yixuan Su and Nigel Collier. Contrastive search is what you need for neural text generation. Transactions on Machine Learning Research, 2023
work page 2023
-
[38]
Control the temperature: Selective sampling for diverse and high-quality LLM outputs
Sergey Troshin, Wafaa Mohammed, Yan Meng, Christof Monz, Antske Fokkens, and Vlad Niculae. Control the temperature: Selective sampling for diverse and high-quality LLM outputs. InSecond Conference on Language Modeling, 2025
work page 2025
-
[39]
Guancheng Tu, Shiyang Zhang, Tianyu Zhang, Yi Zhang, and Diji Yang. Shared nature, unique nurture: Prism for pluralistic reasoning via in-context structure modeling, 2026
work page 2026
-
[40]
Diverse beam search for improved description of complex scenes
Ashwin Vijayakumar, Michael Cogswell, Ramprasaath Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search for improved description of complex scenes. Proceedings of the AAAI Conference on Artificial Intelligence, Apr. 2018
work page 2018
-
[41]
Multilingual prompting for improving LLM generation diversity
Qihan Wang, Shidong Pan, Tal Linzen, and Emily Black. Multilingual prompting for improving LLM generation diversity. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6367–6389, 2025
work page 2025
-
[42]
Optimizing diversity and quality through base-aligned model collaboration, 2025
Yichen Wang, Chenghao Yang, Tenghao Huang, Muhao Chen, Jonathan May, and Mina Lee. Optimizing diversity and quality through base-aligned model collaboration, 2025
work page 2025
-
[43]
Base models beat aligned models at randomness and creativity
Peter West and Christopher Potts. Base models beat aligned models at randomness and creativity. InSecond Conference on Language Modeling, 2025
work page 2025
-
[44]
Weijia Xu, Nebojsa Jojic, Sudha Rao, Chris Brockett, and Bill Dolan. Echoes in ai: Quantifying lack of plot diversity in llm outputs.Proceedings of the National Academy of Sciences, 2025
work page 2025
-
[45]
Llm probability concentration: How alignment shrinks the generative horizon, 2026
Chenghao Yang, Sida Li, and Ari Holtzman. Llm probability concentration: How alignment shrinks the generative horizon, 2026
work page 2026
-
[46]
Generation space size: Understanding and calibrating open-endedness of llm generations, 2025
Sunny Yu, Ahmad Jabbar, Robert Hawkins, Dan Jurafsky, and Myra Cheng. Generation space size: Understanding and calibrating open-endedness of llm generations, 2025
work page 2025
-
[47]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[48]
Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael R. Tomz, Christopher D. Manning, and Weiyan Shi. Verbalized sampling: How to mitigate mode collapse and unlock llm diversity, 2025
work page 2025
-
[49]
Noveltybench: Evaluating creativity and diversity in language models
Yiming Zhang, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay Samuel, Barry Wang, and Daphne Ippolito. Noveltybench: Evaluating creativity and diversity in language models. InSecond Conference on Language Modeling, 2025
work page 2025
-
[50]
Yuxuan Zhou, Margret Keuper, and Mario Fritz. Balancing diversity and risk in LLM sampling: How to select your method and parameter for open-ended text generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26352–26365, 2025
work page 2025
-
[51]
Improving open-ended text generation via adaptive decoding
Wenhong Zhu, Hongkun Hao, Zhiwei He, Yiming Ai, and Rui Wang. Improving open-ended text generation via adaptive decoding. InForty-first International Conference on Machine Learning, 2024. 12 A LLM-as-a-judge Details A.1 Prompt and Model Token validity is scored based on the greedy-decoding completion. We use Qwen3.5-35B-A3B-FP8 with thinking enabled as ou...
work page 2024
-
[52]
grammar, spelling and punctuation,
-
[53]
semantic soundness, validity, and relevance to the question,
-
[54]
overall quality. When evaluating grammar, check for spelling mistakes, punctuation errors, and grammatical issues. If spaces are missing between words, extra punctuations in the middle of sentences, or incorrect capitalization, that should be considered a grammar error. Additionally, if the generation contains non-English characters, that should be consid...
work page 2045
-
[55]
(Order Calibration) p is order calibrated if for any valid token v∈ V and invalid token w∈ V , it assigns a higher probability to the valid token, i.e.,p(v|y <t)≥p(w|y <t)
-
[56]
(Shape Calibration) p is shape calibrated if for any token v∈ V , it assigns probability mass to v according to the number of valid continuations starting withv, i.e.,p(v|y <t)∝N(y <t ◦v). Note that shape calibration is stronger than order calibration: even if order calibration is resolved, shape calibration can still persist. However, perfect shape calib...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.