Recognition: 2 theorem links
· Lean TheoremReCoVer: Resilient LLM Pre-Training System via Fault-Tolerant Collective and Versatile Workload
Pith reviewed 2026-05-13 01:55 UTC · model grok-4.3
The pith
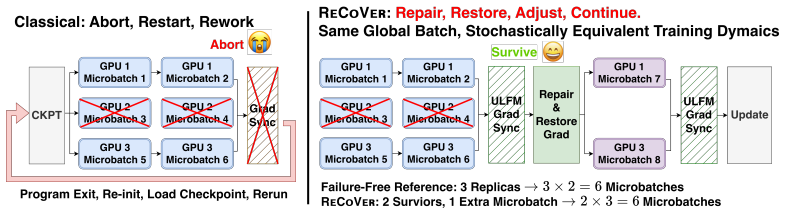
ReCoVer keeps the per-iteration gradient distribution identical to failure-free LLM pre-training by holding microbatch count constant after any GPU losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
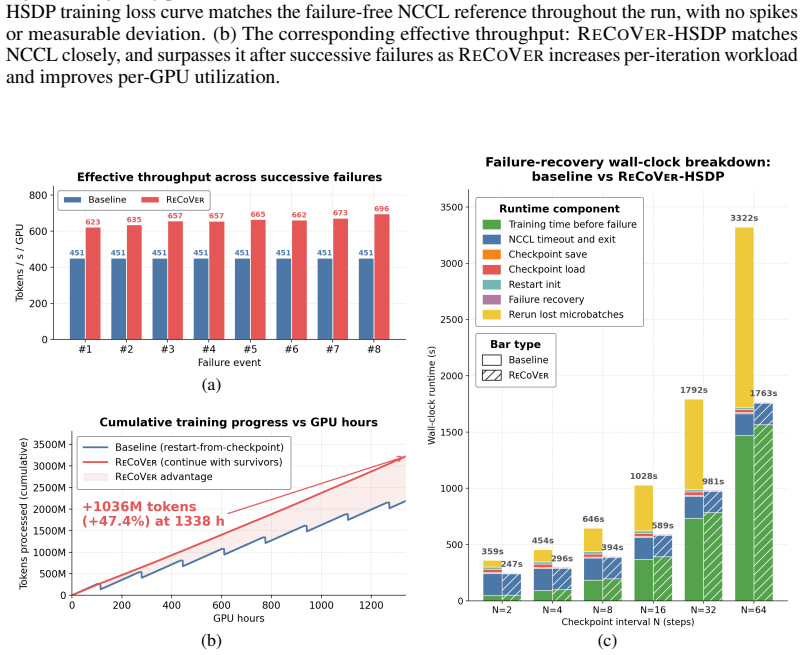
ReCoVer upholds the invariant that each iteration processes a fixed number of microbatches regardless of which GPUs fail. This is realized through three decoupled layers: fault-tolerant collectives that prevent error propagation, in-step recovery that salvages intra-iteration work, and a versatile-workload policy that redistributes microbatch quotas to survivors. The design works as a drop-in layer for both 3D parallelism and HSDP. On up to 512-GPU runs with 256 GPUs lost across the job, the system matches the failure-free loss curve while delivering 2.23 times the effective throughput of checkpoint-restart baselines and 74.9 percent more tokens in 234 GPU-hours.
What carries the argument
The constant-microbatch invariant per iteration, maintained by fault-tolerant collectives, in-step recovery, and dynamic redistribution of microbatch quotas to survivors.
Load-bearing premise
Keeping the microbatch count fixed across surviving GPUs produces gradients whose statistical properties remain identical to a failure-free run and do not accumulate bias or divergence over long training.
What would settle it
Run an identical pre-training job once with ReCoVer under injected failures and once without failures; if the loss curves or downstream metrics diverge beyond normal run-to-run variance, the stochastic-equivalence claim is false.
Figures








read the original abstract
Pre-training large language models on massive GPU clusters has made hardware faults routine rather than rare, driving the need for resilient training systems. Yet existing frameworks either focus on specific parallelism schemes or risk drifting away from a failure-free training trajectory. We propose ReCoVer, a resilient LLM pre-training system that upholds a single invariant: each iteration keeps the number of microbatches constant, ensuring per-iteration gradients remain stochastically equivalent to a failure-free run. The framework is organized as three decoupled protocol layers: (1) Fault-tolerant collectives that isolate faults from propagating across replicas; (2) in-step fine-grained recovery that preserves intra-iteration progress and prevents gradient corruption; (3) versatile-workload policy that dynamically redistributes microbatch quotas across the survivors. The design is parallelism-agnostic, integrating directly with both 3D parallelism and Hybrid Sharded Data Parallel (HSDP) as a drop-in substrate. We evaluate our implementation on end-to-end pre-training tasks for up to 512 GPUs, ReCoVer successfully preserves the training trajectory from a failure-free reference despite of 256 GPUs lost spread across the run. For comparison with checkpoint-and-restart baselines, ReCoVer demonstrates $2.23\times$ higher effective throughput after successive failures. This advantage results in ReCoVer processing 74.9% more tokens at 234 GPU-hours, with the gap widening as the training prolongs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ReCoVer, a resilient LLM pre-training system that upholds the invariant of keeping the number of microbatches per iteration constant to ensure per-iteration gradients remain stochastically equivalent to a failure-free run. It consists of three layers: fault-tolerant collectives to isolate faults, in-step fine-grained recovery to preserve intra-iteration progress, and a versatile-workload policy for dynamic microbatch quota redistribution to survivors. The design is parallelism-agnostic and integrates with 3D parallelism and HSDP. End-to-end evaluations on up to 512 GPUs with up to 256 failures across the run show preservation of the training trajectory from a failure-free reference, 2.23× higher effective throughput than checkpoint-and-restart baselines, and 74.9% more tokens processed at 234 GPU-hours.
Significance. If the invariant on gradient equivalence holds under redistribution and the empirical results prove robust, ReCoVer addresses a critical practical challenge in large-scale distributed training where hardware faults are routine. The reported throughput gains and trajectory preservation could enable more efficient utilization of massive GPU clusters without sacrificing model quality, with the parallelism-agnostic drop-in design adding practical value.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim that constant microbatch count ensures stochastically equivalent gradients (and thus preserved training trajectory despite 256 GPU losses) is load-bearing, yet the versatile-workload policy's dynamic redistribution of quotas to survivors risks altering data selection or ordering. Without explicit mechanisms such as synchronized data sampling or checkpointed data loader state, small discrepancies could accumulate over long training runs, undermining the equivalence invariant. The reported 2.23× throughput and 74.9% more tokens depend on this not occurring.
- [Evaluation] Evaluation section: The end-to-end results on 512 GPUs report a 2.23× effective throughput gain and trajectory preservation after successive failures, but lack details on failure injection method, how equivalence is quantified (e.g., loss curve comparisons or gradient statistics), and statistical significance of the gains. This makes verification of the performance claims difficult and is load-bearing for the main empirical contribution.
minor comments (2)
- [Abstract] Abstract: 'despite of 256 GPUs lost' is grammatically incorrect and should read 'despite 256 GPUs being lost' or 'despite the loss of 256 GPUs'.
- The paper would benefit from a dedicated limitations section discussing edge cases, such as faults occurring mid-iteration or interactions with specific data loaders.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the importance of the equivalence invariant and experimental details. We address each point below and will revise the manuscript to incorporate clarifications and additional information.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central claim that constant microbatch count ensures stochastically equivalent gradients (and thus preserved training trajectory despite 256 GPU losses) is load-bearing, yet the versatile-workload policy's dynamic redistribution of quotas to survivors risks altering data selection or ordering. Without explicit mechanisms such as synchronized data sampling or checkpointed data loader state, small discrepancies could accumulate over long training runs, undermining the equivalence invariant. The reported 2.23× throughput and 74.9% more tokens depend on this not occurring.
Authors: We agree that explicit mechanisms are essential to uphold the invariant and that the current manuscript would benefit from a clearer description. The versatile-workload policy redistributes microbatch quotas while preserving global data ordering through a synchronized data loader that maintains a shared iteration state and checkpoints the sampling position at the beginning of each iteration across survivors. This ensures data selection and ordering remain identical to the failure-free case. We will expand the System Design and Evaluation sections with pseudocode and a dedicated paragraph detailing this synchronization to make the safeguards explicit. revision: yes
-
Referee: [Evaluation] Evaluation section: The end-to-end results on 512 GPUs report a 2.23× effective throughput gain and trajectory preservation after successive failures, but lack details on failure injection method, how equivalence is quantified (e.g., loss curve comparisons or gradient statistics), and statistical significance of the gains. This makes verification of the performance claims difficult and is load-bearing for the main empirical contribution.
Authors: We acknowledge that the Evaluation section would be strengthened by additional methodological details for reproducibility. In the revised version we will add: (1) failure injection via random process termination at specified iteration boundaries during the run; (2) equivalence quantification through side-by-side loss curves, per-iteration gradient norm comparisons, and final model perplexity; and (3) statistical significance via three independent runs with reported means and standard deviations. These elements will be integrated into the Evaluation section and the experimental setup description. revision: yes
Circularity Check
No circularity; design invariant and empirical results are independent
full rationale
The paper's core claim rests on a stated design invariant (constant microbatches per iteration) that is upheld by the three protocol layers and then validated through direct end-to-end experiments comparing against checkpoint-restart baselines on up to 512 GPUs. No equations, fitted parameters, or self-citations are presented that reduce the reported throughput gains, token counts, or trajectory preservation to the inputs by construction. The stochastic-equivalence statement is an explicit assumption of the workload policy rather than a derived result that loops back on itself. This is a standard systems paper whose performance numbers are externally falsifiable via the described runs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hardware faults can be detected and isolated without corrupting ongoing gradient computation when using specialized collectives.
- domain assumption Redistributing microbatch quotas across surviving GPUs preserves the stochastic properties of the original training trajectory.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
upholds a single invariant: each iteration keeps the number of microbatches constant, ensuring per-iteration gradients remain stochastically equivalent
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
versatile-workload policy that dynamically redistributes microbatch quotas across the survivors
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
A. Bouteiller, G. Bosilca, and J. J. Dongarra. Plan b: Interruption of ongoing mpi operations to support failure recovery. InProceedings of the 22nd European MPI Users’ Group Meeting, pages 1–9, 2015
work page 2015
-
[4]
S. Dash, I. R. Lyngaas, J. Yin, X. Wang, R. Egele, J. A. Ellis, M. Maiterth, G. Cong, F. Wang, and P. Balaprakash. Optimizing distributed training on frontier for large language models. In ISC High Performance 2024 Research Paper Proceedings (39th International Conference), pages 1–11. Prometeus GmbH, 2024
work page 2024
-
[5]
A. Eisenman, K. K. Matam, S. Ingram, D. Mudigere, R. Krishnamoorthi, K. Nair, M. Smelyan- skiy, and M. Annavaram. {Check-N-Run}: A checkpointing system for training deep learning recommendation models. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pages 929–943, 2022
work page 2022
- [6]
-
[7]
M. Gooding. xai targets one million gpus for colossus supercomputer in memphis, 2024
work page 2024
-
[8]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
S. Hasan. Scaling llama4 training to 100k, 2026
work page 2026
-
[10]
Q. Hu, Z. Ye, Z. Wang, G. Wang, M. Zhang, Q. Chen, P. Sun, D. Lin, X. Wang, Y . Luo, et al. Characterization of large language model development in the datacenter. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 709–729, 2024
work page 2024
- [11]
-
[12]
I. Jang, Z. Yang, Z. Zhang, X. Jin, and M. Chowdhury. Oobleck: Resilient distributed training of large models using pipeline templates. InProceedings of the 29th Symposium on Operating Systems Principles, pages 382–395, 2023
work page 2023
-
[13]
M. Jeon, S. Venkataraman, A. Phanishayee, J. Qian, W. Xiao, and F. Yang. Analysis of{Large- Scale}{Multi-Tenant}{GPU} clusters for {DNN} training workloads. In2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 947–960, 2019. 10
work page 2019
-
[14]
Z. Jiang, H. Lin, Y . Zhong, Q. Huang, Y . Chen, Z. Zhang, Y . Peng, X. Li, C. Xie, S. Nong, et al. {MegaScale}: Scaling large language model training to more than 10,000 {GPUs}. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 745–760, 2024
work page 2024
-
[15]
A. Kokolis, M. Kuchnik, J. Hoffman, A. Kumar, P. Malani, F. Ma, Z. DeVito, S. Sengupta, K. Saladi, and C.-J. Wu. Revisiting reliability in large-scale machine learning research clusters. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1259–1274. IEEE, 2025
work page 2025
- [16]
- [17]
-
[18]
J. Li, G. Bosilca, A. Bouteiller, and B. Nicolae. Elastic deep learning through resilient collective operations. InProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, pages 44–50, 2023
work page 2023
- [19]
- [20]
- [21]
- [22]
-
[23]
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia. Pipedream: Generalized pipeline parallelism for dnn training. In Proceedings of the 27th ACM symposium on operating systems principles, pages 1–15, 2019
work page 2019
-
[24]
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, et al. Efficient large-scale language model training on gpu clusters using megatron-lm. InProceedings of the international conference for high performance computing, networking, storage and analysis, pages 1–15, 2021
work page 2021
-
[25]
B. Nicolae, A. Moody, E. Gonsiorowski, K. Mohror, and F. Cappello. Veloc: Towards high performance adaptive asynchronous checkpointing at large scale. In2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 911–920. IEEE, 2019
work page 2019
- [26]
- [27]
-
[28]
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020. 11
work page 2020
-
[29]
S., Narang, S., Edunov, S., Naumov, M., Tang, C., and Oldham, M
O. Salpekar, R. Varma, K. Yu, V . Ivanov, Y . Wang, A. Sharif, M. Si, S. Xu, F. Tian, S. Zheng, et al. Training llms with fault tolerant hsdp on 100,000 gpus.arXiv preprint arXiv:2602.00277, 2026
-
[30]
Horovod: fast and easy distributed deep learning in TensorFlow
A. Sergeev and M. Del Balso. Horovod: fast and easy distributed deep learning in tensorflow. arXiv preprint arXiv:1802.05799, 2018
work page Pith review arXiv 2018
-
[31]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[32]
N. Tazi, F. Mom, H. Zhao, P. Nguyen, M. Mekkouri, L. Werra, and T. Wolf. The ultra-scale playbook: Training llms on gpu clusters. 2025.URl: https://huggingface. co/spaces/nanotron/ultrascaleplaybook, 2025
work page 2025
-
[33]
J. Thorpe, P. Zhao, J. Eyolfson, Y . Qiao, Z. Jia, M. Zhang, R. Netravali, and G. H. Xu. Bamboo: Making preemptible instances resilient for affordable training of large{DNNs}. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 497–513, 2023
work page 2023
-
[34]
B. Wan, M. Han, Y . Sheng, Y . Peng, H. Lin, M. Zhang, Z. Lai, M. Yu, J. Zhang, Z. Song, et al. {ByteCheckpoint}: A unified checkpointing system for large foundation model development. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25), pages 559–578, 2025
work page 2025
-
[35]
B. Wan, G. Liu, Z. Song, J. Wang, Y . Zhang, G. Sheng, S. Wang, H. Wei, C. Wang, W. Lou, et al. Robust llm training infrastructure at bytedance. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pages 186–203, 2025
work page 2025
- [36]
-
[37]
Z. Wang, Z. Jia, S. Zheng, Z. Zhang, X. Fu, T. E. Ng, and Y . Wang. Gemini: Fast failure recovery in distributed training with in-memory checkpoints. InProceedings of the 29th Symposium on Operating Systems Principles, pages 364–381, 2023
work page 2023
-
[38]
Z. Wang, Z. Liu, R. Zhang, A. Maurya, P. Hovland, B. Nicolae, F. Cappello, and Z. Zhang. Boost: Bottleneck-optimized scalable training framework for low-rank large language models. arXiv preprint arXiv:2512.12131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
- [40]
-
[41]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Y . Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023. A Additional Evaluations and Details This appendix provides additional evaluation details and the results for RECOVER-HSDP that cannot be inclu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.