Recognition: 2 theorem links
· Lean TheoremOptimal Representations for Generalized Contrastive Learning with Imbalanced Datasets
Pith reviewed 2026-05-13 02:27 UTC · model grok-4.3
The pith
For imbalanced contrastive learning, optimal representations collapse to class means with angles set by class proportions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
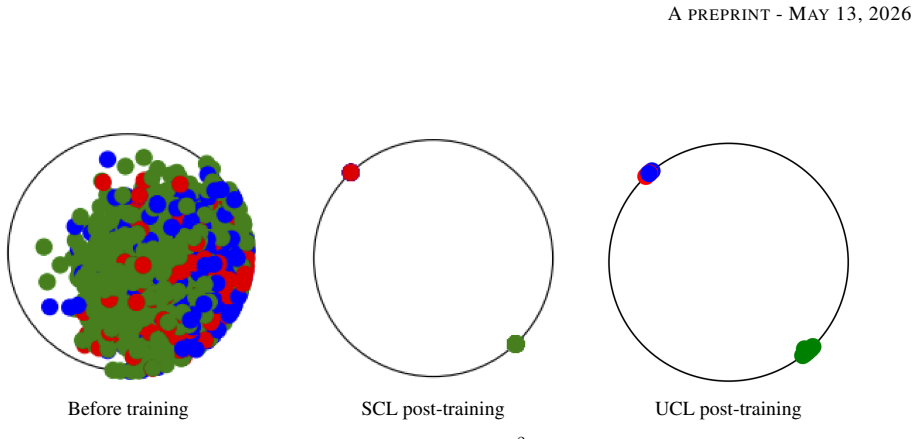
For a large, generalized family of contrastive learning losses, when the representation dimension is greater than the number of classes, the optimal representations of all samples from the same class collapse to their class means and their geometry exhibits an angular symmetry structure that is determined by the relative class proportions. In general, the geometry can be determined by solving a convex optimization problem. When class imbalance is extreme, contrastive learning exhibits minority collapse where all samples from the minority classes collapse into a single vector whenever the class imbalance exceeds a threshold depending on the loss and number of negative samples.
What carries the argument
The convex optimization problem whose solution gives the angular symmetry structure of the optimal class means under a generalized contrastive loss.
If this is right
- The geometry of optimal representations is obtained by solving a convex program for any loss in the family.
- Minority collapse occurs once the imbalance ratio surpasses a threshold fixed by the loss regularity and the number of negative samples.
- The balanced case recovers the known equiangular tight frame geometry as a special case.
- These predictions are confirmed by numerical simulations on imbalanced datasets.
Where Pith is reading between the lines
- Training procedures could incorporate the convex program as a regularizer to control the desired geometry.
- Investigating finite sample or non-converged training dynamics would reveal how close real models come to this optimal geometry.
- The minority collapse threshold offers a quantitative criterion for deciding when class reweighting or oversampling is required.
Load-bearing premise
The analysis assumes the loss function satisfies certain regularity conditions, the embedding dimension exceeds the number of classes, and training reaches the global optimum of the loss.
What would settle it
Train a contrastive model to convergence on a synthetic dataset with controlled class proportions, extract the empirical class means, and verify whether their inner products match the solution of the convex optimization and whether minority means coincide exactly above the predicted imbalance threshold.
Figures

read the original abstract
In this paper, we provide a computable characterization of the geometry of optimal representations in Contrastive Learning (CL) when the classes are imbalanced. When classes are balanced and the representation dimension is greater than the number of classes, it is well-known that the optimal representations exhibit Neural Collapse (NC), i.e., representations from the same class collapse to their class means and the class means form an Equiangular Tight Frame (ETF). For imbalanced classes and a large, generalized family of CL losses, we prove that the optimal representations of all samples from the same class collapse to their class means and their geometry exhibits an angular symmetry structure that is determined by the relative class proportions. In general, we show that the geometry can be determined by solving a convex optimization problem. Exploiting this symmetry structure, we analytically investigate a special case where class imbalance is extreme and prove that CL exhibits a phenomenon called Minority Collapse (MC) where all samples from the minority classes (classes with small probabilities) collapse into a single vector, whenever the class imbalance exceeds a threshold, which in turn depends on the regularity properties of the CL loss used and on the number of negative samples. Numerical results are provided to illustrate these phenomena and corroborate the theoretical results. We conclude by identifying a number of open problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for a generalized family of contrastive learning (CL) losses with imbalanced class proportions, the optimal representations exhibit within-class collapse to their class means, with the geometry of these means displaying an angular symmetry structure fully determined by the relative class proportions; this geometry is characterized as the solution to a convex optimization problem. In the extreme-imbalance regime, it further proves a 'Minority Collapse' (MC) phenomenon in which all minority-class samples collapse to a single vector once imbalance exceeds a threshold that depends on loss regularity properties and the number of negative samples. The results extend the balanced-case Neural Collapse (NC) geometry and are supported by numerical experiments.
Significance. If the stated regularity conditions on the loss family, the dimension assumption (d larger than the number of classes), and global optimality are satisfied, the work supplies a computable, convex characterization of optimal CL geometries under imbalance together with an explicit, falsifiable threshold for MC. These are concrete strengths: the reduction to a convex program and the analytic derivation of the MC threshold constitute parameter-free predictions that can be checked numerically, extending the NC literature in a precise way.
major comments (1)
- [§3 (symmetry characterization) and §4 (MC threshold)] The central proofs (likely §3–4) rely on the representation dimension being sufficiently large relative to the number of classes and on the optimizer attaining the global minimum of the loss; these assumptions are load-bearing for both the symmetry characterization and the MC threshold, yet the manuscript does not provide a quantitative lower bound on d or a verification that the convex program indeed corresponds to a global minimizer of the original non-convex CL objective.
minor comments (3)
- [Main theoretical section] The convex optimization problem that determines the angular geometry should be stated explicitly (including the objective and constraints) in the main text rather than deferred to an appendix, so that the dependence on class proportions is immediately visible.
- [Experimental section] Numerical experiments should report the precise CL loss (e.g., InfoNCE with temperature), the exact imbalance ratios, and the number of negative samples used, together with a direct comparison of the observed angles against the convex-program solution.
- [Introduction / §4] The term 'Minority Collapse' is introduced as a new phenomenon; a short paragraph contrasting it with standard NC and with other collapse notions in the literature would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and for highlighting the load-bearing assumptions in our proofs. We address the major comment below.
read point-by-point responses
-
Referee: [§3 (symmetry characterization) and §4 (MC threshold)] The central proofs (likely §3–4) rely on the representation dimension being sufficiently large relative to the number of classes and on the optimizer attaining the global minimum of the loss; these assumptions are load-bearing for both the symmetry characterization and the MC threshold, yet the manuscript does not provide a quantitative lower bound on d or a verification that the convex program indeed corresponds to a global minimizer of the original non-convex CL objective.
Authors: We agree that these assumptions are central. The proofs establish that any global minimizer must exhibit within-class collapse to class means whose angular geometry solves the stated convex program; the dimension assumption enters to ensure the means can realize arbitrary angles in the collapsed regime. We will revise the manuscript to explicitly state the quantitative lower bound d ≥ K (where K is the number of classes) and add a brief justification in §3, noting that this is the minimal dimension allowing the class means to span the necessary (K-1)-dimensional configuration without interference, consistent with the balanced NC case. Regarding global optimality, our results characterize the geometry attained at global minimizers of the non-convex loss rather than proving from scratch that the convex program's solution is always achieved; the reduction to the convex program follows after proving collapse must occur at optimality. A complete landscape analysis confirming attainment without further assumptions lies outside the current scope, though it is consistent with the numerical experiments. We will add a short discussion remark acknowledging this and listing it as an open question. revision: partial
Circularity Check
No circularity: derivation reduces to external class proportions and stated loss assumptions
full rationale
The central results characterize minimizers of a generalized family of contrastive losses by proving within-class collapse to means and reducing inter-class angular geometry to a convex program whose sole data-dependent inputs are the given class proportions together with explicit regularity conditions on the loss and the number of negative samples. The Minority Collapse threshold is obtained directly from the same symmetry analysis without any fitted parameters, self-referential definitions, or load-bearing self-citations. All steps are self-contained once the stated assumptions (sufficient representation dimension and global optimality) are granted; no equation or claim reduces by construction to a prior fitted quantity or to an unverified self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive loss functions belong to a generalized family possessing regularity properties that enable the collapse proofs.
invented entities (1)
-
Minority Collapse
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that the optimal representations of all samples from the same class collapse to their class means and their geometry exhibits an angular symmetry structure that is determined by the relative class proportions. In general, we show that the geometry can be determined by solving a convex optimization problem.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the lower bound is a strictly convex function of the Gram matrix whose entries are the pairwise inner products of unit-norm class mean feature vectors
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Transactions on Machine Learning Research , issn=
Hard-Negative Sampling for Contrastive Learning: Optimal Representation Geometry and Neural- vs Dimensional-Collapse , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
work page 2025
-
[2]
Transactions on Machine Learning Research , year=
Hard-Negative Sampling for Contrastive Learning: Optimal Representation Geometry and Neural-vs Dimensional-Collapse , author=. Transactions on Machine Learning Research , year=
-
[3]
arXiv preprint arXiv:2306.07960 , year=
Symmetric neural-collapse representations with supervised contrastive loss: The impact of relu and batching , author=. arXiv preprint arXiv:2306.07960 , year=
-
[4]
Proceedings of the National Academy of Sciences , volume=
Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training , author=. Proceedings of the National Academy of Sciences , volume=. 2021 , publisher=
work page 2021
-
[5]
International Conference on Machine Learning , pages=
Dissecting supervised contrastive learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[6]
Transactions on Machine Learning Research , issn=
Neural Collapse: A Review on Modelling Principles and Generalization , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
work page 2023
-
[7]
Proceedings of the 40th International Conference on Machine Learning , pages =
Neural Collapse in Deep Linear Networks: From Balanced to Imbalanced Data , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[8]
Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained
Dang, Hien and Huu, Tho Tran and Nguyen, Tan Minh and Ho, Nhat , booktitle =. Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained. 2024 , editor =
work page 2024
-
[9]
Symmetric Neural-Collapse Representations with Supervised Contrastive Loss: The Impact of Re
Ganesh Ramachandra Kini and Vala Vakilian and Tina Behnia and Jaidev Gill and Christos Thrampoulidis , booktitle=. Symmetric Neural-Collapse Representations with Supervised Contrastive Loss: The Impact of Re. 2024 , url=
work page 2024
-
[10]
Journal of Machine Learning Research , volume=
Neural collapse for unconstrained feature model under cross-entropy loss with imbalanced data , author=. Journal of Machine Learning Research , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Provable guarantees for self-supervised deep learning with spectral contrastive loss , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
2024 IEEE International Symposium on Information Theory (ISIT) , pages=
Supervised Contrastive Representation Learning: Landscape Analysis with Unconstrained Features , author=. 2024 IEEE International Symposium on Information Theory (ISIT) , pages=. 2024 , organization=
work page 2024
- [13]
- [14]
- [15]
-
[16]
Journal of Mathematical Sciences , volume=
Equiangular tight frames , author=. Journal of Mathematical Sciences , volume=. 2009 , publisher=
work page 2009
-
[17]
Nguyen, Thuan and Jiang, Ruijie and Aeron, Shuchin and Ishwar, Prakash and Brown, D. Richard , booktitle=. On Neural Collapse in Contrastive Learning with Imbalanced Datasets , year=
- [18]
-
[19]
When hard negative sampling meets supervised contrastive learning , author=. 2023 , eprint=
work page 2023
-
[20]
International Conference on Learning Representations , year=
Contrastive Learning with Hard Negative Samples , author=. International Conference on Learning Representations , year=
-
[21]
Advances in neural information processing systems , volume=
Neural collapse with normalized features: A geometric analysis over the riemannian manifold , author=. Advances in neural information processing systems , volume=
-
[22]
arXiv preprint arXiv:2010.02037 , year=
Conditional negative sampling for contrastive learning of visual representations , author=. arXiv preprint arXiv:2010.02037 , year=
-
[23]
International Conference on Learning Representations , year=
Understanding Dimensional Collapse in Contrastive Self-supervised Learning , author=. International Conference on Learning Representations , year=
-
[24]
The Eleventh International Conference on Learning Representations , year=
On the duality between contrastive and non-contrastive self-supervised learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[25]
A cookbook of self-supervised learning.arXiv preprint arXiv:2304.12210, 2023
A cookbook of self-supervised learning , author=. arXiv preprint arXiv:2304.12210 , year=
-
[26]
arXiv preprint arXiv:2302.07920 , year=
InfoNCE Loss Provably Learns Cluster-Preserving Representations , author=. arXiv preprint arXiv:2302.07920 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Understanding deep contrastive learning via coordinate-wise optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
The Eleventh International Conference on Learning Representations , year=
Generalizing and Decoupling Neural Collapse via Hyperspherical Uniformity Gap , author=. The Eleventh International Conference on Learning Representations , year=
-
[29]
The Journal of Machine Learning Research , volume=
Contrastive estimation reveals topic posterior information to linear models , author=. The Journal of Machine Learning Research , volume=. 2021 , publisher=
work page 2021
-
[30]
Advances in Neural Information Processing Systems , volume=
Predicting what you already know helps: Provable self-supervised learning , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
International Conference on Machine Learning , pages=
Toward understanding the feature learning process of self-supervised contrastive learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[32]
International Conference on Learning Representations , year=
Chaos is a Ladder: A New Theoretical Understanding of Contrastive Learning via Augmentation Overlap , author=. International Conference on Learning Representations , year=
-
[33]
The Eleventh International Conference on Learning Representations , year=
What shapes the loss landscape of self supervised learning? , author=. The Eleventh International Conference on Learning Representations , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Are all losses created equal: A neural collapse perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
International Conference on Machine Learning , pages=
On the optimization landscape of neural collapse under mse loss: Global optimality with unconstrained features , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[36]
ACM Computing Surveys , volume=
A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned, and Perspectives , author=. ACM Computing Surveys , volume=. 2023 , publisher=
work page 2023
-
[37]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Unsupervised feature learning via non-parametric instance discrimination , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[38]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep metric learning via lifted structured feature embedding , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[39]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Exploring simple siamese representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
ICLR 2022-International Conference on Learning Representations , year=
VICReg: Variance-Invariance-Covariance Regularization For Self-Supervised Learning , author=. ICLR 2022-International Conference on Learning Representations , year=
work page 2022
-
[42]
International Conference on Machine Learning , pages=
On variational bounds of mutual information , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[43]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Facenet: A unified embedding for face recognition and clustering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[44]
Proceedings of the IEEE international conference on computer vision , pages=
Hard-aware deeply cascaded embedding , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[45]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Sampling matters in deep embedding learning , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[46]
Advances in Neural Information Processing Systems , volume=
Supervised contrastive learning , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
A Theoretical Analysis of Contrastive Unsupervised Representation Learning
A theoretical analysis of contrastive unsupervised representation learning , author=. arXiv preprint arXiv:1902.09229 , year=
work page Pith review arXiv 1902
-
[48]
arXiv preprint arXiv:2112.11450 , year=
Max-Margin Contrastive Learning , author=. arXiv preprint arXiv:2112.11450 , year=
-
[49]
arXiv preprint arXiv:2206.01197 , year=
Hard Negative Sampling Strategies for Contrastive Representation Learning , author=. arXiv preprint arXiv:2206.01197 , year=
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ContrastNet: A Contrastive Learning Framework for Few-Shot Text Classification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[51]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Improved text classification via contrastive adversarial training , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[52]
International Conference on Machine Learning , pages=
Utilizing Expert Features for Contrastive Learning of Time-Series Representations , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[53]
arXiv preprint arXiv:2102.12982 , year=
A primer on contrastive pretraining in language processing: Methods, lessons learned and perspectives , author=. arXiv preprint arXiv:2102.12982 , year=
-
[54]
Machine Learning for Health , pages=
Contrastive representation learning for electroencephalogram classification , author=. Machine Learning for Health , pages=. 2020 , organization=
work page 2020
-
[55]
Advances in Neural Information Processing Systems , volume=
Hard negative mixing for contrastive learning , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Contrastive and generative graph convolutional networks for graph-based semi-supervised learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Enhancing unsupervised video representation learning by decoupling the scene and the motion , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[58]
A survey on contrastive self-supervised learning , author=. Technologies , volume=. 2020 , publisher=
work page 2020
-
[59]
arXiv preprint arXiv:2206.04041 , year=
Neural collapse: A review on modelling principles and generalization , author=. arXiv preprint arXiv:2206.04041 , year=
-
[60]
arXiv preprint arXiv:2301.00437 , year=
Neural collapse in deep linear network: From balanced to imbalanced data , author=. arXiv preprint arXiv:2301.00437 , year=
-
[61]
Proceedings of the National Academy of Sciences , volume=
Prevalence of neural collapse during the terminal phase of deep learning training , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
work page 2020
-
[62]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[63]
International Conference on Machine Learning , pages=
Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained ReLU Features Model , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[64]
International Conference on Machine Learning , pages=
Understanding contrastive representation learning through alignment and uniformity on the hypersphere , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[65]
CVX: Matlab software for disciplined convex programming, version 2.1 , author=
-
[66]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Contrastive clustering , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[67]
arXiv preprint arXiv:2202.04298 , volume=
Image difference captioning with pre-training and contrastive learning , author=. arXiv preprint arXiv:2202.04298 , volume=
- [68]
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Semantically contrastive learning for low-light image enhancement , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Autogcl: Automated graph contrastive learning via learnable view generators , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
SAIL: Self-Augmented Graph Contrastive Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[72]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A simple and effective self-supervised contrastive learning framework for aspect detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[73]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Accelerating Ecological Sciences from Above: Spatial Contrastive Learning for Remote Sensing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[74]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Contrastive spatio-temporal pretext learning for self-supervised video representation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[75]
Simple unsupervised graph representation learning , author=. 2022 , organization=
work page 2022
-
[76]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Deepchannel: Salience estimation by contrastive learning for extractive document summarization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[77]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Motif-driven contrastive learning of graph representations , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[78]
Proceedings of the AAAI conference on artificial intelligence , volume=
Contrastive triple extraction with generative transformer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[79]
International conference on machine learning , pages=
Data-efficient image recognition with contrastive predictive coding , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[80]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Improving generalization via scalable neighborhood component analysis , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.