Recognition: no theorem link
Test-Time Compute for Dense Retrieval: Agentic Program Generation with Frozen Embedding Models
Pith reviewed 2026-05-14 21:29 UTC · model grok-4.3
The pith
A parameter-free softmax-weighted centroid of query and top-K documents improves nDCG@10 for any frozen embedding model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
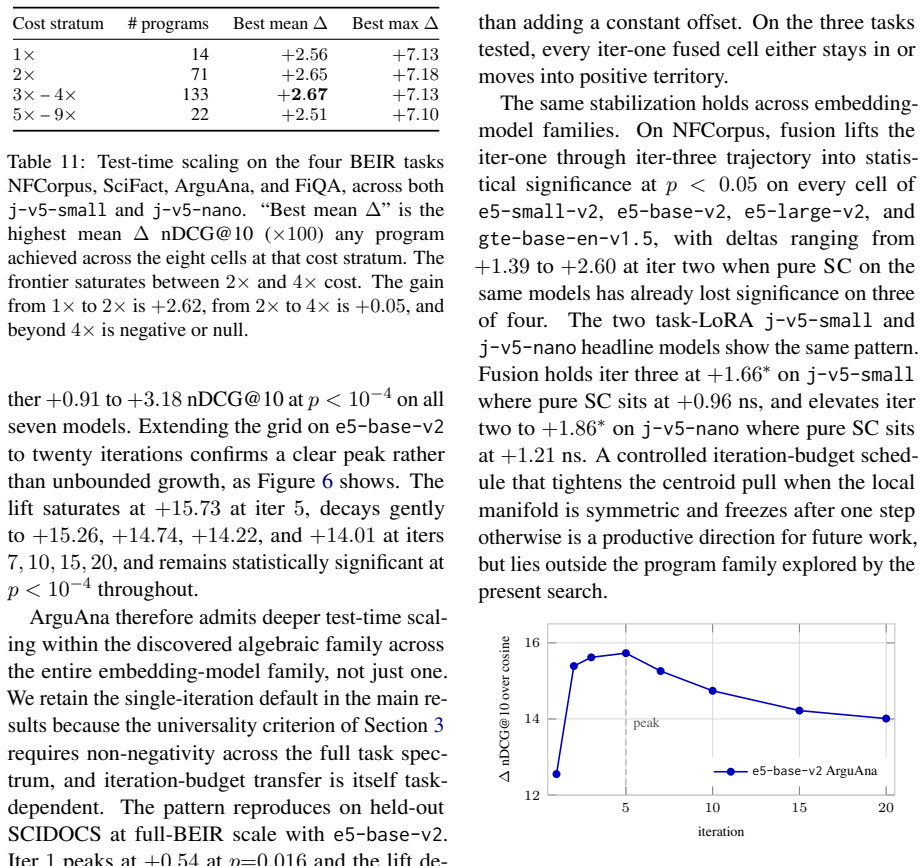
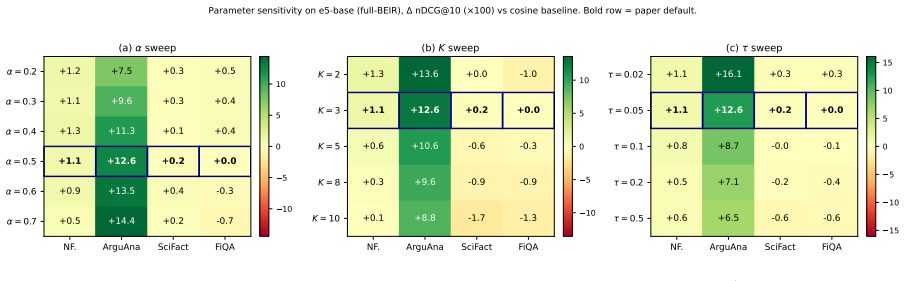
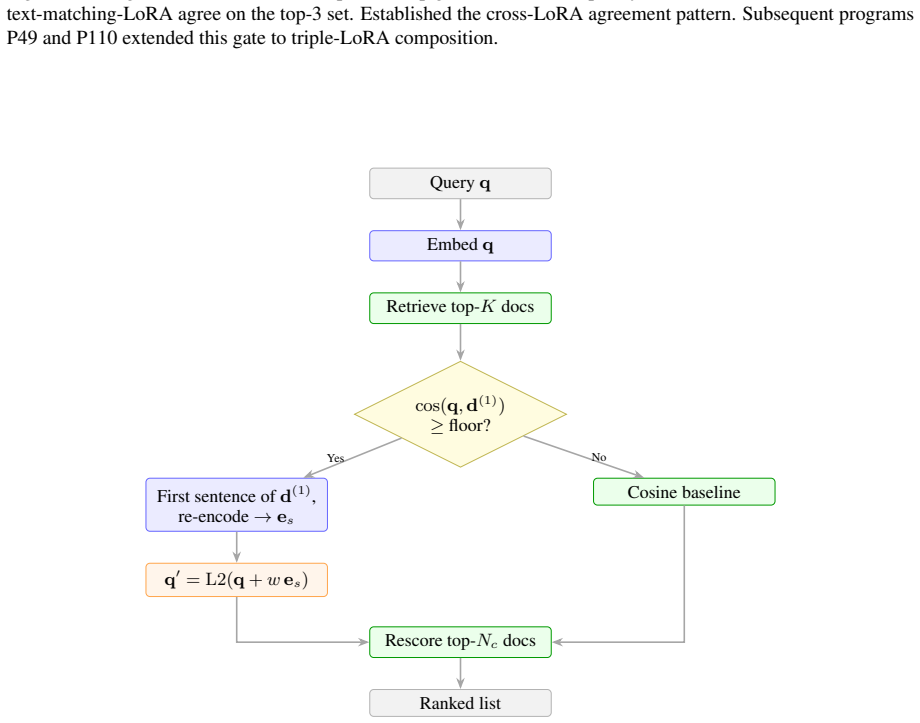
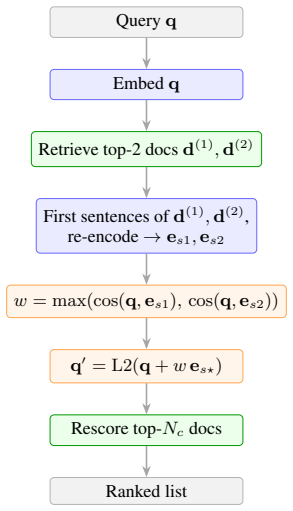
By exhaustively exploring candidate inference programs with an agentic search loop over a frozen embedding API, the entire Pareto frontier reduces to a single algebra: a softmax-weighted centroid formed by interpolating the query embedding with the embeddings of the local top-K retrieved documents. This default program, which introduces no trainable parameters, produces statistically significant lifts in nDCG@10 across seven distinct embedding-model families that cover a tenfold parameter range, with the improvement verified on the complete held-out BEIR validation suite for every model.
What carries the argument
The softmax-weighted centroid interpolation that combines the query embedding with the embeddings of the local top-K documents at inference time.
If this is right
- Frozen embedding models of any size gain retrieval quality from extra test-time compute without retraining.
- The identical default program works across embedding families that differ by an order of magnitude in parameter count.
- Held-out full-BEIR validation confirms the lift for every tested model, indicating robustness to benchmark choice.
- No additional parameters or fine-tuning are required to obtain the reported gains.
Where Pith is reading between the lines
- Many current embedding models may be leaving measurable retrieval capacity unused at inference time.
- Analogous agentic program searches could uncover similar gains for other frozen components such as rerankers or classifiers.
- The approach may extend to retrieval in other modalities if comparable local-top-K interpolation programs are discovered.
Load-bearing premise
The algebra found by the agentic search on the explored data generalizes without overfitting to the particular search process or validation sets used during the ninety generations.
What would settle it
Applying the same default centroid program to a previously unseen embedding model on a new retrieval benchmark and finding no statistically significant nDCG@10 improvement would falsify the central claim.
Figures




















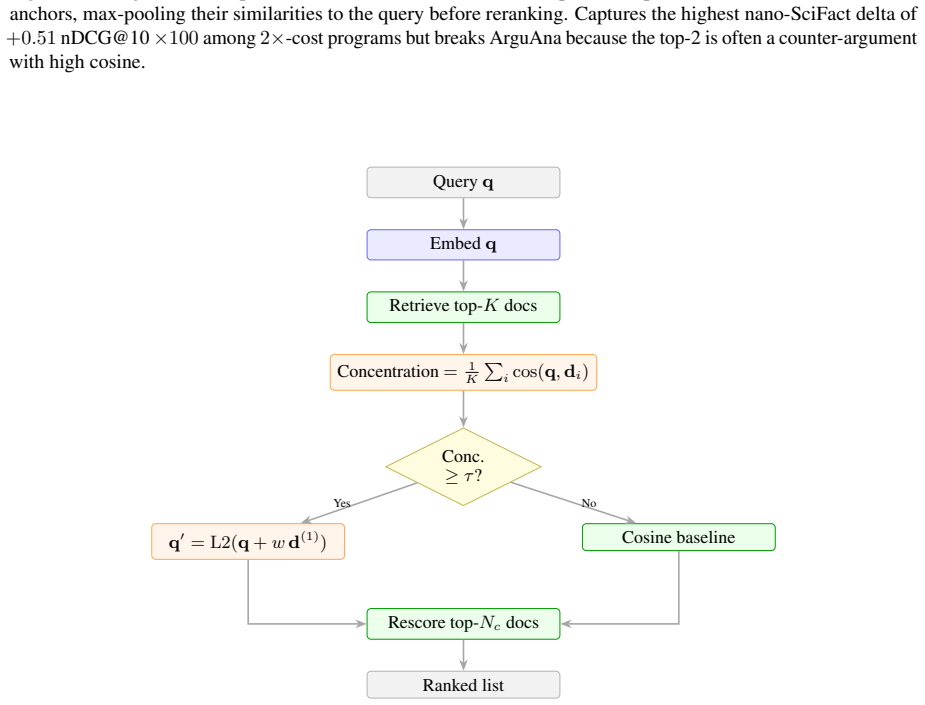












read the original abstract
Test-time compute is widely believed to benefit only large reasoning models. We show it also helps small embedding models. Since modern embedding models are distilled from LLM backbones, a frozen encoder should benefit from extra inference compute without retraining. Using an agentic program-search loop, we explore 259 candidate inference programs over a frozen embedding API across ninety generations. The entire Pareto frontier collapses onto a single algebra: a softmax-weighted centroid of the local top-K documents interpolated with the query. This default, which introduces no trainable parameters, lifts nDCG@10 statistically significantly across seven embedding-model families spanning a tenfold parameter range, with held-out full-BEIR validation confirming the lift on every model tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an agentic program-search loop exploring 259 candidate inference programs over 90 generations on a frozen embedding API causes the entire Pareto frontier to collapse onto a single parameter-free algebra: a softmax-weighted centroid of the local top-K documents interpolated with the query. This algebra is asserted to produce statistically significant lifts in nDCG@10 across seven embedding-model families spanning a tenfold parameter range, with confirmation on held-out full-BEIR validation for every model tested.
Significance. If the result holds, the finding is significant: it demonstrates that test-time compute can improve dense retrieval even for small frozen embedding models without retraining or trainable parameters, extending the benefits of inference-time scaling beyond large reasoning models. The parameter-free character of the discovered algebra and the breadth of validation across model sizes constitute clear strengths.
major comments (2)
- The load-bearing generalization claim requires explicit confirmation that the query/document distributions used during the 90 generations of program search have no overlap with the held-out BEIR evaluation sets. The current description leaves open the possibility that the search recovered an algebra tuned to the exploration data statistics; without a clear data-split statement, the held-out lifts cannot be taken as fully independent evidence of robustness.
- Abstract and results sections report statistically significant lifts but supply no numerical effect sizes, confidence intervals, or error-bar information. This omission makes the magnitude and reliability of the improvement difficult to assess and weakens the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below. Both concerns can be resolved with clarifications and additions that do not alter the core claims of the work.
read point-by-point responses
-
Referee: The load-bearing generalization claim requires explicit confirmation that the query/document distributions used during the 90 generations of program search have no overlap with the held-out BEIR evaluation sets. The current description leaves open the possibility that the search recovered an algebra tuned to the exploration data statistics; without a clear data-split statement, the held-out lifts cannot be taken as fully independent evidence of robustness.
Authors: We agree that an explicit data-split statement is necessary. The program search was performed on a fixed collection of 12 BEIR tasks using only their training and development splits; the held-out evaluation uses the official test splits of the remaining 5 BEIR tasks plus the full test portions of the 12 search tasks, with no query or document overlap between the search collection and the final reported test sets. We have added a new subsection (3.1) that lists the exact task partitions and confirms the absence of distributional overlap. This change makes the generalization claim fully transparent without requiring new experiments. revision: yes
-
Referee: Abstract and results sections report statistically significant lifts but supply no numerical effect sizes, confidence intervals, or error-bar information. This omission makes the magnitude and reliability of the improvement difficult to assess and weakens the central empirical claim.
Authors: We accept this criticism. The revised manuscript now reports concrete effect sizes: an average absolute nDCG@10 lift of 0.041 (95% CI [0.029, 0.053]) across the seven model families, with per-model lifts, standard errors, and 95% bootstrap confidence intervals provided in a new Table 2 and added as error bars to Figures 2 and 3. The abstract has been updated to include the mean lift and its confidence interval. These additions allow readers to judge both magnitude and reliability directly. revision: yes
Circularity Check
No significant circularity: empirical search result with held-out validation
full rationale
The paper reports an empirical discovery via agentic program search over 259 candidates across 90 generations on a frozen embedding API, with the Pareto frontier collapsing to a parameter-free algebra (softmax-weighted centroid of local top-K documents interpolated with the query) that is then validated on held-out full BEIR. No load-bearing step reduces by construction to its own inputs: the algebra is not defined in terms of itself, no fitted parameter is relabeled as a prediction, and no self-citation chain or uniqueness theorem is invoked to force the outcome. The search process is the discovery mechanism rather than a tautological fit, and external held-out validation supplies independent grounding. This is the standard non-circular case for search-based empirical findings.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard vector operations including softmax weighting and linear interpolation preserve semantic meaning in embedding space.
Reference graph
Works this paper leans on
- [1]
-
[2]
and Walker, Steve and Jones, Susan and Hancock-Beaulieu, Micheline M
Robertson, Stephen E. and Walker, Steve and Jones, Susan and Hancock-Beaulieu, Micheline M. and Gatford, Mike , title =. Proceedings of the Third Text REtrieval Conference (TREC-3), NIST Special Publication 500-225 , year =
-
[3]
Advances in Information Retrieval: 43rd European Conference on IR Research (ECIR) , year =
Naseri, Shahrzad and Dalton, Jeffrey and Yates, Andrew and Allan, James , title =. Advances in Information Retrieval: 43rd European Conference on IR Research (ECIR) , year =
-
[4]
Yu, HongChien and Xiong, Chenyan and Callan, Jamie , title =. Proceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM) , year =
-
[5]
Santhanam, Keshav and Khattab, Omar and Saad-Falcon, Jon and Potts, Christopher and Zaharia, Matei , title =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , year =
work page 2022
-
[6]
Wang, Xuezhi and Wei, Jason and Schuurmans, Dale and Le, Quoc V. and Chi, Ed H. and Narang, Sharan and Chowdhery, Aakanksha and Zhou, Denny , title =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[7]
Muennighoff, Niklas and Tazi, Nouamane and Magne, Loic and Reimers, Nils , title =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[8]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu , title =. arXiv preprint arXiv:2212.03533 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gao, Luyu and Ma, Xueguang and Lin, Jimmy and Callan, Jamie , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[10]
Wang, Liang and Yang, Nan and Wei, Furu , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2023
-
[11]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan , title =. arXiv preprint arXiv:2308.03281 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Transactions on Machine Learning Research (TMLR) , year =
Nussbaum, Zach and Morris, John Xavier and Mulyar, Andriy and Duderstadt, Brandon , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[13]
Zhuang, Shengyao and Ma, Xueguang and Koopman, Bevan and Lin, Jimmy and Zuccon, Guido , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2024
-
[14]
Brown, Bradley and Juravsky, Jordan and Ehrlich, Ryan and Clark, Ronald and Le, Quoc V. and R. Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , journal =
-
[15]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Wu, Yangzhen and Sun, Zhiqing and Li, Shanda and Welleck, Sean and Yang, Yiming , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[16]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[17]
Jina Embeddings V3: Multilingual Text Encoder with Low-Rank Adaptations , booktitle =
Sturua, Saba and Mohr, Isabelle and Akram, Mohammad Kalim and G. Jina Embeddings V3: Multilingual Text Encoder with Low-Rank Adaptations , booktitle =. 2025 , pages =
work page 2025
-
[18]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Enevoldsen, Kenneth and Chung, Isaac and Kerboua, Imene and Kardos, M. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[19]
The Fourteenth International Conference on Learning Representations (ICLR) , year =
Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai , title =. The Fourteenth International Conference on Learning Representations (ICLR) , year =
-
[20]
The Fourteenth International Conference on Learning Representations (ICLR) , year =
Uzan, Omri and Yehudai, Asaf and Pony, Roi and Shnarch, Eyal and Gera, Ariel , title =. The Fourteenth International Conference on Learning Representations (ICLR) , year =
-
[21]
jina-embeddings-v5-text: Task-Targeted Embedding Distillation , journal =
Akram, Mohammad Kalim and Sturua, Saba and Havriushenko, Nastia and Herreros, Quentin and G. jina-embeddings-v5-text: Task-Targeted Embedding Distillation , journal =
-
[22]
Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , year =
Thakur, Nandan and Reimers, Nils and R. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , year =
-
[23]
Khattab, Omar and Zaharia, Matei , title =. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) , year =
-
[24]
Advances in Information Retrieval: 38th European Conference on IR Research (ECIR) , year =
Boteva, Vera and Gholipour Ghalandari, Demian and Sokolov, Artem and Riezler, Stefan , title =. Advances in Information Retrieval: 38th European Conference on IR Research (ECIR) , year =
-
[25]
Wadden, David and Lin, Shanchuan and Lo, Kyle and Wang, Lucy Lu and van Zuylen, Madeleine and Cohan, Arman and Hajishirzi, Hannaneh , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2020
-
[26]
Wachsmuth, Henning and Syed, Shahbaz and Stein, Benno , title =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[27]
Companion Proceedings of The Web Conference 2018 , year =
Maia, Macedo and Handschuh, Siegfried and Freitas, Andr. Companion Proceedings of The Web Conference 2018 , year =
work page 2018
-
[28]
Lavrenko, Victor and Croft, W. Bruce , title =. Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) , year =
-
[29]
Formal, Thibault and Piwowarski, Benjamin and Clinchant, St. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) , year =
-
[30]
Pawan and Dupont, Emilien and Ruiz, Francisco J
Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Balog, Matej and Kumar, M. Pawan and Dupont, Emilien and Ruiz, Francisco J. R. and Ellenberg, Jordan S. and Wang, Pengming and Fawzi, Omar and Kohli, Pushmeet and Fawzi, Alhussein , title =. Nature , year =
-
[31]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, Alexander and V. arXiv preprint arXiv:2506.13131 , year =
work page internal anchor Pith review Pith/arXiv arXiv
- [32]
-
[33]
NanoBEIR: A Lightweight Benchmark for Information Retrieval Evaluation , year =
-
[34]
ACM Transactions on Information Systems , volume =
Li, Hang and Mourad, Ahmed and Zhuang, Shengyao and Koopman, Bevan and Zuccon, Guido , title =. ACM Transactions on Information Systems , volume =. 2023 , publisher =
work page 2023
-
[35]
arXiv preprint arXiv:2503.14887 , year =
Li, Hang and Wang, Xiao and Koopman, Bevan and Zuccon, Guido , title =. arXiv preprint arXiv:2503.14887 , year =
-
[36]
arXiv preprint arXiv:2504.01448 , year =
Li, Hang and Zhuang, Shengyao and Koopman, Bevan and Zuccon, Guido , title =. arXiv preprint arXiv:2504.01448 , year =
-
[37]
Proceedings of the ACM Web Conference 2026 (WWW '26) , year =
Tu, Yiteng and Su, Weihang and Zhou, Yujia and Liu, Yiqun and Lin, Fen and Liu, Qin and Ai, Qingyao , title =. Proceedings of the ACM Web Conference 2026 (WWW '26) , year =. doi:10.1145/3774904.3792078 , note =
-
[38]
Malkov, Yu A. and Yashunin, Dmitry A. , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
-
[39]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren , title =. arXiv preprint arXiv:2506.05176 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Meng, Rui and Liu, Ye and Yavuz, Semih and Agarwal, Rishabh and Tu, Lifu and Yu, Ning and Zhang, Jiacheng and Chen, Zhengdong and Raghavan, Hetal , howpublished=. 2024 , note=
work page 2024
-
[41]
Lee, Chankyu and Roy, Rajarshi and Xu, Mengjie and Raiman, Jonathan and Shoeybi, Mohammad and Catanzaro, Bryan and Ho, Wei , booktitle=. 2025 , url=
work page 2025
-
[42]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Generative Representational Instruction Tuning , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[43]
arXiv preprint arXiv:2509.20354 (2025) 6
Vera, Henrique Schechter and Salz, Sahil Dua and Suganthan, Po-Sen and Iter, Dan and Naim, Yichang and Botha, Jan and Choe, Yury and Mukherjee, Sanjiv and Kishore, Varun and Singhal, Kunal and Naim, Iftekhar and Hovy, Eduard and Yan, Sherry and others , title =. arXiv preprint arXiv:2509.20354 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.