Recognition: no theorem link
Predictive Maps of Multi-Agent Reasoning: A Successor-Representation Spectrum for LLM Communication Topologies
Pith reviewed 2026-05-15 06:03 UTC · model grok-4.3
The pith
Spectral properties of successor representations rank multi-agent LLM communication topologies by robustness and error accumulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
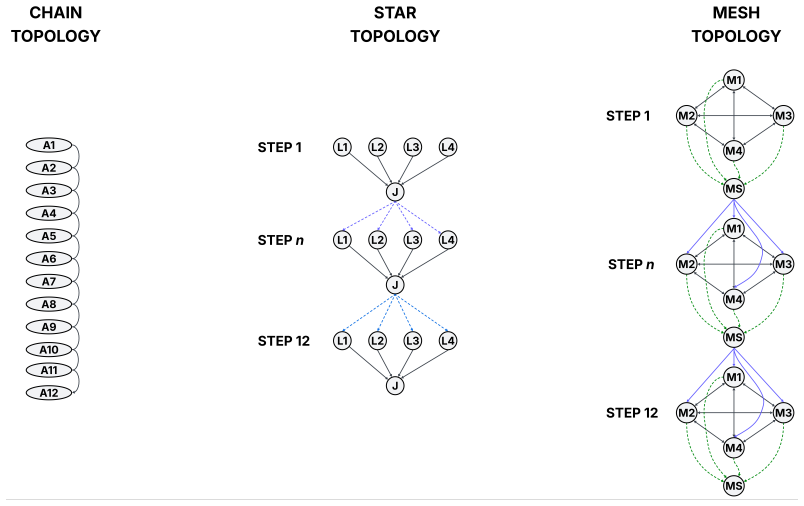
We introduce a structural diagnostic for multi-agent LLM communication graphs based on the successor representation M = (I - γ P)^{-1} of the row-stochastic communication operator, and we connect three of its spectral quantities, the spectral radius ρ(M), the spectral gap Δ(M), and the condition number κ(M), to three distinct failure modes. We derive closed-form spectra for the chain, star, and mesh under row-stochastic normalization, and validate the predictions on a 12-step structured state-tracking task with Qwen2.5-7B-Instruct over 100 independent trials. The condition number is a perfect rank-order predictor of empirical perturbation robustness (r_s = 1.0); the spectral gap partially 0.
What carries the argument
the successor representation M = (I - γ P)^{-1} of the row-stochastic communication operator, which converts graph structure into predicted long-term occupancy measures used to diagnose robustness, consensus speed, and error growth
If this is right
- Topologies ordered by increasing condition number will exhibit strictly increasing sensitivity to input perturbations in LLM message passing.
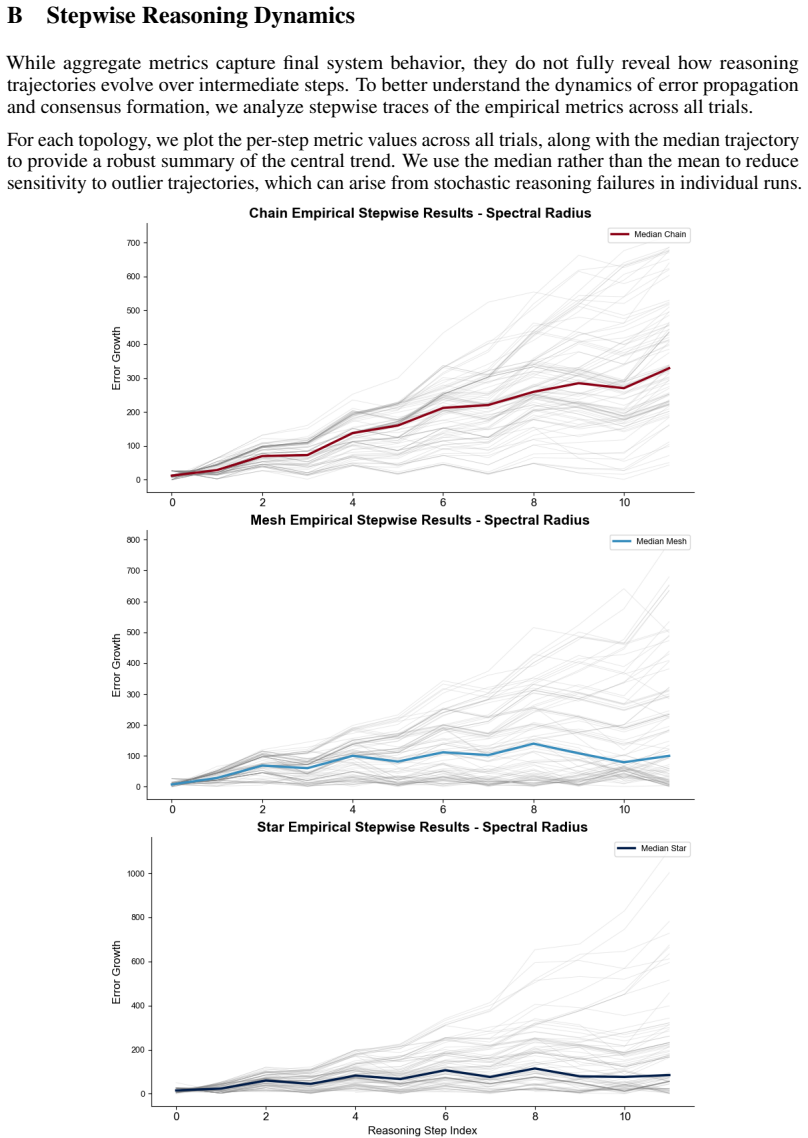
- Graphs with larger spectral radii will produce lower total accumulated deviation across repeated reasoning steps.
- Spectral-gap values supply a partial ordering on how rapidly agent states converge to a shared distribution.
- Closed-form spectrum calculations allow direct comparison of arbitrary new topologies without running agent simulations.
- An affine-noise correction to the linear map restores correct ordering when bias drift violates the pure contraction assumption.
Where Pith is reading between the lines
- The same spectral quantities could be used to search over larger families of hybrid topologies for ones that simultaneously minimize condition number and control spectral radius.
- The diagnostic might extend to settings where communication edges are added or removed dynamically during a run, by updating the operator matrix on the fly.
- If the linear approximation proves insufficient for open-ended tasks, the affine extension already sketched in the paper could be made the default predictive map.
- The framework suggests treating topology selection as an optimization problem over the space of row-stochastic matrices with prescribed spectral targets.
Load-bearing premise
That the linear successor representation of a row-stochastic communication operator captures the actual reasoning dynamics, bias drift, and error propagation of LLMs in multi-agent interaction.
What would settle it
Repeating the 12-step state-tracking trials with a different base model or introducing explicit non-linear bias terms and checking whether the reported perfect rank correlations for condition number and spectral radius remain intact.
Figures



read the original abstract
Practitioners deploying multi-agent large language model (LLM) systems must currently choose between communication topologies such as chain, star, mesh, and richer variants without any pre-inference diagnostic for which topology will amplify drift, converge to consensus, or remain robust under perturbation. Existing evaluation answers these questions only post hoc and only for the task measured. We introduce a structural diagnostic for multi-agent LLM communication graphs based on the successor representation $M = (I - \gamma P)^{-1}$ of the row-stochastic communication operator, and we connect three of its spectral quantities, the spectral radius $\rho(M)$, the spectral gap $\Delta(M)$, and the condition number $\kappa(M)$, to three distinct failure modes. We derive closed-form spectra for the chain, star, and mesh under row-stochastic normalization, and validate the predictions on a 12-step structured state-tracking task with Qwen2.5-7B-Instruct over 100 independent trials. The condition number is a perfect rank-order predictor of empirical perturbation robustness ($r_s = 1.0$); the spectral gap partially predicts consensus dynamics ($r_s = 0.5$); and the spectral radius is perfectly \emph{inverted} with respect to cumulative error ($r_s = -1.0$). We trace this inversion to a regime in which linear spectra are blind to non-contracting bias drift, and we propose an affine-noise extension of the predictive map that recovers the empirical ordering. We read this as a first step toward representational, drift-aware structural diagnostics for multi-agent LLM systems, sitting alongside classical spectral and consensus theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a successor-representation-based spectral diagnostic for multi-agent LLM communication topologies, deriving closed-form spectra for chain, star, and mesh graphs from the matrix M = (I - γP)^{-1} and linking the spectral radius, gap, and condition number to error accumulation, consensus, and perturbation robustness. It validates these on a state-tracking task with Qwen2.5-7B-Instruct, reporting perfect Spearman rank correlations (rs=1.0 for condition number with robustness, rs=-1.0 inverted for spectral radius with error) and proposes an affine-noise extension to resolve the observed inversion in the linear model.
Significance. If the spectral quantities can be shown to predict LLM dynamics beyond the current setup, the work would supply a useful pre-inference structural tool for topology selection that complements classical consensus theory. The closed-form derivations for the three topologies and the explicit mapping to failure modes are positive features, yet the small sample and post-hoc extension reduce the immediate strength of the central claim.
major comments (3)
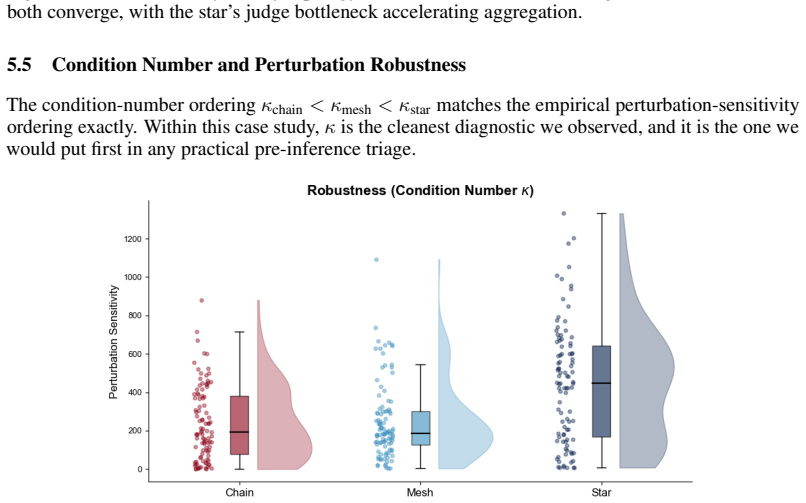
- [Validation] Validation section: with exactly three topologies (chain, star, mesh), the reported Spearman correlations of rs=1.0 and rs=-1.0 are uninformative because any monotonic ordering of three items necessarily produces |rs|=1.0; this provides no statistical evidence that the spectral quantities are generally predictive.
- [Spectral analysis] Spectral analysis (abstract and results): the linear successor representation M=(I-γP)^{-1} inverts the spectral-radius ordering relative to observed cumulative error, requiring an affine-noise extension whose parameters are not derived from the original linear model; this indicates a gap in the core mapping from linear spectra to LLM error propagation and bias drift.
- [Introduction and validation] Core modeling assumption (introduction and validation): the claim that the linear successor representation captures actual reasoning dynamics rests on the three-topology experiment, but the necessity of the ad-hoc extension to recover empirical orderings shows that the base model does not reliably predict the tested failure modes.
minor comments (2)
- [Methods] Clarify the precise definition and numerical value of γ used in the closed-form spectra and in the empirical trials.
- [Results] Add explicit equations for the affine-noise extension so readers can reproduce the adjusted predictions.
Simulated Author's Rebuttal
We thank the referee for the constructive critique. We agree that the small number of topologies limits the strength of the reported correlations and that the affine extension highlights an incompleteness in the linear model. We will revise the manuscript to address these points explicitly while preserving the closed-form derivations and the observed orderings as the core contribution.
read point-by-point responses
-
Referee: [Validation] Validation section: with exactly three topologies (chain, star, mesh), the reported Spearman correlations of rs=1.0 and rs=-1.0 are uninformative because any monotonic ordering of three items necessarily produces |rs|=1.0; this provides no statistical evidence that the spectral quantities are generally predictive.
Authors: We fully agree that a Spearman correlation of ±1.0 is guaranteed for any consistent ordering of three items and therefore supplies no statistical evidence of general predictiveness. The substantive observation in the manuscript is that the closed-form spectral predictions for the three topologies produce exactly the same ordering as the empirical measurements of robustness and error. In the revised version we will remove any implication of statistical generality, explicitly note the n=3 limitation, and present the result as a descriptive match between theory and experiment on these topologies. revision: yes
-
Referee: [Spectral analysis] Spectral analysis (abstract and results): the linear successor representation M=(I-γP)^{-1} inverts the spectral-radius ordering relative to observed cumulative error, requiring an affine-noise extension whose parameters are not derived from the original linear model; this indicates a gap in the core mapping from linear spectra to LLM error propagation and bias drift.
Authors: The manuscript already records the inversion and attributes it to non-contracting bias drift that lies outside the linear contraction assumption. The affine-noise extension is offered as an empirical correction that restores the observed ordering. We accept that its parameters are not derived from the linear model and therefore constitute a gap in the theoretical mapping. The revision will expand the discussion of this gap, present the extension more clearly as a post-hoc adjustment, and add a brief analysis of how the affine term relates to the empirical bias observed in the LLM responses. revision: partial
-
Referee: [Introduction and validation] Core modeling assumption (introduction and validation): the claim that the linear successor representation captures actual reasoning dynamics rests on the three-topology experiment, but the necessity of the ad-hoc extension to recover empirical orderings shows that the base model does not reliably predict the tested failure modes.
Authors: We agree that the requirement for the extension demonstrates that the base linear model does not fully predict the error-accumulation behavior in the tested LLM setting. The paper already frames the linear spectra as providing partial predictions (condition number for robustness, spectral gap for consensus) while requiring adjustment for cumulative error. In revision we will strengthen the cautious language in the introduction and validation sections, explicitly state the scope of the linear model, and position the affine extension as evidence of the need for further modeling rather than as a complete solution. revision: yes
Circularity Check
No significant circularity; derivation is mathematically self-contained
full rationale
The paper derives closed-form spectra for the successor representation M = (I - γP)^{-1} on the chain, star, and mesh topologies via direct application of linear algebra to the row-stochastic communication operator P. These spectral quantities (ρ(M), Δ(M), κ(M)) are computed independently from the graph structure and then compared post hoc to empirical LLM outcomes on the same three topologies. While the perfect Spearman correlations (rs = ±1.0) are statistically uninformative for n=3, this does not render the derivation circular: the spectra are not fitted to the error or robustness data, nor do they reduce to those data by construction. The affine-noise extension is explicitly introduced as a post-hoc adjustment to explain an observed inversion and is not part of the core linear derivation. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing premises. The chain from graph operator to spectral predictions remains independent of the experimental results.
Axiom & Free-Parameter Ledger
free parameters (1)
- gamma
axioms (1)
- domain assumption Communication operator P is row-stochastic
Reference graph
Works this paper leans on
-
[1]
Kimberly L. Stachenfeld, Matthew M. Botvinick, and Samuel J. Gershman. The hippocampus as a predictive map.Nature Neuroscience, 20(11):1643–1653, 2017
work page 2017
-
[2]
Ida Momennejad, Evan M. Russek, Jin H. Cheong, Matthew M. Botvinick, Nathaniel D. Daw, and Samuel J. Gershman. The successor representation in human reinforcement learning.Nature Human Behaviour, 1(9):680–692, 2017
work page 2017
-
[3]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[4]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models. InAAAI Conference on Artificial Intelligence, 2024
work page 2024
-
[5]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed H. Awadallah, Ryen W. White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V . Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges.arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representatio...
work page 2024
-
[10]
Holistic evaluation of language models.Transactions on Machine Learning Research (TMLR), 2023
Percy Liang et al. Holistic evaluation of language models.Transactions on Machine Learning Research (TMLR), 2023
work page 2023
-
[11]
Aarohi Srivastava et al. Beyond the imitation game: Quantifying and extrapolating the capabili- ties of language models.Transactions on Machine Learning Research (TMLR), 2023
work page 2023
-
[12]
Peter Dayan. Improving generalization for temporal difference learning: The successor repre- sentation.Neural Computation, 5(4):613–624, 1993
work page 1993
-
[13]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[14]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. Encouraging divergent thinking in large language models through multi-agent debate.arXiv preprint arXiv:2305.19118, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Bowman, Tim Rocktäschel, and Ethan Perez
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktäschel, and Ethan Perez. Debating with more persuasive LLMs leads to more truthful answers. InInternational Conference on Machine Learning (ICML), 2024. 11
work page 2024
-
[16]
Self- refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Sy...
work page 2023
-
[17]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[18]
ChatDev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2024
work page 2024
-
[19]
CAMEL: Communicative agents for “mind” exploration of large language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large language model society. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[20]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InACM Symposium on User Interface Software and Technology (UIST), 2023
work page 2023
-
[21]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[22]
Re- flexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[23]
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan Ö. Arik. Chain of agents: Large language models collaborating on long-context tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[24]
Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More agents is all you need. Transactions on Machine Learning Research (TMLR), 2024
work page 2024
-
[25]
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why do multi-agent LLM systems fail? InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[26]
Convolutional neural networks on graphs with fast localized spectral filtering
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. InAdvances in Neural Information Processing Systems (NeurIPS), 2016
work page 2016
-
[27]
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[28]
On the bottleneck of graph neural networks and its practical implications
Uri Alon and Eran Yahav. On the bottleneck of graph neural networks and its practical implications. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
- [29]
-
[30]
Deeper insights into graph convolutional networks for semi-supervised learning
Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. InAAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[31]
Graph neural networks exponentially lose expressive power for node classification
Kenta Oono and Taiji Suzuki. Graph neural networks exponentially lose expressive power for node classification. InInternational Conference on Learning Representations (ICLR), 2020. 12
work page 2020
- [32]
-
[33]
Morris H. DeGroot. Reaching a consensus.Journal of the American Statistical Association, 69 (345):118–121, 1974
work page 1974
-
[34]
Reza Olfati-Saber, J. Alex Fax, and Richard M. Murray. Consensus and cooperation in net- worked multi-agent systems.Proceedings of the IEEE, 95(1):215–233, 2007
work page 2007
-
[35]
Randomized gossip algorithms.IEEE Transactions on Information Theory, 52(6):2508–2530, 2006
Stephen Boyd, Arpita Ghosh, Balaji Prabhakar, and Devavrat Shah. Randomized gossip algorithms.IEEE Transactions on Information Theory, 52(6):2508–2530, 2006
work page 2006
-
[36]
Levin and Yuval Peres.Markov Chains and Mixing Times
David A. Levin and Yuval Peres.Markov Chains and Mixing Times. American Mathematical Society, 2 edition, 2017
work page 2017
-
[37]
Fan R. K. Chung.Spectral Graph Theory. American Mathematical Society, 1997
work page 1997
-
[38]
Lin Xiao, Stephen Boyd, and Seung-Jean Kim. Distributed average consensus with least-mean- square deviation.Journal of Parallel and Distributed Computing, 67(1):33–46, 2007
work page 2007
-
[39]
Machine learning with adversaries: Byzantine tolerant gradient descent
Peva Blanchard, El Mahdi El Mhamdi, Rachid Guerraoui, and Julien Stainer. Machine learning with adversaries: Byzantine tolerant gradient descent. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[40]
Russek, Ida Momennejad, Matthew M
Evan M. Russek, Ida Momennejad, Matthew M. Botvinick, Samuel J. Gershman, and Nathaniel D. Daw. Predictive representations can link model-based reinforcement learning to model-free mechanisms.PLOS Computational Biology, 13(9):e1005768, 2017
work page 2017
-
[41]
Hunt, Tom Schaul, Hado van Hasselt, and David Silver
André Barreto, Will Dabney, Rémi Munos, Jonathan J. Hunt, Tom Schaul, Hado van Hasselt, and David Silver. Successor features for transfer in reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[42]
Marlos C. Machado, Marc G. Bellemare, and Michael Bowling. A Laplacian framework for option discovery in reinforcement learning. InInternational Conference on Machine Learning (ICML), 2017
work page 2017
- [43]
-
[44]
Adversarial attacks on neural networks for graph data
Daniel Zügner, Amir Akbarnejad, and Stephan Günnemann. Adversarial attacks on neural networks for graph data. InACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2018
work page 2018
-
[45]
Adversarial attack on graph structured data
Hanjun Dai, Hui Li, Tian Tian, Xin Huang, Lin Wang, Jun Zhu, and Le Song. Adversarial attack on graph structured data. InInternational Conference on Machine Learning (ICML), 2018
work page 2018
-
[46]
Red teaming language models with language models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 3419–3448, 2022
work page 2022
-
[47]
Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. Faith and fate: Limits of transformers on compositionality. InAdvances in Neural Information Processing Systems (Neu...
work page 2023
-
[48]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 2024
work page 2024
-
[49]
Nelson Cowan. The magical number 4 in short-term memory: A reconsideration of mental storage capacity.Behavioral and Brain Sciences, 24(1):87–114, 2001. 13
work page 2001
-
[50]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations (ICLR), 2018. 14 A Theoretical Derivations This appendix collects the mathematical support for the main-text claims. Section A.1 derives the closed-form spectra reported in ...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.