Recognition: 2 theorem links
· Lean TheoremPoseBridge: Bridging the Skeletonization Gap for Zero-Shot Skeleton-Based Action Recognition
Pith reviewed 2026-05-13 02:37 UTC · model grok-4.3
The pith
PoseBridge recovers semantic cues lost in skeletonization to improve zero-shot skeleton-based action recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that by bridging intermediate human pose estimation representations to the skeleton-text alignment process, rather than aligning skeletons directly with text, zero-shot skeleton-based action recognition can be enhanced without introducing additional visual modalities or object detectors.
What carries the argument
Skeleton-conditioned bridging and semantic prototype adaptation that transfer pose-anchored semantic cues extracted from the human pose estimation process.
If this is right
- Improved ZSSAR performance across NTU-RGB+D 60/120, PKU-MMD, and Kinetics-200/400 datasets.
- Particularly strong gains on the PURLS benchmark with diverse in-the-wild videos.
- No requirement for extra RGB action branches or object detection modules.
- Consistent improvements across all evaluated protocols and splits.
Where Pith is reading between the lines
- Similar bridging of intermediate representations could help in other tasks where input compression loses context, such as other vision-language alignments.
- The approach might be extended to few-shot settings or combined with minimal additional cues without full modality addition.
- Testing on more recent HPE models could reveal how the bridging effectiveness depends on the quality of the initial pose estimation.
Load-bearing premise
Pose-anchored semantic cues from human pose estimation can be transferred to skeleton-text alignment without adding errors or needing extra video information.
What would settle it
A test where PoseBridge is applied to a dataset with actions where HPE intermediates provide no additional semantic value, resulting in no performance gain or a loss over direct alignment.
Figures







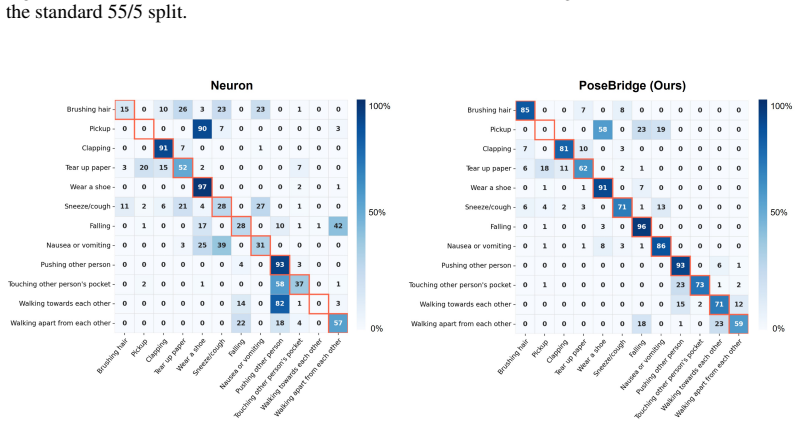
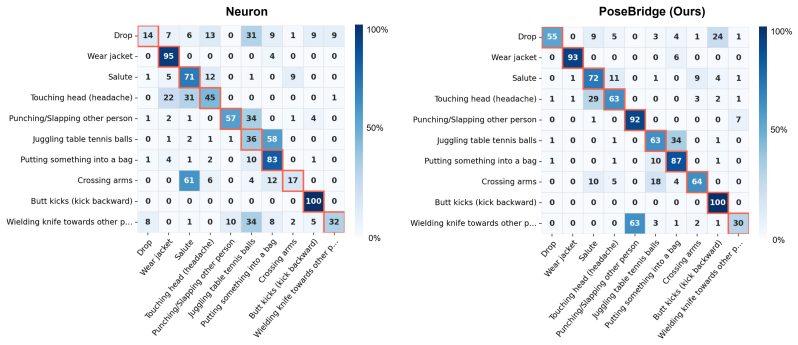




read the original abstract
Zero-shot skeleton-based action recognition (ZSSAR) is typically treated as a skeleton-text alignment problem: encode joint-coordinate sequences, align them with language, and classify unseen actions. We argue that this alignment is often too late. Skeletons are not complete action observations, but compressed outputs of human pose estimation (HPE); by the time alignment begins, human-object interactions and pose-relative visual cues may no longer be explicit. We call this upstream semantic loss. To address it, we propose PoseBridge, an HPE-aware ZSSAR framework that bridges intermediate HPE representations to skeleton-text alignment. Rather than adding an RGB action branch or object detector, PoseBridge extracts pose-anchored semantic cues from the same HPE process that produces skeletons, then transfers them through skeleton-conditioned bridging and semantic prototype adaptation. Across NTU-RGB+D 60/120, PKU-MMD, and Kinetics-200/400, PoseBridge improves ZSSAR performance under the evaluated protocols. On the Kinetics-200/400 PURLS benchmark, which contains in-the-wild videos with diverse scenes and action contexts, PoseBridge shows the clearest separation, improving the strongest compared baseline by 13.3-17.4 points across all eight splits. Our code will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PoseBridge, an HPE-aware framework for zero-shot skeleton-based action recognition (ZSSAR) that extracts pose-anchored semantic cues from the human pose estimation process, transfers them via skeleton-conditioned bridging, and adapts them into semantic prototypes for alignment with text embeddings. It argues that standard skeleton-text alignment occurs too late and suffers from upstream semantic loss of human-object interactions and pose-relative cues. The central empirical claim is consistent performance gains over baselines on NTU-RGB+D 60/120, PKU-MMD, and especially the Kinetics-200/400 PURLS benchmark, where it improves the strongest baseline by 13.3-17.4 points across all eight splits.
Significance. If the reported gains prove robust and attributable to the bridging construction rather than HPE-specific artifacts, the work would offer a practical advance in ZSSAR by recovering semantic information without introducing new modalities. The public code release is a clear strength for reproducibility. The approach of conditioning on intermediate HPE representations is conceptually distinct from prior skeleton-only or RGB-augmented methods, but its significance hinges on verification that the prototype adaptation generalizes to unseen actions without leakage or error injection.
major comments (3)
- [Abstract] Abstract: the headline claim of 13.3-17.4 point gains on Kinetics-200/400 PURLS across all eight splits is presented without error bars, ablation tables, or statistical tests; this directly undermines assessment of whether the skeleton-conditioned bridging and semantic prototype adaptation contribute reliably or whether results reflect post-hoc split selection or HPE estimator bias.
- [Experiments] Experiments section: no cross-HPE ablation is reported to isolate whether pose-anchored cues add orthogonal semantic value beyond the final skeleton coordinates; because the same HPE pipeline supplies both the skeleton input and the bridged cues, any gain could arise from richer exploitation of that specific estimator rather than the proposed bridging module.
- [Methods] Methods: the description of semantic prototype adaptation for zero-shot classes does not specify mechanisms to prevent leakage from seen-class visual context or to ensure generalization of the bridged representations; this is load-bearing for the claim that the framework addresses upstream semantic loss without new errors.
minor comments (2)
- The abstract would be clearer if it briefly named the bridging architecture (e.g., transformer layers or MLP) and the adaptation loss used.
- Notation for the pose-anchored cues and the bridging function should be introduced with explicit equations early in the methods to avoid ambiguity when reading the results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We are pleased that the significance of the work is recognized, particularly the conceptual distinction and the public code release. We address each major comment below, committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 13.3-17.4 point gains on Kinetics-200/400 PURLS across all eight splits is presented without error bars, ablation tables, or statistical tests; this directly undermines assessment of whether the skeleton-conditioned bridging and semantic prototype adaptation contribute reliably or whether results reflect post-hoc split selection or HPE estimator bias.
Authors: We agree that including error bars, ablation tables, and statistical tests would enhance the credibility of the headline claim. While the full experimental results in the paper include detailed comparisons, we will revise the abstract to reference these supporting analyses and add error bars to the reported gains. We will also include statistical tests in the Experiments section to confirm the significance of the improvements across splits. revision: partial
-
Referee: [Experiments] Experiments section: no cross-HPE ablation is reported to isolate whether pose-anchored cues add orthogonal semantic value beyond the final skeleton coordinates; because the same HPE pipeline supplies both the skeleton input and the bridged cues, any gain could arise from richer exploitation of that specific estimator rather than the proposed bridging module.
Authors: This is a valid concern. To demonstrate that the pose-anchored cues provide additional semantic value independent of the specific HPE estimator, we will conduct and report cross-HPE ablations in the revised Experiments section, using alternative pose estimators to verify the robustness of the bridging approach. revision: yes
-
Referee: [Methods] Methods: the description of semantic prototype adaptation for zero-shot classes does not specify mechanisms to prevent leakage from seen-class visual context or to ensure generalization of the bridged representations; this is load-bearing for the claim that the framework addresses upstream semantic loss without new errors.
Authors: We will clarify this in the revised Methods section by detailing the semantic prototype adaptation procedure. The adaptation operates by aligning bridged pose-anchored cues with text embeddings for unseen classes in a manner that excludes any direct visual information from seen classes, relying instead on the transferred semantic cues and language models to ensure no leakage and proper generalization. revision: yes
Circularity Check
No significant circularity; empirical framework with benchmark results
full rationale
The paper proposes PoseBridge as a new HPE-aware framework for ZSSAR that extracts and bridges pose-anchored cues from the same human pose estimation process used to generate skeletons. The central claims consist of architectural descriptions and reported performance gains on standard datasets (NTU-RGB+D 60/120, PKU-MMD, Kinetics-200/400 PURLS) under zero-shot protocols. No equations, parameter-fitting steps, or predictions are presented that reduce by construction to the inputs; the 13.3-17.4 point gains are framed as experimental outcomes rather than quantities derived from self-referential definitions or fitted constants. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The derivation chain is therefore self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- bridging and adaptation hyperparameters
axioms (1)
- domain assumption Skeletons produced by HPE are compressed outputs that discard human-object interactions and pose-relative visual cues before text alignment occurs.
invented entities (1)
-
pose-anchored semantic cues
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PoseBridge extracts pose-anchored semantic cues from the same HPE process... transfers them through skeleton-conditioned bridging and semantic prototype adaptation
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the pose-anchored semantics... via skeleton-conditioned semantic bridge and semantic prototype adaptation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fine-grained side information guided dual-prompts for zero-shot skeleton action recognition
Yang Chen, Jingcai Guo, Tian He, Xiaocheng Lu, and Ling Wang. Fine-grained side information guided dual-prompts for zero-shot skeleton action recognition. InProceedings of the 32nd ACM International Conference on Multimedia, pages 778–786, 2024
work page 2024
-
[2]
Neuron: Learning context-aware evolving representations for zero-shot skeleton action recognition
Yang Chen, Jingcai Guo, Song Guo, and Dacheng Tao. Neuron: Learning context-aware evolving representations for zero-shot skeleton action recognition. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8721–8730, 2025
work page 2025
-
[3]
Yang Chen, Miaoge Li, Zhijie Rao, Deze Zeng, Song Guo, and Jingcai Guo. Learning by neighbor-aware semantics, deciding by open-form flows: Towards robust zero-shot skeleton action recognition.arXiv preprint arXiv:2511.09388, 2025
-
[4]
Skeleton- based action recognition with shift graph convolutional network
Ke Cheng, Yifan Zhang, Xiangyu He, Weihan Chen, Jian Cheng, and Hanqing Lu. Skeleton- based action recognition with shift graph convolutional network. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 183–192, 2020
work page 2020
-
[5]
Jeonghyeok Do and Munchurl Kim. Bridging the skeleton-text modality gap: Diffusion-powered modality alignment for zero-shot skeleton-based action recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12757–12768, October 2025
work page 2025
-
[6]
Revisiting skeleton-based action recognition
Haodong Duan, Yue Zhao, Kai Chen, Dahua Lin, and Bo Dai. Revisiting skeleton-based action recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2969–2978, 2022
work page 2022
-
[7]
Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, Marc’Aurelio Ranzato, and Tomas Mikolov. Devise: A deep visual-semantic embedding model.Advances in neural information processing systems, 26, 2013
work page 2013
-
[8]
Syntactically guided generative embeddings for zero-shot skeleton action recognition
Pranay Gupta, Divyanshu Sharma, and Ravi Kiran Sarvadevabhatla. Syntactically guided generative embeddings for zero-shot skeleton action recognition. In2021 IEEE International Conference on Image Processing (ICIP), pages 439–443. IEEE, 2021
work page 2021
-
[9]
Learning robust visual- semantic embeddings
Yao-Hung Hubert Tsai, Liang-Kang Huang, and Ruslan Salakhutdinov. Learning robust visual- semantic embeddings. InProceedings of the IEEE International conference on Computer Vision, pages 3571–3580, 2017
work page 2017
-
[10]
Bhavan Jasani and Afshaan Mazagonwalla. Skeleton based zero shot action recognition in joint pose-language semantic space.arXiv preprint arXiv:1911.11344, 2019
-
[11]
arXiv preprint arXiv:2303.07399 (2023)
Tao Jiang, Peng Lu, Li Zhang, Ningsheng Ma, Rui Han, Chengqi Lyu, Yining Li, and Kai Chen. Rtmpose: Real-time multi-person pose estimation based on mmpose.arXiv preprint arXiv:2303.07399, 2023
-
[12]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
YOLOv11: An Overview of the Key Architectural Enhancements
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements.arXiv preprint arXiv:2410.17725, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
work page 2020
-
[15]
Jidong Kuang, Hongsong Wang, Chaolei Han, Yang Zhang, and Jie Gui. Zero-shot skeleton- based action recognition with dual visual-text alignment.Pattern Recognition, page 112342, 2025
work page 2025
-
[16]
Sheng-Wei Li, Zi-Xiang Wei, Wei-Jie Chen, Yi-Hsin Yu, Chih-Yuan Yang, and Jane Yung- jen Hsu. Sa-dvae: Improving zero-shot skeleton-based action recognition by disentangled variational autoencoders. InEuropean conference on computer vision, pages 447–462. Springer, 2024. 10
work page 2024
-
[17]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[18]
PKU-MMD: A Large Scale Benchmark for Continuous Multi-Modal Human Action Understanding
Chunhui Liu, Yueyu Hu, Yanghao Li, Sijie Song, and Jiaying Liu. Pku-mmd: A large scale benchmark for continuous multi-modal human action understanding.arXiv preprint arXiv:1703.07475, 2017
work page Pith review arXiv 2017
-
[19]
Hongjie Liu, Yingchun Niu, Kun Zeng, Chun Liu, Mengjie Hu, and Qing Song. Beyond- skeleton: Zero-shot skeleton action recognition enhanced by supplementary rgb visual informa- tion.Expert Systems with Applications, 273:126814, 2025
work page 2025
-
[20]
Jun Liu, Amir Shahroudy, Mauricio Perez, Gang Wang, Ling-Yu Duan, and Alex C Kot. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding.IEEE transactions on pattern analysis and machine intelligence, 42(10):2684–2701, 2019
work page 2019
-
[21]
Recognizing human actions as the evolution of pose estimation maps
Mengyuan Liu and Junsong Yuan. Recognizing human actions as the evolution of pose estimation maps. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1159–1168, 2018
work page 2018
-
[22]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[23]
General- ized zero-shot learning via aligned variational autoencoders
Edgar Schonfeld, Sayna Ebrahimi, Samarth Sinha, Trevor Darrell, and Zeynep Akata. General- ized zero-shot learning via aligned variational autoencoders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 54–57, 2019
work page 2019
-
[24]
Ntu rgb+ d: A large scale dataset for 3d human activity analysis
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1010–1019, 2016
work page 2016
-
[25]
Two-stream adaptive graph convolutional networks for skeleton-based action recognition
Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12026–12035, 2019
work page 2019
-
[26]
Ski models: Skeleton induced vision-language embeddings for understanding activities of daily living
Arkaprava Sinha, Dominick Reilly, Francois Bremond, Pu Wang, and Srijan Das. Ski models: Skeleton induced vision-language embeddings for understanding activities of daily living. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6931–6939, 2025
work page 2025
-
[27]
Deep high-resolution representation learning for human pose estimation
Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5693–5703, 2019
work page 2019
-
[28]
Ning Wang, Tieyue Wu, Naeha Sharif, Farid Boussaid, Guangming Zhu, Lin Mei, Mohammed Bennamoun, et al. Skeletoncontext: Skeleton-side context prompt learning for zero-shot skeleton-based action recognition.arXiv preprint arXiv:2603.29692, 2026
-
[29]
Hao Wen, Zhe-Ming Lu, Fengli Shen, Ziqian Lu, Yangming Zheng, and Jialin Cui. Enhancing skeleton-based action recognition with feature maps from pose estimation networks.IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, page 2024EAP1162, 2025
work page 2025
-
[30]
Fine-grained action retrieval through multiple parts-of-speech embeddings
Michael Wray, Diane Larlus, Gabriela Csurka, and Dima Damen. Fine-grained action retrieval through multiple parts-of-speech embeddings. InProceedings of the IEEE/CVF international conference on computer vision, pages 450–459, 2019
work page 2019
-
[31]
Wenhan Wu, Zhishuai Guo, Chen Chen, Hongfei Xue, and Aidong Lu. Frequency-semantic en- hanced variational autoencoder for zero-shot skeleton-based action recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11122–11131, 2025. 11
work page 2025
-
[32]
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vitpose: Simple vision transformer baselines for human pose estimation.Advances in neural information processing systems, 35: 38571–38584, 2022
work page 2022
-
[33]
Spatial temporal graph convolutional networks for skeleton-based action recognition
Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[34]
Zero-shot skeleton- based action recognition via mutual information estimation and maximization
Yujie Zhou, Wenwen Qiang, Anyi Rao, Ning Lin, Bing Su, and Jiaqi Wang. Zero-shot skeleton- based action recognition via mutual information estimation and maximization. InProceedings of the 31st ACM international conference on multimedia, pages 5302–5310, 2023
work page 2023
-
[35]
Part-aware unified representation of language and skeleton for zero-shot action recognition
Anqi Zhu, Qiuhong Ke, Mingming Gong, and James Bailey. Part-aware unified representation of language and skeleton for zero-shot action recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18761–18770, 2024
work page 2024
-
[36]
Anqi Zhu, Jingmin Zhu, James Bailey, Mingming Gong, and Qiuhong Ke. Semantic-guided cross-modal prompt learning for skeleton-based zero-shot action recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13876–13885, 2025. 12 Appendix This appendix provides additional details, results, and analyses that supp...
work page 2025
-
[37]
The best results are highlighted inred, and the second-best results are blue . Method Venue NTU-RGB+D 60 (Xsub)NTU-RGB+D 120 (Xsub) 40/20 Split 30/30 Split 80/40 Split 60/60 Split ReViSE [9] ICCV 2017 24.3 14.8 19.5 8.3 JPoSE [30] ICCV 2019 20.1 12.4 13.7 7.7 CADA-V AE [23] CVPR 2019 16.2 11.5 10.6 5.7 SynSE [8] ICIP 2021 19.9 12.0 13.6 7.7 PURLS [35] CVP...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.