Recognition: 2 theorem links
· Lean TheoremBitLM: Unlocking Multi-Token Language Generation with Bitwise Continuous Diffusion
Pith reviewed 2026-05-13 01:50 UTC · model grok-4.3
The pith
BitLM encodes tokens as fixed binary codes and uses diffusion to generate multiple tokens in parallel inside causal blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
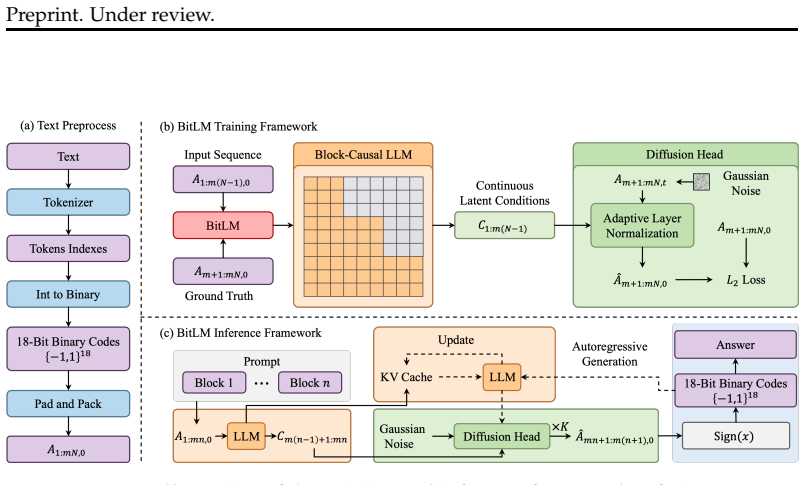
BitLM represents each token as a fixed-length binary code and employs a lightweight diffusion head to denoise multiple tokens in parallel within each block. It preserves left-to-right causal attention across blocks while making joint lexical decisions inside them, combining the reliability of autoregressive modeling with the parallelism of iterative refinement. By replacing the large-vocabulary softmax with bitwise denoising, the model reframes token generation as iterative commitment in a compact binary space.
What carries the argument
The bitwise continuous diffusion head that jointly denoises fixed-length binary codes for several tokens inside each causally ordered block.
If this is right
- Pre-training avoids the computational cost of large-vocabulary softmax layers.
- Inference runs faster because multiple tokens are produced per block through parallel denoising steps.
- The model can capture multi-token units such as phrases and collocations more directly than single-token autoregression.
- The one-token-at-a-time paradigm is shown to be replaceable while retaining the causal foundation that makes language models work.
- Overall model strength improves alongside the throughput gains.
Where Pith is reading between the lines
- Similar block-wise binary diffusion could be applied to other autoregressive domains such as code or protein sequences.
- Variable block lengths or adaptive binary precision might further trade off speed against expressiveness in future versions.
- The approach suggests that diffusion-style refinement inside causal windows could complement rather than replace existing speculative decoding techniques.
Load-bearing premise
A fixed-length binary code plus lightweight diffusion can faithfully represent the joint distribution over multiple tokens inside each block without losing semantic content or breaking the left-to-right causal constraints needed for coherent language.
What would settle it
A direct comparison on long-form generation tasks showing that BitLM produces measurably less coherent or less accurate text than a standard autoregressive baseline of similar size, or that any speed gains disappear once quality is held constant.
Figures



read the original abstract
Autoregressive language models generate text one token at a time, yet natural language is inherently structured in multi-token units, including phrases, n-grams, and collocations that carry meaning jointly. This one-token bottleneck limits both the expressiveness of the model during pre-training and its throughput at inference time. Existing remedies such as speculative decoding or diffusion-based language models either leave the underlying bottleneck intact or sacrifice the causal structure essential to language modeling. We propose BitLM, a language model that represents each token as a fixed-length binary code and employs a lightweight diffusion head to denoise multiple tokens in parallel within each block. Crucially, BitLM preserves left-to-right causal attention across blocks while making joint lexical decisions within each block, combining the reliability of autoregressive modeling with the parallelism of iterative refinement. By replacing the large-vocabulary softmax with bitwise denoising, BitLM reframes token generation as iterative commitment in a compact binary space, enabling more efficient pre-training and substantially faster inference without altering the causal foundation that makes language models effective. Our results demonstrate that the one-token-at-a-time paradigm is not a fundamental requirement but an interface choice, and that changing it can yield a stronger and faster language model. We hope BitLM points toward a promising direction for next-generation language model architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BitLM, a language model architecture in which each token is represented by a fixed-length binary code rather than a large-vocabulary softmax. A lightweight continuous diffusion head is then used to jointly denoise and generate multiple tokens in parallel inside each block, while left-to-right causal attention is retained across blocks. The central claim is that this hybrid design removes the one-token-at-a-time bottleneck, yielding both stronger models and substantially faster inference without violating the causal structure required for coherent language modeling.
Significance. If the empirical and theoretical claims hold, the work would be significant: it offers a concrete alternative to the dominant autoregressive interface and demonstrates that intra-block parallelism can be achieved while preserving the autoregressive factorization across blocks. The bitwise diffusion formulation is a novel technical contribution that could influence future hybrid autoregressive-diffusion architectures and improve throughput in both pre-training and inference.
major comments (2)
- [Abstract] Abstract: the statement that 'our results demonstrate that the one-token-at-a-time paradigm is not a fundamental requirement' is unsupported by any quantitative results, baselines, or ablation studies in the provided text. Without these data the central claim cannot be evaluated.
- [Method] Method section (description of binary encoding and diffusion head): the manuscript does not supply a derivation or empirical verification that the fixed-length binary code is bijective and that the continuous diffusion process recovers exact discrete token probabilities (especially for low-probability or highly context-dependent tokens). This assumption is load-bearing for the claim that semantic information is preserved and that the model remains strictly autoregressive across blocks.
minor comments (1)
- [Abstract] The abstract is clear but would benefit from a single sentence stating the binary code length and number of diffusion steps used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments have prompted us to strengthen the presentation of our empirical results and to add formal details to the method. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'our results demonstrate that the one-token-at-a-time paradigm is not a fundamental requirement' is unsupported by any quantitative results, baselines, or ablation studies in the provided text. Without these data the central claim cannot be evaluated.
Authors: We appreciate the referee drawing attention to the need for clearer linkage between the abstract claim and supporting evidence. The full manuscript reports quantitative results in Section 4, including perplexity on WikiText-103 and C4, wall-clock inference throughput, and ablations on block size and diffusion steps, all benchmarked against standard autoregressive transformers. These results underpin the claim. To address the concern directly, we have revised the abstract to include an explicit reference to these experiments and added a concise summary of the key empirical findings at the end of the introduction. revision: yes
-
Referee: [Method] Method section (description of binary encoding and diffusion head): the manuscript does not supply a derivation or empirical verification that the fixed-length binary code is bijective and that the continuous diffusion process recovers exact discrete token probabilities (especially for low-probability or highly context-dependent tokens). This assumption is load-bearing for the claim that semantic information is preserved and that the model remains strictly autoregressive across blocks.
Authors: This is a fair and important point. The binary encoding is constructed via a deterministic, invertible mapping from each vocabulary token to a unique fixed-length binary vector (length chosen so that 2^b exceeds vocabulary size), implemented as a lookup table. We have added a short formal derivation in the revised Method section establishing bijectivity and invertibility. The diffusion head operates on a continuous relaxation of these bit vectors and is trained to predict bit-wise probabilities; the final token is recovered by rounding and lookup. While the continuous process yields an approximation rather than an exact closed-form discrete distribution, we have added empirical verification consisting of token reconstruction accuracy on held-out data (stratified by frequency) together with a new table and discussion of performance on low-probability tokens. The autoregressive factorization across blocks is enforced solely by the causal attention mask at the block level and is independent of the intra-block diffusion. revision: yes
Circularity Check
No circularity: BitLM introduces independent architectural components
full rationale
The paper proposes a new token representation via fixed-length binary codes combined with a lightweight diffusion head for intra-block parallel denoising, while retaining standard causal attention across blocks. This design is presented as an alternative interface rather than a mathematical derivation that reduces to prior fitted parameters, self-citations, or redefinitions. No equations or claims in the abstract or described structure equate the claimed performance gains (stronger/faster modeling) to inputs by construction; the benefits are attributed to the novel bitwise continuous diffusion mechanism itself. The derivation chain remains self-contained, with no load-bearing steps that collapse into tautologies or fitted renamings.
Axiom & Free-Parameter Ledger
free parameters (1)
- binary code length
axioms (1)
- domain assumption Natural language contains meaningful multi-token units that benefit from joint modeling
invented entities (1)
-
Bitwise continuous diffusion head
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
replaces the large-vocabulary softmax with bitwise denoising... fixed-length binary code... diffusion head to denoise multiple tokens in parallel within each block
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
block-causal attention mask... p(y1:L) = ∏ p(y(n) | y(<n))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yuang Ai, Jiaming Han, Shaobin Zhuang, Weijia Mao, Xuefeng Hu, Ziyan Yang, Zhenheng Yang, Huaibo Huang, Xiangyu Yue, and Hao Chen. Bitdance: Scaling autoregressive generative models with binary tokens.arXiv preprint arXiv:2602.14041,
-
[2]
arXiv preprint arXiv:2503.09573 , year=
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models.arXiv preprint arXiv:2503.09573,
-
[3]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745,
work page internal anchor Pith review arXiv
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[5]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads, 2024.URL https://arxiv. org/abs/2401.10774, 1(2),
work page internal anchor Pith review arXiv 2024
-
[6]
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning.arXiv preprint arXiv:2208.04202,
-
[7]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
work page 2019
-
[8]
Mask-predict: Parallel decoding of conditional masked language models
Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. Mask-predict: Parallel decoding of conditional masked language models. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pp. 6112–6121,
work page 2019
-
[9]
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, and Gabriel Syn- naeve. Better & faster large language models via multi-token prediction.arXiv preprint arXiv:2404.19737,
-
[10]
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and LingPeng Kong. Diffuseq: Se- quence to sequence text generation with diffusion models.arXiv preprint arXiv:2210.08933,
-
[11]
10 Preprint. Under review. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Non-autoregressive neural machine translation.arXiv preprint arXiv:1711.02281, 2017
Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. Non- autoregressive neural machine translation.arXiv preprint arXiv:1711.02281,
-
[13]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution, 2024.URL https://arxiv. org/abs/2310.16834,
work page internal anchor Pith review arXiv 2024
-
[18]
Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 conference on empirical methods in natural language processing, pp. 1797–1807,
work page 2018
-
[19]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[21]
Self-conditioned embedding diffusion for text generation
Robin Strudel, Corentin Tallec, Florent Altch´e, Yilun Du, Yaroslav Ganin, Arthur Mensch, Will Grathwohl, Nikolay Savinov, Sander Dieleman, Laurent Sifre, et al. Self-conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236,
-
[22]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Semi-autoregressive neural machine translation
Chunqi Wang, Ji Zhang, and Haiqing Chen. Semi-autoregressive neural machine translation. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 479–488,
work page 2018
-
[24]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Breaking the Softmax Bottleneck: A High-Rank RNN Language Model
Zhilin Yang, Zihang Dai, Ruslan Salakhutdinov, and William W Cohen. Breaking the softmax bottleneck: A high-rank rnn language model.arXiv preprint arXiv:1711.03953,
-
[26]
PixelDiT: Pixel Diffusion Transformers for Image Generation
Yongsheng Yu, Wei Xiong, Weili Nie, Yichen Sheng, Shiqiu Liu, and Jiebo Luo. Pixeldit: Pixel diffusion transformers for image generation.arXiv preprint arXiv:2511.20645,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
A reparameterized discrete diffusion model for text generation.arXiv preprint arXiv:2302.05737, 2023
Lin Zheng, Jianbo Yuan, Lei Yu, and Lingpeng Kong. A reparameterized discrete diffusion model for text generation.arXiv preprint arXiv:2302.05737,
-
[28]
Shaobin Zhuang, Yuang Ai, Jiaming Han, Weijia Mao, Xiaohui Li, Fangyikang Wang, Xiao Wang, Yan Li, Shanchuan Lin, Kun Xu, et al. Uniwetok: An unified binary tokenizer with codebook size 2128 for unified multimodal large language model.arXiv preprint arXiv:2602.14178,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.