Recognition: 1 theorem link
· Lean TheoremEPIC: Efficient Predicate-Guided Inference-Time Control for Compositional Text-to-Image Generation
Pith reviewed 2026-05-13 06:02 UTC · model grok-4.3
The pith
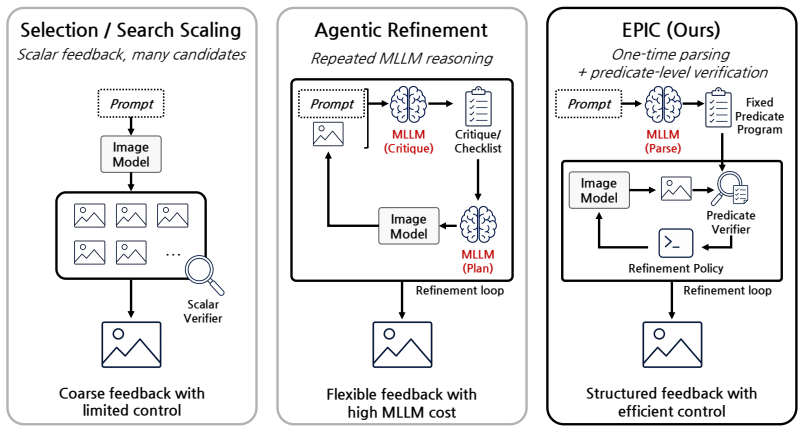
EPIC parses each prompt into a fixed visual program of predicates to guide targeted editing or resampling, raising compositional accuracy from 34% to 71% on GenEval2 while lowering cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By casting refinement as predicate-guided search over a fixed visual program parsed once from the prompt, EPIC routes failures between local editing and global resampling so that the final image satisfies more of the original compositional constraints than single-pass generation or existing iterative baselines, all without retraining and at lower realized cost.
What carries the argument
A fixed visual program of object variables and typed predicates, parsed from the prompt once and held constant, that supplies both the verification checklist and the rule for choosing between editing and resampling.
If this is right
- Prompt-level accuracy on GenEval2 rises from 34.16% to 71.46% compared with single-pass generation.
- Under identical generator, editor, and maximum budget, accuracy exceeds the strongest prior refinement baseline by 19.23 points.
- Realized cost falls by 31% in image-model executions, 72% in MLLM calls, and 81% in MLLM tokens per prompt.
- The method works with any base generator and editor pair that can produce and modify images.
Where Pith is reading between the lines
- The same fixed-program structure could be reused for video or 3D generation by adding temporal or spatial predicates to the verification step.
- Making the initial parser more reliable would likely increase the fraction of prompts that reach full satisfaction.
- The failure-routing logic offers a reusable template for efficient search in any generative setting that supports partial edits.
Load-bearing premise
The prompt can be parsed once into a complete and accurate set of predicates, and visual verification can correctly identify which predicates hold in any given image without systematic errors.
What would settle it
Accuracy measured on a collection of prompts where the parser omits key relations or the verifier misjudges counts and attributes would show whether the reported gains remain when parsing or verification is imperfect.
Figures





read the original abstract
Recent text-to-image (T2I) generators can synthesize realistic images, but still struggle with compositional prompts involving multiple objects, counts, attributes, and relations. We introduce EPIC (Efficient Predicate-Guided Inference-Time Control), a training-free inference-time refinement framework for compositional T2I generation. EPIC casts refinement as predicate-guided search: it parses the original prompt once into a fixed visual program of object variables and typed predicates, covering checkable conditions such as object presence, counts, attributes, and relations. Each generated or edited image is verified against this program using visual evidence extracted from that image. An image is judged to satisfy the prompt only when all predicates are satisfied; otherwise, failed predicates decide the next step, routing local failures to targeted editing and global failures to resampling while the fixed visual program remains unchanged. On GenEval2, EPIC improves prompt-level accuracy from 34.16% for single-pass generation with the base generator to 71.46%. Under the same generator/editor setting and maximum image-model execution budget, EPIC outperforms the strongest prior refinement baseline by 19.23 points while reducing realized cost by 31% in image-model executions, 72% in MLLM calls, and 81% in MLLM tokens per prompt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EPIC, a training-free inference-time refinement framework for compositional text-to-image generation. It parses the input prompt once into a fixed visual program consisting of object variables and typed predicates (covering presence, counts, attributes, and relations), verifies each generated or edited image against this program via visual evidence from an MLLM, and routes failures to targeted editing or resampling while keeping the program unchanged. On GenEval2, EPIC reports raising prompt-level accuracy from 34.16% (single-pass base generator) to 71.46%, outperforming the strongest prior refinement baseline by 19.23 points under identical generator/editor settings and maximum image-model budget, while cutting realized costs by 31% in image-model executions, 72% in MLLM calls, and 81% in MLLM tokens.
Significance. If the reported gains are attributable to the predicate-guided mechanism rather than baseline or implementation choices, the work offers a practical, training-free route to substantially higher compositional fidelity in T2I models. The efficiency claims (cost reductions alongside accuracy gains) and the explicit use of an external verification step distinguish it from prior refinement methods and could influence inference-time control techniques more broadly.
major comments (2)
- [Abstract] Abstract and Methods: The central accuracy claim (34.16% → 71.46% on GenEval2) and all cost savings rest on the assumption that the one-time prompt parse into the fixed visual program is both complete and faithful. No parse-error statistics, failure-case analysis, or ablation on parser quality are reported, so it remains possible that the gains are driven by prompts where parsing succeeds easily and that the method degrades on cases with omitted relations, wrong counts, or mis-specified attributes.
- [Methods] Methods: Because the visual program is fixed after the initial parse and never revised, predicate verification on image evidence cannot recover from an upstream parsing error. This makes the reported superiority over baselines load-bearing on parser reliability; an ablation that injects controlled parse errors or compares against an oracle parser would be required to isolate the contribution of the predicate-guided routing.
minor comments (1)
- [Abstract] Abstract: The phrase 'maximum image-model execution budget' should be defined more precisely (e.g., total number of generator/editor calls allowed per prompt) so that the cost-comparison protocol is reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, clarifying the design rationale while agreeing to strengthen the manuscript with additional analysis on parser reliability.
read point-by-point responses
-
Referee: [Abstract] Abstract and Methods: The central accuracy claim (34.16% → 71.46% on GenEval2) and all cost savings rest on the assumption that the one-time prompt parse into the fixed visual program is both complete and faithful. No parse-error statistics, failure-case analysis, or ablation on parser quality are reported, so it remains possible that the gains are driven by prompts where parsing succeeds easily and that the method degrades on cases with omitted relations, wrong counts, or mis-specified attributes.
Authors: We agree that explicit parser analysis is missing from the current manuscript and would strengthen the claims. The parser is implemented as a single structured LLM call that extracts object variables and typed predicates (presence, counts, attributes, relations) with a fixed output schema to reduce hallucination. In the revised version we will add a dedicated subsection reporting parse accuracy on the full GenEval2 set, broken down by predicate type, together with a qualitative failure-case analysis of the small number of parsing errors observed. This will allow readers to assess whether the reported gains hold when parsing is imperfect. revision: yes
-
Referee: [Methods] Methods: Because the visual program is fixed after the initial parse and never revised, predicate verification on image evidence cannot recover from an upstream parsing error. This makes the reported superiority over baselines load-bearing on parser reliability; an ablation that injects controlled parse errors or compares against an oracle parser would be required to isolate the contribution of the predicate-guided routing.
Authors: The fixed-program design is intentional: it avoids repeated LLM calls for re-parsing and enables the observed efficiency gains (31–81 % cost reduction) by routing edits solely on image evidence. While the current results already show EPIC outperforming prior refinement baselines under identical generator/editor budgets, we acknowledge that an oracle-parser ablation would better isolate the predicate-guided search contribution. In the revision we will add such an ablation by (i) injecting controlled parse errors (e.g., dropped relations or incorrect counts) and (ii) comparing against an oracle program derived from ground-truth annotations, quantifying the performance drop attributable to parsing versus the search mechanism itself. revision: yes
Circularity Check
No circularity: algorithmic framework with independent verification steps
full rationale
The paper describes EPIC as a training-free search procedure that parses the prompt once into a fixed visual program of objects and predicates, then verifies each image against that program using external visual evidence. No equations, fitted parameters, or predictions are present. The accuracy and cost claims are empirical outcomes of running the described procedure on GenEval2; they do not reduce to the inputs by construction, self-citation chains, or renamed ansatzes. The fixed-program assumption is a methodological choice whose correctness is externally testable, not a definitional loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Prompts can be parsed once into a complete and fixed visual program of object variables and typed predicates.
- domain assumption Visual evidence extracted from a generated image can reliably determine whether each predicate is satisfied.
invented entities (1)
-
Visual program
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
7 Black Forest Labs. FLUX.2 [klein] 4B. https://huggingface.co/black-forest-labs/FLUX. 2-klein-4B, 2026a. Hugging Face model card. Accessed: 2026-04-26. 20 Black Forest Labs. FLUX.2 [klein] 9B. https://huggingface.co/black-forest-labs/FLUX. 2-klein-9B, 2026b. Hugging Face model card. Accessed: 2026-04-26. 7 Chieh-Yun Chen, Min Shi, Gong Zhang, and Humphre...
work page 2026
-
[3]
23 Jaemin Cho, Yushi Hu, Roopal Garg, Peter Anderson, Ranjay Krishna, Jason Baldridge, Mohit Bansal, Jordi Pont-Tuset, and Su Wang. Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation.arXiv preprint arXiv:2310.18235, 2023a. 3 Jaemin Cho, Abhay Zala, and Mohit Bansal. Dall-eval: Probing the reasoning skill...
-
[4]
Benchmarking spatial relationships in text-to-image generation.arXiv preprint arXiv:2212.10015,
1, 3, 23 Tejas Gokhale, Hamid Palangi, Besmira Nushi, Vibhav Vineet, Eric Horvitz, Ece Kamar, Chitta Baral, and Yezhou Yang. Benchmarking spatial relationships in text-to-image generation.arXiv preprint arXiv:2212.10015,
-
[5]
1, 3 Liyao Jiang, Ruichen Chen, Chao Gao, and Di Niu. RAISE: Requirement-adaptive evolutionary refinement for training-free text-to-image alignment.arXiv preprint arXiv:2603.00483,
-
[6]
GenEval 2: Addressing benchmark drift in text-to-image evaluation.arXiv preprint arXiv:2512.16853,
2, 3, 4, 7 Amita Kamath, Kai-Wei Chang, Ranjay Krishna, Luke Zettlemoyer, Yushi Hu, and Marjan Ghazvininejad. GenEval 2: Addressing benchmark drift in text-to-image evaluation.arXiv preprint arXiv:2512.16853,
-
[7]
2, 3 Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models.arXiv preprint arXiv:2305.13655,
-
[8]
Flow Matching for Generative Modeling
4 Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
1 Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
3, 7 Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Inference-time scaling for diffusion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732, 2025a. 2, 3 Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preferenc...
-
[11]
arXiv preprint arXiv:2501.06848 (2025)
21 Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848,
-
[12]
Denoising Diffusion Implicit Models
3 Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020a. 1 Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. 1 Michael Tschann...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
4 Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
1 Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, et al. SANA 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer.arXiv preprint arXiv:2501.18427,
-
[15]
Inference-time scaling of diffusion models through classical search.arXiv preprint arXiv:2505.23614,
2, 4 Xiangcheng Zhang, Haowei Lin, Haotian Ye, James Zou, Jianzhu Ma, Yitao Liang, and Yilun Du. Inference-time scaling of diffusion models through classical search.arXiv preprint arXiv:2505.23614,
-
[16]
You are a visual-program compiler for text-to-image prompts
The same MLLM is used for visual-program parsing, optional visual-program review, prompt rewriting, visible-text verification, crop-level verification for action-related attributes, and the limited uncertainty override. MLLM prompt templates.Table 5 summarizes the default prompt templates and structured outputs for the MLLM components that control the vis...
-
[17]
and CLIP scores (Ghosh et al., 2023), which can under-recognize outputs from current high-fidelity generators. We therefore use these results as an additional reference point rather than the main evidence for compositional alignment, and rely on GenEval2 for the primary evaluation because it was designed to address such drift (Kamath et al., 2025). D.3 Or...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.