Recognition: no theorem link
MULTI: Disentangling Camera Lens, Sensor, View, and Domain for Novel Image Generation
Pith reviewed 2026-05-13 05:24 UTC · model grok-4.3
The pith
MULTI disentangles camera lens, sensor, view, and domain factors using two-stage textual inversion to create novel image combinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
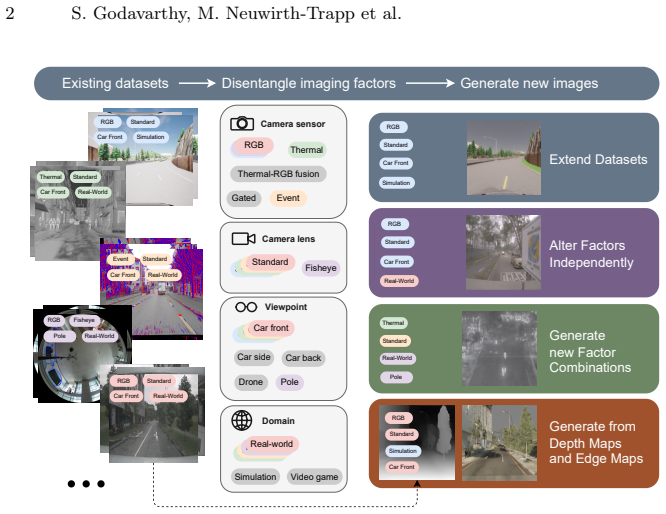
By separating the learning of general imaging factors in the first stage of textual inversion from dataset-specific factors in the second stage, MULTI enables the disentanglement of camera lens, sensor types, viewpoints, and domain characteristics. This setup allows the generation of images with previously unseen factor combinations, the extension of existing datasets, and the reduction of distribution gaps between real and synthetic images.
What carries the argument
MULTI, a two-stage textual inversion process that isolates general factors first and then dataset-specific ones to achieve multi-factor disentanglement.
If this is right
- This setup enables the extension of existing datasets through novel factor combinations.
- Distribution gaps between real and generated images are reduced.
- Specific factors can be modified independently while supporting image-to-image generation with ControlNets.
- The effectiveness is shown through evaluation on the DF-RICO benchmark.
Where Pith is reading between the lines
- If the isolation holds, imaging conditions could be composed modularly in synthesis pipelines much like separate controls for content and style.
- The two-stage pattern might extend to other attributes such as lighting conditions or material properties in later models.
- Practical use would need checks that disentanglement remains stable when applied to camera models and scenes far outside the original training sets.
Load-bearing premise
The two-stage textual inversion isolates general and dataset-specific imaging factors without leakage or mixing between them.
What would settle it
Generate images with novel combinations of factors absent from training and verify through metrics or human evaluation whether each intended factor such as lens type or domain can be identified independently without interference from the others.
Figures



read the original abstract
Recent text-to-image models produce high-quality images, yet text ambiguity hinders precise control when specific styles or objects are required. There have been a number of recent works dealing with learning and composing multiple objects and patterns. However, current work focuses almost entirely on image content, overlooking imaging factors such as camera lens, sensor types, imaging viewpoints, and scenes' domain characteristics. We introduce this new challenge as Imaging Factor Disentanglement and show limitations of current approaches in the regime. We, therefore, propose the new method Multi-factor disentanglement through Textual Inversion (MULTI). It consists of two stages: in the first stage, we learn general factors, and in the second stage, we extract dataset-specific ones. This setup enables the extension of existing datasets and novel factor combinations, thereby reducing distribution gaps. It further supports modifications of specific factors and image-to-image generation via ControlNets. The evaluation on our new DF-RICO benchmark demonstrates the effectiveness of MULTI and highlights the importance of Factor Disentanglement as a new direction of research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Imaging Factor Disentanglement as a new challenge for text-to-image models, noting that existing work overlooks factors such as camera lens, sensor type, viewpoint, and domain. It proposes MULTI, a two-stage textual inversion method in which the first stage learns general factors and the second extracts dataset-specific ones. This is claimed to enable dataset extension, novel factor combinations, distribution-gap reduction, and image-to-image generation via ControlNets. Effectiveness is demonstrated on the new DF-RICO benchmark.
Significance. If the two-stage process can reliably isolate imaging factors, the work would open a useful direction for fine-grained control in generative models that goes beyond object and style composition, with potential benefits for dataset augmentation and generalization.
major comments (1)
- [Method (two-stage textual inversion)] The central claim of disentanglement requires that stage-1 embeddings capture only generic imaging factors (lens, sensor, viewpoint) while stage-2 embeddings capture only dataset-specific residuals, with no cross-contamination. The method description performs sequential optimization of separate pseudo-tokens without orthogonality loss, mutual-information penalty, or cycle-consistency constraint between the two embedding sets. When training images contain correlated factors, the optimization can distribute information across both stages, violating the isolation needed for novel factor recombination and distribution-gap reduction.
minor comments (2)
- The manuscript supplies no implementation details, quantitative metrics, ablation studies, or error analysis, making it impossible to verify whether the described stages actually support the disentanglement claims.
- No equations or formal derivations appear to define the pseudo-token optimization or the separation between general and dataset-specific factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on the two-stage textual inversion method below and will revise the paper to strengthen the presentation of disentanglement.
read point-by-point responses
-
Referee: [Method (two-stage textual inversion)] The central claim of disentanglement requires that stage-1 embeddings capture only generic imaging factors (lens, sensor, viewpoint) while stage-2 embeddings capture only dataset-specific residuals, with no cross-contamination. The method description performs sequential optimization of separate pseudo-tokens without orthogonality loss, mutual-information penalty, or cycle-consistency constraint between the two embedding sets. When training images contain correlated factors, the optimization can distribute information across both stages, violating the isolation needed for novel factor recombination and distribution-gap reduction.
Authors: We appreciate the referee highlighting this key requirement for reliable disentanglement. In MULTI, stage 1 optimizes a set of pseudo-tokens on a broad collection of images drawn from multiple datasets to capture generic imaging factors (lens, sensor, viewpoint), while stage 2 optimizes a separate set of pseudo-tokens on the target dataset with stage-1 tokens frozen, allowing them to encode only the residual dataset-specific variations. The sequential nature and data selection are intended to encourage separation without explicit cross terms. Our experiments on DF-RICO, including novel factor recombination and distribution-gap reduction, provide empirical support for this isolation. That said, we agree that additional regularization would further guard against leakage when factors are correlated. In the revision we will add an orthogonality loss between the two embedding sets, report mutual-information estimates between stages, and include ablation studies on factor swapping to quantify the degree of disentanglement. revision: yes
Circularity Check
No circularity: new method construction with no derived quantities or self-referential definitions
full rationale
The paper proposes MULTI as a two-stage textual inversion procedure for imaging factor disentanglement. No equations, derivations, or quantitative predictions appear in the abstract or description. The central claims concern the empirical behavior of this new architecture on the introduced DF-RICO benchmark and its ability to enable novel factor combinations. These are presented as properties of the proposed construction rather than results obtained by fitting parameters to a subset of data and then predicting closely related quantities, or by any self-citation chain. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are referenced. The method is therefore self-contained as an independent proposal.
Axiom & Free-Parameter Ledger
invented entities (2)
-
MULTI method
no independent evidence
-
DF-RICO benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Agnolucci, L., Baldrati, A., Del Bimbo, A., Bertini, M.: isearle: Improving textual inversion for zero-shot composed image retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
work page 2025
-
[2]
Avrahami,O.,Aberman,K.,Fried,O.,Cohen-Or,D.,Lischinski,D.:Break-a-scene: Extracting multiple concepts from a single image. In: SIGGRAPH Asia. pp. 1–12 (2023)
work page 2023
-
[3]
arXiv preprint arXiv:2506.12447 (2025) 14 S
Baisa, N.L., Pallam, B., Jayavel, A.: Clip-handid: Vision-language model for hand- based person identification. arXiv preprint arXiv:2506.12447 (2025) 14 S. Godavarthy, M. Neuwirth-Trapp et al
-
[4]
Bijelic, M., Gruber, T., Mannan, F., Kraus, F., Ritter, W., Dietmayer, K., Heide, F.: Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather. In: CVPR. pp. 11679–11689 (Jun 2020). https://doi. org/10.1109/CVPR42600.2020.01170
-
[5]
Bishop, C.M., Nasrabadi, N.M.: Pattern recognition and machine learning, vol. 4. Springer (2006)
work page 2006
- [6]
-
[7]
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuScenes: A multimodal dataset for autonomous driving. arXiv preprint arXiv:1903.11027 (May 2020)
-
[8]
arXiv preprint arXiv:2405.12944 (May 2024)
Chen, Z., Qian, Y., Yang, X., Wang, C., Yang, M.: AMFD: Distillation via Adap- tive Multimodal Fusion for Multispectral Pedestrian Detection. arXiv preprint arXiv:2405.12944 (May 2024). https://doi.org/10.48550/arXiv.2405.12944
-
[9]
Dong,Z.,Wei,P.,Lin,L.:Dreamartist:Controllableone-shottext-to-imagegenera- tion via positive-negative adapter: Z. dong et al. International Journal of Computer Vision133(10), 7037–7053 (2025)
work page 2025
- [10]
-
[11]
https://www.flir.com/oem/adas/adas-dataset-form/ (Accessed: 01122024)
FLIR, T.: FREE Teledyne FLIR Thermal Dataset for Algorithm Training. https://www.flir.com/oem/adas/adas-dataset-form/ (Accessed: 01122024)
-
[12]
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-or, D.: An image is worth one word: Personalizing text-to-image genera- tion using textual inversion. In: ICLR (2022)
work page 2022
-
[13]
ACM Transactions On Graphics (TOG)44(4), 1–11 (2025)
Garibi,D.,Yadin,S.,Paiss,R.,Tov,O.,Zada,S.,Ephrat,A.,Michaeli,T.,Mosseri, I., Dekel, T.: Tokenverse: Versatile multi-concept personalization in token modu- lation space. ACM Transactions On Graphics (TOG)44(4), 1–11 (2025)
work page 2025
-
[14]
Nature629(8014), 1034–1040 (May 2024)
Gehrig, D., Scaramuzza, D.: Low-latency automotive vision with event cameras. Nature629(8014), 1034–1040 (May 2024). https://doi.org/10.1038/ s41586-024-07409-w
work page 2024
-
[15]
Gehrig, M., Aarents, W., Gehrig, D., Scaramuzza, D.: DSEC: A Stereo Event Camera Dataset for Driving Scenarios. IEEE Robot. Autom. Lett.6(3), 4947–4954 (Jul 2021). https://doi.org/10.1109/LRA.2021.3068942
-
[16]
Gochoo, M., Otgonbold, M.E., Ganbold, E., Hsieh, J.W., Chang, M.C., Chen, P.Y., Dorj, B., Al Jassmi, H., Batnasan, G., Alnajjar, F., Abduljabbar, M., Lin, F.P.: FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detec- tion. In: CVPR Workshops. pp. 5305–5313 (Jun 2023). https://doi.org/10.1109/ CVPRW59228.2023.00559
-
[17]
Goodfellow, I., Bengio, Y., Courville, A., Bengio, Y.: Deep learning, vol. 1. MIT Press (2016)
work page 2016
-
[18]
Ha, D., Dai, A., Le, Q.V.: Hypernetworks. arXiv preprint arXiv:1609.09106 (2016)
work page internal anchor Pith review arXiv 2016
-
[19]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
work page 2021
-
[20]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
work page 2017
-
[21]
Journal of educational psychology24(6), 417 (1933) MUL TI: Disentangling Imaging Factors 15
Hotelling, H.: Analysis of a complex of statistical variables into principal compo- nents. Journal of educational psychology24(6), 417 (1933) MUL TI: Disentangling Imaging Factors 15
work page 1933
-
[22]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
work page 2022
-
[23]
https://doi.org/10.48550/arXiv.1610.01983
Johnson-Roberson, M., Barto, C., Mehta, R., Sridhar, S.N., Rosaen, K., Vasude- van, R.: Driving in the Matrix: Can Virtual Worlds Replace Human-Generated Annotations for Real World Tasks? arXiv preprint arXiv:1610.01983 (Feb 2017). https://doi.org/10.48550/arXiv.1610.01983
-
[24]
Kansy, M., Naruniec, J., Schroers, C., Gross, M., Weber, R.M.: Reenact anything: Semantic video motion transfer using motion-textual inversion. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–12 (2025)
work page 2025
- [25]
-
[26]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2017)
work page 2017
-
[27]
Journal of machine learn- ing research9(Nov), 2579–2605 (2008)
Maaten, L.v.d., Hinton, G.: Visualizing data using t-sne. Journal of machine learn- ing research9(Nov), 2579–2605 (2008)
work page 2008
- [28]
- [29]
- [30]
-
[31]
on lines and planes of closest fit to systems of points in space
Pearson, K.: Liii. on lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin philosophical magazine and journal of science 2(11), 559–572 (1901)
work page 1901
-
[32]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. In: ICLR (2023)
work page 2023
- [33]
- [34]
-
[35]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
work page 2022
-
[36]
Advances in neural information processing systems29(2016)
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training gans. Advances in neural information processing systems29(2016)
work page 2016
-
[37]
Sensors22(11), 3992 (May 2022)
Schneider, P., Anisimov, Y., Islam, R., Mirbach, B., Rambach, J., Stricker, D., Grandidier, F.: TIMo—A Dataset for Indoor Building Monitoring with a Time- of-Flight Camera. Sensors22(11), 3992 (May 2022). https://doi.org/10.3390/ s22113992
work page 2022
-
[38]
Shentu, J., Watson, M., Al Moubayed, N.: Attencraft: Attention-guided disentan- glement of multiple concepts for text-to-image customization. CoRR (2024) 16 S. Godavarthy, M. Neuwirth-Trapp et al
work page 2024
-
[39]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
In: Proceedingsofthe37thInternationalConferenceonNeuralInformationProcessing Systems
Sohn, K., Ruiz, N., Lee, K., Chin, D.C., Blok, I., Chang, H., Barber, J., Jiang, L., Entis, G., Li, Y., et al.: Styledrop: text-to-image generation in any style. In: Proceedingsofthe37thInternationalConferenceonNeuralInformationProcessing Systems. pp. 66860–66889 (2023)
work page 2023
-
[41]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Sun, T., Segu, M., Postels, J., Wang, Y., Van Gool, L., Schiele, B., Tombari, F., Yu, F.: SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Do- main Adaptation. In: CVPR. pp. 21339–21350 (Jun 2022). https://doi.org/10. 1109/CVPR52688.2022.02068
-
[42]
ACM Transactions on Graphics (TOG)42(6), 1–13 (2023)
Vinker, Y., Voynov, A., Cohen-Or, D., Shamir, A.: Concept decomposition for visual exploration and inspiration. ACM Transactions on Graphics (TOG)42(6), 1–13 (2023)
work page 2023
- [43]
- [44]
-
[45]
arXiv preprint arXiv:2502.13081 (2025)
Wei, Y., Zheng, Y., Zhang, Y., Liu, M., Ji, Z., Zhang, L., Zuo, W.: Personalized image generation with deep generative models: A decade survey. arXiv preprint arXiv:2502.13081 (2025)
-
[46]
In: Medical Imaging with Deep Learning
de Wilde, B., Saha, A., de Rooij, M., Huisman, H., Litjens, G.: Medical diffusion on a budget: Textual inversion for medical image generation. In: Medical Imaging with Deep Learning. pp. 1687–1706. PMLR (2024)
work page 2024
-
[47]
Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing
Wrenninge, M., Unger, J.: Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing. arXiv preprint arXiv:1810.08705 (Oct 2018). https://doi.org/10. 48550/arXiv.1810.08705
work page Pith review arXiv 2018
-
[48]
Xu, C., Xu, Y., Zhang, H., Xu, X., He, S.: Dreamanime: Learning style-identity textualdisentanglementforanimeandbeyond.IEEETransactionsonVisualization and Computer Graphics (2024)
work page 2024
- [49]
-
[50]
arXiv preprint arXiv:2307.08252 (Jul 2023)
Yang, L., Li, L., Xin, X., Sun, Y., Song, Q., Wang, W.: Large-Scale Person Detection and Localization using Overhead Fisheye Cameras. arXiv preprint arXiv:2307.08252 (Jul 2023). https://doi.org/10.48550/arXiv.2307.08252
- [51]
-
[52]
arXiv preprint arXiv:1905.01489 (Jul 2021)
Yogamani, S., Hughes, C., Horgan, J., Sistu, G., Varley, P., O’Dea, D., Uricar, M., Milz, S., Simon, M., Amende, K., Witt, C., Rashed, H., Chennupati, S., Nayak, S., Mansoor, S., Perroton, X., Perez, P.: WoodScape: A multi-task, multi-camera fish- eye dataset for autonomous driving. arXiv preprint arXiv:1905.01489 (Jul 2021). https://doi.org/10.48550/arXi...
-
[53]
arxiv preprint arXiv:1805.04687 (Apr 2020)
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. arxiv preprint arXiv:1805.04687 (Apr 2020)
- [54]
-
[55]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
work page 2018
- [56]
-
[57]
Zhong, W., Yang, H., Liu, Z., He, H., He, Z., Niu, X., Zhang, D., Li, G.: Mod- adapter: Tuning-free and versatile multi-concept personalization via modulation adapter. arXiv preprint arXiv:2505.18612 (2025)
-
[58]
A <source> <sensor> image from <view> captured with <lens> showing <description>
Zhu, P., Wen, L., Du, D., Bian, X., Fan, H., Hu, Q., Ling, H.: Detection and Tracking Meet Drones Challenge. PAMI44(11), 7380–7399 (Nov 2022). https: //doi.org/10.1109/TPAMI.2021.3119563 18 S. Godavarthy, M. Neuwirth-Trapp et al. Supplementary Material S.1 DF-RICO Benchmark To study our method, we build upon RICO benchmark [29], which was initially develo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.