Recognition: 2 theorem links
· Lean TheoremEgoEV-HandPose: Egocentric 3D Hand Pose Estimation and Gesture Recognition with Stereo Event Cameras
Pith reviewed 2026-05-13 05:48 UTC · model grok-4.3
The pith
Stereo event cameras with a bird's-eye-view fusion module deliver accurate 3D bimanual hand tracking and gesture recognition even in low light and occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lifting stereo event features into a canonical bird's-eye-view space and refining them through iterative reprojection-guided loops resolves monocular depth ambiguity and maintains kinematic consistency across bimanual motions, yielding state-of-the-art 3D pose and gesture results on real-world egocentric data where frame-based cameras degrade.
What carries the argument
KeypointBEV, a stereo fusion module that projects features into a canonical bird's-eye-view space and runs an iterative reprojection-guided refinement loop to resolve depth uncertainty.
If this is right
- Event-based egocentric systems can now operate in lighting conditions where conventional RGB cameras produce motion blur.
- Bimanual hand tracking becomes feasible without explicit occlusion handling stages.
- A single end-to-end network can output both 3D keypoints and discrete gesture labels from the same event stream.
- Real-world stereo event datasets enable training and benchmarking of future event-vision models beyond simulated data.
Where Pith is reading between the lines
- The same bird's-eye-view lifting could be applied to full upper-body or object-interaction tracking if additional keypoints are annotated.
- Because event data is sparse, the approach may scale to higher-resolution sensors without proportional compute growth.
- Integration with inertial measurements could further stabilize the refinement loop against ego-motion.
Load-bearing premise
The iterative reprojection loop will reliably correct depth errors and keep hand kinematics consistent even when the camera itself is moving quickly or when calibration is imperfect.
What would settle it
Record a new sequence with rapid head motion or known calibration drift and measure whether MPJPE rises substantially above 30 mm while gesture accuracy drops below 80 percent.
Figures








read the original abstract
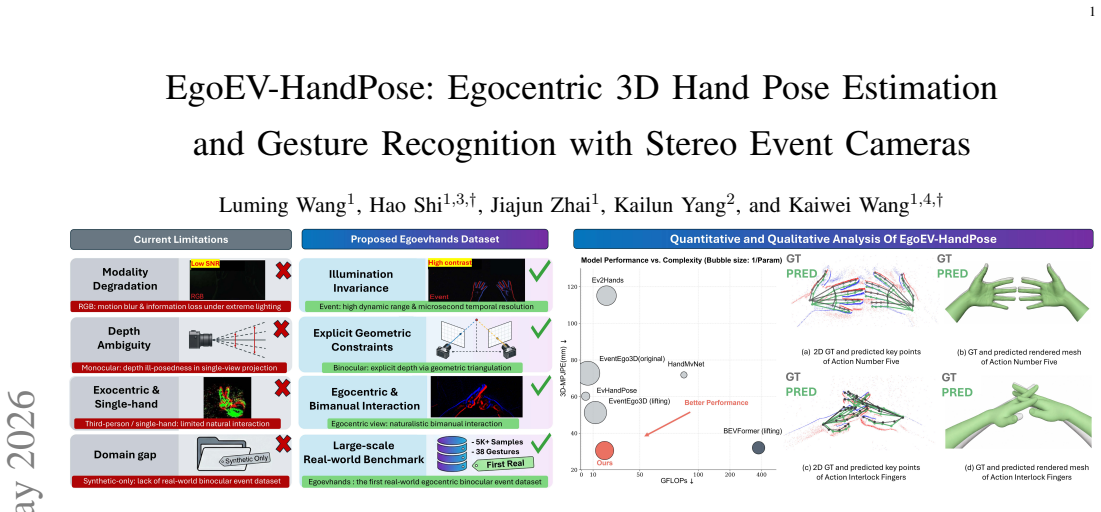
Egocentric 3D hand pose estimation and gesture recognition are essential for immersive augmented/virtual reality, human-computer interaction, and robotics. However, conventional frame-based cameras suffer from motion blur and limited dynamic range, while existing event-based methods are hindered by ego-motion interference, monocular depth ambiguity, and the lack of large-scale real-world stereo datasets. To overcome these limitations, we propose EgoEV-HandPose, an end-to-end framework for joint 3D bimanual pose estimation and gesture recognition from stereo event streams. Central to our approach is KeypointBEV, a flexible stereo fusion module that lifts features into a canonical bird's-eye-view space and employs an iterative reprojection-guided refinement loop to progressively resolve depth uncertainty and enforce kinematic consistency. In addition, we introduce EgoEVHands, the first large-scale real-world stereo event-camera dataset for egocentric hand perception, containing 5,419 annotated sequences with dense 3D/2D keypoints across 38 gesture classes under varying illumination. Extensive experiments demonstrate that EgoEV-HandPose achieves state-of-the-art performance with an MPJPE of 30.54mm and 86.87% Top-1 gesture recognition accuracy, significantly outperforming RGB-based stereo and prior event-camera methods, particularly in low-light and bimanual occlusion scenarios, thereby setting a new benchmark for event-based egocentric perception. The established dataset and source code will be publicly released at https://github.com/ZJUWang01/EgoEV-HandPose.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EgoEV-HandPose, an end-to-end framework for joint 3D bimanual hand pose estimation and gesture recognition from stereo event streams. Its core is KeypointBEV, a stereo fusion module that lifts features into bird's-eye-view space and applies an iterative reprojection-guided refinement loop to resolve depth ambiguity and enforce kinematic consistency. The authors also release EgoEVHands, a new large-scale real-world stereo event dataset with 5,419 sequences, dense 3D/2D keypoints, and 38 gesture classes under varying illumination. Experiments report SOTA results of 30.54 mm MPJPE and 86.87% Top-1 gesture accuracy, outperforming RGB stereo and prior event methods especially under low light and bimanual occlusion.
Significance. If the performance claims hold after addressing the noted concerns, the work would meaningfully advance event-based egocentric perception by mitigating motion blur and dynamic-range limitations of frame cameras while providing the first large real-world stereo event dataset for this task. Public release of the dataset and code would further support reproducibility and benchmarking in immersive AR/VR and robotics applications.
major comments (1)
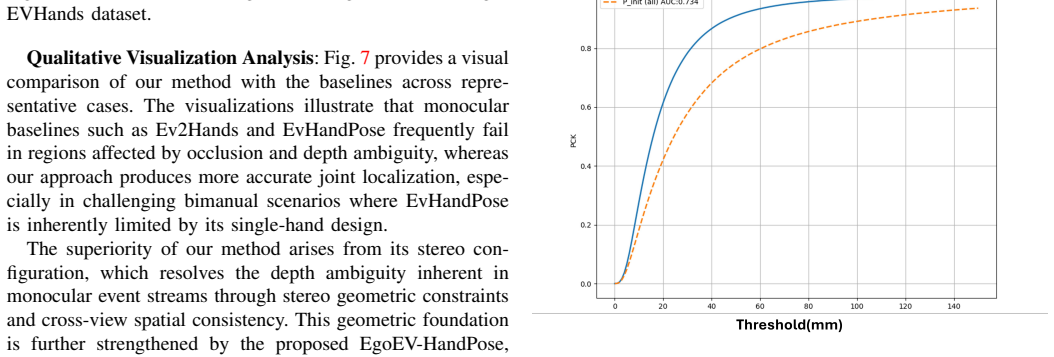
- [KeypointBEV / §3] KeypointBEV description (abstract and §3): the iterative reprojection-guided refinement loop is presented as the mechanism that reliably resolves monocular depth ambiguity and enforces kinematic consistency, yet no quantitative sensitivity analysis is provided for ego-motion magnitude, residual calibration drift, event noise levels, or iteration count. Because the headline MPJPE of 30.54 mm and gesture accuracy rest on this loop converging to correct minima, the absence of such analysis leaves the central empirical claims vulnerable to the exact perturbations that arise in real egocentric stereo streams.
minor comments (2)
- [Abstract] Abstract: the phrase 'significantly outperforming' should be accompanied by the specific baseline MPJPE and accuracy numbers (or a reference to Table X) so readers can immediately gauge the margin.
- [Dataset] Dataset section: clarify the train/validation/test split ratios and whether any sequences were held out by subject or illumination condition; this directly affects claims of generalization to low-light and occlusion scenarios.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address the single major comment below and have revised the manuscript accordingly to strengthen the validation of KeypointBEV.
read point-by-point responses
-
Referee: [KeypointBEV / §3] KeypointBEV description (abstract and §3): the iterative reprojection-guided refinement loop is presented as the mechanism that reliably resolves monocular depth ambiguity and enforces kinematic consistency, yet no quantitative sensitivity analysis is provided for ego-motion magnitude, residual calibration drift, event noise levels, or iteration count. Because the headline MPJPE of 30.54 mm and gesture accuracy rest on this loop converging to correct minima, the absence of such analysis leaves the central empirical claims vulnerable to the exact perturbations that arise in real egocentric stereo streams.
Authors: We agree that the original submission lacked a dedicated quantitative sensitivity analysis of the iterative reprojection-guided refinement loop. This is a fair observation, as the loop is central to resolving depth ambiguity. In the revised manuscript we have added a new subsection (now §3.4) and corresponding supplementary figures that report controlled experiments varying ego-motion magnitude (0–1.0 m/s), residual calibration drift (0–3 pixels), event noise density (0–20% polarity flips), and iteration count (1–6). Within the operating ranges observed in EgoEVHands, MPJPE remains below 35 mm and Top-1 gesture accuracy above 85%, with convergence typically reached by iteration 3. These results are now explicitly tied to the headline metrics and support the loop’s reliability under realistic egocentric perturbations. revision: yes
Circularity Check
No significant circularity detected in derivation or claims
full rationale
The paper describes an end-to-end neural framework (KeypointBEV) for stereo event-based hand pose estimation and introduces a new dataset (EgoEVHands) for empirical evaluation. Reported metrics (MPJPE 30.54 mm, 86.87% accuracy) are standard held-out test-set results on real-world sequences, not quantities defined in terms of fitted parameters or self-referential equations. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided abstract or method summary; the derivation chain consists of architectural choices and supervised training whose outputs are independently falsifiable on external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- network weights and hyperparameters
axioms (2)
- domain assumption Stereo event cameras are calibrated and synchronized
- domain assumption Hand kinematics provide useful consistency constraints
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KeypointBEV ... lifts features into a canonical bird’s-eye-view space and employs an iterative reprojection-guided refinement loop to progressively resolve depth uncertainty and enforce kinematic consistency
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LBEV = λ3d L3D + Σ wk (L(k)Iter2D + L(k)3D)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ego4D: Around the world in 3,000 hours of egocentric video,
K. Graumanet al., “Ego4D: Around the world in 3,000 hours of egocentric video,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 11, pp. 9468–9509, 2025
work page 2025
-
[2]
MEgATrack: monochrome egocentric articulated hand- tracking for virtual reality,
S. Hanet al., “MEgATrack: monochrome egocentric articulated hand- tracking for virtual reality,”ACM Transactions on Graphics, vol. 39, no. 4, pp. 87–1, 2020
work page 2020
-
[3]
EgoGesture: A new dataset and benchmark for egocentric hand gesture recognition,
Y . Zhang, C. Cao, J. Cheng, and H. Lu, “EgoGesture: A new dataset and benchmark for egocentric hand gesture recognition,”IEEE Transactions on Multimedia, vol. 20, no. 5, pp. 1038–1050, 2018
work page 2018
-
[4]
Assembly101: A large-scale multi-view video dataset for understanding procedural activities,
F. Seneret al., “Assembly101: A large-scale multi-view video dataset for understanding procedural activities,” inProc. CVPR, 2022, pp. 21 064– 21 074
work page 2022
-
[5]
First-person hand action benchmark with RGB-D videos and 3D hand pose annota- tions,
G. Garcia-Hernando, S. Yuan, S. Baek, and T.-K. Kim, “First-person hand action benchmark with RGB-D videos and 3D hand pose annota- tions,” inProc. CVPR, 2018, pp. 409–419. 14
work page 2018
-
[6]
Egovsr: To- wards high-quality egocentric video super-resolution,
Y . Chi, J. Gu, J. Zhang, W. Yang, and Y . Tian, “Egovsr: To- wards high-quality egocentric video super-resolution,”arXiv preprint arXiv:2305.14708, 2023
-
[7]
G. Gallegoet al., “Event-based vision: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 1, pp. 154–180, 2022
work page 2022
-
[8]
EventEgoHands: Event-based egocentric 3D hand mesh reconstruction,
R. Hara, W. Ikeda, M. Hatano, and M. Isogawa, “EventEgoHands: Event-based egocentric 3D hand mesh reconstruction,” inProc. ICIP, 2025, pp. 1199–1204
work page 2025
-
[9]
EventEgo3D: 3D human motion capture from egocentric event streams,
C. Millerdurai, H. Akada, J. Wang, D. Luvizon, C. Theobalt, and V . Golyanik, “EventEgo3D: 3D human motion capture from egocentric event streams,” inProc. CVPR, 2024, pp. 1186–1195
work page 2024
-
[10]
EventHands: Real-time neural 3D hand pose estima- tion from an event stream,
V . Rudnevet al., “EventHands: Real-time neural 3D hand pose estima- tion from an event stream,” inProc. ICCV, 2021, pp. 12 365–12 375
work page 2021
-
[11]
EvHandPose: Event- based 3D hand pose estimation with sparse supervision,
J. Jiang, J. Li, B. Zhang, X. Deng, and B. Shi, “EvHandPose: Event- based 3D hand pose estimation with sparse supervision,”IEEE Trans- actions on Pattern Analysis and Machine Intelligence, vol. 46, no. 9, pp. 6416–6430, 2024
work page 2024
-
[12]
3D pose estimation of two interacting hands from a monocular event camera,
C. Millerduraiet al., “3D pose estimation of two interacting hands from a monocular event camera,” inProc. 3DV, 2024, pp. 291–301
work page 2024
-
[13]
HandMvNet: Real-time 3D hand pose estimation using multi-view cross-attention fusion,
M. A. Ali, N. Robertini, and D. Stricker, “HandMvNet: Real-time 3D hand pose estimation using multi-view cross-attention fusion,” inProc. VISAPP, 2025, pp. 555–562
work page 2025
-
[14]
Exploring event-based human pose estimation with 3D event representations,
X. Yinet al., “Exploring event-based human pose estimation with 3D event representations,”Computer Vision and Image Understanding, vol. 249, p. 104189, 2024
work page 2024
-
[15]
DHP19: Dynamic vision sensor 3D human pose dataset,
E. Calabreseet al., “DHP19: Dynamic vision sensor 3D human pose dataset,” inProc. CVPRW, 2019, pp. 1695–1704
work page 2019
-
[16]
EgoEvGesture: Gesture recognition based on egocentric event camera,
L. Wang, H. Shi, X. Yin, K. Yang, K. Wang, and J. Bai, “EgoEvGesture: Gesture recognition based on egocentric event camera,” inProc. SMC, 2025, pp. 6606–6613
work page 2025
-
[17]
The EPIC-KITCHENS dataset: Collection, challenges and baselines,
D. Damenet al., “The EPIC-KITCHENS dataset: Collection, challenges and baselines,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 11, pp. 4125–4141, 2021
work page 2021
-
[18]
T. Kwon, B. Tekin, J. St"uhmer, F. Bogo, and M. Pollefeys, “H2O: Two hands manipulating objects for first person interaction recognition,” in Proc. ICCV, 2021, pp. 10 118–10 128
work page 2021
-
[19]
ARCTIC: A dataset for dexterous bimanual hand-object manipulation,
Z. Fanet al., “ARCTIC: A dataset for dexterous bimanual hand-object manipulation,” inProc. CVPR, 2023, pp. 12 943–12 954
work page 2023
-
[20]
HOI4D: A 4D egocentric dataset for category-level human-object interaction,
Y . Liuet al., “HOI4D: A 4D egocentric dataset for category-level human-object interaction,” inProc. CVPR, 2022, pp. 20 981–20 990
work page 2022
-
[21]
A low power, fully event-based gesture recognition system,
A. Amiret al., “A low power, fully event-based gesture recognition system,” inProc. CVPR, 2017, pp. 7388–7397
work page 2017
-
[22]
E2(GO)MOTION: Motion augmented event stream for egocentric action recognition,
C. Plizzariet al., “E2(GO)MOTION: Motion augmented event stream for egocentric action recognition,” inProc. CVPR, 2022, pp. 19 903– 19 915
work page 2022
-
[23]
EHoA: A benchmark for task- oriented hand-object action recognition via event vision,
W. Chen, S.-C. Liu, and J. Zhang, “EHoA: A benchmark for task- oriented hand-object action recognition via event vision,”IEEE Transac- tions on Industrial Informatics, vol. 20, no. 8, pp. 10 304–10 313, 2024
work page 2024
-
[24]
Helios: An extremely low power event-based gesture recognition for always-on smart eyewear,
P. Bhattacharyyaet al., “Helios: An extremely low power event-based gesture recognition for always-on smart eyewear,” inProc. ECCV, 2024, pp. 168–184
work page 2024
-
[25]
Complement- ing event streams and RGB frames for hand mesh reconstruction,
J. Jiang, X. Zhou, B. Wang, X. Deng, C. Xu, and B. Shi, “Complement- ing event streams and RGB frames for hand mesh reconstruction,” in Proc. CVPR, 2024, pp. 24 944–24 954
work page 2024
-
[26]
AssemblyHands: Towards egocentric activity understanding via 3D hand pose estimation,
T. Ohkawa, K. He, F. Sener, T. Hodan, L. Tran, and C. Keskin, “AssemblyHands: Towards egocentric activity understanding via 3D hand pose estimation,” inProc. CVPR, 2023, pp. 12 999–13 008
work page 2023
-
[27]
Ego2HandsPose: A dataset for egocentric two- hand 3D global pose estimation,
F. Lin and T. Martinez, “Ego2HandsPose: A dataset for egocentric two- hand 3D global pose estimation,” inProc. WACV, 2024, pp. 4363–4371
work page 2024
-
[28]
Learning to estimate 3D hand pose from single RGB images,
C. Zimmermann and T. Brox, “Learning to estimate 3D hand pose from single RGB images,” inProc. ICCV, 2017, pp. 4913–4921
work page 2017
-
[29]
HOPE-Net: A graph-based model for hand-object pose estimation,
B. Doosti, S. Naha, M. Mirbagheri, and D. J. Crandall, “HOPE-Net: A graph-based model for hand-object pose estimation,” inProc. CVPR, 2020, pp. 6607–6616
work page 2020
-
[30]
HandJoKe: Joint-guided keypoint denoising transformer for depth-based 3D hand pose estimation,
J. Gan, L. Chen, P. Hu, J. Leng, W. Li, and X. Gao, “HandJoKe: Joint-guided keypoint denoising transformer for depth-based 3D hand pose estimation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 1, pp. 861–873, 2026
work page 2026
-
[31]
Embodied hands: modeling and capturing hands and bodies together,
J. Romero, D. Tzionas, and M. J. Black, “Embodied hands: modeling and capturing hands and bodies together,”ACM Transactions on Graph- ics (TOG), vol. 36, no. 6, pp. 1–17, 2017
work page 2017
-
[32]
G. Moon and K. M. Lee, “I2L-MeshNet: Image-to-lixel prediction network for accurate 3D human pose and mesh estimation from a single RGB image,” inProc. ECCV, 2020, pp. 752–768
work page 2020
-
[33]
Pushing the envelope for RGB- based dense 3D hand pose estimation via neural rendering,
S. Baek, K. I. Kim, and T.-K. Kim, “Pushing the envelope for RGB- based dense 3D hand pose estimation via neural rendering,” inProc. CVPR, 2019, pp. 1067–1076
work page 2019
-
[34]
G. Moon, S.-I. Yu, H. Wen, T. Shiratori, and K. M. Lee, “InterHand2. 6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image,” inProc. ECCV, 2020, pp. 548–564
work page 2020
-
[35]
3D hand shape and pose estimation from a single RGB image,
L. Geet al., “3D hand shape and pose estimation from a single RGB image,” inProc. CVPR, 2019, pp. 10 825–10 834
work page 2019
-
[36]
HOnnotate: A method for 3D annotation of hand and object poses,
S. Hampali, M. Rad, M. Oberweger, and V . Lepetit, “HOnnotate: A method for 3D annotation of hand and object poses,” inProc. CVPR, 2020, pp. 3193–3203
work page 2020
-
[37]
3D hand pose estimation from monocular RGB with feature interaction module,
S. Guo, E. Rigall, Y . Ju, and J. Dong, “3D hand pose estimation from monocular RGB with feature interaction module,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 8, pp. 5293– 5306, 2022
work page 2022
-
[38]
POEM: Reconstructing hand in a point embedded multi- view stereo,
L. Yanget al., “POEM: Reconstructing hand in a point embedded multi- view stereo,” inProc. CVPR, 2023, pp. 21 108–21 112
work page 2023
-
[39]
In my perspective, in my hands: Accurate egocentric 2D hand pose and action recognition,
W. Mucha and M. Kampel, “In my perspective, in my hands: Accurate egocentric 2D hand pose and action recognition,” inProc. FG, 2024, pp. 1–9
work page 2024
-
[40]
Spatial–temporal synchronous transformer for skeleton-based hand gesture recognition,
D. Zhao, H. Li, and S. Yan, “Spatial–temporal synchronous transformer for skeleton-based hand gesture recognition,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 3, pp. 1403– 1412, 2023
work page 2023
-
[41]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D,” inProc. ECCV, 2020, pp. 194–210
work page 2020
-
[42]
MPL: Lifting 3D human pose from multi-view 2D poses,
S. A. Ghasemzadeh, A. Alahi, and C. De Vleeschouwer, “MPL: Lifting 3D human pose from multi-view 2D poses,” inProc. ECCV, 2024, pp. 36–52
work page 2024
-
[43]
X. Zhao, L. Yang, W. Huang, Q. Wang, X. Wang, and Y . Lou, “EV- TIFNet: lightweight binocular fusion network assisted by event camera time information for 3D human pose estimation,”Journal of Real-Time Image Processing, vol. 21, no. 4, p. 150, 2024
work page 2024
-
[44]
Learnable triangulation of human pose,
K. Iskakov, E. Burkov, V . Lempitsky, and Y . Malkov, “Learnable triangulation of human pose,” inProc. ICCV, 2019, pp. 7717–7726
work page 2019
-
[45]
Z. Liet al., “BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” inProc. ECCV, 2022, pp. 1–18
work page 2022
-
[46]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
J. Huanget al., “BEVDet: High-performance multi-camera 3D object detection in bird-eye-view,” inarXiv preprint arXiv:2112.11790, 2021
work page internal anchor Pith review arXiv 2021
-
[47]
EgoPoseFormer: A simple baseline for stereo egocentric 3D human pose estimation,
C. Yang, A. Tkach, S. Hampali, L. Zhang, E. J. Crowley, and C. Keskin, “EgoPoseFormer: A simple baseline for stereo egocentric 3D human pose estimation,” inProc. ECCV, 2024, pp. 401–417
work page 2024
-
[48]
MLPHand: Real time multi-view 3D hand reconstruction via MLP modeling,
J. Yang, J. Li, G. Li, H.-Y . Wu, Z. Shen, and Z. Fan, “MLPHand: Real time multi-view 3D hand reconstruction via MLP modeling,” inProc. ECCV, 2024, pp. 407–424
work page 2024
-
[49]
Two viewpoints based real-time recognition for hand gestures,
A. Krishan Kumar, A. Kaushal Kumar, and S. Guo, “Two viewpoints based real-time recognition for hand gestures,”IET Image Processing, vol. 14, no. 17, pp. 4606–4613, 2020
work page 2020
-
[50]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Renet al., “Grounded SAM: Assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
MediaPipe: A Framework for Building Perception Pipelines
C. Lugaresiet al., “MediaPipe: A framework for building perception pipelines,”arXiv preprint arXiv:1906.08172, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[52]
MobileHumanPose: Toward real-time 3D human pose estimation in mobile devices,
S. Choi, S. Choi, and C. Kim, “MobileHumanPose: Toward real-time 3D human pose estimation in mobile devices,” inProc. CVPRW, 2021, pp. 2328–2338
work page 2021
-
[53]
Simple baselines for human pose estimation and tracking,
B. Xiao, H. Wu, and Y . Wei, “Simple baselines for human pose estimation and tracking,” inProc. ECCV, 2018, pp. 466–481
work page 2018
-
[54]
PointNet: Deep learning on point sets for 3D classification and segmentation,
R. Q. Charles, H. Su, M. Kaichun, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” inProc. CVPR, 2017, pp. 77–85
work page 2017
-
[55]
Dynamic graph CNN for learning on point clouds,
Y . Wang, Y . Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, “Dynamic graph CNN for learning on point clouds,”ACM Transactions on Graphics (TOG), vol. 38, no. 5, pp. 1–12, 2019
work page 2019
-
[56]
H. Zhao, L. Jiang, J. Jia, P. Torr, and V . Koltun, “Point transformer,” in Proc. ICCV, 2021, pp. 16 239–16 248
work page 2021
-
[57]
VMV-GCN: V olumetric multi-view based graph CNN for event stream classification,
B. Xie, Y . Deng, Z. Shao, H. Liu, and Y . Li, “VMV-GCN: V olumetric multi-view based graph CNN for event stream classification,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 1976–1983, 2022
work page 1976
-
[58]
V oxel-based multi-scale transformer network for event stream processing,
D. Liu, T. Wang, and C. Sun, “V oxel-based multi-scale transformer network for event stream processing,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, pp. 2112–2124, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.