BioSEN: A Bio-acoustic Signal Enhancement Network for Animal Vocalizations
Pith reviewed 2026-05-15 07:33 UTC · model grok-4.3
The pith
BioSEN adapts speech enhancement methods into a lighter network that cleans animal vocalization recordings as well as or better than existing models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
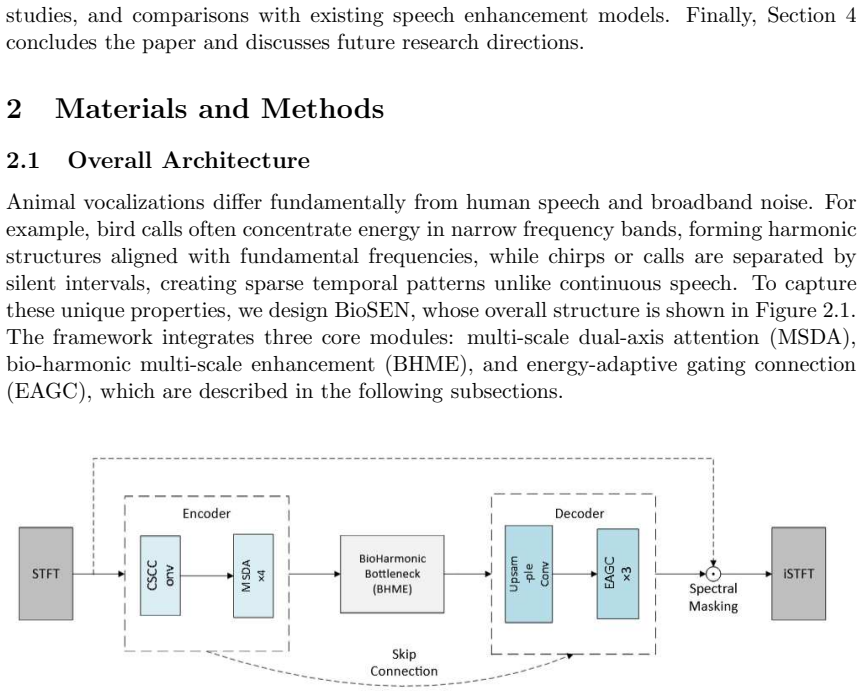
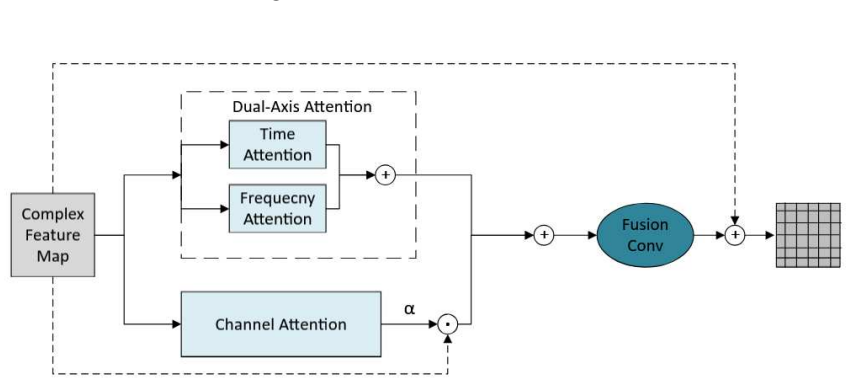
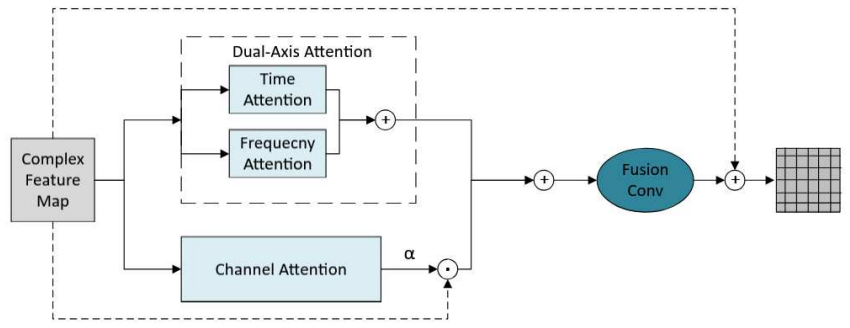
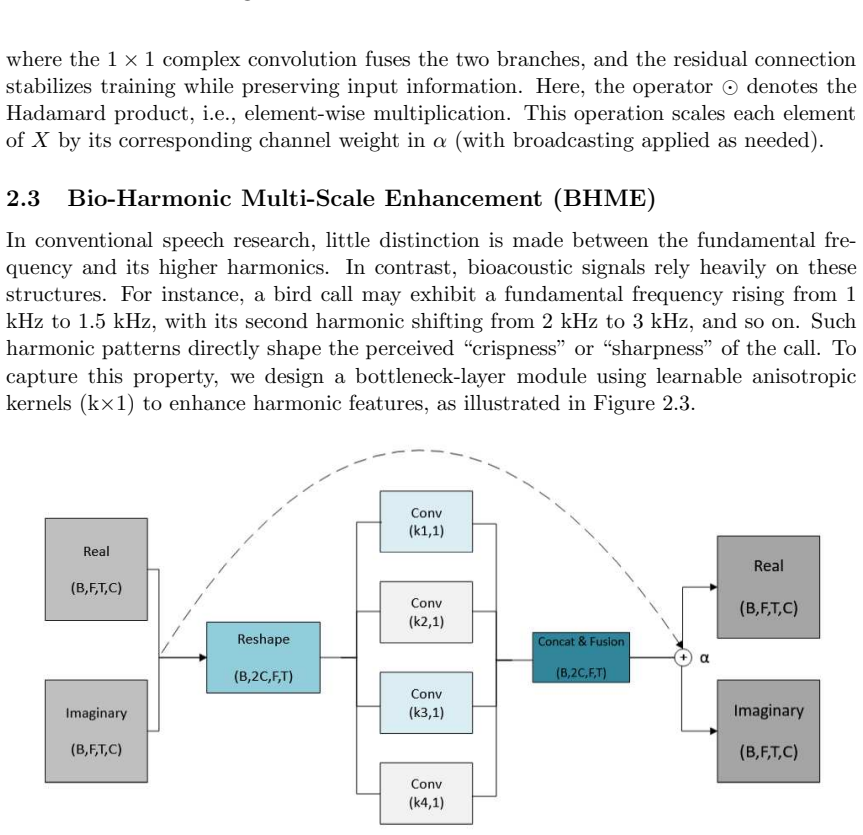
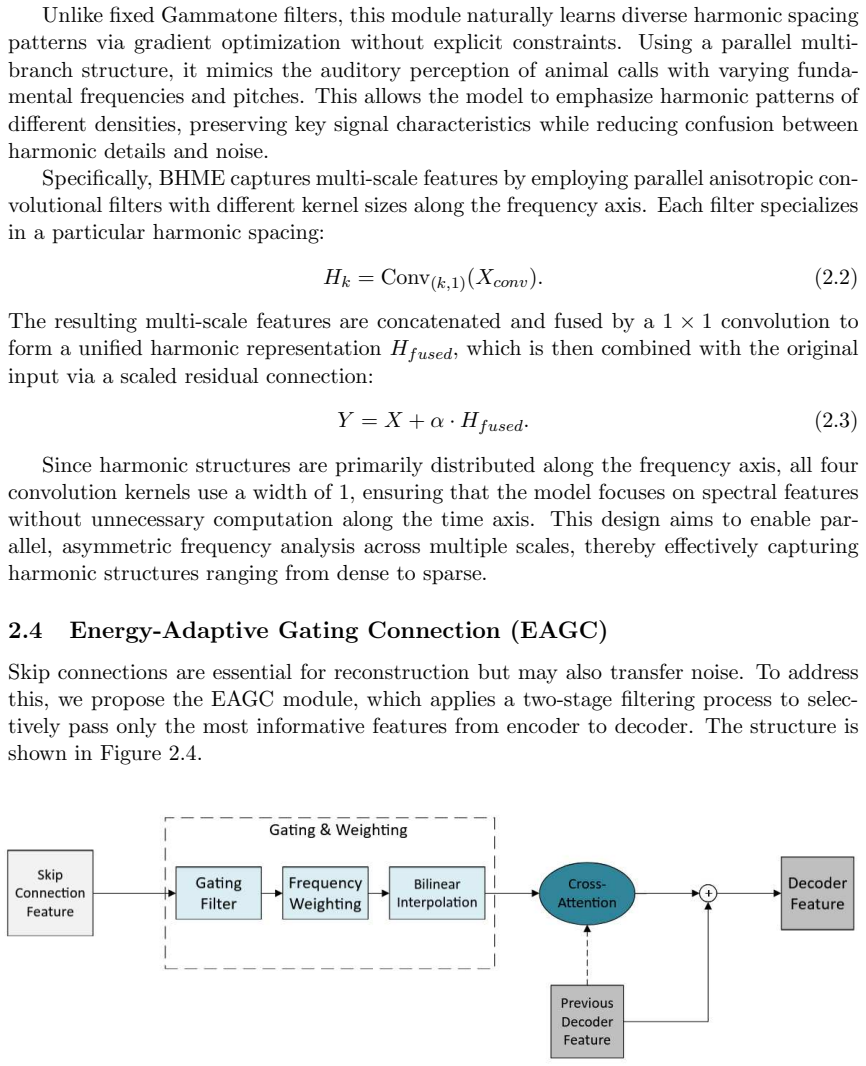
BioSEN consists of a multi-scale dual-axis attention unit for time-frequency feature extraction, a bio-harmonic multi-scale enhancement unit for capturing harmonic structures, and an energy-adaptive gating connection unit that applies frequency weights to prevent vocalizations from being removed as noise. When evaluated on three bioacoustic datasets, this architecture matches or exceeds state-of-the-art speech enhancement models while requiring substantially less computation.
What carries the argument
BioSEN's three-module architecture, especially the energy-adaptive gating connection unit that uses frequency weights to preserve animal vocalizations during enhancement.
If this is right
- Bioacoustic datasets can be cleaned effectively for downstream analysis such as species identification without high computational cost.
- Conservation monitoring systems gain the ability to process field recordings in real time on modest hardware.
- Speech enhancement techniques transfer to animal sounds when modified for harmonics and energy patterns.
- Reduced model complexity enables wider deployment in biodiversity projects with limited resources.
- Noisy animal recordings become more usable for long-term ecological studies.
Where Pith is reading between the lines
- The efficiency could support embedding the model in portable sensors for continuous on-site wildlife tracking.
- Similar modular designs might extend to enhancement of other non-speech sounds such as insect calls or marine acoustics.
- Broad generalization would reduce reliance on large labeled datasets for each new species.
- Cross-domain audio processing in ecology becomes more feasible if the gating mechanism proves robust beyond the tested cases.
Load-bearing premise
Adaptations of speech enhancement methods with these modules will generalize across diverse animal species and recording conditions without requiring extensive species-specific retraining or validation.
What would settle it
Applying BioSEN to recordings from a previously untested animal species or under substantially different noise conditions and observing that it falls below speech model performance or needs major retraining to recover accuracy.
Figures
read the original abstract
Most work in audio enhancement targets human speech, while bioacoustics is less studied due to noisy recordings and the distinct traits of animal sounds. To fill this gap, we adapt speech enhancement methods and build BioSEN, a model made for bioacoustic signals. BioSEN has three modules: a multi-scale dual-axis attention unit for time-frequency feature extraction, a bio-harmonic multi-scale enhancement unit for capturing harmonic structures, and an energy-adaptive gating connection unit that uses frequency weights to keep vocalizations from being removed as noise. Tests on three bioacoustic datasets show that BioSEN matches or exceeds state-of-the-art speech enhancement models while using far less computation. These results show BioSEN's strength for bioacoustic audio enhancement and its promise for biodiversity monitoring and conservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BioSEN, a neural network architecture for enhancing bio-acoustic signals from animal vocalizations. The model adapts speech enhancement methods and incorporates three specialized modules: a multi-scale dual-axis attention unit for extracting time-frequency features, a bio-harmonic multi-scale enhancement unit to capture harmonic structures in animal sounds, and an energy-adaptive gating connection unit that uses frequency weights to prevent removal of vocalizations as noise. The central claim is that evaluations on three bioacoustic datasets show BioSEN matching or exceeding state-of-the-art speech enhancement models while requiring substantially less computational resources.
Significance. Should the empirical results be confirmed with rigorous validation, this contribution would be significant for the field of bioacoustics. It addresses the gap in audio enhancement for non-speech signals by providing a computationally efficient model tailored to the characteristics of animal vocalizations. This has direct implications for biodiversity monitoring, conservation efforts, and automated analysis of field recordings, where noise is prevalent and computational resources may be limited.
major comments (2)
- [§4 (Experimental Evaluation)] §4 (Experimental Evaluation): The abstract and available text report performance gains on three bioacoustic datasets but provide no details on the specific baselines implemented, the evaluation metrics used (e.g., whether SNR, STOI, or bioacoustic-specific measures), error bars or statistical significance, dataset characteristics (species, recording conditions, sizes), or training procedures. This information is load-bearing for assessing the claim that BioSEN matches or exceeds SOTA with less computation.
- [§3 (Model Architecture)] §3 (Model Architecture): The description of the three modules (multi-scale dual-axis attention unit, bio-harmonic multi-scale enhancement unit, energy-adaptive gating connection unit) is high-level; without equations or diagrams showing how they differ from standard speech enhancement components, it is difficult to evaluate the novelty and the rationale for their design choices.
minor comments (1)
- [Abstract] Abstract: The phrase 'far less computation' is imprecise; the manuscript should quantify this (e.g., number of parameters, FLOPs, or inference time) in comparison to the baselines.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive evaluation of the potential significance of BioSEN for bioacoustics applications. We address each major comment below and will revise the manuscript to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [§4 (Experimental Evaluation)] §4 (Experimental Evaluation): The abstract and available text report performance gains on three bioacoustic datasets but provide no details on the specific baselines implemented, the evaluation metrics used (e.g., whether SNR, STOI, or bioacoustic-specific measures), error bars or statistical significance, dataset characteristics (species, recording conditions, sizes), or training procedures. This information is load-bearing for assessing the claim that BioSEN matches or exceeds SOTA with less computation.
Authors: We agree that §4 currently lacks sufficient detail to fully substantiate the empirical claims. In the revised manuscript we will expand the experimental evaluation section to explicitly list all baselines (including the specific speech enhancement models and their implementations), the full set of metrics (SNR, STOI, PESQ, and bioacoustic-specific measures such as vocalization detection F1-score), error bars computed over multiple random seeds with statistical significance tests (e.g., paired t-tests), complete dataset descriptions (species, recording environments, total duration, train/validation/test splits), and training procedures (optimizer, learning rate schedule, batch size, loss function, and hardware used). We will also add a table summarizing computational cost (FLOPs, parameters, inference time) for direct comparison. revision: yes
-
Referee: [§3 (Model Architecture)] §3 (Model Architecture): The description of the three modules (multi-scale dual-axis attention unit, bio-harmonic multi-scale enhancement unit, energy-adaptive gating connection unit) is high-level; without equations or diagrams showing how they differ from standard speech enhancement components, it is difficult to evaluate the novelty and the rationale for their design choices.
Authors: We acknowledge that the current description of the three modules in §3 is high-level. In the revision we will add the full mathematical formulations (equations) for each component, including the multi-scale dual-axis attention mechanism, the bio-harmonic multi-scale enhancement operations that explicitly model harmonic structures, and the energy-adaptive gating equations that incorporate frequency-dependent weights. We will also include a new figure with block diagrams that contrast each module against the corresponding standard blocks in speech enhancement networks (e.g., dual-path RNN or conformer layers) to clearly illustrate the bioacoustic-specific modifications and their motivation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents BioSEN as an empirical adaptation of speech-enhancement architectures to bioacoustic signals, with performance claims resting entirely on standard dataset comparisons rather than any derivation chain. No equations, fitted parameters renamed as predictions, self-definitional modules, or load-bearing self-citations appear in the abstract or described structure; the three modules are introduced as design choices whose value is assessed externally via metrics on held-out bioacoustic recordings. This leaves the central claim self-contained and falsifiable against independent baselines.
Axiom & Free-Parameter Ledger
free parameters (3)
- multi-scale attention hyperparameters
- harmonic enhancement scales
- energy-adaptive gating weights
axioms (2)
- domain assumption Neural networks can learn useful time-frequency representations from labeled or paired noisy-clean audio data.
- domain assumption Animal vocalizations exhibit distinct harmonic structures separable from background noise via learned filters.
invented entities (3)
-
multi-scale dual-axis attention unit
no independent evidence
-
bio-harmonic multi-scale enhancement unit
no independent evidence
-
energy-adaptive gating connection unit
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kohlberg, A. B., Myers, C. R., Figueroa, L. L. (2024). Fro m buzzes to bytes: A sys- tematic review of automated bioacoustics models used to det ect, classify and monitor insects. J. Appl. Ecol. , 61(6), 1199–1211
work page 2024
-
[2]
Navine, A. K., Camp, R. J., Weldy, M. J., Denton, T., Hart, P. J. (2024). Counting the chorus: A bioacoustic indicator of population density. Ecological Indicators, 169, 112930
work page 2024
-
[3]
Rasmussen, J. H., Stowell, D., Briefer, E. F. (2024). Sou nd evidence for biodiversity monitoring. Science, 385(6705), 138–140
work page 2024
-
[4]
Sharma, S., Sato, K., Gautam, B. P. (2023). A methodologi cal literature review of acoustic wildlife monitoring using artificial intelligenc e tools and techniques. Sustain- ability, 15(9), 7128
work page 2023
-
[5]
Gajecki, T., Nogueira, W. (2025). Adversarial learning for end-to-end cochlear speech denoising using lightweight deep learning models. Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 1–5
work page 2025
-
[6]
Dementyev, A., Reddy, C. K. A., Wisdom, S., Chatlani, N., Hershey, J. R., Lyon, R. F. (2025). Towards sub-millisecond latency real-time spee ch enhancement models on hearables. Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 1–5
work page 2025
-
[7]
Zhao, Y., Xie, Y., Ren, J., Wang, W., Xu, J. (2025). Dual-a xis spectrum attention network: A robust model for underwater acoustic signal deno ising. Applied Acoustics, 240, 110865
work page 2025
-
[8]
Tang, J., Chen, Z., Chen, M. (2025). A novel underwater ac oustic signal denoising model based on complex convolution dual-branch multi-scal e attention network. Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 1–5
work page 2025
-
[9]
Barnhill, A., N¨ oth, E., Maier, A., Bergler, C. (2024). A NIMAL-CLEAN: A deep denoising toolkit for animal-independent signal enhancem ent. Proc. Interspeech
work page 2024
-
[10]
Juodakis, J., Marsland, S. (2022). Wind-robust sound e vent detection and denoising for bioacoustics. Methods Ecol. Evol. , 13, 2005–2017
work page 2022
- [11]
-
[12]
, Pietquin, O., Effenberger, F., Cusimano, M
Miron, M., Keen, S., Liu, J.-Y., Hoffman, B., Hagiwara, M. , Pietquin, O., Effenberger, F., Cusimano, M. (2024). Biodenoising: animal vocalizatio n denoising without access to clean data. arXiv preprint arXiv:2410.03427
-
[13]
Sarkar, E., Magimai.-Doss, M. (2025). Comparing self- supervised learning models pre-trained on human speech and animal vocalizations for bi oacoustics processing. Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 1–5
work page 2025
-
[14]
Vellinga, W. (2025). Xeno-canto – bird sounds from arou nd the world. Xeno-canto Foundation for Nature Sounds, [Online]. Available: https://doi.org/10.15468/qv0ksn. 9
-
[15]
Earth species library: O pen datasets for bioacoustic research
Earth Species Project (2020). Earth species library: O pen datasets for bioacoustic research. [Online]. Available: https://github.com/earthspecies/library
work page 2020
-
[16]
Mumm, C. A. S., Kn¨ ornschild, M. (2014). The Vocal Repertoire of Adult and Neonate Giant Otters (Pteronura brasiliensis). PLoS ONE , 9(11), e112562
work page 2014
-
[17]
Elie, J. E., Theunissen, F. E. (2018). Zebra finches iden tify individuals using vocal signatures unique to each call type. Nature Communications, 9, 4026
work page 2018
-
[18]
Yin, S., McCowan, B. (2004). Acoustic similarity and affi liation in rhesus macaques (Macaca mulatta). Animal Behaviour , 68, 343-355
work page 2004
-
[19]
Yang, L., Liu, W., Meng, R., Lee, G., Baek, S., Moon, H.-G . (2024). FSPEN: An ultra-lightweight network for real-time speech enhanceme nt. Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 10671–10675
work page 2024
-
[20]
Yan, H., Zhang, J., Fan, C., Zhou, Y., Liu, P. (2025). LiS enNet: Lightweight sub- band and dual-path modeling for real-time speech enhanceme nt. Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 1–5
work page 2025
- [21]
-
[22]
Hu, Y., Liu, Y., Lv, S., Xing, M., Zhang, S., Fu, Y., Wu, J. , Zhang, B., Xie, L. (2020). DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement. arXiv preprint arXiv:2008.00264
-
[23]
Chen, J., Wang, Z., Tuo, D., Wu, Z., Kang, S., Meng, H. (20 22). FullSubNet+: Channel attention FullSubNet with complex spectrograms fo r speech enhancement. Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP) , 7857–7861. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.