Recognition: no theorem link
DelAC: A Multi-agent Reinforcement Learning of Team-Symmetric Stochastic Games
Pith reviewed 2026-05-14 21:26 UTC · model grok-4.3
The pith
Team-symmetric stochastic games always have a team-symmetric Nash equilibrium that a new actor-critic algorithm can locate efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In team-symmetric stochastic games with m greater than or equal to two teams, players within each team possess symmetric identities and a common payoff function, which guarantees the existence of a team-symmetric Nash equilibrium. This equilibrium is recovered by solving an associated linear complementarity problem. The authors introduce DelAC, an actor-critic multi-agent reinforcement learning algorithm built on this equilibrium concept, and demonstrate through simulation that it outperforms many existing multi-agent reinforcement learning algorithms.
What carries the argument
The team-symmetric Nash equilibrium, expressed and solved as a linear complementarity problem, which directly supplies the policy gradients and value estimates inside the DelAC actor-critic update rules.
If this is right
- Any team-symmetric stochastic game is guaranteed to contain at least one equilibrium that respects the team partition.
- The linear complementarity formulation yields an exact computational route to that equilibrium without enumerating all joint policies.
- DelAC inherits convergence properties from the underlying equilibrium and therefore inherits stability guarantees unavailable to generic multi-agent learners.
- Performance improvements observed in simulation follow directly from restricting the policy search to the symmetric subspace.
- The method scales to larger numbers of teams provided the symmetry assumption continues to hold.
Where Pith is reading between the lines
- The symmetry reduction could be applied to continuous-time or partially observable variants if the payoff identity still holds.
- Real-world systems such as interchangeable robot teams or symmetric auction participants become natural test beds for DelAC.
- Exploiting team symmetry may mitigate the exponential growth of joint action spaces that currently limits multi-agent reinforcement learning.
Load-bearing premise
Players inside each team must have exactly identical identities and payoff functions, and the reported simulation gains must extend to environments not tested in the paper.
What would settle it
A controlled simulation of a team-symmetric stochastic game in which DelAC either fails to converge to a Nash equilibrium or is outperformed by at least one standard multi-agent baseline.
Figures
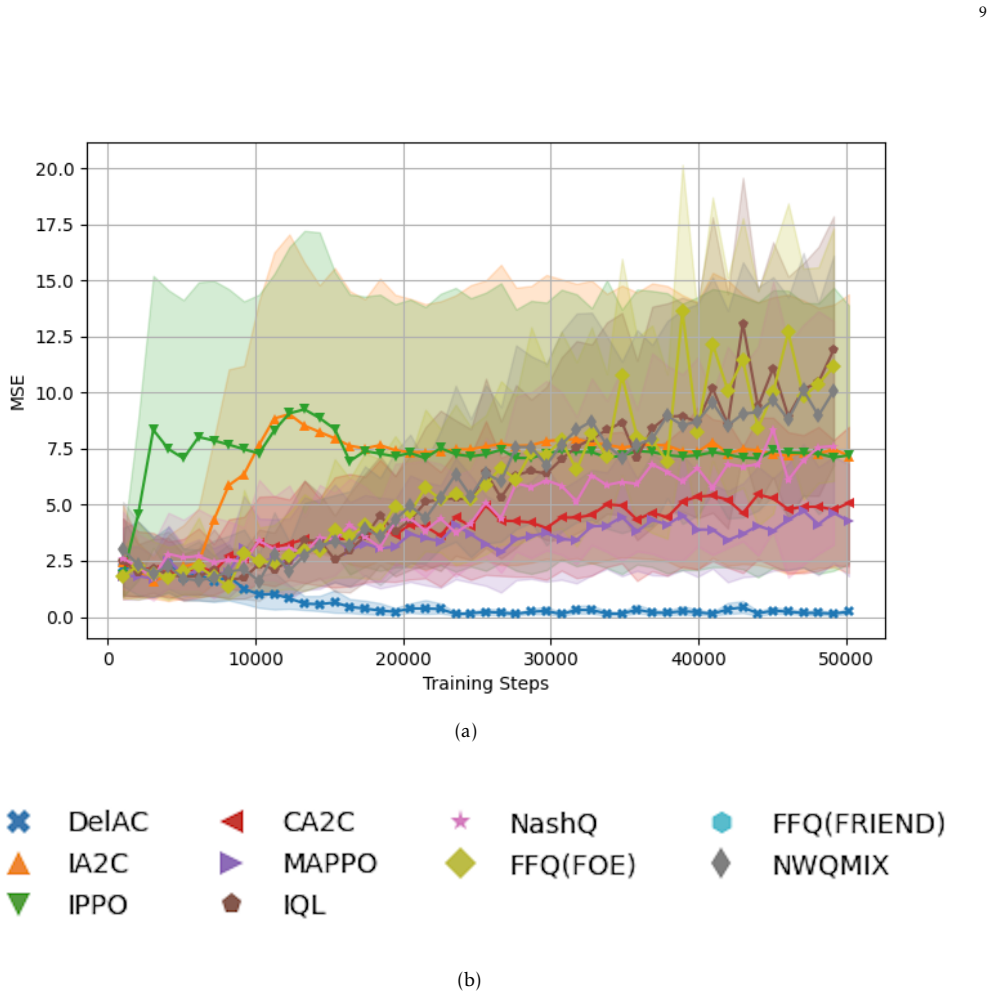


read the original abstract
In this paper we study team-symmetric games with $m\ge 2$ teams. Players within a team have symmetric identity and have a common payoff function. We show that team-symmetric games always have a team-symmetric Nash equilibrium. We develop and solve a linear complementarity problem of team-symmetric Nash equilibria. We propose an actor-critic based multi-agent reinforcement learning algorithm for team-symmetric games. Through simulations, we show that this multi-agent reinforcement learning algorithm performs much better than many existing algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies team-symmetric stochastic games with m ≥ 2 teams, where players within each team share identical identities and a common payoff function. It claims that such games always admit a team-symmetric Nash equilibrium, develops a linear complementarity problem (LCP) whose solution yields these equilibria, and proposes an actor-critic multi-agent reinforcement learning algorithm (DelAC) that simulations show outperforms many existing algorithms.
Significance. A rigorous existence result for team-symmetric equilibria in stochastic games would usefully extend standard game-theoretic tools to team-structured settings and could simplify equilibrium computation. If the LCP is correctly formulated, it would provide a concrete algorithmic pathway; the DelAC proposal could advance practical MARL for symmetric-team domains. However, the empirical superiority claims rest on simulations whose statistical robustness is not detailed in the abstract, limiting immediate impact.
major comments (1)
- [LCP development (methods section)] The LCP formulation for team-symmetric Nash equilibria (described in the abstract and developed in the methods) is stated directly on action probabilities without explicit embedding of the Bellman optimality conditions, state-value functions, or the transition kernel. Standard LCP constructions (e.g., Lemke-Howson) apply to normal-form games; discounted stochastic games require the equilibrium conditions to couple strategies with value-function fixed points. Without these constraints, solutions to the proposed LCP need not satisfy the stochastic-game equilibrium definition, which is load-bearing for both the existence theorem and the computability claim.
minor comments (1)
- [Abstract] The abstract asserts that the DelAC algorithm 'performs much better than many existing algorithms' but supplies no error bars, baseline specifications, environment details, or statistical tests; this weakens the empirical support and should be expanded in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript on team-symmetric stochastic games. The major comment highlights an important aspect of the LCP formulation that we address point-by-point below. We will incorporate clarifications in the revised version.
read point-by-point responses
-
Referee: The LCP formulation for team-symmetric Nash equilibria (described in the abstract and developed in the methods) is stated directly on action probabilities without explicit embedding of the Bellman optimality conditions, state-value functions, or the transition kernel. Standard LCP constructions (e.g., Lemke-Howson) apply to normal-form games; discounted stochastic games require the equilibrium conditions to couple strategies with value-function fixed points. Without these constraints, solutions to the proposed LCP need not satisfy the stochastic-game equilibrium definition, which is load-bearing for both the existence theorem and the computability claim.
Authors: We appreciate the referee identifying this potential gap in explicitness. Our LCP is derived from the team-symmetric best-response conditions of the stochastic game, where the payoff terms are defined using the expected value functions under the transition kernel and discount factor; the complementarity conditions are set to enforce both the equilibrium property and the Bellman fixed-point equations simultaneously. The variables include both the symmetric action probabilities and auxiliary value-function components to couple these elements. However, we agree that the methods section does not spell out this embedding with sufficient detail or notation. In the revision we will expand the LCP derivation to explicitly include the Bellman optimality constraints, state-value variables, and transition-kernel expectations, thereby confirming that any solution satisfies the stochastic-game Nash equilibrium definition. This change strengthens the presentation without altering the underlying result. revision: yes
Circularity Check
No circularity: existence proof and LCP formulation are independent of inputs
full rationale
The paper defines team-symmetric games by symmetric identities and common payoffs within teams, then proves existence of a team-symmetric Nash equilibrium and constructs an LCP from the resulting equilibrium conditions. The DelAC actor-critic algorithm is proposed by adapting standard multi-agent RL methods to the symmetry structure. None of these steps reduce a claimed result to a fitted parameter or self-referential definition by construction; the equilibrium theorem rests on game-theoretic arguments external to the fitted values, and simulation results serve only as empirical validation. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known patterns appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Team-symmetric games admit at least one team-symmetric Nash equilibrium
Reference graph
Works this paper leans on
-
[1]
S. V. Albrecht, F. Christianos, and L. Sch ¨afer,Multi-Agent Reinforcement Learning Foundations and Modern Approaches. Cambridge, Massachusetts: The MIT Press, 2024
work page 2024
-
[2]
If multi-agent learning is the answer, what is the question?
Y. Shoham and K. Leyton-Brown, “If multi-agent learning is the answer, what is the question?”Artificial Intelligence, vol. 171, no. 7, p. 421–429, 2007
work page 2007
-
[3]
Nash Q-learning for general-sum stochastic games,
J. Hu and M. P . Wellman, “Nash Q-learning for general-sum stochastic games,”Journal of Machine Learning Research, vol. 4, pp. 1039 – 1069, 2003
work page 2003
-
[4]
The complexity of computing a Nash equilibrium,
C. Daskalakis, P . Goldberg, and C. Papadimitriou, “The complexity of computing a Nash equilibrium,” inSTOC, 2006
work page 2006
-
[5]
Settling the complexity of two-player Nash equilibrium,
X. Chen and X. Deng, “Settling the complexity of two-player Nash equilibrium,” inFOCS, 2006
work page 2006
-
[6]
Mean-field-type games in engineering,
B. Djehiche, A. Tcheukam, and H. Tembine, “Mean-field-type games in engineering,”AIMS Electronics and Electrical Engineering, vol. 1, no. 1, pp. 18–73, 2017
work page 2017
-
[7]
Efficiency of symmetric nash equilibria in epidemic models with confinements,
M. Sanchez and J. Doncel, “Efficiency of symmetric nash equilibria in epidemic models with confinements,” inPerformance Evaluation Methodologies and Tools – V ALUETOOLS 2023, ser. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, vol. 539. Springer, Cham, Jan. 2024, pp. 51–58
work page 2023
-
[8]
J. Nash, “Non-cooperative games,”The Annals of Mathematics, vol. 54, no. 2, pp. 286 – 295, Sep. 1951
work page 1951
-
[9]
Symmetry, equilibria, and robustness in common-payoff games,
S. Emmons, C. Oesterheld, A. Critch, V. Conitzer, and S. Russell, “Symmetry, equilibria, and robustness in common-payoff games,” inProceedings of the International Conference on Machine Learning (ICML). PMLR 162. Retrieved 21, April 2024
work page 2024
-
[10]
An in-depth look at symmetric games in game theory,
S. Lee, “An in-depth look at symmetric games in game theory,” https://www.numberanalytics.com/blog/in-depth-look- symmetric-games-game-theory, 2025
work page 2025
-
[11]
Equilibria in symmetric games: Theory and applications,
A. Hefti, “Equilibria in symmetric games: Theory and applications,”Theoretical Economics, vol. 12, pp. 979–1002, 2017
work page 2017
-
[12]
Computing equilibria in anonymous games,
C. Daskalakis and C. Papadimitriou, “Computing equilibria in anonymous games,” in48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), 2007, pp. 83–93
work page 2007
-
[13]
Partially-specified large games,
E. Kalai, “Partially-specified large games,” inInternet and Network Economics, X. Deng and Y. Ye, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2005, pp. 3–13
work page 2005
-
[14]
System level analysis of eMBB and grant-free URLLC multiplexing in uplink,
R. Abreu, T. Jacobsen, K. Pedersen, G. Berardinelli, and P . Mogensen, “System level analysis of eMBB and grant-free URLLC multiplexing in uplink,” in2019 IEEE 89th Vehicular Technology Conference (VTC2019-Spring), 2019, pp. 1–5
work page 2019
-
[15]
W. Saad, Z. Han, H. V. Poor, and T. Basar, “Game theoretic methods for the smart grid: An overview of microgrid systems, demand-side management, and communications,”IEEE Signal Processing Magazine, vol. 29, no. 5, pp. 86 – 105, Sept. 2012
work page 2012
-
[16]
Game theory for cyber security and privacy,
C. T. Do, N. H. Tran, C. Hong, C. A. Kamhoua, K. A. Kwiat, E. P . Blasch, S. Ren, N. Pissinou, and S. S. Iyengar, “Game theory for cyber security and privacy,”ACM Computing Surveys, vol. 50, no. 2, 2017
work page 2017
-
[17]
Efficient multi-round llm inference over disaggregated serving,
W. He, Y. Jiang, P . Zhao, Q. Xu, E. Yoneki, B. Cui, and F. Fu, “Efficient multi-round llm inference over disaggregated serving,” 2026. [Online]. Available: https://arxiv.org/abs/2602.14516
-
[18]
Agentrm: An os-inspired resource manager for llm agent systems,
J. She, “Agentrm: An os-inspired resource manager for llm agent systems,” 2026. [Online]. Available: https://arxiv.org/abs/2603.13110
-
[19]
Heterogeneous computing: The key to powering the future of ai agent inference,
Y. Zhao and J. Liu, “Heterogeneous computing: The key to powering the future of ai agent inference,” 2026. [Online]. Available: https://arxiv.org/abs/2601.22001
-
[20]
Y. Shoham and K. Leyton-Brown,Multiagent systems algorithmic, game-theoretic, and logical foundations. Cambridge: Cambridge University Press, 2009
work page 2009
-
[21]
Playing Atari with Deep Reinforcement Learning
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
Nash Q-learning for general-sum stochastic games,
J. Hu and M. P . Wellman, “Nash Q-learning for general-sum stochastic games,”Journal of machine learning research, vol. 4, no. Nov, pp. 1039–1069, 2003
work page 2003
-
[23]
Friend-or-foe Q-learning in general-sum games,
M. L. Littmanet al., “Friend-or-foe Q-learning in general-sum games,” inICML, vol. 1, 2001, pp. 322–328
work page 2001
-
[24]
QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. Foerster, and S. Whiteson, “QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning,” 2018. [Online]. Available: https://arxiv.org/abs/1803.11485
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
NWQMIX - an extension of qmix with negative weights for competitive play,
C.-Y. Wu, “NWQMIX - an extension of qmix with negative weights for competitive play,” 2024
work page 2024
-
[26]
Multi-agent actor-critic for mixed cooperative- competitive environments,
R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative- competitive environments,”Advances in neural information processing systems, vol. 30, 2017. 13
work page 2017
-
[27]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P . Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
G. Papoudakis, F. Christianos, L. Sch ¨afer, and S. V. Albrecht, “Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks,”arXiv preprint arXiv:2006.07869, 2020
-
[29]
On centralized critics in multi-agent reinforcement learning,
X. Lyu, A. Baisero, Y. Xiao, B. Daley, and C. Amato, “On centralized critics in multi-agent reinforcement learning,”Journal of Artificial Intelligence Research, vol. 77, pp. 295–354, 2023
work page 2023
-
[30]
The surprising effectiveness of PPO in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu, “The surprising effectiveness of PPO in cooperative multi-agent games,”Advances in neural information processing systems, vol. 35, pp. 24 611–24 624, 2022
work page 2022
-
[31]
S. V. Albrecht, F. Christianos, and L. Sch ¨afer,Multi-Agent Reinforcement Learning: Foundations and Modern Approaches. MIT Press, 2024. [Online]. Available: https://www.marl-book.com
work page 2024
-
[32]
Revisiting parameter sharing in multi-agent deep reinforcement learning,
J. K. Terry, N. Grammel, S. Son, B. Black, and A. Agrawal, “Revisiting parameter sharing in multi-agent deep reinforcement learning,”arXiv preprint arXiv:2005.13625, 2020
-
[33]
Scaling multi-agent reinforcement learning with selective parameter sharing,
F. Christianos, G. Papoudakis, M. A. Rahman, and S. V. Albrecht, “Scaling multi-agent reinforcement learning with selective parameter sharing,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 1989–1998
work page 2021
-
[34]
Towards convergence to Nash equilibria in two-team zero-sum games,
F. Kalogiannis, I. Panageas, and E.-V. Vlatakis-Gkaragkounis, “Towards convergence to Nash equilibria in two-team zero-sum games,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=4BPFwvKOvo5
work page 2023
-
[35]
G. E. Bredon,Topology and geometry. Springer Science & Business Media, 2013, vol. 139
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.