Recognition: no theorem link
No One Knows the State of the Art in Geospatial Foundation Models
Pith reviewed 2026-05-14 21:01 UTC · model grok-4.3
The pith
Nobody knows the state of the art in geospatial foundation models because papers cannot be compared.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the GFM literature does not standardize evaluations, training and testing protocols, released weights, or pretraining controls well enough for anyone to compare or rank models. A 152-paper audit finds 46 disagreements of 10+ points on identical model-benchmark-protocol triples, 94 papers using unique pretraining data configurations, and 39 percent of papers releasing no weights. The authors conclude that this prevents determination of the current state of the art and propose six expectations to remedy it.
What carries the argument
The 152-paper audit that quantifies performance disagreements, unique pretraining setups, and weight-release rates across the GFM literature.
If this is right
- Models cannot be ranked or selected for specific tasks on the basis of published numbers.
- Users cannot confidently choose the strongest GFM for applications such as disaster response or food-security monitoring.
- Differences in architecture or pretraining cannot be isolated from differences in evaluation protocol.
- Community progress on GFMs is slowed by the inability to build on or refute prior claims.
Where Pith is reading between the lines
- Similar coordination failures may exist in other domain-specific foundation model literatures that also lack shared harnesses.
- Adopting the six proposed expectations would make it possible to run controlled experiments that separate data effects from architecture effects.
- Widespread weight release under named licenses would enable independent groups to test models on new benchmarks without retraining from scratch.
Load-bearing premise
The sampled papers are representative of the full GFM literature and the observed disagreements stem primarily from missing standards rather than other factors.
What would settle it
A single shared evaluation harness applied to all existing models that produces consistent rankings with no 10-point disagreements on the same benchmarks.
Figures
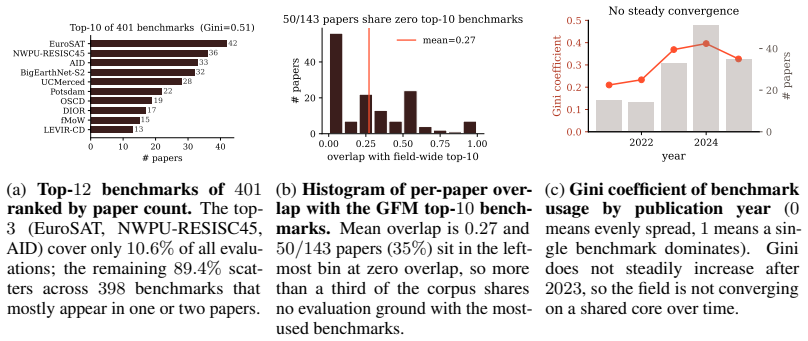


read the original abstract
Geospatial foundation models (GFMs) have been proposed as generalizable backbones for disaster response, land-cover mapping, food-security monitoring, and other high-stakes Earth-observation tasks. Yet the published work about these models does not give reviewers or users enough information to tell which model fits a given task. We argue that nobody knows what the current state of the art is in geospatial foundation models. The methods may be useful, but the GFM literature does not standardize evaluations, training and testing protocols, released weights, or pretraining controls well enough for anyone to compare or rank them. In a 152-paper audit, we find 46 cross-paper disagreements of at least 10 points for the same model, benchmark, and protocol; 94/126 papers with extractable pretraining data use a configuration no other paper uses; and 39% of GFM papers release no model weights. This lack of community standards can be solved. We propose six concrete expectations: named-license weight release, shared core evaluations, copied-versus-rerun baseline annotations, variance reporting, one shared evaluation harness, and data-vs-architecture-vs-algorithm controls. These gaps are a coordination failure, not a fault of any individual lab; the authors of this paper, like many others in the GFM community, have contributed to them. Rather than just critiquing the community, we aim to provide concrete steps toward a shared understanding of how to innovate GFMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits 152 papers on geospatial foundation models (GFMs) and reports 46 cross-paper disagreements of at least 10 points on identical model-benchmark-protocol triples, 94/126 unique pretraining configurations, and 39% of papers releasing no weights. It concludes that these inconsistencies mean the community cannot determine the state of the art and proposes six concrete expectations (named-license weight release, shared core evaluations, copied-versus-rerun baselines, variance reporting, one shared harness, and data-vs-architecture-vs-algorithm controls) to remedy the coordination failure.
Significance. If the audit statistics are representative, the work identifies a systemic barrier to progress in a field with high-stakes applications. The constructive framing that credits the community (including the authors themselves) for the gaps, together with the explicit list of six expectations, gives the manuscript practical value beyond critique.
major comments (2)
- [Abstract and audit description] Abstract and audit description: the central counts (46 disagreements, 94/126 unique configs, 39% no weights) rest on an audit whose paper-selection criteria, exact disagreement measurement protocol, and inter-annotator agreement are not reported. These omissions are load-bearing for the claim that the observed inconsistencies prevent SOTA determination across the GFM literature.
- [Audit description] Audit description: no formal sampling frame or justification is given for why the 152-paper corpus is representative of the full GFM literature. Without this, the generalization from the observed 46 disagreements and 94 unique pretraining setups to the conclusion that “nobody knows” the SOTA remains under-supported.
minor comments (1)
- [Proposal section] The six proposed expectations are listed clearly but would benefit from a short table or bullet list that maps each expectation to the specific audit finding it addresses.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address the two major comments below and will revise the manuscript to provide the requested methodological details and justifications.
read point-by-point responses
-
Referee: [Abstract and audit description] Abstract and audit description: the central counts (46 disagreements, 94/126 unique configs, 39% no weights) rest on an audit whose paper-selection criteria, exact disagreement measurement protocol, and inter-annotator agreement are not reported. These omissions are load-bearing for the claim that the observed inconsistencies prevent SOTA determination across the GFM literature.
Authors: We agree that these details are essential for transparency and to support the central claims. In the revised manuscript we will add a dedicated 'Audit Methodology' subsection that specifies: the exact paper-selection criteria (search terms, databases, date range, and inclusion/exclusion rules); the precise protocol used to identify and count disagreements (how model-benchmark-protocol triples were matched and the 10-point threshold applied); and any inter-annotator agreement measures or validation steps employed during data extraction. These additions will make the audit reproducible and directly address the load-bearing concern. revision: yes
-
Referee: [Audit description] Audit description: no formal sampling frame or justification is given for why the 152-paper corpus is representative of the full GFM literature. Without this, the generalization from the observed 46 disagreements and 94 unique pretraining setups to the conclusion that “nobody knows” the SOTA remains under-supported.
Authors: We acknowledge that a formal sampling frame and explicit justification would strengthen the generalization. In revision we will insert a paragraph describing the systematic search strategy (keywords, sources, and temporal scope), the rationale for the 152-paper corpus, and a limitations discussion noting that the sample is not exhaustive but captures the dominant publication trends in the field. We will also qualify the 'nobody knows' conclusion to reflect that the observed inconsistencies are indicative rather than a complete census, while maintaining that they demonstrate a systemic coordination failure. revision: yes
Circularity Check
Empirical audit with no derivations or self-referential reductions
full rationale
The paper performs a direct count-based audit of 152 existing GFM papers, reporting observed frequencies of disagreements, unique pretraining configs, and weight-release rates. No equations, fitted parameters, predictions, or uniqueness theorems are invoked. The central claim follows immediately from the tabulated audit statistics without any intermediate derivation that could reduce to the inputs by construction. Self-mention of community contributions is incidental and not load-bearing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 152-paper corpus is a representative sample of published GFM work
Reference graph
Works this paper leans on
-
[1]
Omnisat: Self- supervised modality fusion for earth observation
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. Omnisat: Self- supervised modality fusion for earth observation. InEuropean Conference on Computer Vision, pages 409–427. Springer, 2024
work page 2024
-
[2]
Anysat: One earth observation model for many resolutions, scales, and modalities
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. Anysat: One earth observation model for many resolutions, scales, and modalities. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19530–19540, 2025
work page 2025
-
[3]
Satlaspretrain: A large-scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdinando, and Aniruddha Kembhavi. Satlaspretrain: A large-scale dataset for remote sensing image understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16772–16782, 2023
work page 2023
-
[4]
Olmoearth: Stable latent image modeling for multimodal earth observation
Favyen Bastani et al. Olmoearth: Stable latent image modeling for multimodal earth observation. arXiv preprint, 2025
work page 2025
-
[5]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Longllada: Unlocking long context capabilities in diffusion llms
Nikolaos Ioannis Bountos, Arthur Ouaknine, Ioannis Papoutsis, and David Rolnick. FoMo: Multi-modal, multi-scale and multi-task remote sensing foundation models for forest monitoring. InAAAI Conference on Artificial Intelligence, pages 27858–27868, 2025. doi: 10.1609/aaai. v39i27.35002
-
[7]
Unreproducible research is reproducible
Xavier Bouthillier, César Laurent, and Pascal Vincent. Unreproducible research is reproducible. InInternational Conference on Machine Learning, pages 725–734. PMLR, 2019
work page 2019
-
[8]
Accounting for variance in machine learning benchmarks
Xavier Bouthillier, Pierre Delaunay, Mirko Bronzi, et al. Accounting for variance in machine learning benchmarks. InMLSys, 2021
work page 2021
-
[9]
Christopher F Brown, Michal R Kazmierski, Valerie J Pasquarella, William J Rucklidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, et al. Alphaearth foundations: An embedding field model for accurate and efficient global mapping from sparse label data.arXiv preprint arXiv:2507.22291, 2025
-
[10]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[11]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[12]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021
work page 2021
-
[13]
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 105(10):1865–1883, 2017
work page 2017
-
[14]
Gordon Christie, Neil Fendley, James Wilson, and Ryan Mukherjee. Functional map of the world. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6172–6180, 2018
work page 2018
-
[15]
Revisiting pre-trained remote sensing model benchmarks: Resizing and normalization matters
Isaac Corley, Caleb Robinson, and Anthony Ortiz. Revisiting pre-trained remote sensing model benchmarks: Resizing and normalization matters. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 3162–3172, 2024. doi: 10.1109/ CVPRW63382.2024.00322. 10
-
[16]
arXiv preprint arXiv :2506.06281 (2025)
Muhammad Sohail Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Muham- mad Haris Khan, Rao Muhammad Anwer, Jorma Laaksonen, Fahad Shahbaz Khan, and Salman Khan. Terrafm: A scalable foundation model for unified multisensor earth observation.arXiv preprint arXiv:2506.06281, 2025
-
[17]
The benchmark lottery.arXiv preprint arXiv:2107.07002, 2021
Mostafa Dehghani, Yi Tay, Alexey A. Gritsenko, et al. The benchmark lottery.arXiv preprint arXiv:2107.07002, 2021
-
[18]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[19]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
work page 2019
-
[20]
Data science at the singularity.Harvard Data Science Review, 6(1), 2024
David Donoho. Data science at the singularity.Harvard Data Science Review, 6(1), 2024
work page 2024
-
[21]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[22]
Phileo bench: Evaluating geo-spatial foundation models
Casper Fibaek, Luke Camilleri, Andreas Luyts, Nikolaos Dionelis, and Bertrand Le Saux. Phileo bench: Evaluating geo-spatial foundation models. InIEEE International Geoscience and Remote Sensing Symposium (IGARSS), 2024
work page 2024
-
[23]
Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Hynek, and Thomas Wolf. Open LLM leaderboard v2, 2024. https://huggingface.co/spaces/ open-llm-leaderboard/open_llm_leaderboard
work page 2024
-
[24]
Major tom: Expandable datasets for earth observation
Alistair Francis and Mikolaj Czerkawski. Major tom: Expandable datasets for earth observation. InIGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium, pages 2935–2940. IEEE, 2024
work page 2024
-
[25]
Bad tables: Why you shouldn’t trust results tables in remote-sensing founda- tion model papers, 2026
Anthony Fuller. Bad tables: Why you shouldn’t trust results tables in remote-sensing founda- tion model papers, 2026. URLhttps://antofuller.github.io/BAD_TABLES.pdf. Talk, ICLR Machine Learning for Remote Sensing Workshop, April 2026
work page 2026
-
[26]
Anthony Fuller, Koreen Millard, and James Green. Croma: Remote sensing representations with contrastive radar-optical masked autoencoders.Advances in Neural Information Processing Systems, 36:5506–5538, 2023
work page 2023
-
[27]
A framework for few-shot language model evaluation.Zenodo, 2024.lm-evaluation-harness
Leo Gao, Jonathan Tow, Baber Abbasi, et al. A framework for few-shot language model evaluation.Zenodo, 2024.lm-evaluation-harness
work page 2024
-
[28]
Anatol Garioud, Nicolas Gonthier, Loic Landrieu, Apolline De Wit, Marion Valette, Marc Poupée, Sébastien Giordano, et al. Flair: a country-scale land cover semantic segmentation dataset from multi-source optical imagery.Advances in Neural Information Processing Systems, 36:16456–16482, 2023
work page 2023
-
[29]
Terratorch: The geospatial foundation models toolkit
Carlos Gomes, Benedikt Blumenstiel, Joao Lucas De Sousa Almeida, Pedro Henrique De Oliveira, Paolo Fraccaro, Francesc Marti Escofet, Daniela Szwarcman, Naomi Simumba, Romeo Kienzler, and Bianca Zadrozny. Terratorch: The geospatial foundation models toolkit. InIGARSS 2025-2025 IEEE International Geoscience and Remote Sensing Symposium, pages 6364–6368. IEEE, 2025
work page 2025
-
[30]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 11
work page 2016
-
[31]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
work page 2019
-
[32]
Huiyang Hu, Peijin Wang, Yingchao Feng, Kaiwen Wei, Wenxin Yin, Wenhui Diao, Mengyu Wang, Hanbo Bi, Kaiyue Kang, Tong Ling, et al. Ringmo-agent: A unified remote sensing foun- dation model for multi-platform and multi-modal reasoning.arXiv preprint arXiv:2507.20776, 2025
-
[33]
Jingliang Hu, Rong Liu, Danfeng Hong, Andrés Camero, Jing Yao, Mathias Schneider, Franz Kurz, Karl Segl, and Xiao Xiang Zhu. Mdas: A new multimodal benchmark dataset for remote sensing.Earth System Science Data, 15(1):113–131, 2023
work page 2023
-
[34]
Ziyue Huang, Mingming Zhang, Yuan Gong, Qingjie Liu, and Yunhong Wang. Generic knowledge boosted pretraining for remote sensing images.IEEE Transactions on Geoscience and Remote Sensing, 62:1–13, 2024
work page 2024
-
[35]
Yuru Jia, Valerio Marsocci, Ziyang Gong, Xue Yang, Maarten Vergauwen, and Andrea Nascetti. Can generative geospatial diffusion models excel as discriminative geospatial foundation mod- els? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8429–8440, 2025
work page 2025
-
[36]
Nicolas Karasiak, Jean-François Dejoux, Claude Monteil, and David Sheeren. Spatial depen- dence between training and test sets: another pitfall of classification accuracy assessment in remote sensing.Machine Learning, 111:2715–2740, 2022. doi: 10.1007/s10994-021-05972-1
-
[37]
Teja Kattenborn, Felix Schiefer, Julian Frey, Hannes Feilhauer, Miguel D. Mahecha, and Carsten F. Dormann. Spatially autocorrelated training and validation samples inflate perfor- mance assessment of convolutional neural networks.ISPRS Open Journal of Photogrammetry and Remote Sensing, 5:100018, 2022. doi: 10.1016/j.ophoto.2022.100018
-
[38]
Amandeep Kaur, Mirali Purohit, Gedeon Muhawenayo, Esther Rolf, and Hannah Kerner. Pretrain where? investigating how pretraining data diversity impacts geospatial foundation model performance.arXiv preprint arXiv:2604.21104, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[40]
Bernard Koch, Emily Denton, Alex Hanna, and Jacob G. Foster. Reduced, reused and recycled: The life of a dataset in machine learning research. InNeurIPS Datasets and Benchmarks, 2021
work page 2021
-
[41]
GEO-Bench: Toward foundation models for earth monitoring
Alexandre Lacoste, Nils Lehmann, Pau Rodríguez Castaño, et al. GEO-Bench: Toward foundation models for earth monitoring. InNeurIPS Datasets and Benchmarks, 2023
work page 2023
-
[42]
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. Geo-bench: Toward foundation models for earth monitoring.Advances in Neural Information Processing Systems, 36:51080–51093, 2023
work page 2023
-
[43]
Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. Object detection in optical remote sensing images: A survey and a new benchmark.ISPRS journal of photogrammetry and remote sensing, 159:296–307, 2020
work page 2020
-
[44]
Masked angle-aware autoencoder for remote sensing images
Zhihao Li, Biao Hou, Siteng Ma, Zitong Wu, Xianpeng Guo, Bo Ren, and Licheng Jiao. Masked angle-aware autoencoder for remote sensing images. InEuropean Conference on Computer Vision, pages 260–278. Springer, 2024
work page 2024
-
[45]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, et al. Holistic evaluation of language models. Transactions on Machine Learning Research, 2023. 12
work page 2023
-
[46]
Zachary C Lipton and Jacob Steinhardt. Troubling trends in machine learning scholarship: Some ml papers suffer from flaws that could mislead the public and stymie future research. Queue, 17(1):45–77, 2019
work page 2019
-
[47]
Docling: An efficient open-source toolkit for AI-driven document conversion
Nikolaos Livathinos, Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Panos Vagenas, Cesar Berrospi Ramis, Matteo Omenetti, Kasper Dinkla, Yusik Kim, et al. Do- cling: An efficient open-source toolkit for ai-driven document conversion.arXiv preprint arXiv:2501.17887, 2025
-
[48]
Yang Long, Gui-Song Xia, Shengyang Li, Wen Yang, Michael Ying Yang, Xiao Xiang Zhu, Liangpei Zhang, and Deren Li. On creating benchmark dataset for aerial image interpreta- tion: Reviews, guidances and million-aid.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14:4205–4230, 2021
work page 2021
-
[49]
Siqi Lu, Junlin Guo, James R. Zimmer-Dauphinee, et al. Vision foundation models in remote sensing: A survey.IEEE Geoscience and Remote Sensing Magazine, 2024
work page 2024
-
[50]
Sea- sonal contrast: Unsupervised pre-training from uncurated remote sensing data
Oscar Manas, Alexandre Lacoste, Xavier Giró-i Nieto, David Vazquez, and Pau Rodriguez. Sea- sonal contrast: Unsupervised pre-training from uncurated remote sensing data. InProceedings of the IEEE/CVF international conference on computer vision, pages 9414–9423, 2021
work page 2021
-
[51]
Valerio Marsocci, Yuru Jia, Gilles Le Bellier, et al. PANGAEA: A global and inclusive benchmark for geospatial foundation models.arXiv preprint arXiv:2412.04204, 2024
-
[52]
Towards geospatial foundation models via continual pretraining
Matías Mendieta, Boran Han, Xingjian Shi, Yi Zhu, and Chen Chen. Towards geospatial foundation models via continual pretraining. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16806–16816, 2023
work page 2023
-
[53]
Mmearth: Exploring multi-modal pretext tasks for geospatial representation learning
Vishal Nedungadi, Ankit Kariryaa, Stefan Oehmcke, Serge Belongie, Christian Igel, and Nico Lang. Mmearth: Exploring multi-modal pretext tasks for geospatial representation learning. In European Conference on Computer Vision, pages 164–182. Springer, 2024
work page 2024
-
[54]
Simon Ott, Adriano Barbosa-Silva, Kathrin Blagec, Jan Brauner, and Matthias Samwald. Mapping global dynamics of benchmark creation and saturation in artificial intelligence.Nature Communications, 2022
work page 2022
-
[55]
Planted: a dataset for planted forest identification from multi- satellite time series
Luis Miguel Pazos-Outón, Cristina Nader Vasconcelos, Anton Raichuk, Anurag Arnab, Dan Morris, and Maxim Neumann. Planted: a dataset for planted forest identification from multi- satellite time series. InIGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium, pages 7066–7070. IEEE, 2024
work page 2024
-
[56]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[57]
Scale-mae: A scale- aware masked autoencoder for multiscale geospatial representation learning
Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brockman, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale-mae: A scale- aware masked autoencoder for multiscale geospatial representation learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4088–4099, 2023
work page 2023
-
[58]
Position: Mission critical – satellite data is a distinct modality in machine learning.ICML, 2024
Esther Rolf, Konstantin Klemmer, Caleb Robinson, and Hannah Kerner. Position: Mission critical – satellite data is a distinct modality in machine learning.ICML, 2024
work page 2024
-
[59]
Michael Schmitt, Lloyd Haydn Hughes, Chunping Qiu, and Xiao Xiang Zhu. Sen12ms–a curated dataset of georeferenced multi-spectral sentinel-1/2 imagery for deep learning and data fusion.arXiv preprint arXiv:1906.07789, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[60]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022. 13
work page 2022
-
[61]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565. Association for Computational Linguistics, 2018
work page 2018
-
[62]
Naomi Simumba, Nils Lehmann, Paolo Fraccaro, Hamed Alemohammad, Geeth De Mel, Salman Khan, Manil Maskey, Nicolas Longepe, Xiao Xiang Zhu, Hannah Kerner, et al. Geo- bench-2: From performance to capability, rethinking evaluation in geospatial ai.arXiv preprint arXiv:2511.15658, 2025
-
[63]
Earthdial: Turning multi-sensory earth observations to interactive dialogues
Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fahad Shah- baz Khan, et al. Earthdial: Turning multi-sensory earth observations to interactive dialogues. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14303–14313, 2025
work page 2025
-
[64]
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, et al. Beyond the imitation game: Quanti- fying and extrapolating the capabilities of language models.Transactions on Machine Learning Research, 2023
work page 2023
-
[65]
Adam J Stewart, Caleb Robinson, Isaac A Corley, Anthony Ortiz, Juan M Lavista Ferres, and Arindam Banerjee. Torchgeo: deep learning with geospatial data.ACM Transactions on Spatial Algorithms and Systems, 11(4):1–28, 2025
work page 2025
-
[66]
Xian Sun, Peijin Wang, Zhiyuan Yan, Feng Xu, Ruiping Wang, Wenhui Diao, Jin Chen, Jihao Li, Yingchao Feng, Tao Xu, et al. Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery.ISPRS Journal of Photogrammetry and Remote Sensing, 184:116–130, 2022
work page 2022
-
[67]
Chao Tao, Ji Qi, Guo Zhang, Qing Zhu, Weipeng Lu, and Haifeng Li. Tov: The original vision model for optical remote sensing image understanding via self-supervised learning.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 16:4916–4930, 2023
work page 2023
-
[68]
Galileo: Learning global & local features of many remote sensing modalities
Gabriel Tseng, Ruben Cartuyvels, Ivan Zvonkov, Mirali Purohit, David Rolnick, and Hannah Kerner. Galileo: Learning global & local features of many remote sensing modalities. In Proceedings of the International Conference on Machine Learning, 2025
work page 2025
-
[69]
Panopticon: Advancing any-sensor foundation models for earth observation
Leonard Waldmann, Ando Shah, Yi Wang, Nils Lehmann, Adam Stewart, Zhitong Xiong, Xiao Xiang Zhu, Stefan Bauer, and John Chuang. Panopticon: Advancing any-sensor foundation models for earth observation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2204–2214, 2025
work page 2025
-
[70]
Harnessing massive satellite imagery with efficient masked image modeling
Fengxiang Wang, Hongzhen Wang, Di Wang, Zonghao Guo, Zhenyu Zhong, Long Lan, Wenjing Yang, and Jing Zhang. Harnessing massive satellite imagery with efficient masked image modeling. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6935–6947, 2025
work page 2025
-
[71]
Yi Wang, Nassim Ait Ali Braham, Zhitong Xiong, Chenying Liu, Conrad M Albrecht, and Xiao Xiang Zhu. Ssl4eo-s12: A large-scale multimodal, multitemporal dataset for self- supervised learning in earth observation [software and data sets].IEEE Geoscience and Remote Sensing Magazine, 11(3):98–106, 2023
work page 2023
-
[72]
Gui-Song Xia, Jingwen Hu, Fan Hu, Baoguang Shi, Xiang Bai, Yanfei Zhong, Liangpei Zhang, and Xiaoqiang Lu. Aid: A benchmark data set for performance evaluation of aerial scene classification.IEEE Transactions on Geoscience and Remote Sensing, 55(7):3965–3981, 2017
work page 2017
-
[73]
Dota: A large-scale dataset for object detection in aerial images
Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Belongie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liangpei Zhang. Dota: A large-scale dataset for object detection in aerial images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3974–3983, 2018. 14
work page 2018
-
[74]
Aoran Xiao, Weihao Xuan, Junjue Wang, et al. Foundation models for remote sensing and earth observation: A survey.IEEE Geoscience and Remote Sensing Magazine, 2025
work page 2025
-
[75]
Zhitong Xiong, Yi Wang, Fahong Zhang, Adam J Stewart, Joelle Hanna, Damian Borth, Ioannis Papoutsis, Bertrand Le Saux, Gustau Camps-Valls, and Xiao Xiang Zhu. Neural plasticity- inspired multimodal foundation model for earth observation.arXiv preprint arXiv:2403.15356, 2024
-
[76]
Bag-of-visual-words and spatial extensions for land-use classifi- cation
Yi Yang and Shawn Newsam. Bag-of-visual-words and spatial extensions for land-use classifi- cation. InACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS), pages 270–279, 2010
work page 2010
-
[77]
A large-scale study of representation learning with the visual task adaptation benchmark
Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, et al. A large-scale study of representation learning with the visual task adaptation benchmark.arXiv preprint arXiv:1910.04867, 2019
-
[78]
Mingming Zhang, Qingjie Liu, and Yunhong Wang. Ctxmim: Context-enhanced masked image modeling for remote sensing image understanding.ACM Transactions on Multimedia Computing, Communications and Applications, 21(12):1–22, 2025
work page 2025
-
[79]
Wei Zhang, Miaoxin Cai, Tong Zhang, Yin Zhuang, and Xuerui Mao. Earthgpt: A universal multimodal large language model for multisensor image comprehension in remote sensing domain.IEEE Transactions on Geoscience and Remote Sensing, 62:1–20, 2024
work page 2024
-
[80]
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. Rs5m and georsclip: A large- scale vision-language dataset and a large vision-language model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–23, 2024. A Reproducibility The supplementary repository contains the 152-paper corpus, extraction prompts, normalization code, ha...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.