Recognition: unknown
MMCL-Bench: Multimodal Context Learning from Visual Rules, Procedures, and Evidence
Pith reviewed 2026-05-14 20:53 UTC · model grok-4.3
The pith
Current multimodal models solve fewer than one-third of tasks that require learning rules and procedures from visual examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMCL-Bench demonstrates that current frontier multimodal models remain far from robust multimodal context learning, with even the strongest model solving fewer than one-third of tasks under strict evaluation. Failures occur throughout the pipeline: models struggle to anchor to the provided visual teaching context, extract relevant evidence from images or sequences, reason over the recovered rules or procedures, and construct responses that faithfully apply the learned context to new instances.
What carries the argument
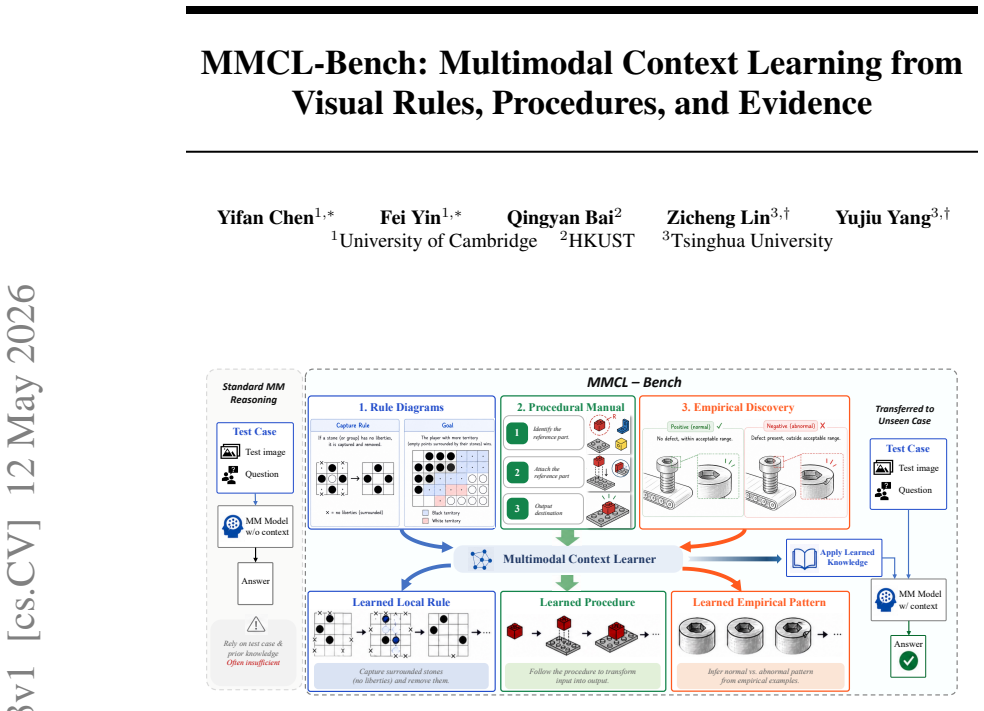
MMCL-Bench, a benchmark of 102 tasks across rule system application, procedural task execution, and empirical discovery and induction that requires recovering evidence from visual or mixed-modality teaching contexts before applying it.
If this is right
- Improvements in visual evidence extraction are required before downstream reasoning over learned context can succeed.
- Context anchoring mechanisms must be strengthened to keep models focused on the supplied teaching materials rather than external knowledge.
- Reasoning steps must be made more reliable when applying recovered rules or procedures to novel visual instances.
- Response construction needs tighter coupling to the learned context to reduce fabrication of unsupported details.
- Diagnostic breakdowns by pipeline stage can guide targeted architecture changes rather than uniform scaling.
Where Pith is reading between the lines
- Similar context-learning gaps may appear in domains that combine instructions with diagrams or sensor data, suggesting the benchmark pattern could generalize beyond the current task set.
- If the identified failure stages prove consistent across model families, then hybrid systems that separate evidence localization from reasoning might close the gap faster than end-to-end training.
- The benchmark could serve as a testbed for measuring whether new multimodal architectures reduce errors at specific pipeline stages rather than only improving overall accuracy.
- Extending the task categories to include longer video sequences or interactive procedures would test whether the current performance ceiling is an artifact of short-context evaluation.
Load-bearing premise
The 102 tasks and rubric-based scoring faithfully isolate multimodal context learning without introducing unintended biases in task selection or evaluation criteria.
What would settle it
A frontier multimodal model that scores above 70 percent on the full set of 102 tasks under the same strict rubric-based evaluation would falsify the claim that robust multimodal context learning remains unsolved.
Figures







read the original abstract
We introduce MMCL-Bench, a benchmark for multimodal context learning: learning task-local rules, procedures, and empirical patterns from visual or mixed-modality teaching context and applying them to new visual instances. Unlike text-only context learning or standard multimodal question answering, this setting requires models to recover and localize relevant evidence from images, screenshots, manuals, videos, and frame sequences before they can reason over the learned context. MMCL-Bench contains 102 tasks spanning three categories: rule system application, procedural task execution, and empirical discovery and induction. We evaluate frontier multimodal models with strict rubric-based scoring and find that current systems remain far from robust multimodal context learning, with even the strongest model solving fewer than one-third of tasks under strict evaluation. Diagnostic ablations and error analysis show that failures arise throughout the context-to-answer pipeline, including context anchoring, visual evidence extraction, context reasoning, and response construction. MMCL-Bench thus highlights multimodal context learning as an important unsolved capability bottleneck for current multimodal models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MMCL-Bench, a benchmark for multimodal context learning consisting of 102 tasks spanning rule system application, procedural task execution, and empirical discovery and induction. Frontier multimodal models are evaluated with strict rubric-based scoring, showing that even the strongest model solves fewer than one-third of tasks; diagnostic ablations and error analysis attribute failures to context anchoring, visual evidence extraction, context reasoning, and response construction.
Significance. If the benchmark tasks and rubrics are shown to be robust, the results would be significant for identifying multimodal context learning as an unsolved bottleneck beyond standard VQA or text-only in-context learning, providing a new evaluation framework with pipeline-level error breakdowns.
major comments (3)
- [§3] §3 (Benchmark Construction): The manuscript supplies high-level category definitions, task counts, and pipeline stages but omits the full set of 102 task definitions, complete rubric criteria, and inter-annotator agreement statistics. These omissions are load-bearing because the central claim that models solve <1/3 of tasks under strict evaluation rests on the assumption that the tasks and scoring faithfully isolate multimodal context learning without selection or scoring biases.
- [§5] §5 (Error Analysis): The reported error breakdowns across context anchoring, evidence extraction, reasoning, and response construction are presented at an aggregate level only; without per-model quantitative stage-wise statistics or concrete scoring examples for borderline cases, it is not possible to assess whether the diagnostic conclusions are reproducible or proportionate to the performance gap.
- [§4] §4 (Model Evaluation): The claim of strict rubric-based scoring is central to the <1/3 success rate result, yet the manuscript does not include the rubric templates, annotation guidelines, or agreement numbers; this prevents independent verification that the evaluation isolates the intended capability rather than unintended visual or formatting artifacts.
minor comments (1)
- [Figures/Tables] Figure 2 (task distribution) and Table 1 (model results) would benefit from clearer axis labels and explicit mention of the exact number of tasks per category to improve readability.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address each of the major comments below and plan to revise the paper accordingly to enhance reproducibility and clarity.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The manuscript supplies high-level category definitions, task counts, and pipeline stages but omits the full set of 102 task definitions, complete rubric criteria, and inter-annotator agreement statistics. These omissions are load-bearing because the central claim that models solve <1/3 of tasks under strict evaluation rests on the assumption that the tasks and scoring faithfully isolate multimodal context learning without selection or scoring biases.
Authors: We agree that including the full details is essential for independent verification. In the revised version, we will add an appendix containing all 102 task definitions, the complete rubric criteria for each category, and the inter-annotator agreement statistics computed during the annotation process. This will directly address the concern about potential biases in task selection and scoring. revision: yes
-
Referee: [§5] §5 (Error Analysis): The reported error breakdowns across context anchoring, evidence extraction, reasoning, and response construction are presented at an aggregate level only; without per-model quantitative stage-wise statistics or concrete scoring examples for borderline cases, it is not possible to assess whether the diagnostic conclusions are reproducible or proportionate to the performance gap.
Authors: We concur that more granular error analysis would improve the diagnostic value. We will revise §5 to include per-model quantitative breakdowns of errors at each pipeline stage in a new table, and add specific examples of borderline cases with scoring rationales to demonstrate how the rubrics were applied. revision: yes
-
Referee: [§4] §4 (Model Evaluation): The claim of strict rubric-based scoring is central to the <1/3 success rate result, yet the manuscript does not include the rubric templates, annotation guidelines, or agreement numbers; this prevents independent verification that the evaluation isolates the intended capability rather than unintended visual or formatting artifacts.
Authors: We recognize the importance of transparency in the evaluation protocol. We will incorporate the rubric templates and annotation guidelines into the supplementary materials, along with the inter-annotator agreement numbers, to allow readers to verify that the scoring focuses on multimodal context learning capabilities. revision: yes
Circularity Check
No significant circularity; empirical benchmark evaluation is self-contained
full rationale
The manuscript introduces MMCL-Bench as a new collection of 102 tasks in three categories and reports direct empirical performance of frontier models under rubric scoring. No equations, parameter fitting, derivations, or self-citation chains are used to support the central claim that even the strongest model solves fewer than one-third of tasks. Task definitions, category counts, and error breakdowns are presented as independent measurements on the newly constructed benchmark, with no reduction of results to inputs by construction. The evaluation pipeline is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard AI benchmark evaluation practices including rubric-based scoring and error categorization are appropriate for this capability
invented entities (1)
-
MMCL-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cl-bench: A benchmark for context learning
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, et al. Cl-bench: A benchmark for context learning. arXiv preprint arXiv:2602.03587, 2026
-
[2]
CL-bench leaderboard.https://www.clbench.com/, 2026
CL-bench Team. CL-bench leaderboard.https://www.clbench.com/, 2026. Accessed April 4, 2026
work page 2026
-
[3]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilin- gual, multitask benchmark for long context understanding.arXiv preprint arXiv:2308.14508, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Long-context llms struggle with long in-context learning.arXiv preprint arXiv:2404.02060, 2024
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, and Wenhu Chen. Long-context llms struggle with long in-context learning.arXiv preprint arXiv:2404.02060, 2024
-
[5]
Zhaowei Wang, Wenhao Yu, Xiyu Ren, Jipeng Zhang, Yu Zhao, Rohit Saxena, Liang Cheng, Ginny Wong, Simon See, Pasquale Minervini, Yangqiu Song, and Mark Steedman. Mmlong- bench: Benchmarking long-context vision-language models effectively and thoroughly.arXiv preprint arXiv:2505.10610, 2025
-
[6]
Milebench: Benchmarking mllms in long context.arXiv preprint arXiv:2404.18532, 2024
Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, and Benyou Wang. Milebench: Benchmarking mllms in long context.arXiv preprint arXiv:2404.18532, 2024
-
[7]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[8]
Yongshuo Zong, Ondrej Bohdal, and Timothy Hospedales. Vl-icl bench: The devil in the details of multimodal in-context learning.arXiv preprint arXiv:2403.13164, 2024
-
[9]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[10]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal LLM’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[12]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
work page 2019
-
[13]
Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusiñol, Ernest Valveny, C. V . Jawahar, and Dimosthenis Karatzas. Scene text visual question answering. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2019. 10
work page 2019
-
[14]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In2019 International Conference on Document Analysis and Recognition Workshops, 2019
work page 2019
-
[15]
Minesh Mathew, Dimosthenis Karatzas, and C. V . Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021
work page 2021
-
[16]
Hierarchical multimodal transformers for multi-page docvqa.Pattern Recognition, 2024
Rubèn Tito, Dimosthenis Karatzas, and Ernest Valveny. Hierarchical multimodal transformers for multi-page docvqa.Pattern Recognition, 2024
work page 2024
-
[17]
Minesh Mathew, Viraj Bagal, Rubèn Pérez Tito, Dimosthenis Karatzas, Ernest Valveny, and C. V . Jawahar. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision, 2022
work page 2022
-
[18]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the Association for Computational Linguistics, 2022
work page 2022
-
[19]
Letian Zhang, Xiaotong Zhai, Zhongkai Zhao, Yongshuo Zong, Xin Wen, and Bingchen Zhao. What if the tv was off? examining counterfactual reasoning abilities of multi-modal language models.arXiv preprint arXiv:2310.06627, 2024
-
[20]
Yusu Qian, Hanrong Ye, Jean-Philippe Fauconnier, Peter Grasch, Yinfei Yang, and Zhe Gan. MIA-Bench: Towards better instruction following evaluation of multimodal LLMs.arXiv preprint arXiv:2407.01509, 2024
-
[21]
Yifan Jia, Kailin Jiang, Yuyang Liang, Qihan Ren, Yi Xin, Rui Yang, Fenze Feng, Mingcai Chen, Hengyang Lu, Haozhe Wang, Xiaoye Qu, Dongrui Liu, Lizhen Cui, and Yuntao Du. Benchmarking multimodal knowledge conflict for large multimodal models.arXiv preprint arXiv:2505.19509, 2025
-
[22]
Yaning Pan, Qianqian Xie, Guohui Zhang, Zekun Wang, Yongqian Wen, Yuanxing Zhang, Haoxuan Hu, Zhiyu Pan, Yibing Huang, Zhidong Gan, et al. Mt-video-bench: A holistic video understanding benchmark for evaluating multimodal llms in multi-turn dialogues.arXiv preprint arXiv:2510.17722, 2025
-
[23]
Zikui Cai, Andrew Wang, Anirudh Satheesh, Ankit Nakhawa, Hyunwoo Jae, Keenan Pow- ell, Minghui Liu, Neel Jay, Sungbin Oh, Xiyao Wang, Yongyuan Liang, Tom Goldstein, and Furong Huang. Morse-500: A programmatically controllable video benchmark to stress-test multimodal reasoning.arXiv preprint arXiv:2506.05523, 2025
-
[24]
Lawrence Jang, Yinheng Li, Dan Zhao, Charles Ding, Justin Lin, Paul Pu Liang, Rogerio Bonatti, and Kazuhito Koishida. Videowebarena: Evaluating long context multimodal agents with video understanding web tasks.arXiv preprint arXiv:2410.19100, 2024
-
[25]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 11 A Supplementary Evaluation Details A.1 API and Agent Comparisons Table 5 reports matched...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.