Recognition: no theorem link
Large Language Models for Agentic NetOps and AIOps: Architectures, Evaluation, and Safety
Pith reviewed 2026-05-14 19:50 UTC · model grok-4.3
The pith
Operational reliability in LLM-based NetOps and AIOps comes from the machinery around the model rather than the model itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
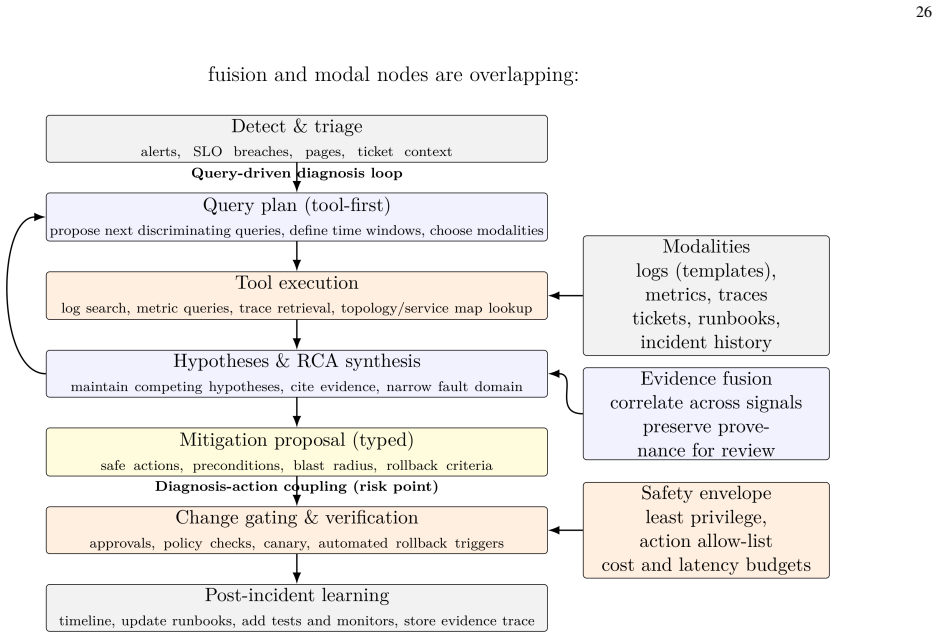
The paper claims that a consistent pattern appears across work on telemetry query recommendation, diagnosis, root-cause analysis, configuration synthesis, change planning, and limited self-healing. This pattern can be organized around the hierarchy of autonomy, tool scope, evidence traces, and assurance contracts. These contracts define what an agent may observe, propose, and execute, and they specify the checks that must pass before any action is allowed. Operational reliability does not come chiefly from the model itself. It depends on the machinery around the model, including permissions, policies, and rollback options. Evaluation should therefore move beyond static question answering to,
What carries the argument
The hierarchy of autonomy, tool scope, evidence traces, and assurance contracts, which structures agent workflows from evidence gathering to action while enforcing operational checks and constraints.
If this is right
- Agentic systems require workflow-centred evaluation that includes trace quality, bounded tool use, safe proposal generation, and replay in sandboxed environments with rollback-aware scoring.
- Progress depends on treating autonomy as a constrained operational control problem whose outputs must be reliable, auditable, and securely deployable.
- Security, privacy, and governance risks become acute when agents sit close to operational control surfaces.
Where Pith is reading between the lines
- The hierarchy could be tested for fit in other agentic settings such as robotic control or financial trading systems.
- Formal verification techniques could be added to strengthen assurance contracts.
- Empirical studies could quantify how much each layer of the hierarchy contributes to measured reliability.
Load-bearing premise
That the reviewed tasks exhibit a consistent pattern that can be usefully organized around the hierarchy of autonomy, tool scope, evidence traces, and assurance contracts.
What would settle it
A detailed literature scan that finds no shared structure across the listed tasks or shows reliability deriving primarily from the LLM without the additional machinery of contracts and checks.
Figures














read the original abstract
Large language models are increasingly being used to support network operations (NetOps) and artificial intelligence for IT operations (AIOps), including incident investigation, root-cause analysis, configuration synthesis, and limited self-healing. In both NetOps and AIOps, this shift is changing how tasks are managed. Agent-based operations work as workflows, from gathering evidence to taking action, following permissions, policies, and checks, and providing rollback options when necessary. This is crucial because operational decisions can have instant impacts. To make the argument concrete, we organise the relevant literature around the hierarchy of autonomy, tool scope, evidence traces, and assurance contracts. These contracts define what an agent may observe, propose, and execute. They also define the checks that must pass before any action is allowed. A consistent pattern appears across work on telemetry query recommendation, diagnosis, root-cause analysis, configuration synthesis, change planning, and limited self-healing. Operational reliability does not come chiefly from the model itself. It depends on the machinery around the model. We also argue that evaluation should go beyond static question answering. Agentic NetOps and AIOps systems require workflow-centred evaluation, including trace quality, bounded tool use, safe proposal generation, replay in sandboxed environments, and canary trials with rollback-aware scoring. Without these measures, a system may appear robust yet remain too fragile. Finally, we examine security, privacy, and governance risks that become acute when agents sit close to operational control surfaces. Taken together, the survey concludes that progress in intelligent NetOps and AIOps will depend on treating autonomy as a constrained operational control problem, whose outputs must be reliable, auditable, and securely deployable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys the application of large language models to agentic NetOps and AIOps tasks including telemetry query recommendation, diagnosis, root-cause analysis, configuration synthesis, change planning, and limited self-healing. It organizes the literature around a proposed hierarchy of autonomy, tool scope, evidence traces, and assurance contracts, arguing that operational reliability derives primarily from the surrounding machinery and constraints rather than the LLM itself. The work further advocates shifting evaluation from static QA to workflow-centered metrics (trace quality, bounded tool use, sandbox replay, canary trials) and examines security, privacy, and governance risks when agents approach operational control surfaces.
Significance. If the claimed consistent pattern across domains holds with explicit per-work mappings, the survey offers a useful organizing framework for designing constrained, auditable agentic systems in high-stakes operations. The emphasis on workflow evaluation and assurance contracts addresses a genuine gap between model capabilities and deployable reliability; the safety discussion is timely given the proximity to live control planes.
major comments (2)
- [Abstract and §3] Abstract and §3 (Literature Organization): The central claim that 'a consistent pattern appears across' the six domains and that 'operational reliability does not come chiefly from the model itself' is asserted via high-level summaries but lacks explicit per-paper mappings to the four elements (autonomy hierarchy, tool scope, evidence traces, assurance contracts) that isolate the machinery as the decisive factor. Without tables or structured breakdowns showing specific failures of model-only approaches versus successes attributable to contracts/traces, the pattern remains framed rather than evidenced.
- [§4] §4 (Evaluation): The call for workflow-centred evaluation (trace quality, bounded tool use, sandbox replay, rollback-aware scoring) is well-motivated but the section provides no concrete metrics, scoring rubrics, or example evaluation protocols drawn from the surveyed works; this leaves the recommendation at the level of desiderata rather than actionable guidance that could be adopted by the community.
minor comments (2)
- [Abstract and §1] The abstract and introduction use 'agentic' and 'workflows' without an early formal definition or diagram; a small taxonomy figure would clarify the hierarchy before the literature sections.
- [§5] Several citations in the safety section (§5) appear to be recent preprints; adding a note on the recency and potential volatility of those sources would help readers assess the stability of the risk claims.
Simulated Author's Rebuttal
Thank you for the constructive comments. We address the major points below and will incorporate revisions to provide more explicit mappings and concrete evaluation guidance.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Literature Organization): The central claim that 'a consistent pattern appears across' the six domains and that 'operational reliability does not come chiefly from the model itself' is asserted via high-level summaries but lacks explicit per-paper mappings to the four elements (autonomy hierarchy, tool scope, evidence traces, assurance contracts) that isolate the machinery as the decisive factor. Without tables or structured breakdowns showing specific failures of model-only approaches versus successes attributable to contracts/traces, the pattern remains framed rather than evidenced.
Authors: We appreciate this observation. Although the manuscript structures the discussion around the four elements with illustrative examples from the literature, we agree that a structured table would better evidence the consistent pattern. In the revised manuscript, we will introduce a summary table in Section 3 that explicitly maps each referenced work to the autonomy hierarchy, tool scope, evidence traces, and assurance contracts. This will highlight cases where model-only approaches fail and where the surrounding machinery provides the reliability, thereby strengthening the central claim. revision: yes
-
Referee: [§4] §4 (Evaluation): The call for workflow-centred evaluation (trace quality, bounded tool use, sandbox replay, rollback-aware scoring) is well-motivated but the section provides no concrete metrics, scoring rubrics, or example evaluation protocols drawn from the surveyed works; this leaves the recommendation at the level of desiderata rather than actionable guidance that could be adopted by the community.
Authors: We concur that the evaluation section would benefit from greater specificity. We will revise §4 to include concrete metrics and rubrics extracted from the surveyed papers, such as trace quality scores used in root-cause analysis studies, examples of bounded tool use from configuration works, and sandbox replay protocols from self-healing literature. Additionally, we will outline an example workflow evaluation protocol that the community could adopt, moving the recommendations from desiderata to actionable guidance. revision: yes
Circularity Check
No circularity: survey organizes literature without derivations or self-referential reductions
full rationale
The paper is a literature survey that proposes an organizational hierarchy (autonomy, tool scope, evidence traces, assurance contracts) to frame existing work on NetOps/AIOps tasks. No equations, fitted parameters, predictions, or derivations appear anywhere in the text. The central observation that reliability depends on surrounding machinery is presented as a pattern distilled from cited external literature rather than derived from the authors' prior results or by construction from the survey's own inputs. Self-citations, if present, are not load-bearing for any claim; the paper contains no uniqueness theorems, ansatzes, or renamings that reduce to self-reference. The derivation chain is therefore self-contained as a descriptive re-organization with no internal circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent-based operations work as workflows with permissions, policies, checks, and rollback options
Reference graph
Works this paper leans on
-
[1]
A general approach to network configuration analysis,
A. Fogel, S. Fung, L. Pedrosa, M. Walraed-Sullivan, R. Govindan, R. Mahajan, and T. Millstein, “A general approach to network configuration analysis,” inProceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15). USENIX Association, 2015, pp. 469–483
work page 2015
-
[2]
Header space analysis: Static checking for networks,
P. Kazemian, G. Varghese, and N. McKeown, “Header space analysis: Static checking for networks,” inProceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2012
work page 2012
-
[3]
VeriFlow: Verifying Network-Wide invariants in real time,
A. Khurshid, X. Zou, W. Zhou, M. Caesar, and P. B. Godfrey, “VeriFlow: Verifying Network-Wide invariants in real time,” in10th USENIX Symposium on Networked Systems Design and Implementation (NSDI 13). USENIX Association, Apr. 2013, pp. 15–27
work page 2013
-
[4]
N. R. Murphy, B. Beyer, C. Jones, and J. Petoff,Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media, 2016. 44
work page 2016
-
[5]
N. Forsgren, J. Humble, and G. Kim,Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations. IT Revolution Press, 2018
work page 2018
-
[6]
The vision of autonomic computing,
J. Kephart and D. Chess, “The vision of autonomic computing,”Computer, vol. 36, no. 1, pp. 41–50, 2003
work page 2003
-
[7]
Monitorassistant: Simplifying cloud service monitoring via large language models,
Z. Yu, M. Ma, C. Zhang, S. Qin, Y . Kang, C. Bansal, S. Rajmohan, Y . Dang, C. Pei, D. Pei, Q. Lin, and D. Zhang, “Monitorassistant: Simplifying cloud service monitoring via large language models,” inCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. ACM, 2024, pp. 38–49
work page 2024
-
[8]
Xpert: Empowering incident management with query recommendations via large language models,
Y . Jiang, C. Zhang, S. He, Z. Yang, M. Ma, S. Qin, Y . Kang, Y . Dang, S. Rajmohan, Q. Lin, and D. Zhang, “Xpert: Empowering incident management with query recommendations via large language models,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24. Association for Computing Machinery, 2024
work page 2024
-
[9]
Netassistant: Dialogue based network diagnosis in data center networks,
H. Wang, A. Abhashkumar, C. Lin, T. Zhang, X. Gu, N. Ma, C. Wu, S. Liu, W. Zhou, Y . Dong, W. Jiang, and Y . Wang, “Netassistant: Dialogue based network diagnosis in data center networks,” inProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI ’24). USENIX Association, 2024
work page 2024
-
[10]
Automatic root cause analysis via large language models for cloud incidents,
Y . Chen, H. Xie, M. Ma, Y . Kang, X. Gao, L. Shi, Y . Cao, X. Gao, H. Fan, M. Wen, J. Zeng, S. Ghosh, X. Zhang, C. Zhang, Q. Lin, S. Rajmohan, D. Zhang, and T. Xu, “Automatic root cause analysis via large language models for cloud incidents,” inProceedings of the 19th European Conference on Computer Systems (EuroSys ’24). ACM, 2024, pp. 674–688
work page 2024
-
[11]
Abstractions for network update,
M. Reitblatt, N. Foster, J. Rexford, C. Schlesinger, and D. Walker, “Abstractions for network update,” inProceedings of the ACM SIGCOMM 2012 Conference. ACM, 2012, pp. 323–334
work page 2012
-
[12]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems (NeurIPS 2020), 2020
work page 2020
-
[13]
Toolformer: language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessi, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: language models can teach themselves to use tools,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023
work page 2023
-
[14]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProceedings of the International Conference on Learning Representations, ser. ICLR 2023, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
work page 2023
-
[15]
A survey on intent-based networking,
A. Leivadeas and M. Falkner, “A survey on intent-based networking,”IEEE Communications Surveys & Tutorials, vol. 25, no. 1, pp. 625–655, 2023
work page 2023
-
[16]
Intent-based networking for the enterprise: a modern network architecture,
M. Falkner and J. Apostolopoulos, “Intent-based networking for the enterprise: a modern network architecture,”Communications of the ACM, vol. 65, no. 11, pp. 108–117, 2022
work page 2022
-
[17]
NetComplete: Practical network-wide configuration synthesis with autocompletion,
A. El-Hassany, P. Tsankov, L. Vanbever, and M. T. Vechev, “NetComplete: Practical network-wide configuration synthesis with autocompletion,” inProceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2018, pp. 579–594
work page 2018
-
[18]
A survey of aiops methods for failure management,
P. Notaro, J. Cardoso, and M. Gerndt, “A survey of aiops methods for failure management,”ACM Trans. Intell. Syst. Technol., vol. 12, no. 6, 2021
work page 2021
-
[19]
Webarena: A realistic web environment for building autonomous agents,
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Fried, U. Alon, and G. Neubig, “Webarena: A realistic web environment for building autonomous agents,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
API-bank: A comprehensive benchmark for tool-augmented LLMs,
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y . Li, “API-bank: A comprehensive benchmark for tool-augmented LLMs,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 3102–3116
work page 2023
-
[21]
Gorilla: Large language model connected with massive apis,
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,” inAdvances in Neural Information Processing Systems (NeurIPS 2024), vol. 37, 2024, pp. 126 544–126 565
work page 2024
-
[22]
Safely and automatically updating in-network acl configurations with intent language,
B. Tian, X. Zhang, E. Zhai, H. H. Liu, Q. Ye, C. Wang, X. Wu, Z. Ji, Y . Sang, M. Zhanget al., “Safely and automatically updating in-network acl configurations with intent language,” inProceedings of the ACM Special Interest Group on Data Communication, 2019, pp. 214–226
work page 2019
-
[23]
SWE-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[24]
Understanding BGP misconfiguration,
R. Mahajan, D. Wetherall, and T. Anderson, “Understanding BGP misconfiguration,” inProceedings of the ACM SIGCOMM 2002 Conference, 2002, pp. 3–16
work page 2002
-
[25]
Openflow: enabling innovation in campus networks,
N. McKeown, T. Anderson, H. Balakrishnan, G. Parulkar, L. Peterson, J. Rexford, S. Shenker, and J. Turner, “Openflow: enabling innovation in campus networks,”SIGCOMM Comput. Commun. Rev., vol. 38, no. 2, p. 69–74, 2008
work page 2008
-
[26]
Consistent updates for software-defined networks: change you can believe in!
M. Reitblatt, N. Foster, J. Rexford, and D. Walker, “Consistent updates for software-defined networks: change you can believe in!” inProceedings of the 10th ACM Workshop on Hot Topics in Networks, ser. HotNets-X, 2011, pp. 1–6
work page 2011
-
[27]
G-rca: A generic root cause analysis platform for service quality management in large ip networks,
H. Yan, L. Breslau, Z. Ge, D. Massey, D. Pei, and J. Yates, “G-rca: A generic root cause analysis platform for service quality management in large ip networks,”IEEE/ACM Transactions on Networking, vol. 20, no. 6, pp. 1734–1747, 2012
work page 2012
-
[28]
Mining causality of network events in log data,
S. Kobayashi, K. Otomo, K. Fukuda, and H. Esaki, “Mining causality of network events in log data,”IEEE Transactions on Network and Service Management, vol. 15, no. 1, pp. 53–67, 2018
work page 2018
-
[29]
Causal analysis of network logs with layered protocols and topology knowledge,
S. Kobayashi, K. Otomo, and K. Fukuda, “Causal analysis of network logs with layered protocols and topology knowledge,” in2019 15th International Conference on Network and Service Management (CNSM), 2019, pp. 1–9
work page 2019
-
[30]
A general approach to network configuration verification,
R. Beckett, A. Gupta, R. Mahajan, and D. Walker, “A general approach to network configuration verification,” inProceedings of the ACM SIGCOMM 2017 Conference, 2017, pp. 155–168
work page 2017
-
[31]
Checking beliefs in dynamic networks,
N. P. Lopes, N. Bjørner, P. Godefroid, K. Jayaraman, and G. Varghese, “Checking beliefs in dynamic networks,” inProceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15), 2015, pp. 499–512. 45
work page 2015
-
[32]
Lessons from the evolution of the batfish configuration analysis tool,
M. Brown, A. Fogel, D. Halperin, V . Heorhiadi, R. Mahajan, and T. Millstein, “Lessons from the evolution of the batfish configuration analysis tool,” inProceedings of the ACM SIGCOMM 2023 Conference, 2023, pp. 122–135
work page 2023
-
[33]
Pinpoint: Problem determination in large, dynamic internet services,
M. Y . Chen, E. Kiciman, E. Fratkin, A. Fox, and E. A. Brewer, “Pinpoint: Problem determination in large, dynamic internet services,” inProceedings of the International Conference on Dependable Systems and Networks (DSN). IEEE, 2002, pp. 595–604
work page 2002
-
[34]
Orca: Differential bug localization in large-scale services,
R. Bhagwan, R. Kumar, C. S. Maddila, and A. A. Philip, “Orca: Differential bug localization in large-scale services,” inProceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18), 2018, pp. 493–509
work page 2018
-
[35]
Towards intelligent incident management: why we need it and how we make it,
Z. Chen, Y . Kang, L. Li, X. Zhang, H. Zhang, H. Xu, Y . Zhou, L. Yang, J. Sun, Z. Xuet al., “Towards intelligent incident management: why we need it and how we make it,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2020, pp. 1487–1497
work page 2020
-
[36]
J. Jiang, W. Lu, J. Chen, Q. Lin, P. Zhao, Y . Kang, H. Zhang, Y . Xiong, F. Gao, Z. Xuet al., “How to mitigate the incident? an effective troubleshooting guide recommendation technique for online service systems,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineeri...
work page 2020
-
[37]
Enjoy your observability: An industrial survey of microservice tracing and analysis,
B. Li, X. Peng, Q. Xiang, H. Wang, T. Xie, J. Sun, and X. Liu, “Enjoy your observability: An industrial survey of microservice tracing and analysis,”Empirical Software Engineering, vol. 27, no. 1, p. 25, 2022
work page 2022
-
[38]
MRCA: Metric-level root cause analysis for microservices via multi-modal data,
Y . Wang, Z. Zhu, Q. Fu, Y . Ma, and P. He, “MRCA: Metric-level root cause analysis for microservices via multi-modal data,” in Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24), 2024, pp. 1057–1068
work page 2024
-
[39]
Hemirca: Fine-grained root cause analysis for microservices with heterogeneous data sources,
Z. Zhu, C. Lee, X. Tang, and P. He, “Hemirca: Fine-grained root cause analysis for microservices with heterogeneous data sources,” ACM Trans. Softw. Eng. Methodol., vol. 33, no. 8, 2024
work page 2024
-
[40]
X-trace: A pervasive network tracing framework,
R. Fonseca, G. Porter, R. H. Katz, S. Shenker, and I. Stoica, “X-trace: A pervasive network tracing framework,” inProceedings of the 4th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’07), 2007, pp. 271–284
work page 2007
-
[41]
Canopy: An end-to-end performance tracing and analysis system,
J. Kaldor, J. Mace, M. Bejda, E. Gao, W. Kuropatwa, J. O’Neill, K. W. Ong, B. Schaller, P. Shan, B. Viscomi, V . Venkataraman, K. Veeraraghavan, and Y . J. Song, “Canopy: An end-to-end performance tracing and analysis system,” inProceedings of the 26th ACM Symposium on Operating Systems Principles (SOSP ’17), 2017, pp. 34–50
work page 2017
-
[42]
An empirical study of policy as code: Adoption, purpose, and maintenance,
R. Opdebeeck, M. Alfadel, A. Rahman, Y . Kashiwa, J. F. Ferreira, R. G. Kula, and C. D. Roover, “An empirical study of policy as code: Adoption, purpose, and maintenance,” inProceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026), 2026
work page 2026
-
[43]
Automated infrastructure as code program testing,
D. Sokolowski, D. Spielmann, and G. Salvaneschi, “Automated infrastructure as code program testing,”IEEE Transactions on Software Engineering, vol. 50, no. 6, pp. 1585–1599, 2024
work page 2024
-
[44]
Change management in physical network lifecycle automation,
M. Al-Fares, V . Beauregard, K. Grant, A. Griffith, J. Hasan, C. Huang, Q. Leng, J. Li, A. Lin, Z. Liu, A. Mansy, B. Martinusen, N. Mehta, J. C. Mogul, A. Narver, A. Nigham, M. Obenberger, S. Smith, K. Steinkraus, S. Sun, E. Thiele, and A. Vahdat, “Change management in physical network lifecycle automation,” in2023 USENIX Annual Technical Conference (USEN...
work page 2023
-
[45]
Learning from lessons learned: Preliminary findings from a study of learning from failure,
J. Sillito and M. Pope, “Learning from lessons learned: Preliminary findings from a study of learning from failure,” inProceedings of the 2024 IEEE/ACM 17th International Conference on Cooperative and Human Aspects of Software Engineering, 2024, pp. 97–102
work page 2024
-
[46]
Drain: An online log parsing approach with fixed depth tree,
P. He, J. Zhu, Z. Zheng, and M. R. Lyu, “Drain: An online log parsing approach with fixed depth tree,” in2017 IEEE International Conference on Web Services (ICWS), 2017, pp. 33–40
work page 2017
-
[47]
Deeplog: Anomaly detection and diagnosis from system logs through deep learning,
M. Du, F. Li, G. Zheng, and V . Srikumar, “Deeplog: Anomaly detection and diagnosis from system logs through deep learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017, pp. 1285–1298
work page 2017
-
[48]
Loghub: A large collection of system log datasets for ai-driven log analytics,
J. Zhu, S. He, P. He, J. Liu, and M. R. Lyu, “Loghub: A large collection of system log datasets for ai-driven log analytics,” in2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE), 2023, pp. 355–366
work page 2023
-
[49]
OpenTelemetry Authors, “Opentelemetry specification,” Cloud Native Computing Foundation (CNCF), 2024, accessed: 2026-02-02
work page 2024
-
[50]
An empirical study on change-induced incidents of online service systems,
Y . Wu, B. Chai, Y . Li, B. Liu, J. Li, Y . Yang, and W. Jiang, “An empirical study on change-induced incidents of online service systems,” inProceedings of the IEEE/ACM 45th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 2023, pp. 234–245
work page 2023
-
[51]
Identifying linked incidents in large-scale online service systems,
Y . Chen, X. Yang, H. Dong, X. He, H. Zhang, Q. Lin, J. Chen, P. Zhao, Y . Kang, F. Gao, Z. Xu, and D. Zhang, “Identifying linked incidents in large-scale online service systems,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2020, pp. 304–314
work page 2020
-
[52]
Llexus: an ai agent system for incident management,
P. Las-Casas, A. G. Kumbhare, R. Fonseca, and S. Agarwal, “Llexus: an ai agent system for incident management,”SIGOPS Oper. Syst. Rev., vol. 58, no. 1, 2024
work page 2024
-
[53]
Tool learning with foundation models,
Y . Qin, S. Hu, Y . Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, X. Zhou, Y . Huang, C. Xiao, C. Han, Y . R. Fung, Y . Su, H. Wang, C. Qian, R. Tian, K. Zhu, S. Liang, X. Shen, B. Xu, Z. Zhang, Y . Ye, B. Li, Z. Tang, J. Yi, Y . Zhu, Z. Dai, L. Yan, X. Cong, Y . Lu, W. Zhao, Y . Huang, J. Yan, X. Han, X. Sun, D. Li, J. Phang, C. Yang, T. Wu, H. Ji, G. Li, Z. L...
work page 2024
-
[54]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs,
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qian, S. Zhao, L. Hong, R. Tian, R. Xie, J. Zhou, M. Gerstein, D. Li, Z. Liu, and M. Sun, “ToolLLM: Facilitating large language models to master 16000+ real-world APIs,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[55]
J. Humble and D. Farley,Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Addison- Wesley Professional, 2010
work page 2010
-
[56]
Risk based planning of network changes in evolving data centers,
O. Alipourfard, J. Gao, J. Koenig, C. Harshaw, A. Vahdat, and M. Yu, “Risk based planning of network changes in evolving data centers,” inProceedings of the 27th ACM Symposium on Operating Systems Principles, ser. SOSP ’19. New York, NY , USA: Association for Computing Machinery, 2019, pp. 414–429
work page 2019
-
[57]
Artificial intelligence risk management framework: Generative artificial intelligence profile,
C. Autio, R. Schwartz, J. Dunietz, S. Jain, M. Stanley, E. Tabassi, P. Hall, and K. Roberts, “Artificial intelligence risk management framework: Generative artificial intelligence profile,” Tech. Rep., 2024-07-26 04:07:00 2024. 46
work page 2024
-
[58]
Creating characteristically auditable agentic ai systems,
C. C. Phiri, “Creating characteristically auditable agentic ai systems,” inProceedings of Intelligent Robotics FAIR 2025 (IntRob ’25), 2025, pp. 1–14
work page 2025
-
[59]
What do llms need to synthesize correct router configurations?
R. Mondal, A. Tang, R. Beckett, T. Millstein, and G. Varghese, “What do llms need to synthesize correct router configurations?” in Proceedings of the 22nd ACM Workshop on Hot Topics in Networks (HotNets ’23). Association for Computing Machinery, 2023, pp. 189–195
work page 2023
-
[60]
Meshagent: Enabling reliable network management with large language models,
Y . Zhou, K. Hsieh, S. K. Mani, S. Kandula, and Z. Liu, “Meshagent: Enabling reliable network management with large language models,”Proc. ACM Meas. Anal. Comput. Syst., vol. 9, no. 3, Dec. 2025
work page 2025
-
[61]
Artificial intelligence risk management framework (ai rmf 1.0),
E. Tabassi, “Artificial intelligence risk management framework (ai rmf 1.0),” Tech. Rep., 2023-01-26 05:01:00 2023
work page 2023
-
[62]
Dapper, a large-scale distributed systems tracing infrastructure,
B. H. Sigelman, L. A. Barroso, M. Burrows, P. Stephenson, M. Plakal, D. Beaver, S. Jaspan, and C. Shanbhag, “Dapper, a large-scale distributed systems tracing infrastructure,” Google, Inc., Tech. Rep., 2010, technical report (widely circulated)
work page 2010
-
[63]
Pivot tracing: Dynamic causal monitoring for distributed systems,
J. Mace, R. Roelke, and R. Fonseca, “Pivot tracing: Dynamic causal monitoring for distributed systems,” inProceedings of the 25th Symposium on Operating Systems Principles (SOSP ’15). Association for Computing Machinery, 2015, pp. 378–393
work page 2015
-
[64]
Real time network policy checking using header space analysis,
P. Kazemian, M. Chang, H. Zeng, G. Varghese, N. McKeown, and S. Whyte, “Real time network policy checking using header space analysis,” inProceedings of the 10th USENIX Conference on Networked Systems Design and Implementation, 2013, p. 99–112
work page 2013
-
[65]
Accuracy, scalability, coverage: A practical configuration verifier on a global wan,
F. Ye, D. Yu, E. Zhai, H. H. Liu, B. Tian, Q. Ye, C. Wang, X. Wu, T. Guo, C. Jin, D. She, Q. Ma, B. Cheng, H. Xu, M. Zhang, Z. Wang, and R. Fonseca, “Accuracy, scalability, coverage: A practical configuration verifier on a global wan,” inProceedings of the ACM SIGCOMM 2020 Conference, 2020, pp. 599–614
work page 2020
-
[66]
Itbench: evaluating ai agents across diverse real-world it automation tasks,
S. Jha, R. Arora, Y . Watanabe, T. Yanagawa, Y . Chen, J. Clark, B. Bhavya, M. Verma, H. Kumar, H. Kitahara, N. Zheutlin, S. Takano, D. Pathak, F. George, X. Wu, B. O. Turkkan, G. Vanloo, M. Nidd, T. Dai, O. Chatterjee, P. Gupta, S. Samanta, P. Aggarwal, R. Lee, J.-w. Ahn, D. Kar, A. Paradkar, Y . Deng, P. Moogi, P. Mohapatra, N. Abe, C. Narayanaswami, T....
work page 2025
-
[67]
Agentbench: Evaluating llms as agents,
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y . Su, H. Sun, M. Huang, Y . Dong, and J. Tang, “Agentbench: Evaluating llms as agents,” inICLR 2024, 2024
work page 2024
-
[68]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains,
S. Yao, N. Shinn, P. Razavi, and K. R. Narasimhan, “τ-bench: A benchmark for tool-agent-user interaction in real-world domains,” inInternational Conference on Learning Representations (ICLR 2025), 2025. [Online]. Available: https://openreview.net/forum?id=roNSXZpUDN
work page 2025
- [69]
-
[70]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,” inProceedings of the 2023 Workshop on Artificial Intelligence and Security (AISec ’23). Association for Computing Machinery, 2023, pp. 79–90
work page 2023
-
[71]
StruQ: Defending against prompt injection with structured queries,
S. Chen, J. Piet, C. Sitawarin, and D. Wagner, “StruQ: Defending against prompt injection with structured queries,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 2383–2400
work page 2025
-
[72]
D. Pasquini, E. M. Kornaropoulos, G. Ateniese, O. Akgul, A. Theocharis, and P. Efstathopoulos, “When AIOps become “AI oops”: Subverting LLM-driven IT operations via telemetry manipulation,” arXiv:2508.06394, 2025
-
[73]
Failures and fixes: A study of software system incident response,
J. Sillito and E. Kutomi, “Failures and fixes: A study of software system incident response,” in2020 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2020, pp. 185–195
work page 2020
-
[74]
Trust in collaborative automation in high stakes software engineering work: A case study at nasa,
D. G. Widder, L. Dabbish, J. D. Herbsleb, A. Holloway, and S. Davidoff, “Trust in collaborative automation in high stakes software engineering work: A case study at nasa,” inProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, 2021
work page 2021
-
[75]
RCAgent: Cloud root cause analysis by autonomous agents with tool-augmented large language models,
Z. Wang, Z. Liu, Y . Zhang, A. Zhong, J. Wang, F. Yin, L. Fan, L. Wu, and Q. Wen, “RCAgent: Cloud root cause analysis by autonomous agents with tool-augmented large language models,” inProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM), 2024, pp. 4966–4974
work page 2024
-
[76]
Acto: Automatic end-to-end testing for operation correctness of cloud system management,
J. T. Gu, X. Sun, W. Zhang, Y . Jiang, C. Wang, M. Vaziri, O. Legunsen, and T. Xu, “Acto: Automatic end-to-end testing for operation correctness of cloud system management,” inProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP). ACM, 2023, pp. 96–112
work page 2023
-
[77]
Conveyor: One-Tool-Fits-All continuous software deployment at meta,
B. Grubic, Y . Wang, T. Petrochko, R. Yaniv, B. Jones, D. Callies, M. Clarke-Lauer, D. Kelley, S. Demetriou, K. Yu, and C. Tang, “Conveyor: One-Tool-Fits-All continuous software deployment at meta,” in17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). USENIX Association, 2023, pp. 325–342
work page 2023
-
[78]
Localized explanations for automatically synthesized network configurations,
A. Nazari, Y . Zhang, M. Raghothaman, and H. Chen, “Localized explanations for automatically synthesized network configurations,” inProceedings of the 23rd ACM Workshop on Hot Topics in Networks (HotNets), 2024, pp. 52–59
work page 2024
-
[79]
Automatic configuration repair,
X. Liu, P. Zhang, A. Abhashkumar, J. Chen, and W. Jiang, “Automatic configuration repair,” inProceedings of the 23rd ACM Workshop on Hot Topics in Networks (HotNets), 2024, pp. 213–220
work page 2024
-
[80]
Learning to generate structured output with schema reinforcement learning,
Y . Lu, H. Li, X. Cong, Z. Zhang, Y . Wu, Y . Lin, Z. Liu, F. Liu, and M. Sun, “Learning to generate structured output with schema reinforcement learning,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 4905–4918
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.