Recognition: no theorem link
CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
Pith reviewed 2026-05-14 20:33 UTC · model grok-4.3
The pith
Multimodal document models often produce correct answers while citing the wrong evidence regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
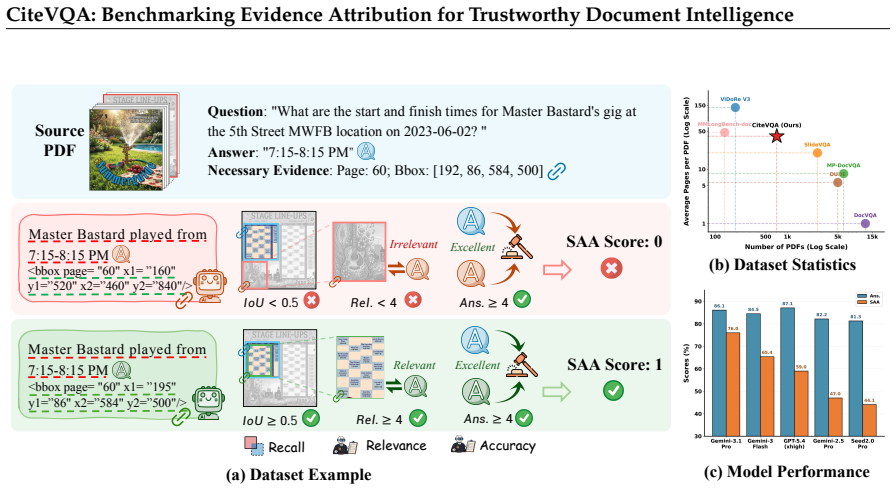
Multimodal large language models exhibit attribution hallucination: they frequently return the right answer to a document question while citing the wrong bounding-box regions within the document. CiteVQA addresses this by requiring models to output element-level citations alongside each answer and scores them with Strict Attributed Accuracy, which awards credit only when both the answer and the cited regions are correct.
What carries the argument
CiteVQA benchmark and its Strict Attributed Accuracy metric, which jointly require correct answers and correct element-level bounding-box citations, with ground truth produced by an automated masking-ablation pipeline validated by experts.
If this is right
- Answer-only evaluations systematically overestimate the reliability of current multimodal models on document tasks.
- High-stakes document intelligence applications require models that can supply traceable, element-level citations.
- Model training objectives must add explicit supervision for citation accuracy rather than optimizing answer accuracy alone.
- Benchmarks that ignore attribution leave a reliability gap in regulated domains such as law and medicine.
Where Pith is reading between the lines
- The same attribution failures likely appear in other multimodal settings where models must reference specific image or chart regions rather than document pages.
- Training regimes that reward only final-answer correctness without penalizing incorrect citations probably reinforce this hallucination pattern.
- Extending CiteVQA to include layout-heavy documents or non-English languages could test whether the attribution gap is language- or domain-specific.
Load-bearing premise
The automated masking-ablation pipeline plus expert review produces accurate ground-truth element-level citations that correctly identify the minimal sufficient evidence regions for each question.
What would settle it
Running the same models on a modified version of the documents in which the original evidence regions are replaced with plausible but incorrect text while the correct answers remain unchanged, then checking whether the models shift their citations to the new regions or continue citing the removed ones.
Figures








read the original abstract
Multimodal Large Language Models (MLLMs) have significantly advanced document understanding, yet current Doc-VQA evaluations score only the final answer and leave the supporting evidence unchecked. This answer-only approach masks a critical failure mode: a model can land on the correct answer while grounding it in the wrong passage -- a critical risk in high-stakes domains like law, finance, and medicine, where every conclusion must be traceable to a specific source region. To address this, we introduce CiteVQA, a benchmark that requires models to return element-level bounding-box citations alongside each answer, evaluating both jointly. CiteVQA comprises 1,897 questions across 711 PDFs spanning seven domains and two languages, averaging 40.6 pages per document. To ensure fidelity and scalability, the ground-truth citations are generated by an automated pipeline-which identifies crucial evidence via masking ablation-and are subsequently validated through expert review. At the core of our evaluation is Strict Attributed Accuracy (SAA), which credits a prediction only when the answer and the cited region are both correct. Auditing 20 MLLMs reveals a pervasive Attribution Hallucination: models frequently produce the right answer while citing the wrong region. The strongest system (Gemini-3.1-Pro-Preview) achieves an SAA of only 76.0, and the strongest open-source MLLM reaches just 22.5. Ultimately, towards trustworthy document intelligence, CiteVQA exposes a reliability gap that answer-only evaluations overlook, providing the instrumentation needed to close it. Our repository is available at https://github.com/opendatalab/CiteVQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
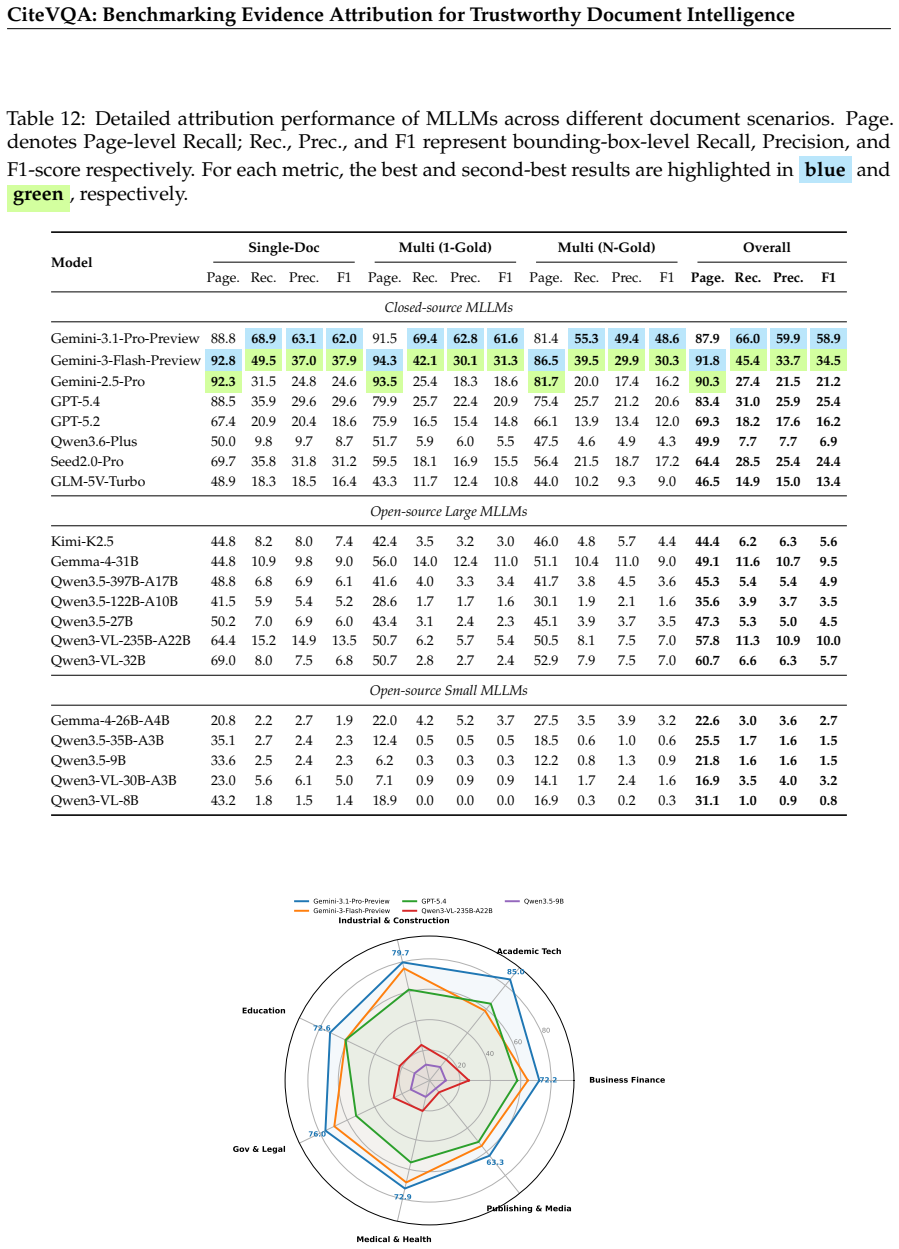
Summary. The paper introduces CiteVQA, a benchmark for joint evaluation of answer correctness and element-level bounding-box citations in multimodal document VQA. It contains 1,897 questions over 711 PDFs (average 40.6 pages) spanning seven domains and two languages. Ground-truth citations are produced via an automated masking-ablation pipeline followed by expert review. The central metric is Strict Attributed Accuracy (SAA), which requires both the answer and the cited region to be correct. Auditing 20 MLLMs reveals pervasive attribution hallucinations, with the strongest model (Gemini-3.1-Pro-Preview) reaching only 76.0 SAA and the strongest open-source model reaching 22.5.
Significance. If the ground-truth element-level citations are reliable, the benchmark is significant because it exposes a failure mode (correct answer with incorrect evidence) that answer-only Doc-VQA evaluations overlook. The scale, domain diversity, and joint evaluation provide concrete instrumentation for improving trustworthiness in high-stakes document intelligence applications. The empirical results on 20 models supply falsifiable measurements that future work can directly compare against.
major comments (2)
- [Dataset construction] Dataset construction section: The automated masking-ablation pipeline that identifies crucial evidence is under-specified. The manuscript provides no details on masking granularity (element vs. region level), the exact selection threshold or criterion for designating evidence as 'crucial', or the procedure for multi-region or overlapping evidence cases. These omissions make it impossible to assess whether the 1,897 ground-truth citations correctly capture the minimal sufficient evidence regions, which is load-bearing for the SAA scores and the attribution-hallucination diagnosis.
- [Expert validation] Expert validation subsection: No inter-annotator agreement statistics, disagreement resolution protocol, or measured error rate are reported for the expert review step that validates the automated pipeline outputs. Without these quantities, the fidelity of the ground-truth element-level bounding boxes cannot be quantified, undermining confidence in the reported SAA values (76.0 / 22.5).
minor comments (2)
- [Abstract] Abstract: Clarify whether the reported average of 40.6 pages per document is the mean or median, and whether page count includes only text pages or all pages.
- [Evaluation] Evaluation section: Provide the exact definition of SAA in an equation or pseudocode box so that readers can reproduce the joint correctness check without ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and will incorporate the requested clarifications into the revised manuscript to improve reproducibility and transparency of the benchmark construction.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: The automated masking-ablation pipeline that identifies crucial evidence is under-specified. The manuscript provides no details on masking granularity (element vs. region level), the exact selection threshold or criterion for designating evidence as 'crucial', or the procedure for multi-region or overlapping evidence cases. These omissions make it impossible to assess whether the 1,897 ground-truth citations correctly capture the minimal sufficient evidence regions, which is load-bearing for the SAA scores and the attribution-hallucination diagnosis.
Authors: We agree that the manuscript description of the masking-ablation pipeline is too concise. In the revised version we will expand the Dataset Construction section with the following details: masking operates at the element level (individual text blocks, tables, and figures identified by the layout parser); a region is labeled crucial if its ablation either flips the answer or reduces the log-probability of the correct answer by more than 15%; and multi-region or overlapping cases are handled by greedily selecting the smallest non-overlapping set of elements whose joint ablation affects the answer. These exact procedures are already implemented in the released code repository; documenting them explicitly in the paper will allow readers to evaluate the fidelity of the ground-truth citations. revision: yes
-
Referee: [Expert validation] Expert validation subsection: No inter-annotator agreement statistics, disagreement resolution protocol, or measured error rate are reported for the expert review step that validates the automated pipeline outputs. Without these quantities, the fidelity of the ground-truth element-level bounding boxes cannot be quantified, undermining confidence in the reported SAA values (76.0 / 22.5).
Authors: We acknowledge that quantitative validation metrics were omitted. In the original process two experts reviewed the automated outputs on a stratified sample of 300 questions, achieving 91% raw agreement (Cohen’s kappa = 0.84). Disagreements were resolved by discussion followed by a third-expert tie-break; the final measured discrepancy rate between the automated pipeline and the expert-corrected citations was 3.8%. We will add a dedicated paragraph to the Expert Validation subsection reporting these figures, the sampling procedure, and the resolution protocol. This will directly quantify the reliability of the ground-truth bounding boxes. revision: yes
Circularity Check
No circularity; empirical benchmark with independent ground-truth construction
full rationale
The paper presents CiteVQA as a new dataset and evaluation protocol for joint answer-plus-citation accuracy in document VQA. SAA is defined directly as the fraction of cases where both the answer is correct and the cited bounding box matches the ground-truth region. Ground-truth regions are produced by an external masking-ablation procedure followed by expert review; this is a data-generation method, not a fitted parameter or self-referential equation. No derivations, uniqueness theorems, or ansatzes are invoked that reduce to the paper's own inputs or prior self-citations. All reported numbers (SAA scores of 76.0 and 22.5) are direct empirical measurements on held-out questions. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert review of the automated masking-ablation pipeline produces reliable ground-truth citations
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Maintnorm: A corpus and benchmark model for lexical normalisation and masking of industrial maintenance short text
Tyler Bikaun, Melinda Hodkiewicz, and Wei Liu. Maintnorm: A corpus and benchmark model for lexical normalisation and masking of industrial maintenance short text. InProceedings of the Ninth Workshop on Noisy and User-generated Text (W-NUT 2024), pages 68–78, 2024
2024
-
[4]
Xiuyuan Chen, Tao Sun, Dexin Su, Ailing Yu, Junwei Liu, Zhe Chen, Gangzeng Jin, Xin Wang, Jingnan Liu, Hansong Xiao, et al. Gaps: A clinically grounded, automated benchmark for evaluating ai clinicians.arXiv preprint arXiv:2510.13734, 2025
-
[5]
M3DOCRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding.arXiv preprint arXiv:2411.04952, 2024
-
[6]
Chao Deng, Jiale Yuan, Pi Bu, Peijie Wang, Zhong-Zhi Li, Jian Xu, Xiao-Hui Li, Yuan Gao, Jun Song, Bo Zheng, and Cheng-Lin Liu. Longdocurl: a comprehensive multimodal long document benchmark integrating understanding, reasoning, and locating.arXiv preprint arXiv:2412.18424, 2024
-
[7]
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models.arXiv preprint arXiv:2407.01449, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
Jessica Foo, Pradyumna Shyama Prasad, and Shaun Khoo. Know or not: a library for evaluating out-of- knowledge base robustness.arXiv preprint arXiv:2505.13545, 2025
-
[9]
Enabling large language models to generate text with citations
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. Enabling large language models to generate text with citations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465–6488, 2023
2023
-
[10]
Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, and Jingren Zhou. mplug-docowl 1.5: Unified structure learning for ocr-free document understanding.arXiv preprint arXiv:2403.12895, 2024
-
[11]
Layoutlmv3: Pre-training for document ai with unified text and image masking
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. Layoutlmv3: Pre-training for document ai with unified text and image masking. InProceedings of the 30th ACM International Conference on Multimedia, pages 4083–4091, 2022
2022
-
[12]
Simpledoc: Multi-modal document understanding with dual-cue page retrieval and iterative refinement
Chelsi Jain, Yiran Wu, Yifan Zeng, Jiale Liu, Shengyu Dai, Zhenwen Shao, Qingyun Wu, and Huazheng Wang. Simpledoc: Multi-modal document understanding with dual-cue page retrieval and iterative refinement. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28398–28415, 2025
2025
-
[13]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.arXiv preprint arXiv:2009.13081, 2020
-
[14]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[15]
Med-r2: Crafting trustworthy llm physicians via retrieval and reasoning of evidence-based medicine
Lu Keer, Zheng Liang, Da Pan, Shusen Zhang, Guosheng Dong, Huang Leng, Bin Cui, Zhonghai Wu, and Wentao Zhang. Med-r2: Crafting trustworthy llm physicians via retrieval and reasoning of evidence-based medicine. InProceedings of the ACM Web Conference 2026, pages 1864–1875, 2026
2026
-
[16]
Ocr-free document understanding transformer
Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. InEuropean Conference on Computer Vision, pages 498–517. Springer, 2022. 11 CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
2022
-
[17]
Rush, Douwe Kiela, Matthieu Cord, and Victor Sanh
Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, and Victor Sanh. Obelics: An open web-scale filtered dataset of interleaved image-text documents, 2023
2023
-
[18]
Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, et al. Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
-
[19]
António Loison, Quentin Macé, Antoine Edy, Victor Xing, Tom Balough, Gabriel Moreira, Bo Liu, Manuel Faysse, Céline Hudelot, and Gautier Viaud. Vidore v3: A comprehensive evaluation of retrieval augmented generation in complex real-world scenarios.arXiv preprint arXiv:2601.08620, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Med-r2: Crafting trustworthy llm physicians through retrieval and reasoning of evidence-based medicine.arXiv e-prints, pages arXiv–2501, 2025
Keer Lu, Zheng Liang, Da Pan, Shusen Zhang, Xin Wu, Weipeng Chen, Zenan Zhou, Guosheng Dong, Bin Cui, and Wentao Zhang. Med-r2: Crafting trustworthy llm physicians through retrieval and reasoning of evidence-based medicine.arXiv e-prints, pages arXiv–2501, 2025
2025
-
[21]
Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems, 37:95963–96010, 2024
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems, 37:95963–96010, 2024
2024
-
[22]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
2022
-
[23]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021
2021
-
[24]
Infograph- icvqa
Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infograph- icvqa. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1697–1706, 2022
2022
-
[25]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023
2023
-
[26]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In2019 international conference on document analysis and recognition (ICDAR), pages 947–952. IEEE, 2019
2019
-
[27]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [28]
-
[29]
Omnidocbench: Benchmarking diverse pdf document parsing with com- prehensive annotations
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, et al. Omnidocbench: Benchmarking diverse pdf document parsing with com- prehensive annotations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24838–24848, 2025
2025
-
[30]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Spiqa: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807–118833, 2024
Shraman Pramanick, Rama Chellappa, and Subhashini Venugopalan. Spiqa: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807–118833, 2024
2024
-
[32]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020. 12 CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
2020
-
[33]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.arXiv preprint arXiv:2111.02114, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Seed1.8 Model Card: Towards Generalized Real-World Agency
Bytedance Seed. Seed1.8 model card: Towards generalized real-world agency, 2026. URL https://arxiv. org/abs/2603.20633
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Slidevqa: A dataset for document visual question answering on multiple images
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, and Kuniko Saito. Slidevqa: A dataset for document visual question answering on multiple images. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13636–13645, 2023
2023
-
[36]
Vdocrag: Retrieval-augmented generation over visually-rich documents
Ryota Tanaka, Taichi Iki, Taku Hasegawa, Kyosuke Nishida, Kuniko Saito, and Jun Suzuki. Vdocrag: Retrieval-augmented generation over visually-rich documents. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24827–24837, 2025
2025
-
[37]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Hierarchical multimodal transformers for multipage docvqa.Pattern Recognition, 144:109834, 2023
Rubèn Tito, Dimosthenis Karatzas, and Ernest Valveny. Hierarchical multimodal transformers for multipage docvqa.Pattern Recognition, 144:109834, 2023
2023
-
[40]
Ccpdf: Building a high quality corpus for visually rich documents from web crawl data
Michał Turski, Tomasz Stanisławek, Karol Kaczmarek, Paweł Dyda, and Filip Grali ´ nski. Ccpdf: Building a high quality corpus for visually rich documents from web crawl data. InInternational Conference on Document Analysis and Recognition, pages 348–365. Springer, 2023
2023
-
[41]
Document understanding dataset and evaluation (dude)
Jordy Van Landeghem, Rubèn Tito, Łukasz Borchmann, Michał Pietruszka, Paweł Józiak, Rafał Powalski, Dawid Jurkiewicz, Mickaël Coustaty, Bertrand Ackaert, Ernest Valveny, Matthew Blaschko, Sien Moens, and Tomasz Stanisławek. Document understanding dataset and evaluation (dude). InProceedings of the IEEE/CVF International Conference on Computer Vision, page...
2023
-
[42]
Bin Wang, Tianyao He, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Tao Chu, Yuan Qu, Zhenjiang Jin, Weijun Zeng, Ziyang Miao, et al. Mineru2. 5-pro: Pushing the limits of data-centric document parsing at scale.arXiv preprint arXiv:2604.04771, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Rare: Retrieval-augmented reasoning modeling.arXiv preprint arXiv:2503.23513, 2025
Zhengren Wang, Jiayang Yu, Dongsheng Ma, Zhe Chen, Yu Wang, Zhiyu Li, Feiyu Xiong, Yanfeng Wang, Linpeng Tang, Wentao Zhang, et al. Rare: Retrieval-augmented reasoning modeling.arXiv preprint arXiv:2503.23513, 2025
-
[44]
Zhengren Wang, Dongsheng Ma, Huaping Zhong, Jiayu Li, Wentao Zhang, Bin Wang, and Conghui He. Agenticocr: Parsing only what you need for efficient retrieval-augmented generation.arXiv preprint arXiv:2602.24134, 2026
-
[45]
Charxiv: Charting gaps in realistic chart understanding in multimodal llms
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, et al. Charxiv: Charting gaps in realistic chart understanding in multimodal llms. Advances in Neural Information Processing Systems, 37:113569–113697, 2024
2024
-
[46]
Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023
-
[47]
Mramg-bench: a comprehensive benchmark for advancing multimodal retrieval-augmented multimodal generation
Qinhan Yu, Zhiyou Xiao, Binghui Li, Zhengren Wang, Chong Chen, and Wentao Zhang. Mramg-bench: a comprehensive benchmark for advancing multimodal retrieval-augmented multimodal generation. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3616–3626, 2025
2025
-
[48]
Visrag: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, et al. Visrag: Vision-based retrieval-augmented generation on multi-modality documents. arXiv preprint arXiv:2410.10594, 2024. 13 CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
-
[49]
Sciegqa: A dataset for scientific evidence-grounded question answering and reasoning, 2026
Wenhan Yu, Zhaoxi Zhang, Wang Chen, Guanqiang Qi, Weikang Li, Lei Sha, Deguo Xia, and Jizhou Huang. Sciegqa: A dataset for scientific evidence-grounded question answering and reasoning, 2026. URL https://arxiv.org/abs/2511.15090
-
[50]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Citalaw: Enhancing llm with citations in legal domain
Kepu Zhang, Weijie Yu, Sunhao Dai, and Jun Xu. Citalaw: Enhancing llm with citations in legal domain. In Findings of the Association for Computational Linguistics: ACL 2025, pages 11183–11196, 2025
2025
-
[52]
Qintong Zhang, Xinjie Lv, Jialong Wu, Baixuan Li, Zhengwei Tao, Guochen Yan, Huanyao Zhang, Bin Wang, Jiahao Xu, Haitao Mi, et al. Docdancer: Towards agentic document-grounded information seeking.arXiv preprint arXiv:2601.05163, 2026
-
[53]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Retrieval-augmented generation for ai-generated content: A survey.Data Science and Engineering, pages 1–29, 2026
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey.Data Science and Engineering, pages 1–29, 2026
2026
-
[55]
FinRAGBench-V: A benchmark for multimodal RAG with visual citation in the financial domain
Suifeng Zhao, Zhuoran Jin, Sujian Li, and Jun Gao. FinRAGBench-V: A benchmark for multimodal RAG with visual citation in the financial domain. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4215–4249, Suzhou, China, Nov...
-
[56]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Dawei Zhu, Rui Meng, Jiefeng Chen, Sujian Li, Tomas Pfister, and Jinsung Yoon. Doclens: A tool-augmented multi-agent framework for long visual document understanding.arXiv preprint arXiv:2511.11552, 2025
-
[58]
Multimodal c4: An open, billion-scale corpus of images interleaved with text
Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, and Yejin Choi. Multimodal C4: An open, billion-scale corpus of images interleaved with text.arXiv preprint arXiv:2304.06939, 2023. 14 CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence Appendi...
-
[59]
**Multi-page**: At least 2 different pages
-
[60]
**Multi-element**: At least 2 element types (e.g., text, table, figure, layout)
-
[61]
- If an element spans multiple pages (e.g., continued table), MUST extract the complete structure from ALL involved pages (e.g., headers from previous page)
**Complete context**: - If including a table/figure, MUST also extract its title, caption, legend, axis labels, footnotes, etc. - If an element spans multiple pages (e.g., continued table), MUST extract the complete structure from ALL involved pages (e.g., headers from previous page). **What to capture**: - **Text**: Key phrases, definitions, scope notes....
-
[62]
Figure",
Search keywords: "Figure", "Table", "Note", "unit", etc
-
[63]
Extract the hit AND all surrounding relevant elements (enforce complete context for tables/figures)
-
[64]
Cross-page link: Connect same metric/entity across different pages
-
[65]
Evidence_package_description
Use screenshots and bounding boxes to confirm type and layout. **Avoid**: - Single-element bundles, ID/page-number dependencies, fragmented tables/figures, broad summaries without clear Q&A target. **Output format**: Return a list of evidence bundles. Generate at least **10** bundles. ```json [{ "Evidence_package_description": "Brief description of purpos...
-
[66]
Complex Synthesis
category: "Complex Synthesis", "Factual Retrieval", "Multimodal Parsing", "Quantitative Reasoning",
-
[67]
template_en/template_cn must be abstract reusable templates, use placeholders like [Entity], [Date], [Metric], [Section], [Method]
-
[68]
example_en/example_cn should be one short concrete question in that sample style
-
[69]
Keep semantic consistency within each sample
-
[70]
Prompt for Annotation Evluation You are an expert evaluator for a VQA benchmark
Must return one item for every sample_id provided. Prompt for Annotation Evluation You are an expert evaluator for a VQA benchmark. Your task is to assess the quality of a given QA pair along three dimensions: **Question Difficulty**, **Answer Quality**, and **Crucial Evidence Quality**. Please follow the scoring criteria below. All scores range from **0 ...
-
[75]
page_number
Pure reasoning/calculation steps do not need`<bbox />`. ## Annotation Format ``` <bbox page="page_number" x1="left" y1="top" x2="right" y2="bottom" /> ``` Page numbers start from 1 (note: ignore original page numbers); coordinates are relative coordinates on the page image, range 0-1000. ## Examples **Question:** What is the net change in the company's pr...
2021
-
[76]
Do not select partial text from a paragraph or a single row from a table, and do not select an entire page or spanning multiple tables/paragraphs
Evidence must be at the **element level**: a complete paragraph, a complete table, a complete image, or a complete note. Do not select partial text from a paragraph or a single row from a table, and do not select an entire page or spanning multiple tables/paragraphs. Note: This is very important and will directly affect your score
-
[77]
For **tables and images**, if there are captions or footnotes, they need to be annotated as **separate evidence** with their own bbox, not merged into the table/image bbox
-
[78]
Each piece of cited evidence text should be followed by a`<bbox />`tag indicating the evidence location
-
[79]
When an inference step relies on multiple pieces of evidence, use multiple`<bbox />` tags separately
-
[80]
document_number
Pure reasoning/calculation steps do not need`<bbox />`. ## Annotation Format ``` <bbox doc="document_number" page="page_number" x1="left" y1="top" x2="right" y2="bottom" /> ``` -`doc`: Document number, starting from 1 (corresponding to`PDF_Source`list order) -`page`: Page number starting from 1 (note: ignore original page numbers) - Coordinates are relati...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.