Recognition: 2 theorem links
· Lean TheoremPyramid Forcing: Head-Aware Pyramid KV Cache Policy for High-Quality Long Video Generation
Pith reviewed 2026-05-14 19:45 UTC · model grok-4.3
The pith
Pyramid Forcing assigns different KV cache lengths to three attention head types to reduce error accumulation in long autoregressive video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
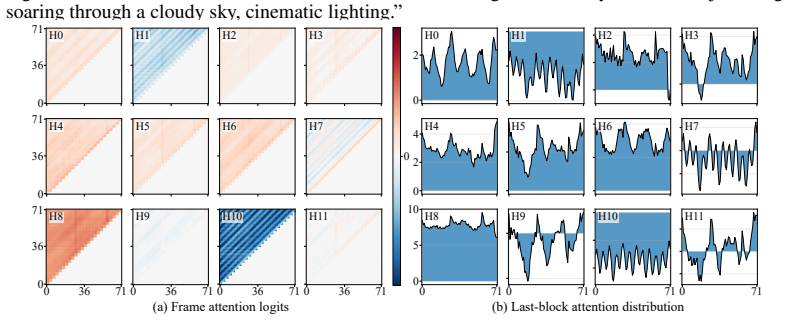
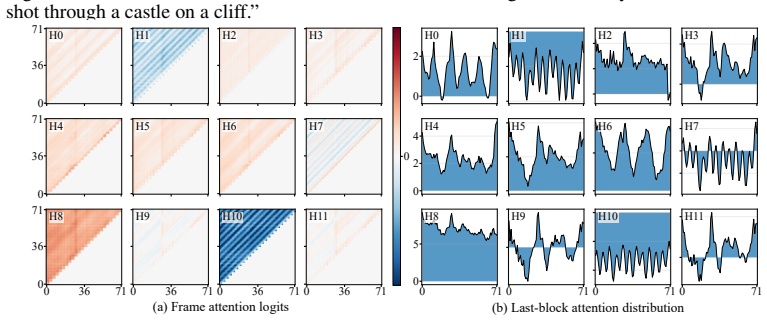
Historical-frame attention analysis reveals three distinct head types—Anchor, Wave, and Veil—and a head-aware pyramidal KVCache policy that matches cache length to each type’s dependency structure measurably reduces long-term degradation in autoregressive video models.
What carries the argument
Pyramid Forcing, the offline head-type classifier combined with type-specific KV cache lengths and ragged-cache attention that supports heterogeneous cache sizes within the same layer.
If this is right
- 60-second Self Forcing quality on VBench-Long rises from 77.87 to 81.21.
- Motion dynamics, visual fidelity, and semantic consistency all improve over long horizons.
- The same gains appear under both Self Forcing and Causal Forcing inference regimes.
- No additional training or online overhead is required once head types are catalogued.
Where Pith is reading between the lines
- The same offline classification step could be reused across multiple video models that share similar transformer backbones.
- Extending the approach to other long-sequence autoregressive domains such as audio or text would test whether analogous head specializations exist.
- Combining Pyramid Forcing with existing sampling or guidance techniques might produce additive quality gains.
Load-bearing premise
The three head types remain stable across models and datasets and can be identified once offline without retraining or added runtime cost.
What would settle it
Replace the identified head-type cache policies with random or uniform assignments on the same model and dataset; if VBench-Long scores stay at or below the 77.87 baseline, the claim is falsified.
Figures


















read the original abstract
Autoregressive video generation enables streaming and open-ended long video synthesis, but still suffers from long-term degradation caused by accumulated errors. Existing KVCache strategies usually apply unified historical-frame retention, implicitly assuming homogeneous historical dependencies across attention heads. We revisit historical-frame attention and reveal three distinct head types: Anchor Heads require broad long-range context, Wave Heads exhibit periodic temporal dependencies, and Veil Heads focus on initial and adjacent frames. Based on this finding, we propose Pyramid Forcing, a head-aware pyramidal KVCache framework that identifies head types offline, assigns behavior-specific cache policies, and supports heterogeneous cache lengths via efficient ragged-cache attention. Experiments on Self Forcing and Causal Forcing show that Pyramid Forcing consistently improves long-horizon generation quality on VBench-Long, increasing the 60-second Self Forcing score from 77.87 to 81.21 while enhancing motion dynamics, visual fidelity, and semantic consistency. Project: https://if-lab-pku.github.io/Pyramid-Forcing/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Pyramid Forcing, a head-aware pyramidal KV cache policy for autoregressive long video generation. It empirically identifies three attention head types (Anchor Heads requiring broad long-range context, Wave Heads with periodic temporal dependencies, and Veil Heads focusing on initial/adjacent frames) from historical-frame attention patterns, assigns type-specific cache policies with heterogeneous lengths, and implements this via efficient ragged-cache attention. Experiments on Self Forcing and Causal Forcing baselines report consistent quality gains on VBench-Long, including raising the 60-second Self Forcing score from 77.87 to 81.21 with improvements in motion dynamics, visual fidelity, and semantic consistency.
Significance. If the head taxonomy proves robust, the method provides a practical, low-overhead way to exploit attention-head heterogeneity for better long-horizon video quality over uniform KV cache retention, with direct relevance to streaming and open-ended synthesis. The reported benchmark lifts are concrete and the ragged-cache mechanism appears efficient, but the absence of cross-model validation limits claims of broad applicability.
major comments (3)
- [Abstract and Method] Abstract and Method: The procedure for offline classification of heads into Anchor, Wave, and Veil types is not specified (no metrics, thresholds, attention-pattern criteria, or pseudocode). This is load-bearing because the central claim and all reported gains rest on the assumption that these categories are stable, reliably identifiable without retraining, and not artifacts of the evaluated model.
- [Experiments] Experiments: The VBench-Long improvements (e.g., 77.87 to 81.21 on 60 s Self Forcing) are presented without statistical significance tests, variance across runs, or ablations that isolate the head-aware policy from the effect of simply using heterogeneous cache lengths via ragged attention. This weakens the attribution of gains to the proposed taxonomy.
- [Experiments] Experiments: No transfer or sensitivity experiments are reported on other backbones, datasets, or sequence lengths to test the stability of the three head types, despite the method's reliance on offline identification being generalizable.
minor comments (2)
- [Abstract] The abstract mentions 'efficient ragged-cache attention' but provides no implementation details or complexity analysis, which would aid reproducibility.
- [Method] Notation for cache policies per head type could be formalized earlier (e.g., with explicit equations for per-type lengths) to clarify the pyramidal structure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. We address each major comment point by point below, outlining specific revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract and Method] Abstract and Method: The procedure for offline classification of heads into Anchor, Wave, and Veil types is not specified (no metrics, thresholds, attention-pattern criteria, or pseudocode). This is load-bearing because the central claim and all reported gains rest on the assumption that these categories are stable, reliably identifiable without retraining, and not artifacts of the evaluated model.
Authors: We agree that the offline classification procedure requires explicit documentation for reproducibility. In the revised manuscript, we will add a dedicated subsection in the Method section describing the classification metrics (temporal attention entropy and periodicity via Fourier analysis of attention scores), the empirical thresholds used to assign heads to Anchor, Wave, and Veil categories, and pseudocode for the full offline procedure. This will clarify that the taxonomy is derived directly from observed attention patterns without any retraining. revision: yes
-
Referee: [Experiments] Experiments: The VBench-Long improvements (e.g., 77.87 to 81.21 on 60 s Self Forcing) are presented without statistical significance tests, variance across runs, or ablations that isolate the head-aware policy from the effect of simply using heterogeneous cache lengths via ragged attention. This weakens the attribution of gains to the proposed taxonomy.
Authors: We acknowledge that stronger statistical support and targeted ablations are needed. In the revision, we will report standard deviations across multiple runs, include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) on the VBench-Long scores, and add an ablation comparing the full head-aware Pyramid Forcing policy against a ragged-attention baseline that uses heterogeneous cache lengths but applies a uniform policy across all heads. This will isolate the contribution of the taxonomy. revision: yes
-
Referee: [Experiments] Experiments: No transfer or sensitivity experiments are reported on other backbones, datasets, or sequence lengths to test the stability of the three head types, despite the method's reliance on offline identification being generalizable.
Authors: Our evaluation focused on the Self Forcing and Causal Forcing baselines to provide a controlled demonstration of the approach. In the revision, we will add sensitivity analysis on varying sequence lengths and discuss observed consistency of head types within the tested models. Comprehensive transfer experiments on additional backbones and datasets are computationally intensive and are identified as future work. revision: partial
Circularity Check
Empirical head classification and external benchmark evaluation keep derivation self-contained
full rationale
The paper identifies three head types (Anchor, Wave, Veil) by revisiting historical-frame attention patterns and presents this taxonomy as an empirical observation rather than a quantity obtained from fitted parameters or self-referential definitions. Pyramid Forcing then assigns distinct KV-cache policies based on these observed types and evaluates the resulting quality lift on the external VBench-Long benchmark (60 s Self Forcing score rising from 77.87 to 81.21). No equations, self-citations, or uniqueness claims reduce any reported prediction to its own inputs by construction; the central improvement is measured against an independent test set and does not rely on renaming known results or smuggling ansatzes via prior work by the same authors.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-head-type cache lengths
axioms (1)
- domain assumption Attention heads exhibit stable, distinguishable temporal dependency patterns that can be identified offline
invented entities (1)
-
Anchor Heads, Wave Heads, Veil Heads
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanforward_accumulates / z_monotone_absolute echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Wave Heads exhibit a small and stable fluctuation period under FFT analysis... P < β where β is determined by theoretical and experimental analysis (period threshold 6.4).
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Offline Tri-Pattern Head Classification... sign-rate statistics and frequency-domain periodicity... HA, HW, HV mutually exclusive.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregres- sive diffusion distillation done right for high-quality real-time interactive video generation.arXiv preprint arXiv:2602.02214, 2026
-
[4]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, pages 4195–4205, 2023
work page 2023
-
[5]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Yume: An interactive world generation model
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
-
[9]
Jianhao Yuan, Xiaofeng Zhang, Felix Friedrich, Nicolas Beltran-Velez, Melissa Hall, Reyhane Askari- Hemmat, Xiaochuang Han, Nicolas Ballas, Michal Drozdzal, and Adriana Romero-Soriano. Inference-time physics alignment of video generative models with latent world models.arXiv preprint arXiv:2601.10553, 2026
-
[10]
Linxi Xie, Lisong C Sun, Ashley Neall, Tong Wu, Shengqu Cai, and Gordon Wetzstein. Generated reality: Human-centric world simulation using interactive video generation with hand and camera control.arXiv preprint arXiv:2602.18422, 2026
-
[11]
Vidarc: Embodied video diffusion model for closed-loop control
Yao Feng, Chendong Xiang, Xinyi Mao, Hengkai Tan, Zuyue Zhang, Shuhe Huang, Kaiwen Zheng, Haitian Liu, Hang Su, and Jun Zhu. Vidarc: Embodied video diffusion model for closed-loop control. arXiv preprint arXiv:2512.17661, 2025
-
[12]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Self-forcing++: Towards minute-scale high-quality video generation.ICLR, 2025
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.ICLR, 2025
work page 2025
-
[14]
Longlive: Real-time interactive long video generation.ICLR, 2025
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.ICLR, 2025
work page 2025
-
[15]
Rolling forcing: Autoregressive long video diffusion in real time.ICLR, 2025
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.ICLR, 2025
work page 2025
-
[16]
Haodong Li, Shaoteng Liu, Zhe Lin, and Manmohan Chandraker. Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion.arXiv preprint arXiv:2602.07775, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Youngrae Kim, Qixin Hu, C-C Jay Kuo, and Peter A Beerel. Memrope: Training-free infinite video generation via evolving memory tokens.arXiv preprint arXiv:2603.12513, 2026
-
[18]
arXiv preprint arXiv:2512.05081 (2025)
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forc- ing: Training-free long video generation with deep sink and participative compression.arXiv preprint arXiv:2512.05081, 2025. 11
-
[19]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self-rollout.arXiv preprint arXiv:2511.20649, 2025
-
[20]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.NeurIPS, 35:16344–16359, 2022
work page 2022
-
[21]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InCVPR, pages 21807–21818, 2024
work page 2024
-
[23]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[24]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InCVPR, pages 22963–22974, 2025
work page 2025
-
[25]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. Flashinfer: Efficient and customizable attention engine for llm inference serving.Proceedings of Machine Learning and Systems, 7, 2025
work page 2025
-
[26]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. NeurIPS, 37:22947–22970, 2024
work page 2024
-
[27]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
work page 2023
-
[28]
Efficient streaming language models with attention sinks.ICLR, 20234
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.ICLR, 20234
-
[29]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 155–172, 2024
work page 2024
-
[30]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
arXiv preprint arXiv:2407.11550 , year =
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference.arXiv preprint arXiv:2407.11550, 2024
-
[32]
Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference
Dongjie Yang, XiaoDong Han, Yan Gao, Yao Hu, Shilin Zhang, and Hai Zhao. Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference. InACL, pages 3258–3270, 2024
work page 2024
-
[33]
Qaq: Quality adaptive quantization for llm kv cache
Wen Cheng, Shichen Dong, Jiayu Qin, and Wei Wang. Qaq: Quality adaptive quantization for llm kv cache. InICCV, pages 2542–2550, 2025
work page 2025
-
[34]
Compressed context memory for online language model interaction.ICLR, 2023
Jang-Hyun Kim, Junyoung Yeom, Sangdoo Yun, and Hyun Oh Song. Compressed context memory for online language model interaction.ICLR, 2023
work page 2023
-
[35]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache.ICML, 2024
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.ICML, 2024
work page 2024
-
[36]
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, and Bohan Zhuang. Minicache: Kv cache compression in depth dimension for large language models.NeurIPS, 37:139997–140031, 2024
work page 2024
-
[37]
A majestic eagle soaring through a cloudy sky, cinematic lighting
Harry Dong, Xinyu Yang, Zhenyu Zhang, Zhangyang Wang, Yuejie Chi, and Beidi Chen. Get more with less: Synthesizing recurrence with kv cache compression for efficient llm inference.ICML, 2024. 12 A Additional Visualizations and Experimental Results. A.1 Additional Evaluation Metrics of the Main Experiment Table 6 reports the remaining VBench-Long metrics f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.