Recognition: no theorem link
Backdoor Channels Hidden in Latent Space: Cryptographic Undetectability in Modern Neural Networks
Pith reviewed 2026-05-14 18:33 UTC · model grok-4.3
The pith
Neural networks can hide backdoors as statistically indistinguishable latent directions, reducing detection to an intractable hypothesis test on model parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that backdoor channels can be constructed as learned latent directions within the geometry of modern neural networks such that no efficient test can separate the backdoored parameter distribution from the clean one; the authors therefore conjecture that practical undetectability follows directly from the intractability of this hypothesis test, enabling high-success attacks on ResNet and Vision Transformer architectures that survive existing defenses.
What carries the argument
Backdoor channels realized as learned latent directions in the network's latent space, which the attack exploits without adding detectable foreign structure.
If this is right
- Attacks achieve consistently high success rates on ResNet and Vision Transformer models trained on standard image classification datasets.
- Clean accuracy degradation remains negligible while the backdoor persists.
- A comprehensive suite of post-training defenses fails to neutralise the backdoor without rendering the model unusable.
- Undetectability holds because the chosen latent directions are statistically indistinguishable from directions arising in normal training.
Where Pith is reading between the lines
- Detection methods will need to move beyond parameter-distribution tests and examine the geometry of representations more directly.
- Training procedures themselves may require new constraints to prevent the emergence of exploitable latent directions.
- Similar latent-space exploitation could apply to other model compromise scenarios such as poisoning or extraction attacks.
- A practical test would be to run targeted latent-direction probes on larger-scale models and measure whether any efficient distinguisher appears.
Load-bearing premise
The hypothesis test that would separate the parameter distribution of a backdoored model from that of a clean model is intractable for state-of-the-art networks.
What would settle it
Discovery of an efficient algorithm that distinguishes the parameter distribution of a backdoored model from a clean model with non-negligible advantage would falsify the undetectability claim.
Figures



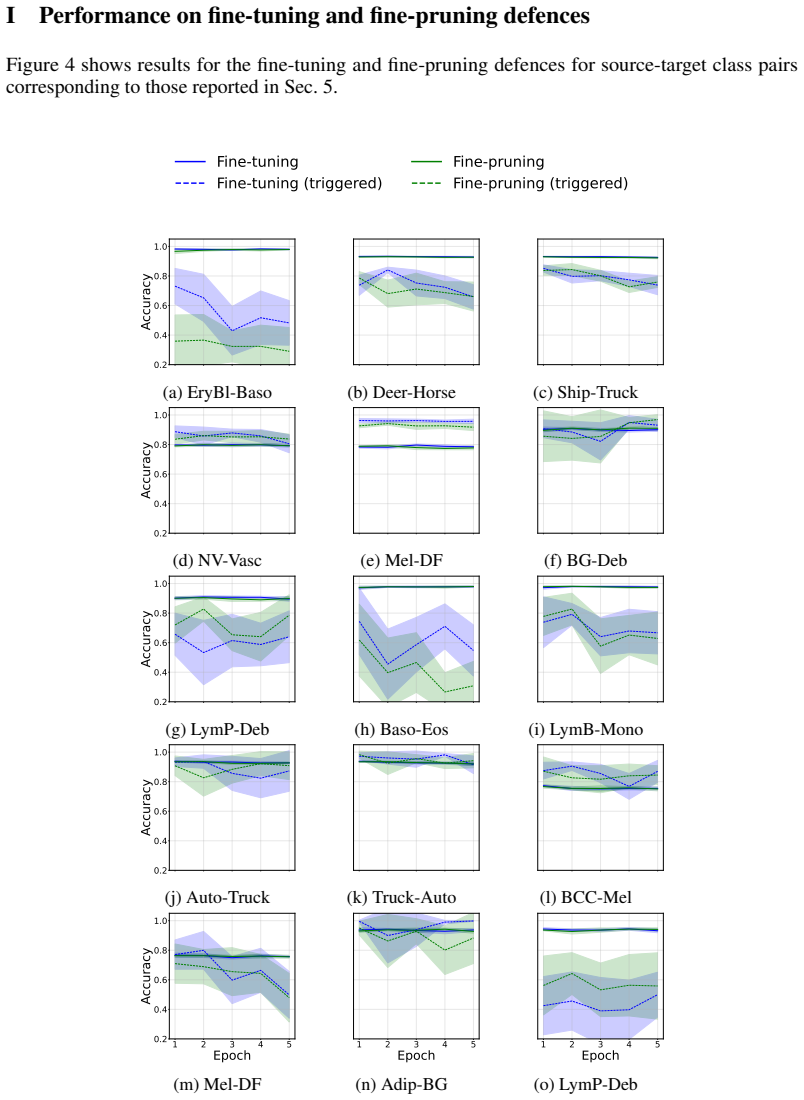


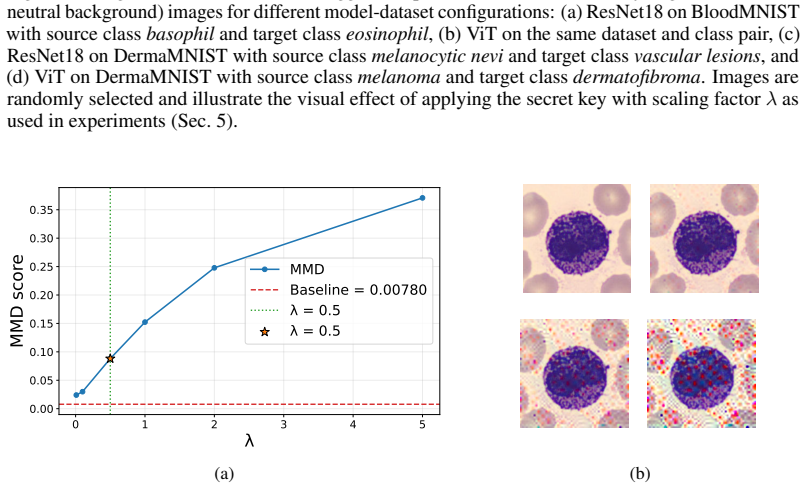
read the original abstract
Recent cryptographic results establish that neural networks can be backdoored such that no efficient algorithm can distinguish them from a clean model. These guarantees, however, have been confined to stylised architectures of limited practical relevance, leaving open whether comparable undetectability extends to modern, end-to-end trained networks. We construct such an attack mechanism for state-of-the-art architectures, closely aligned to the cryptographic notion of undetectability, by identifying backdoor channels as learned latent directions, and show that the question of undetectability reduces to a hypothesis test between two unknown distributions over model parameters, which we conjecture to be intractable in practice. The consequence of this reframing is significant: if exploitable channels within a network's latent space are statistically indistinguishable from naturally learned directions, an attacker need not introduce foreign structure but can instead exploit the geometry the network already possesses. Demonstrating the approach on ResNet and Vision Transformer architectures trained on standard image classification datasets, the attack achieves both consistently high success rates with negligible clean accuracy degradation, and resists a comprehensive suite of post-training defences, none of which neutralise the backdoor without rendering the model unusable. Our results establish that cryptographic backdoors need not be artefacts requiring exotic architectures or artificial constructions, but identifiable as latent properties inherent to the geometry of learned representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a backdoor attack for state-of-the-art neural networks (ResNet and ViT) on image classification tasks by identifying backdoor channels as latent directions in the model's representation space. It argues that cryptographic undetectability can be achieved if the parameter distributions of clean and backdoored models are computationally indistinguishable, conjecturing that the corresponding hypothesis test is intractable for practical model sizes. The approach is demonstrated empirically with high attack success rates, negligible clean accuracy loss, and resistance to a suite of post-training defenses.
Significance. If the central conjecture on the intractability of the hypothesis test holds, the work is significant as it extends cryptographic undetectability results from stylized architectures to modern, end-to-end trained networks. By reframing the problem around exploiting existing latent geometry rather than introducing foreign structure, it provides a new perspective on backdoor attacks. The empirical evaluations on standard datasets offer practical evidence of the attack's effectiveness and stealth against existing defenses, potentially impacting the design of future detection mechanisms in machine learning security.
major comments (2)
- [Abstract and theoretical framing] Abstract and central theoretical framing: The undetectability claim reduces to the conjecture that the hypothesis test between clean and backdoored parameter distributions is computationally intractable for practical model sizes. No formal reduction to a known hardness assumption, no bound on statistical distance, and no advantage analysis for any class of distinguishers is supplied, making this conjecture load-bearing for the claim that the attack exploits naturally occurring geometry without introducing detectable foreign structure.
- [Empirical evaluation] Empirical evaluation: Resistance is shown only against the listed post-training defenses; the manuscript does not evaluate whether other potential distinguishers (e.g., meta-classifiers on weight statistics, activation covariances, or learned detectors) could succeed, leaving open whether the empirical undetectability generalizes beyond the tested suite.
minor comments (1)
- The definition of 'backdoor channel as latent direction' would benefit from an explicit mathematical formulation (e.g., in terms of activation subspaces or weight perturbations) at the first point of introduction to improve precision.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment point by point below, offering clarifications and proposing targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and theoretical framing] Abstract and central theoretical framing: The undetectability claim reduces to the conjecture that the hypothesis test between clean and backdoored parameter distributions is computationally intractable for practical model sizes. No formal reduction to a known hardness assumption, no bound on statistical distance, and no advantage analysis for any class of distinguishers is supplied, making this conjecture load-bearing for the claim that the attack exploits naturally occurring geometry without introducing detectable foreign structure.
Authors: We acknowledge that the central undetectability claim rests on the conjecture that distinguishing the parameter distributions of clean and backdoored models is computationally intractable for practical sizes. The manuscript does not supply a formal reduction to a known hardness assumption, statistical distance bounds, or advantage analysis for specific distinguisher classes, as these remain open theoretical questions. Our contribution instead lies in reframing backdoors as latent directions that align with naturally learned geometry, supported by empirical results showing resistance to tested distinguishers. We will revise the abstract and theoretical sections to state the conjecture more explicitly, discuss its load-bearing role, and note the absence of a formal proof while emphasizing the practical implications of the empirical findings. revision: partial
-
Referee: [Empirical evaluation] Empirical evaluation: Resistance is shown only against the listed post-training defenses; the manuscript does not evaluate whether other potential distinguishers (e.g., meta-classifiers on weight statistics, activation covariances, or learned detectors) could succeed, leaving open whether the empirical undetectability generalizes beyond the tested suite.
Authors: We evaluated the attack against the comprehensive suite of post-training defenses detailed in the manuscript, demonstrating consistent resistance without degrading clean accuracy. While exhaustive evaluation against all conceivable distinguishers (such as meta-classifiers on weight statistics or activation covariances) is not feasible within a single study, the attack's design exploits existing latent geometry rather than introducing statistical anomalies that many such detectors rely upon. We will add a discussion subsection addressing potential additional distinguishers, explaining why they are unlikely to succeed based on the attack mechanism and our empirical observations. revision: partial
- A formal reduction of the parameter-distribution hypothesis test to a known cryptographic hardness assumption, including bounds on statistical distance or distinguisher advantage.
Circularity Check
No significant circularity; undetectability reframed as conjecture on hypothesis-test hardness without self-referential reduction
full rationale
The paper's core move is to identify backdoor channels with existing latent directions and then state that undetectability reduces to the computational hardness of distinguishing the induced parameter distributions, which is conjectured to hold for modern networks. This is an explicit assumption rather than a derivation that collapses back onto the construction by definition or by fitting. No equations are shown that equate a fitted quantity to a claimed prediction, no self-citation chain is invoked to justify uniqueness, and the empirical resistance to defenses is presented as supporting evidence rather than the sole justification. The derivation therefore remains self-contained: the attack construction and the conjecture are logically separate, with the latter serving as an open limitation rather than a hidden tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper The hypothesis test between clean and backdoored parameter distributions is computationally intractable for practical model sizes
invented entities (1)
-
backdoor channel as latent direction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bilal Hussain Abbasi, Yanjun Zhang, Leo Zhang, and Shang Gao. Backdoor attacks and defenses in computer vision domain: A survey.arXiv preprint arXiv:2509.07504, 2025
-
[2]
Complexity theoretic lower bounds for sparse principal component detection
Quentin Berthet and Philippe Rigollet. Complexity theoretic lower bounds for sparse principal component detection. In Shai Shalev-Shwartz and Ingo Steinwart, editors,COLT 2013 - The 26th Annual Conference on Learning Theory, June 12-14, 2013, Princeton University, NJ, USA, JMLR Workshop and Conference Proceedings, pages 1046–1066. JMLR.org, 2013. URL http...
work page 2013
-
[3]
Computational Lower Bounds for Sparse PCA
Quentin Berthet and Philippe Rigollet. Computational lower bounds for sparse pca.arXiv preprint arXiv:1304.0828, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Matthew S. Brennan and Guy Bresler. Optimal average-case reductions to sparse PCA: from weak assumptions to strong hardness. In Alina Beygelzimer and Daniel Hsu, editors,Conference on Learning Theory, COLT 2019, 25-28 June 2019, Phoenix, AZ, USA, Proceedings of Machine Learning Research, pages 469–470. PMLR, 2019. URL http://proceedings.mlr.press/ v99/bre...
work page 2019
-
[5]
Data free backdoor attacks.Advances in Neural Information Processing Systems, 37:23881–23911, 2024
Bochuan Cao, Jinyuan Jia, Chuxuan Hu, Wenbo Guo, Zhen Xiang, Jinghui Chen, Bo Li, and Dawn Song. Data free backdoor attacks.Advances in Neural Information Processing Systems, 37:23881–23911, 2024
work page 2024
-
[6]
Wild patterns reloaded: A survey of machine learning security against training data poisoning
Antonio Emanuele Cinà, Kathrin Grosse, Ambra Demontis, Sebastiano Vascon, Werner Zellinger, Bernhard A Moser, Alina Oprea, Battista Biggio, Marcello Pelillo, and Fabio Roli. Wild patterns reloaded: A survey of machine learning security against training data poisoning. ACM Computing Surveys, 55(13s):1–39, 2023
work page 2023
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
Unelicitable backdoors via cryptographic transformer circuits
Andis Draguns, Andrew Gritsevskiy, Sumeet Ramesh Motwani, and Christian Schroeder de Witt. Unelicitable backdoors via cryptographic transformer circuits. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 53684–53709. Curran Associates, Inc., 202...
-
[9]
Kim, Vinod Vaikuntanathan, and Or Zamir
Shafi Goldwasser, Michael P. Kim, Vinod Vaikuntanathan, and Or Zamir. Planting undetectable backdoors in machine learning models : [extended abstract]. In2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), pages 931–942, 2022. doi: 10.1109/ FOCS54457.2022.00092
-
[10]
Kim, Vinod Vaikuntanathan, and Or Zamir
Shafi Goldwasser, Michael P. Kim, Vinod Vaikuntanathan, and Or Zamir. Planting undetectable backdoors in machine learning models, 2024. URL https://arxiv.org/abs/2204.06974
-
[11]
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.Journal of Machine Learning Research, 13(25):723–773,
-
[12]
URLhttp://jmlr.org/papers/v13/gretton12a.html
-
[13]
Ioannis Grigoriadis, Eleni Vrochidou, Iliana Tsiatsiou, and George A. Papakostas. Machine learning as a service (mlaas)—an enterprise perspective. In Mukesh Saraswat, Chandreyee Chowdhury, Chintan Kumar Mandal, and Amir H. Gandomi, editors,Proceedings of Interna- tional Conference on Data Science and Applications, pages 261–273, Singapore, 2023. Springer ...
work page 2023
-
[14]
Patrik Hammersborg and Inga Strümke. Concept backpropagation: An explainable ai approach for visualising learned concepts in neural network models.arXiv preprint arXiv:2307.12601, 2023. 10
-
[15]
Muhammad Abdullah Hanif, Nandish Chattopadhyay, Bassem Ouni, and Muhammad Shafique. Survey on backdoor attacks on deep learning: Current trends, categorization, applications, research challenges, and future prospects.IEEE Access, 2025
work page 2025
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[17]
Sanghyun Hong, Nicholas Carlini, and Alexey Kurakin. Handcrafted backdoors in deep neural networks.Advances in Neural Information Processing Systems, 35:8068–8080, 2022
work page 2022
-
[18]
Alkis Kalavasis, Amin Karbasi, Argyris Oikonomou, Katerina Sotiraki, Grigoris Velegkas, and Manolis Zampetakis. Injecting undetectable backdoors in obfuscated neural networks and language models.Advances in Neural Information Processing Systems, 37:21537–21571, 2024
work page 2024
-
[19]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on machine learning, pages 2668–2677. PMLR, 2018
work page 2018
-
[20]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[22]
Analyzing and editing inner mechanisms of backdoored language models
Max Lamparth and Anka Reuel. Analyzing and editing inner mechanisms of backdoored language models. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2362–2373, 2024
work page 2024
-
[23]
Fine-pruning: Defending against backdooring attacks on deep neural networks
Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Fine-pruning: Defending against backdooring attacks on deep neural networks. InInternational symposium on research in attacks, intrusions, and defenses, pages 273–294. Springer, 2018
work page 2018
-
[24]
Charles H Martin and Michael W Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165):1–73, 2021
work page 2021
-
[25]
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines.Advances in neural information processing systems, 20, 2007
work page 2007
-
[26]
Mauro Ribeiro, Katarina Grolinger, and Miriam A.M. Capretz. Mlaas: Machine learning as a service. In2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), pages 896–902, 2015. doi: 10.1109/ICMLA.2015.152
-
[27]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
Levent Sagun, Leon Bottou, and Yann LeCun. Eigenvalues of the hessian in deep learning: Singularity and beyond.arXiv preprint arXiv:1611.07476, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Levent Sagun, Utku Evci, V Ugur Guney, Yann Dauphin, and Leon Bottou. Empirical analysis of the hessian of over-parametrized neural networks.arXiv preprint arXiv:1706.04454, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Empirical analysis of the hessian of over-parametrized neural networks
Levent Sagun, Utku Evci, V Ugur Guney, Yann Dauphin, and Leon Bottou. Empirical analysis of the hessian of over-parametrized neural networks. InICLR 2018 Workshop, 2018. URL https://iclr.cc/virtual/2018/workshop/563
work page 2018
-
[30]
Neural cleanse: Identifying and mitigating backdoor attacks in neural networks
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In2019 IEEE symposium on security and privacy (SP), pages 707–723. IEEE, 2019
work page 2019
-
[31]
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific data, 10(1):41, 2023. 11 A Visualisation of spiked covariance Figure 3 illustrates the difference between clean and backdoored distributions, hig...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.