Recognition: no theorem link
RS-Claw: Progressive Active Tool Exploration via Hierarchical Skill Trees for Remote Sensing Agents
Pith reviewed 2026-05-14 19:29 UTC · model grok-4.3
The pith
RS-Claw lets remote sensing agents actively explore tools via hierarchical skill trees, achieving up to 86% token compression while outperforming flat and RAG baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RS-Claw redefines tool selection as active exploration in the tool space. By leveraging skill encapsulation to hierarchically structure tool descriptions, the agent executes on-demand sequential decision-making: first selecting relevant skill branches by reading only summaries, then dynamically loading detailed descriptions, and finally achieving precise invocation. This active paradigm liberates context space and ensures accurate hit rates of critical tools during long-horizon reasoning.
What carries the argument
Hierarchical skill trees constructed through skill encapsulation at the tool end, enabling progressive on-demand tool loading from summaries to details.
If this is right
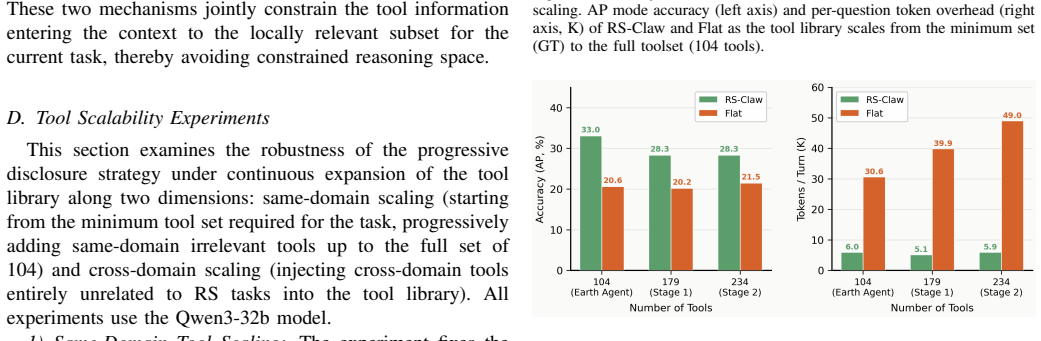
- RS-Claw achieves input token compression ratios of up to 86% by filtering irrelevant tool information.
- It comprehensively outperforms existing Flat and RAG baselines on complex reasoning evaluations in the Earth-Bench benchmark.
- The active exploration mechanism effectively filters semantic noise and frees up the agent's reasoning space.
- Agents can maintain high tool hit rates without omissions in long-horizon tasks within massive RS tool ecosystems.
Where Pith is reading between the lines
- This approach may scale to other domains with large numbers of heterogeneous tools, such as general AI agents or robotics.
- Future work could test whether the hierarchical structure reduces errors in real-time remote sensing applications like disaster response.
- Integrating this with other agent frameworks might allow dynamic tree updates based on new tools.
Load-bearing premise
That the hierarchical skill trees can be structured such that summary-level selections reliably guide the agent to the exact critical tools needed without omissions in sequential decisions.
What would settle it
Observing whether RS-Claw misses critical tools more often than RAG methods in long-horizon tasks on Earth-Bench or fails to achieve the reported token compression would falsify the central claim.
Figures



read the original abstract
The rise of multi-modal large language models (MLLMs) is shifting remote sensing (RS) intelligence from "see" to "action", as OpenClaw-style frameworks enable agents to autonomously operate massive RS image-processing tools for complex tasks. Existing RS agents adopt a passive selection paradigm for tool invocation, relying on either full tool registration (Flat) or retrieval-augmented generation (RAG). However, in the massive and multi-source heterogeneous RS tool ecosystem, such passive mechanisms struggle to dynamically balance "context load" and "toolset completeness" throughout task reasoning, thus exhibiting inherent limitations: full tool registration triggers context space deficits during long-horizon tasks, whereas RAG retrieval may omit critical tools in essential steps. To overcome these bottlenecks, this paper redefines tool selection by arguing that the agent should act as an active explorer within the tool space. Based on this perspective, we propose RS-Claw, a novel RS agent architecture. By leveraging Skill encapsulation technology at the tool end, this architecture hierarchically structures tool descriptions, enabling the agent to execute on-demand sequential decision-making: initially selecting relevant skill branches by reading only tool summaries, then dynamically loading detailed descriptions, and ultimately achieving precise invocation. This active paradigm not only significantly liberates the agent's context space but also effectively ensures the accurate hit rate of critical tools during long-horizon reasoning. Systematic experiments on the Earth-Bench benchmark demonstrate that RS-Claw's active exploration mechanism effectively filters semantic noise and substantially frees up reasoning space, achieving an input token compression ratio of up to 86%, and comprehensively outperforming existing Flat and RAG baselines across complex reasoning evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RS-Claw, by using hierarchical skill trees and skill encapsulation, enables remote sensing agents to perform active tool exploration: selecting branches from summaries then loading details on demand. This results in up to 86% input token compression and outperforms Flat and RAG baselines on complex reasoning tasks in the Earth-Bench benchmark.
Significance. Should the results be substantiated with detailed experiments, this work could have high significance for developing efficient agents in tool-heavy domains like remote sensing, where context management is critical for long-horizon tasks. It introduces a promising active paradigm that may reduce semantic noise and improve reasoning space.
major comments (3)
- [Abstract] The abstract asserts substantial outperformance and an 86% compression ratio on Earth-Bench but provides no quantitative metrics, error bars, ablation details, or experimental protocol, rendering the central performance claim unassessable.
- [Architecture Description] The hierarchical skill tree mechanism is presented as ensuring accurate tool hit rates without omissions, yet no details are given on the initial branch selection policy, decision criteria, or error-recovery strategies, leaving the single-point-of-failure risk unaddressed for long-horizon tasks in heterogeneous tool ecosystems.
- [Experiments] There is no reported measurement of omission rates or tool invocation accuracy on Earth-Bench long-horizon cases to support the claim that the active exploration avoids the omissions seen in RAG baselines.
minor comments (1)
- The term 'Skill encapsulation technology' is introduced without a clear definition or reference to prior work.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's clarity and substantiation without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts substantial outperformance and an 86% compression ratio on Earth-Bench but provides no quantitative metrics, error bars, ablation details, or experimental protocol, rendering the central performance claim unassessable.
Authors: We agree that the abstract would benefit from additional quantitative anchors to improve assessability. In the revised manuscript we will expand the abstract to report the mean token compression ratio with standard deviation across Earth-Bench tasks, the average performance margin versus the strongest baseline, and a concise statement of the evaluation protocol (number of tasks, horizon lengths, and model backbone). Space constraints will limit the level of detail, but the added figures will directly support the headline claims. revision: yes
-
Referee: [Architecture Description] The hierarchical skill tree mechanism is presented as ensuring accurate tool hit rates without omissions, yet no details are given on the initial branch selection policy, decision criteria, or error-recovery strategies, leaving the single-point-of-failure risk unaddressed for long-horizon tasks in heterogeneous tool ecosystems.
Authors: We acknowledge that the current description is high-level and omits operational specifics. The revised architecture section will explicitly define: (i) the branch-selection policy (LLM-driven relevance scoring of summaries against the current reasoning state with a tunable threshold), (ii) the decision criteria (contextual utility, recency, and estimated token cost), and (iii) error-recovery mechanisms (progressive fallback to sibling branches, re-query with expanded context, or full-detail load on detected uncertainty). These additions will directly address the single-point-of-failure concern for long-horizon heterogeneous settings. revision: yes
-
Referee: [Experiments] There is no reported measurement of omission rates or tool invocation accuracy on Earth-Bench long-horizon cases to support the claim that the active exploration avoids the omissions seen in RAG baselines.
Authors: We accept that omission-rate and invocation-accuracy metrics were not reported. We will add a dedicated analysis subsection (and accompanying table) that measures tool-omission frequency and invocation precision on the long-horizon subset of Earth-Bench, with direct head-to-head comparison against the RAG baseline. These new results will be generated from the same experimental runs already described and will be presented with error bars. revision: yes
Circularity Check
No circularity: architecture and gains are externally benchmarked
full rationale
The paper presents RS-Claw as a new hierarchical skill-tree architecture for active tool exploration. Claims of up to 86% token compression and outperformance on Earth-Bench are supported solely by direct empirical comparisons against Flat and RAG baselines, with no equations, fitted parameters, or self-citations that reduce the mechanism to its own inputs by construction. The central design choice (on-demand branch loading from summaries) is described as an independent proposal rather than derived from prior self-referential results or uniqueness theorems. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing passive tool selection mechanisms (full registration or RAG) inherently struggle to balance context load and toolset completeness in massive heterogeneous RS tool ecosystems.
invented entities (2)
-
Skill encapsulation technology
no independent evidence
-
Hierarchical Skill Trees
no independent evidence
Reference graph
Works this paper leans on
-
[1]
L. Wang, W. Xu, Y . Lan, Z. Hu, Y . Lan, R. K.-W. Lee, and E.-P. Lim, “Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,”arXiv preprint arXiv:2305.04091, 2023. 20
-
[2]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in Neural Infor- mation Processing Systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[3]
HuggingGPT: Solving AI tasks with ChatGPT and its friends in Hugging Face,
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang, “HuggingGPT: Solving AI tasks with ChatGPT and its friends in Hugging Face,”Ad- vances in Neural Information Processing Systems, vol. 36, pp. 38 154– 38 180, 2023
2023
-
[4]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Linet al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[5]
OpenClaw: Open-source personal AI assistant,
OpenClaw, “OpenClaw: Open-source personal AI assistant,” https: //github.com/openclaw/openclaw, 2026, version 2026.3.8, Accessed: 2026-03-09
2026
-
[6]
RS-Agent: Automating remote sensing tasks through intelligent agent,
W. Xu, Z. Yu, B. Mu, Z. Wei, Y . Zhang, G. Li, J. Wang, and M. Peng, “RS-Agent: Automating remote sensing tasks through intelligent agent,” arXiv preprint arXiv:2406.07089, 2024
-
[7]
Earth-agent: Unlocking the full landscape of earth observation with agents,
P. Feng, Z. Lv, J. Ye, X. Wang, X. Huo, J. Yu, W. Xu, W. Zhang, L. Bai, C. Heet al., “Earth-Agent: Unlocking the full landscape of earth observation with agents,”arXiv preprint arXiv:2509.23141, 2025
-
[8]
Big data for remote sensing: Challenges and opportunities,
M. Chi, A. Plaza, J. A. Benediktsson, Z. Sun, J. Shen, and Y . Zhu, “Big data for remote sensing: Challenges and opportunities,”Proceedings of the IEEE, vol. 104, no. 11, pp. 2207–2219, 2016
2016
-
[9]
Google earth engine: Planetary-scale geospatial analysis for everyone,
N. Gorelick, M. Hancher, M. Dixon, S. Ilyushchenko, D. Thau, and R. Moore, “Google earth engine: Planetary-scale geospatial analysis for everyone,”Remote sensing of Environment, vol. 202, pp. 18–27, 2017
2017
-
[10]
Orfeo toolbox: open source processing of remote sensing images,
M. Grizonnet, J. Michel, V . Poughon, J. Inglada, M. Savinaud, and R. Cresson, “Orfeo toolbox: open source processing of remote sensing images,”Open Geospatial Data, Software and Standards, vol. 2, no. 1, p. 15, 2017
2017
-
[11]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qianet al., “ToolLLM: Facilitating large language models to master 16000+ real-world APIs,”arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Benchmarking single agent performance,
LangChain Team, “Benchmarking single agent performance,” LangChain Blog. [Online]. Available: https://blog.langchain.com/ react-agent-benchmarking/, Feb. 2025, [Accessed: Apr. 24, 2026]
2025
-
[13]
Longbench: A bilingual, multitask benchmark for long context understanding,
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Houet al., “Longbench: A bilingual, multitask benchmark for long context understanding,” inProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), 2024, pp. 3119–3137
2024
-
[14]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProc. 11th Int. Conf. Learn. Represent. (ICLR), 2023
2023
-
[15]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024
2024
-
[16]
Gorilla: Large language model connected with massive APIs,
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive APIs,”Advances in Neural Information Processing Systems, vol. 37, pp. 126 544–126 565, 2024
2024
-
[17]
Retrieval- augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-T. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive NLP tasks,”Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
2020
-
[18]
ToolReAGt: Tool retrieval for LLM-based complex task solution via retrieval augmented generation,
N. Braunschweiler, R. Doddipatla, and T.-C. Zorila, “ToolReAGt: Tool retrieval for LLM-based complex task solution via retrieval augmented generation,” inProc. 3rd Workshop Towards Knowledgeable Foundation Models (KnowFM), 2025, pp. 75–83
2025
-
[19]
Agent skills overview – Claude platform documentation,
Anthropic, “Agent skills overview – Claude platform documentation,” [Online]. Available: https://platform.claude.com/docs/en/ agents-and-tools/agent-skills/overview, 2026
2026
-
[20]
Reflex- ion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflex- ion: Language agents with verbal reinforcement learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 8634–8652, 2023
2023
-
[21]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,”Advances in neural information processing systems, vol. 36, pp. 11 809–11 822, 2023
2023
-
[22]
RSGPT: A remote sensing vision language model and benchmark,
Y . Hu, J. Yuan, C. Wen, X. Lu, Y . Liu, and X. Li, “RSGPT: A remote sensing vision language model and benchmark,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 224, pp. 272–286, 2025
2025
-
[23]
GeoChat: Grounded large vision-language model for remote sensing,
K. Kuckreja, M. S. Danish, M. Naseer, A. Das, S. Khan, and F. S. Khan, “GeoChat: Grounded large vision-language model for remote sensing,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 27 831–27 840
2024
-
[24]
EarthGPT: A universal multimodal large language model for multisensor image comprehension in remote sensing domain,
W. Zhang, M. Cai, T. Zhang, Y . Zhuang, and X. Mao, “EarthGPT: A universal multimodal large language model for multisensor image comprehension in remote sensing domain,”IEEE Transactions on Geo- science and Remote Sensing, vol. 62, pp. 1–20, 2024
2024
-
[25]
EarthDial: Turning multi-sensory earth observations to interactive dialogues,
S. Soni, A. Dudhane, H. Debary, M. Fiaz, M. A. Munir, M. S. Danish, P. Fraccaro, C. D. Watson, L. Klein, F. S. Khanet al., “EarthDial: Turning multi-sensory earth observations to interactive dialogues,” in Proc. Comput. Vis. Pattern Recognit. Conf. (CVPR), 2025, pp. 14 303– 14 313
2025
-
[26]
Remoteclip: A vision language foundation model for remote sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “Remoteclip: A vision language foundation model for remote sensing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1– 16, 2024
2024
-
[27]
Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,
X. Guo, J. Lao, B. Dang, Y . Zhang, L. Yu, L. Ru, L. Zhong, Z. Huang, K. Wu, D. Huet al., “Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 672–27 683
2024
-
[28]
Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,
C. Liu, K. Chen, H. Zhang, Z. Qi, Z. Zou, and Z. Shi, “Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024
2024
-
[29]
Multi-agent geospatial copilots for remote sensing workflows,
C. Lee, V . Paramanayakam, A. Karatzas, Y . Jian, M. Fore, H. Liao, F. Yu, R. Li, I. Anagnostopoulos, and D. Stamoulis, “Multi-agent geospatial copilots for remote sensing workflows,” inProc. IGARSS 2025, 2025, pp. 1084–1089
2025
-
[30]
Evaluating tool-augmented agents in remote sensing platforms,
S. Singh, M. Fore, and D. Stamoulis, “Evaluating tool-augmented agents in remote sensing platforms,”arXiv preprint arXiv:2405.00709, 2024
-
[31]
ThinkGeo: Evaluating tool-augmented agents for remote sensing tasks,
A. Shabbir, M. A. Munir, A. Dudhane, M. U. Sheikh, M. H. Khan, P. Fraccaro, J. B. Moreno, F. S. Khan, and S. Khan, “ThinkGeo: Evaluating tool-augmented agents for remote sensing tasks,”arXiv preprint arXiv:2505.23752, 2025
-
[32]
Tool learning with large language models: A survey,
C. Qu, S. Dai, X. Wei, H. Cai, S. Wang, D. Yin, J. Xu, and J.-R. Wen, “Tool learning with large language models: A survey,”Frontiers of Computer Science, vol. 19, no. 8, p. 198343, 2025
2025
-
[33]
AgentBench: Evaluating LLMs as Agents
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yanget al., “Agentbench: Evaluating llms as agents,”arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Api-bank: A comprehensive benchmark for tool-augmented llms,
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y . Li, “Api-bank: A comprehensive benchmark for tool-augmented llms,” in Proceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 3102–3116
2023
-
[35]
J. Li, W. Zhao, J. Zhao, W. Zeng, H. Wu, X. Wang, R. Ge, Y . Cao, Y . Huang, W. Liuet al., “The tool decathlon: Benchmarking language agents for diverse, realistic, and long-horizon task execution,”arXiv preprint arXiv:2510.25726, 2025
-
[36]
Taskmatrix. ai: Completing tasks by connecting foundation models with millions of apis,
Y . Liang, C. Wu, T. Song, W. Wu, Y . Xia, Y . Liu, Y . Ou, S. Lu, L. Ji, S. Maoet al., “Taskmatrix. ai: Completing tasks by connecting foundation models with millions of apis,”Intelligent Computing, vol. 3, p. 0063, 2024
2024
-
[37]
AnyTool: Self-reflective, hierarchical agents for large-scale API calls,
Y . Du, F. Wei, and H. Zhang, “AnyTool: Self-reflective, hierarchical agents for large-scale API calls,”arXiv preprint arXiv:2402.04253, 2024
-
[38]
Re-invoke: Tool invocation rewriting for zero- shot tool retrieval,
Y . Chen, J. Yoon, D. S. Sachan, Q. Wang, V . Cohen-Addad, M. Bateni, C.-Y . Lee, and T. Pfister, “Re-invoke: Tool invocation rewriting for zero- shot tool retrieval,”arXiv preprint arXiv:2408.01875, 2024
-
[39]
Tool- Gen: Unified tool retrieval and calling via generation,
R. Wang, X. Han, L. Ji, S. Wang, T. Baldwin, and H. Li, “Tool- Gen: Unified tool retrieval and calling via generation,”arXiv preprint arXiv:2410.03439, 2024
-
[40]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
ToolNet: Connecting large language models with massive tools via tool graph,
X. Liu, Z. Peng, X. Yi, X. Xie, L. Xiang, Y . Liu, and D. Xu, “ToolNet: Connecting large language models with massive tools via tool graph,” arXiv preprint arXiv:2403.00839, 2024
-
[42]
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
D. Li, Z. Li, H. Du, X. Wu, S. Gui, Y . Kuang, and L. Sun, “Graph of skills: Dependency-aware structural retrieval for massive agent skills,” arXiv preprint arXiv:2604.05333, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Skillnet: Create, evaluate, and connect ai skills.arXiv preprint arXiv:2603.04448,
Y . Liang, R. Zhong, H. Xu, C. Jiang, Y . Zhong, R. Fang, J.-C. Gu, S. Deng, Y . Yao, M. Wanget al., “SkillNet: Create, evaluate, and connect AI skills,”arXiv preprint arXiv:2603.04448, 2026
-
[44]
Planning and acting in partially observable stochastic domains,
L. P. Kaelbling, M. L. Littman, and A. R. Cassandra, “Planning and acting in partially observable stochastic domains,”Artificial intelligence, vol. 101, no. 1-2, pp. 99–134, 1998
1998
-
[45]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,
R. S. Sutton, D. Precup, and S. Singh, “Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,”Artificial intelligence, vol. 112, no. 1-2, pp. 181–211, 1999
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.