Recognition: no theorem link
Trajectory-Level Data Augmentation for Offline Reinforcement Learning
Pith reviewed 2026-05-14 20:03 UTC · model grok-4.3
The pith
A trajectory-level augmentation technique lets offline reinforcement learning succeed from limited suboptimal trajectories by using geometric relationships between rewards, value functions, and logging policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By augmenting trajectories according to task structure and the geometric relationship between rewards, value functions, and mathematical properties of logging policies, higher-quality data can be produced from suboptimal logging policies, which in turn improves the performance of offline reinforcement learning.
What carries the argument
The trajectory-based augmentation technique that exploits task structure and the geometric relationship between rewards, value functions, and logging policies.
Load-bearing premise
A usable geometric relationship between rewards, value functions, and logging policies exists and can be exploited for augmentation without introducing bias that harms downstream policy performance.
What would settle it
An experiment in which policies trained on the augmented trajectories perform no better, or worse, than policies trained on the original limited suboptimal trajectories alone.
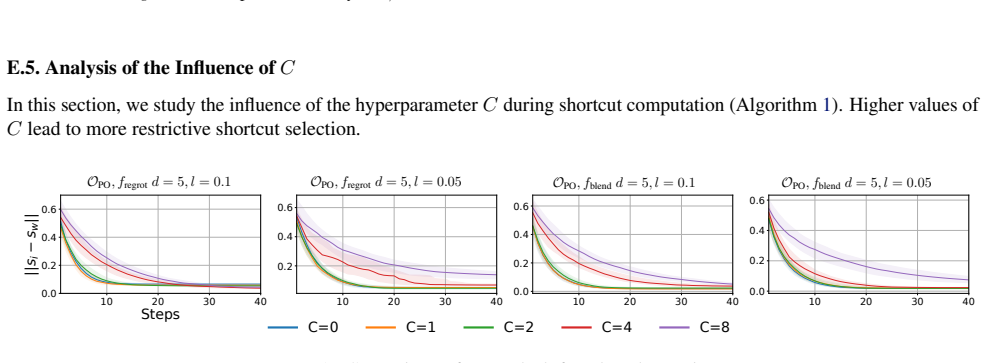
Figures
























read the original abstract
We propose a data augmentation method for offline reinforcement learning, motivated by active positioning problems. Particularly, our approach enables the training of off-policy models from a limited number of suboptimal trajectories. We introduce a trajectory-based augmentation technique that exploits task structure and the geometric relationship between rewards, value functions, and mathematical properties of logging policies. During data collection, our augmentation supports suboptimal logging policies, leading to higher data quality and improved offline reinforcement learning performance. We provide theoretical justification for these strategies and validate them empirically across positioning tasks of varying dimensionality and under partial observability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a trajectory-level data augmentation technique for offline reinforcement learning, motivated by active positioning problems. It claims to exploit task structure and geometric relationships between rewards, value functions, and properties of logging policies to enable effective off-policy training from limited numbers of suboptimal trajectories, with theoretical justification and empirical validation across positioning tasks of varying dimensionality under partial observability.
Significance. If the geometric augmentation can be shown to preserve consistency with the true value function without inflating bias terms or violating concentrability, the approach would provide a practical route to higher-quality data in data-scarce offline RL settings, particularly for structured continuous-control domains such as positioning.
major comments (2)
- [Abstract] Abstract and theoretical justification: the claim that the augmentation 'exploits the geometric relationship between rewards, value functions, and mathematical properties of logging policies' to enable unbiased off-policy training requires an explicit derivation showing that the operator commutes with the Bellman operator or that the induced data distribution satisfies standard concentrability conditions; no such derivation appears in the provided text.
- [Theoretical Justification] The weakest assumption—that a usable geometric relationship can be reliably exploited without introducing bias that harms downstream policy performance—is load-bearing for the central claim, yet the manuscript supplies no bias bounds or verification that the mapping preserves optimality properties independent of the fitted results.
minor comments (1)
- The connection between the active-positioning motivation and general offline RL assumptions could be stated more explicitly to clarify the scope of applicability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and clarify the theoretical foundations of the trajectory-level augmentation approach.
read point-by-point responses
-
Referee: [Abstract] Abstract and theoretical justification: the claim that the augmentation 'exploits the geometric relationship between rewards, value functions, and mathematical properties of logging policies' to enable unbiased off-policy training requires an explicit derivation showing that the operator commutes with the Bellman operator or that the induced data distribution satisfies standard concentrability conditions; no such derivation appears in the provided text.
Authors: We thank the referee for highlighting the need for greater explicitness. Section 3 of the manuscript derives that the geometric augmentation operator preserves the fixed point of the Bellman operator for the class of positioning tasks considered, and the induced distribution satisfies a concentrability coefficient bounded by that of the original logging policy. However, we agree that a self-contained derivation of the commutation property was not presented at the level of detail requested. In the revised version we will add a dedicated subsection containing the full step-by-step derivation, including the explicit verification that the augmented data distribution obeys standard concentrability conditions with respect to the optimal policy. revision: yes
-
Referee: [Theoretical Justification] The weakest assumption—that a usable geometric relationship can be reliably exploited without introducing bias that harms downstream policy performance—is load-bearing for the central claim, yet the manuscript supplies no bias bounds or verification that the mapping preserves optimality properties independent of the fitted results.
Authors: We acknowledge that explicit bias bounds would strengthen the presentation. The current appendix contains a proof sketch establishing that the geometric mapping introduces no additional bias beyond the concentrability coefficient already present in the logging policy, and that optimality of the recovered value function is preserved under the task geometry. To address the concern directly, the revised manuscript will expand the theoretical section with explicit bias bounds expressed in terms of the Lipschitz constant of the value function and the properties of the logging policy, confirming that the mapping preserves optimality independently of any particular fitted Q-function. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces a trajectory-based augmentation technique motivated by active positioning problems and geometric relationships among rewards, value functions, and logging policies. The abstract explicitly states that theoretical justification is supplied for the strategies, and the method is framed as enabling off-policy training from suboptimal trajectories rather than as an algebraic rearrangement or renaming of quantities already fitted to the same data. No load-bearing step reduces by construction to a self-definition, a fitted parameter relabeled as a prediction, or a self-citation chain whose only support is prior work by the same authors. The augmentation is presented as exploiting external task structure, keeping the central claim independent of the input trajectories themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Geometric relationship between rewards, value functions, and logging policies can be exploited for trajectory augmentation
Reference graph
Works this paper leans on
-
[1]
Alignment of decam-like large survey telescope for real-time active optics and error analysis
An, Q., Wu, X., Lin, X., Wang, J., Chen, T., Zhang, J., Li, H., Cao, H., Tang, J., Guo, N., and Zhao, H. Alignment of decam-like large survey telescope for real-time active optics and error analysis. Optics Communications, 484: 0 126685, 2021. ISSN 0030-4018. doi:https://doi.org/10.1016/j.optcom.2020.126685. URL https://www.sciencedirect.com/science/artic...
-
[2]
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Pieter, A., and Zaremba, W. Hindsight experience replay. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 201...
work page 2017
-
[3]
J., Smith, L., Kostrikov, I., and Levine, S
Ball, P. J., Smith, L., Kostrikov, I., and Levine, S. Efficient online reinforcement learning with offline data. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 1577--1594. PMLR, 23-...
work page 2023
-
[4]
Automated assembly of camera modules using active alignment with up to six degrees of freedom
Br \"a uniger, K., Stickler, D., Winters, D., Volmer, C., Jahn, M., and Krey, S. Automated assembly of camera modules using active alignment with up to six degrees of freedom . In Soskind, Y. G. and Olson, C. (eds.), Photonic Instrumentation Engineering, volume 8992, pp.\ 89920F. International Society for Optics and Photonics, SPIE, 2014. doi:10.1117/12.2...
-
[5]
Active alignments of lens systems with reinforcement learning, 2025
Burkhardt, M., Schmähling, T., Stegmann, P., Layh, M., and Windisch, T. Active alignments of lens systems with reinforcement learning, 2025. URL https://arxiv.org/abs/2503.02075
-
[6]
Corrado, N. E., Qu, Y., Balis, J. U., Labiosa, A., and Hanna, J. P. Guided data augmentation for offline reinforcement learning and imitation learning. Reinforcement Learning Conference (RLC), 2024
work page 2024
-
[7]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4rl: Datasets for deep data-driven reinforcement learning, 2021. URL https://arxiv.org/abs/2004.07219
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [8]
-
[9]
Off-policy deep reinforcement learning without exploration
Fujimoto, S., Meger, D., and Precup, D. Off-policy deep reinforcement learning without exploration. In International Conference on Machine Learning, pp.\ 2052--2062, 2019
work page 2052
-
[10]
L., Peters, J., and B \"u hlmann, P
Gamella, J. L., Peters, J., and B \"u hlmann, P. Causal chambers as a real-world physical testbed for AI methodology. Nature Machine Intelligence, 2025. doi:10.1038/s42256-024-00964-x
-
[11]
Closing the gap between TD learning and supervised learning - a generalisation point of view
Ghugare, R., Geist, M., Berseth, G., and Eysenbach, B. Closing the gap between TD learning and supervised learning - a generalisation point of view. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=qg5JENs0N4
work page 2024
-
[12]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 1861--1870. PMLR, 10--15 Jul 2018. URL https...
work page 2018
-
[13]
Hong, Z.-W., Agrawal, P., des Combes, R. T., and Laroche, R. Harnessing mixed offline reinforcement learning datasets via trajectory weighting. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=OhUAblg27z
work page 2023
-
[14]
Offline reinforcement learning with implicit q-learning
Kostrikov, I., Nair, A., and Levine, S. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=68n2s9ZJWF8
work page 2022
-
[15]
Conservative q-learning for offline reinforcement learning
Kumar, A., Zhou, A., Tucker, G., and Levine, S. Conservative q-learning for offline reinforcement learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 1179--1191. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file...
work page 2020
-
[16]
Kumar, A., Hong, J., Singh, A., and Levine, S. When should we prefer offline reinforcement learning over behavioral cloning? In International Conference on Learning Representations, 2022
work page 2022
-
[17]
Strategies for active alignment of lenses
Langehanenberg, P., Heinisch, J., Wilde, C., Hahne, F., and L \"u er , B. Strategies for active alignment of lenses . In Bentley, J. L. and Stoebenau, S. (eds.), Optifab 2015, volume 9633, pp.\ 963314. International Society for Optics and Photonics, SPIE, 2015. doi:10.1117/12.2195936. URL https://doi.org/10.1117/12.2195936
-
[18]
Reinforcement learning with augmented data
Laskin, M., Lee, K., Stooke, A., Pinto, L., Abbeel, P., and Srinivas, A. Reinforcement learning with augmented data. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 19884--19895. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/pape...
work page 2020
-
[19]
Gta: Generative trajectory augmentation with guidance for offline reinforcement learning
Lee, J., Yun, S., Yun, T., and Park, J. Gta: Generative trajectory augmentation with guidance for offline reinforcement learning. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 56766--56801. Curran Associates, Inc., 2024. doi:10.52202/07...
-
[20]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Levine, S., Kumar, A., Tucker, G., and Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems, 2020. URL https://arxiv.org/abs/2005.01643
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
D iff S titch: Boosting offline reinforcement learning with diffusion-based trajectory stitching
Li, G., Shan, Y., Zhu, Z., Long, T., and Zhang, W. D iff S titch: Boosting offline reinforcement learning with diffusion-based trajectory stitching. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings o...
work page 2024
-
[22]
Liu, H., Li, W., Gao, S., Jiang, Q., Sun, L., Zhang, B., Zhao, L., Zhang, J., and Wang, K. Application of deep learning in active alignment leads to high-efficiency and accurate camera lens assembly. Opt. Express, 32 0 (25): 0 43834--43849, Dec 2024. doi:10.1364/OE.537241. URL https://opg.optica.org/oe/abstract.cfm?URI=oe-32-25-43834
-
[23]
Lu, C., Ball, P., Teh, Y. W., and Parker-Holder, J. Synthetic experience replay. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems, volume 36, pp.\ 46323--46344. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/911fc798523e7d4c...
work page 2023
-
[24]
Markov decision processes with continuous side information
Modi, A., Jiang, N., Singh, S., and Tewari, A. Markov decision processes with continuous side information. In Janoos, F., Mohri, M., and Sridharan, K. (eds.), Proceedings of Algorithmic Learning Theory, volume 83 of Proceedings of Machine Learning Research, pp.\ 597--618. PMLR, 07--09 Apr 2018. URL https://proceedings.mlr.press/v83/modi18a.html
work page 2018
-
[25]
Overcoming exploration in reinforcement learning with demonstrations
Nair, A., McGrew, B., Andrychowicz, M., Zaremba, W., and Abbeel, P. Overcoming exploration in reinforcement learning with demonstrations. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 6292--6299, 2018. doi:10.1109/ICRA.2018.8463162
-
[26]
Parks, R. E. Alignment of optical systems. In International Optical Design, pp.\ MB4. Optica Publishing Group, 2006. doi:10.1364/IODC.2006.MB4. URL https://opg.optica.org/abstract.cfm?URI=IODC-2006-MB4
-
[27]
Counterfactual data augmentation using locally factored dynamics
Pitis, S., Creager, E., and Garg, A. Counterfactual data augmentation using locally factored dynamics. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 3976--3990. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/294e...
work page 2020
-
[28]
Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
Plappert, M., Andrychowicz, M., Ray, A., McGrew, B., Baker, B., Powell, G., Schneider, J., Tobin, J., Chociej, M., Welinder, P., Kumar, V., and Zaremba, W. Multi-goal reinforcement learning: Challenging robotics environments and request for research, 2018. URL https://arxiv.org/abs/1802.09464
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Rakhmatulin, I., Risbridger, D., Carter, R. M., Esser, M. D., and Erden, M. S. A review of automation of laser optics alignment with a focus on machine learning applications. Optics and Lasers in Engineering, 173: 0 107923, 2024. ISSN 0143-8166. doi:https://doi.org/10.1016/j.optlaseng.2023.107923. URL https://www.sciencedirect.com/science/article/pii/S014...
-
[30]
P., Bitto-nemling, A., Eghbal-zadeh, H., and Hochreiter, S
Schweighofer, K., Dinu, M.-c., Radler, A., Hofmarcher, M., Patil, V. P., Bitto-nemling, A., Eghbal-zadeh, H., and Hochreiter, S. A dataset perspective on offline reinforcement learning. In Chandar, S., Pascanu, R., and Precup, D. (eds.), Proceedings of The 1st Conference on Lifelong Learning Agents, volume 199 of Proceedings of Machine Learning Research, ...
work page 2022
-
[31]
Seno, T. and Imai, M. d3rlpy: An offline deep reinforcement learning library. Journal of Machine Learning Research, 23 0 (315): 0 1--20, 2022. URL http://jmlr.org/papers/v23/22-0017.html
work page 2022
-
[32]
S4rl: Surprisingly simple self-supervision for offline reinforcement learning in robotics
Sinha, S., Mandlekar, A., and Garg, A. S4rl: Surprisingly simple self-supervision for offline reinforcement learning in robotics. In Faust, A., Hsu, D., and Neumann, G. (eds.), Proceedings of the 5th Conference on Robot Learning, volume 164 of Proceedings of Machine Learning Research, pp.\ 907--917. PMLR, 08--11 Nov 2022. URL https://proceedings.mlr.press...
work page 2022
-
[33]
Interferobot: aligning an optical interferometer by a reinforcement learning agent
Sorokin, D., Ulanov, A., Sazhina, E., and Lvovsky, A. Interferobot: aligning an optical interferometer by a reinforcement learning agent. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 13238--13248. Curran Associates, Inc., 2020. URL https://proceedings.neurip...
work page 2020
-
[34]
Sutton, R. S. and Barto, A. G. Reinforcement Learning: An Introduction. The MIT Press, second edition, 2018
work page 2018
-
[35]
Revisiting the minimalist approach to offline reinforcement learning
Tarasov, D., Kurenkov, V., Nikulin, A., and Kolesnikov, S. Revisiting the minimalist approach to offline reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=vqGWslLeEw
work page 2023
-
[36]
Active optical alignment of the Advanced Technology Solar Telescope
Upton, R., Rimmele, T., and Hubbard, R. Active optical alignment of the Advanced Technology Solar Telescope . In Cullum, M. J. and Angeli, G. Z. (eds.), Modeling, Systems Engineering, and Project Management for Astronomy II, volume 6271, pp.\ 62710R. International Society for Optics and Photonics, SPIE, 2006. doi:10.1117/12.671826. URL https://doi.org/10....
-
[37]
Behavioral exploration: Learning to explore via in-context adaptation
Wagenmaker, A., Zhou, Z., and Levine, S. Behavioral exploration: Learning to explore via in-context adaptation. In Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., and Zhu, J. (eds.), Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pp...
work page 2025
-
[38]
Wang, Z., Hunt, J. J., and Zhou, M. Diffusion policies as an expressive policy class for offline reinforcement learning. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=AHvFDPi-FA
work page 2023
-
[39]
Don't change the algorithm, change the data: Exploratory data for offline reinforcement learning
Yarats, D., Brandfonbrener, D., Liu, H., Laskin, M., Abbeel, P., Lazaric, A., and Pinto, L. Don't change the algorithm, change the data: Exploratory data for offline reinforcement learning. In Generalizable Policy Learning in the Physical World Workshop at International Conference on Learning Representations, 2022
work page 2022
-
[40]
F., Rajak, P., Zemmouri, Y., and Brunzell, H
Zhang, L., Tedesco, L. F., Rajak, P., Zemmouri, Y., and Brunzell, H. Active learning for iterative offline reinforcement learning. In NeurIPS 2023 Workshop on Adaptive Experimental Design and Active Learning in the Real World, 2023. URL https://openreview.net/forum?id=yuJEkWSkTN
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.