Recognition: unknown
LIFT: Last-Mile Fine-Tuning for Table Explicitation
Pith reviewed 2026-05-14 19:39 UTC · model grok-4.3
The pith
Last-mile fine-tuning pairs a pre-trained LLM for initial table extraction with a fine-tuned SLM that repairs errors, matching end-to-end SLM fine-tuning on TEDS while using as few as 1,000 examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
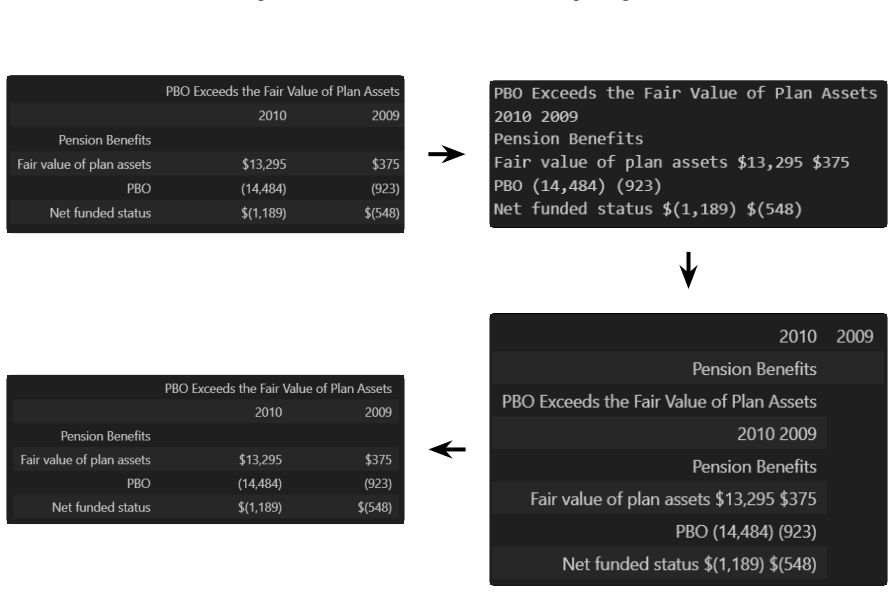
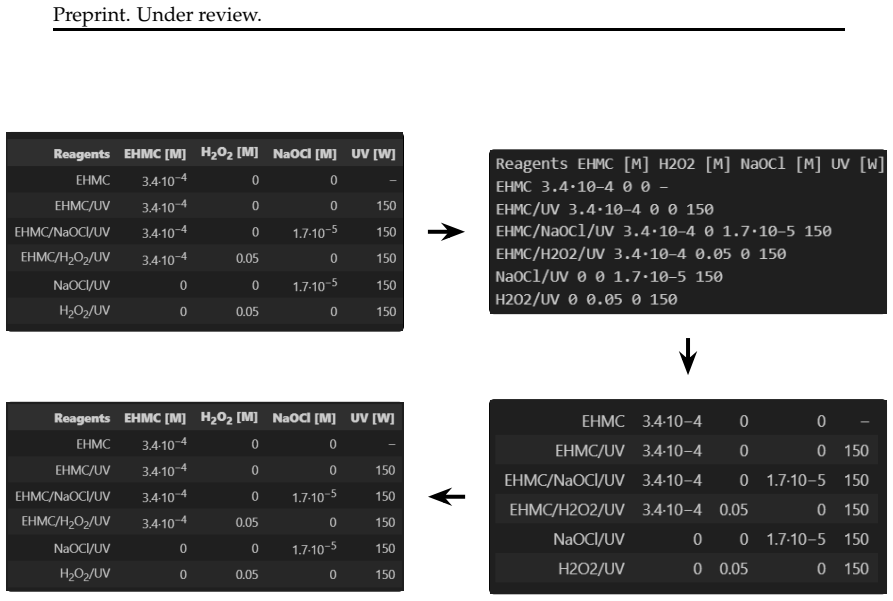
Last-mile fine-tuning, in which a pre-trained LLM produces an initial table extraction and a fine-tuned SLM (1B–24B parameters) repairs errors in that extraction, achieves TEDS scores equal to or higher than end-to-end SLM fine-tuning across 2,596 tables from three datasets, outperforming the baseline by up to 0.144 TEDS points when trained on only 1,000 examples, while also exhibiting greater robustness to input-format variation.
What carries the argument
The Lift pipeline: a pre-trained large language model that first extracts a table from unstructured text, followed by a fine-tuned small language model that repairs errors in the extracted table.
If this is right
- Lift reaches or exceeds end-to-end fine-tuning accuracy with only 1,000 training examples instead of the full dataset.
- The method improves robustness to changes in how the unstructured input text is formatted.
- It outperforms both self-debug and end-to-end fine-tuning approaches when labeled data is scarce.
- Accuracy gains are measured on tree-edit-distance similarity across three distinct table datasets totaling 2,596 examples.
Where Pith is reading between the lines
- The same two-stage pattern could be tested on other structured-output tasks such as extracting nested lists or JSON objects from free text.
- If the repair model can be kept small, organizations could maintain a single large extractor and swap lightweight repair heads for different domains.
- A natural next measurement would be whether the SLM repair step still helps when the initial LLM is replaced by a different model family.
Load-bearing premise
Errors made by the pre-trained LLM during initial extraction are consistently repairable by the fine-tuned SLM in a way that generalizes across datasets and input formats without the repair step creating new systematic mistakes.
What would settle it
Evaluating Lift on a new fourth dataset with previously unseen table structures or input formats and finding that its TEDS score drops below the end-to-end fine-tuning baseline even at 1,000 examples would falsify the central claim.
Figures




read the original abstract
We propose last-mile fine-tuning, or Lift, a pipeline in which a pre-trained large language model extracts an initial table from unstructured clipboard text, and a fine-tuned small language model (1B-24B parameters SLM) repairs errors in the extracted table. On a benchmark of 2,596 tables from three datasets, Lift matches or exceeds end-to-end SLM fine-tuning on tree-edit-distance-based similarity (TEDS) metric while requiring as little as 1,000 training examples - where it outperforms end-to-end fine-tuning by up to 0.144 TEDS points. We term this approach last-mile fine-tuning and show it also more robust to input format variability. Comparisons with self-debug and end-to-end fine-tuning approaches show that last-mile fine-tuning provides an attractive option when training data is limited or when robustness to input variation is sought without compromising on accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LIFT (last-mile fine-tuning), a two-stage pipeline in which a pre-trained LLM first extracts a table from unstructured clipboard text and a fine-tuned SLM (1B-24B parameters) then repairs errors in the initial extraction. Evaluated on 2,596 tables drawn from three datasets, the approach is claimed to match or exceed end-to-end SLM fine-tuning on the tree-edit-distance-based similarity (TEDS) metric while using as few as 1,000 training examples (with reported gains up to 0.144 TEDS points) and to exhibit greater robustness to input-format variation than self-debug or end-to-end baselines.
Significance. If the reported deltas hold under detailed experimental scrutiny, the work would demonstrate a practical, data-efficient route to high-accuracy table extraction that reduces the labeled-data requirement by an order of magnitude relative to full fine-tuning. The multi-dataset evaluation and explicit robustness claim would position LIFT as a useful engineering pattern for low-resource table-understanding pipelines.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Evaluation): the central claim of outperformance by up to 0.144 TEDS points is presented without any mention of the number of random seeds, standard deviations, exact train/validation/test splits, or statistical significance tests. These controls are load-bearing for the claim that LIFT reliably exceeds end-to-end fine-tuning across the three datasets.
- [§3 and §4.2] §3 (Method) and §4.2 (Robustness Experiments): the assumption that the SLM repair step learns generalizable corrections from the upstream LLM's error distribution without introducing offsetting systematic errors is stated but not supported by an error-analysis ablation or per-dataset breakdown of introduced versus corrected mistakes. This directly affects the interpretation of the TEDS gains.
minor comments (2)
- [§3] The pipeline diagram (if present) or the description of the interface between the LLM extraction and SLM repair stages would benefit from an explicit notation for the input/output formats to avoid ambiguity about what constitutes an 'error' passed to the repair model.
- [Table 1] Table 1 (or equivalent results table) should report the exact parameter counts and training budgets for all compared methods side-by-side to make the '1,000-example' advantage immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each of the major comments below and outline the revisions we intend to make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Evaluation): the central claim of outperformance by up to 0.144 TEDS points is presented without any mention of the number of random seeds, standard deviations, exact train/validation/test splits, or statistical significance tests. These controls are load-bearing for the claim that LIFT reliably exceeds end-to-end fine-tuning across the three datasets.
Authors: We agree that additional experimental details are necessary to support the central claims. In the revised manuscript, we will report the number of random seeds (we used 5), include standard deviations for all TEDS scores, specify the exact train/validation/test splits used for each dataset, and perform statistical significance tests (e.g., paired t-tests) to confirm the improvements are significant. These additions will be incorporated into Section 4 and the abstract where appropriate. revision: yes
-
Referee: [§3 and §4.2] §3 (Method) and §4.2 (Robustness Experiments): the assumption that the SLM repair step learns generalizable corrections from the upstream LLM's error distribution without introducing offsetting systematic errors is stated but not supported by an error-analysis ablation or per-dataset breakdown of introduced versus corrected mistakes. This directly affects the interpretation of the TEDS gains.
Authors: We recognize the value of an error analysis to validate the assumption about the SLM repair step. We will add a new subsection in the revised manuscript providing an error-analysis ablation, including a per-dataset breakdown showing the number and types of mistakes introduced versus corrected by the fine-tuned SLM. This will help readers better interpret the TEDS gains and confirm that the repair step contributes positively without systematic offsets. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical two-stage pipeline (pre-trained LLM extraction + SLM repair) and reports performance on held-out test tables from three external datasets using the TEDS metric. All claims reduce to direct experimental comparisons against baselines under matched conditions rather than any derivation, equation, or fitted quantity that is defined in terms of itself. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps in the provided text; the central result is a measured delta on independent test data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A fine-tuned small language model can reliably repair table extraction errors produced by a frozen pre-trained large language model.
Reference graph
Works this paper leans on
-
[1]
GriTS: Grid Table Similarity Metric for Table Structure Recognition
Smock, Brandon and Pesala, Rohith and Abraham, Robin. GriTS: Grid Table Similarity Metric for Table Structure Recognition. Document Analysis and Recognition - ICDAR 2023. 2023
2023
-
[2]
Image-Based Table Recognition: Data, Model, and Evaluation
Zhong, Xu and ShafieiBavani, Elaheh and Jimeno Yepes, Antonio. Image-Based Table Recognition: Data, Model, and Evaluation. Computer Vision -- ECCV 2020. 2020
2020
-
[3]
Optimized Table Tokenization for Table Structure Recognition
Lysak, Maksym and Nassar, Ahmed and Livathinos, Nikolaos and Auer, Christoph and Staar, Peter. Optimized Table Tokenization for Table Structure Recognition. Document Analysis and Recognition - ICDAR 2023. 2023
2023
-
[4]
2019 , eprint=
Complicated Table Structure Recognition , author=. 2019 , eprint=
2019
-
[5]
Text-to-Table: A New Way of Information Extraction
Wu, Xueqing and Zhang, Jiacheng and Li, Hang. Text-to-Table: A New Way of Information Extraction. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.180
-
[6]
2025 , eprint=
TEN: Table Explicitization, Neurosymbolically , author=. 2025 , eprint=
2025
-
[7]
Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam Shazeer and Vinodkumar Prabhakaran and Emi...
-
[8]
Benchmarking Large Language Models for News Summarization
Zhang, Tianyi and Ladhak, Faisal and Durmus, Esin and Liang, Percy and McKeown, Kathleen and Hashimoto, Tatsunori B. Benchmarking Large Language Models for News Summarization. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00632
-
[9]
2022 , eprint=
OPT: Open Pre-trained Transformer Language Models , author=. 2022 , eprint=
2022
-
[10]
Fine-Tune an
Orlando Marquez Ayala and Patrice Bechard and Emily Chen and Maggie Baird and Jingfei Chen , booktitle=. Fine-Tune an. 2025 , url=
2025
-
[11]
MiniLLM: Knowledge Distillation of Large Language Models , url =
Gu, Yuxian and Dong, Li and Wei, Furu and Huang, Minlie , booktitle =. MiniLLM: Knowledge Distillation of Large Language Models , url =
-
[12]
SEMv2: Table separation line detection based on instance segmentation , journal =
Zhenrong Zhang and Pengfei Hu and Jiefeng Ma and Jun Du and Jianshu Zhang and Baocai Yin and Bing Yin and Cong Liu , keywords =. SEMv2: Table separation line detection based on instance segmentation , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.patcog.2024.110279 , url =
-
[13]
T able VLM : Multi-modal Pre-training for Table Structure Recognition
Chen, Leiyuan and Huang, Chengsong and Zheng, Xiaoqing and Lin, Jinshu and Huang, Xuanjing. T able VLM : Multi-modal Pre-training for Table Structure Recognition. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.137
-
[14]
TableFormer: Robust Transformer Modeling for Table-Text Encoding
Jingfeng Yang and Aditya Gupta and Shyam Upadhyay and Luheng He and Rahul Goel and Shachi Paul. TableFormer: Robust Transformer Modeling for Table-Text Encoding. Proc. of ACL. 2022
2022
-
[15]
International conference on pattern recognition , pages=
GFTE: graph-based financial table extraction , author=. International conference on pattern recognition , pages=. 2021 , organization=
2021
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
Prasad, Devashish and Gadpal, Ayan and Kapadni, Kshitij and Visave, Manish and Sultanpure, Kavita , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
-
[17]
Ashish Tiwari and Mukul Singh and Ananya Singha and Arjun Radhakrishna , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.10698 , eprinttype =. 2503.10698 , timestamp =
-
[18]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[19]
MPNet: Masked and Permuted Pre-training for Language Understanding , url =
Song, Kaitao and Tan, Xu and Qin, Tao and Lu, Jianfeng and Liu, Tie-Yan , booktitle =. MPNet: Masked and Permuted Pre-training for Language Understanding , url =
-
[20]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
ArXiv , year=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. ArXiv , year=
-
[24]
ArXiv , year=
Mistral 7B , author=. ArXiv , year=
-
[25]
Mistral Small 3 , url=
Mistral AI Team , year=. Mistral Small 3 , url=
-
[26]
Merrill , title =
Manuel Aristarán and Mike Tigas and Jeremy B. Merrill , title =. 2012 , note =
2012
-
[27]
2026 , url =
Adobe Acrobat. 2026 , url =
2026
-
[28]
TableNet: Deep Learning Model for End-to-end Table Detection and Tabular Data Extraction from Scanned Document Images , year=
Paliwal, Shubham Singh and D, Vishwanath and Rahul, Rohit and Sharma, Monika and Vig, Lovekesh , booktitle=. TableNet: Deep Learning Model for End-to-end Table Detection and Tabular Data Extraction from Scanned Document Images , year=
-
[29]
Deng, Zheye and Chan, Chunkit and Wang, Weiqi and Sun, Yuxi and Fan, Wei and Zheng, Tianshi and Yim, Yauwai and Song, Yangqiu. Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.523
-
[30]
Zhang and D
K. Zhang and D. Shasha. Simple fast algorithms for the editing distance between trees and related problems
-
[31]
Singh, Mukul and Verbruggen, Gust and Le, Vu and Gulwani, Sumit , title =. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =. 2024 , isbn =. doi:10.1145/3627673.3680000 , abstract =
-
[32]
2025 , eprint=
SLMFix: Leveraging Small Language Models for Error Fixing with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[33]
Neurosymbolic repair for low-code formula languages , year =
Bavishi, Rohan and Joshi, Harshit and Cambronero, Jos\'. Neurosymbolic repair for low-code formula languages , year =. Proc. ACM Program. Lang. , month = oct, articleno =. doi:10.1145/3563327 , abstract =
-
[34]
Repair is nearly generation: multilingual program repair with LLMs , year =
Joshi, Harshit and Sanchez, Jos\'. Repair is nearly generation: multilingual program repair with LLMs , year =. Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence , articlen...
-
[35]
Table- LLM -Specialist: Language Model Specialists for Tables using Iterative Fine-tuning
Xing, Junjie and He, Yeye and Zhou, Mengyu and Dong, Haoyu and Han, Shi and Zhang, Dongmei and Chaudhuri, Surajit. Table- LLM -Specialist: Language Model Specialists for Tables using Iterative Fine-tuning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1795
-
[36]
Plug-in and Fine-tuning: Bridging the Gap between Small Language Models and Large Language Models
Kim, Kyeonghyun and Jang, Jinhee and Choi, Juhwan and Lee, Yoonji and Jin, Kyohoon and Kim, YoungBin. Plug-in and Fine-tuning: Bridging the Gap between Small Language Models and Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.271
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.