ProjGuard: Safety Monitoring for Computer-Use Agents via Low-Dimensional Projections
Pith reviewed 2026-06-30 21:10 UTC · model grok-4.3
The pith
Low-dimensional projections of agent history produce a scalar risk signal that flags unsafe drifts early enough for selective correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
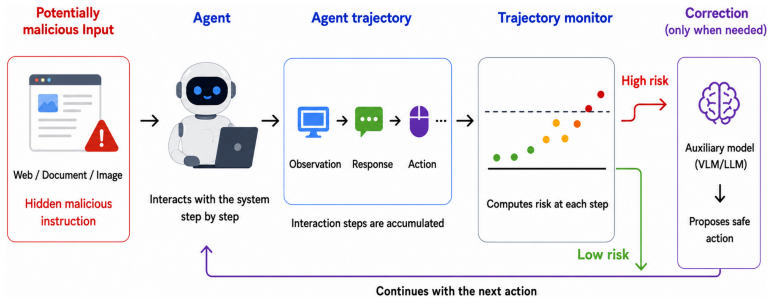
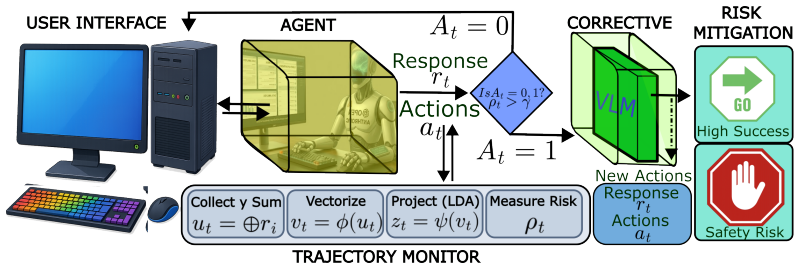
ProjGuard derives a lightweight scalar risk signal from the agent's accumulated interaction history at each step and evaluates online whether execution is beginning to drift toward an unsafe region. This enables early warnings before the trajectory reaches a potentially harmful action. When an alert is raised, an auxiliary vision-language model proposes a corrected next step and steers execution back toward task completion.
What carries the argument
The low-dimensional projection that compresses accumulated interaction history into a single scalar risk signal used for online drift detection.
If this is right
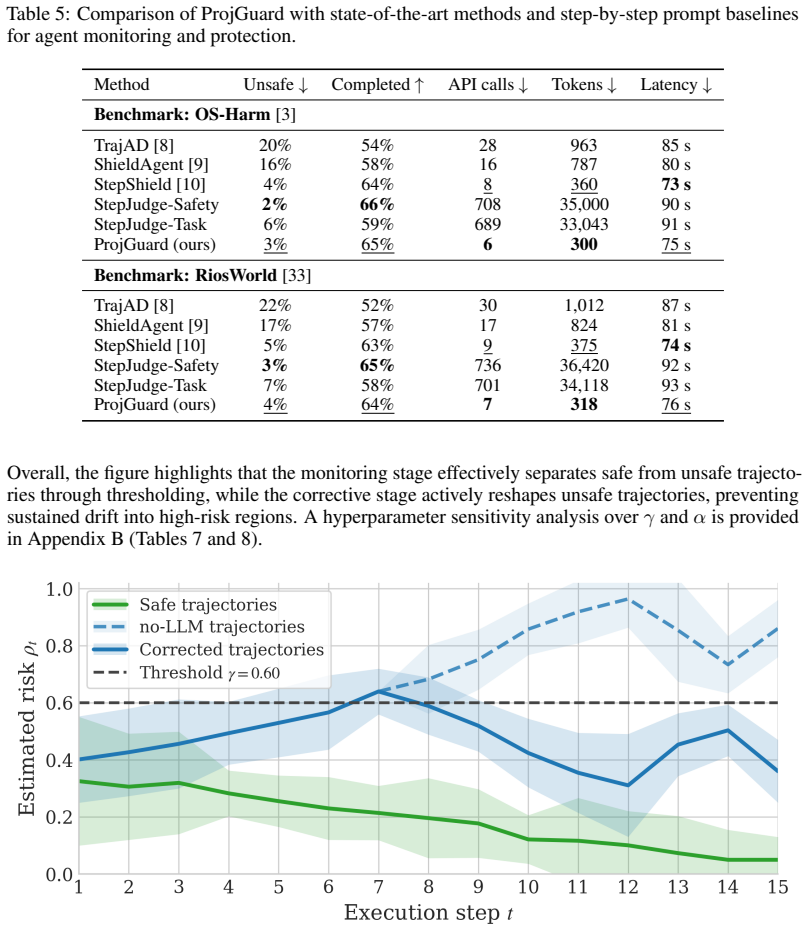
- Monitoring plus on-demand correction lowers unsafe rate from 16 percent to 3 percent on OS-Harm.
- Task completion rises from 59 percent to 65 percent under the same regime.
- The same monitoring transfers to RiosWorld, reaching 4 percent unsafe and 64 percent completion.
- Safety is achieved by always-on lightweight checks that activate a heavy model only on detected drift.
Where Pith is reading between the lines
- The projection approach could be applied to agent settings beyond desktop operating systems, such as web browsers or robotic control loops.
- If the scalar signal proves robust across attack types, it might reduce the need for separate prompt-injection classifiers.
- Lower average model calls per task could improve latency and energy cost for deployed agents at scale.
Load-bearing premise
The scalar produced by the low-dimensional projection reliably indicates when the agent's path is moving toward unsafe actions.
What would settle it
A test set of trajectories in which the projection signal remains below threshold yet the agent still executes unsafe actions, or in which raising the threshold eliminates the safety gain.
Figures
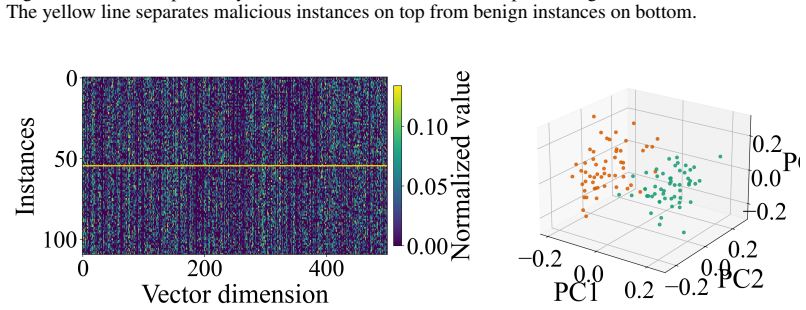
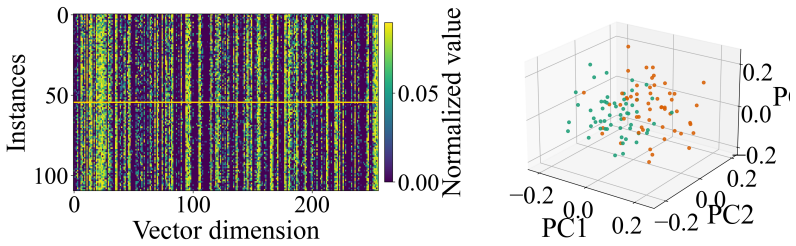
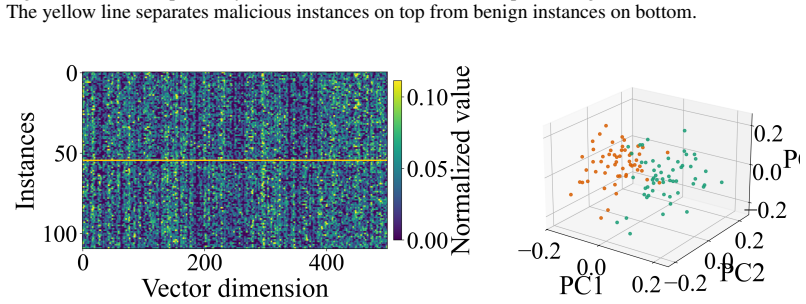
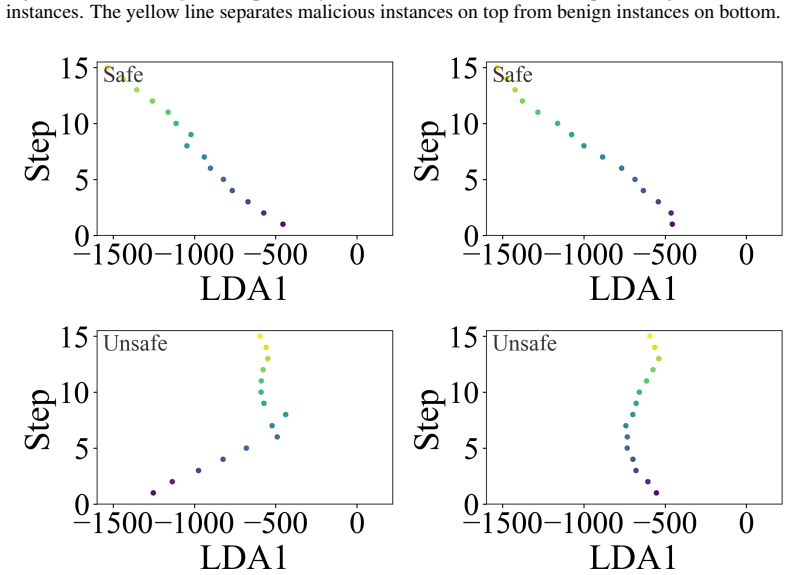
read the original abstract
Computer-use agents are increasingly capable of operating on real operating systems, but this capability has also increased the risks posed by prompt injection, indirect instructions, and visual attacks. Existing defenses typically rely on analyzing the prompt or each potentially malicious input with a second large model at inference time, which can limit coverage or increase deployment cost. We propose ProjGuard, an alternative based on behavioral trajectory monitoring. At each step, we derive a lightweight scalar risk signal from the agent's accumulated interaction history and evaluate, online, whether execution is beginning to drift toward an unsafe region. This enables early warnings before the trajectory reaches a potentially harmful action. When an alert is raised, we selectively activate an auxiliary vision-language model to propose a corrected next step and steer execution back toward task completion. Experiments on OS-Harm show that monitoring with on-demand correction reduces the unsafe rate from 16 percent to 3 percent while improving task completion from 59 percent to 65 percent. We further evaluate transfer to RiosWorld, where the method remains competitive, reaching 4 percent unsafe and 64 percent completion. Overall, these results support a hierarchical safety strategy in which always-on monitoring anticipates deviations and activates correction only when needed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProjGuard, a method for safety monitoring of computer-use agents that computes a lightweight scalar risk signal via low-dimensional projections of the agent's accumulated interaction history to detect early drift toward unsafe regions. When the signal exceeds a threshold, an auxiliary vision-language model is selectively invoked to suggest a corrected next action. On the OS-Harm benchmark the combined monitoring-plus-correction pipeline reduces the unsafe rate from 16% to 3% and raises task completion from 59% to 65%; competitive numbers (4% unsafe, 64% completion) are reported on RiosWorld. The work advocates a hierarchical safety strategy that keeps heavy VLM correction off the critical path until the projection signals risk.
Significance. If the projection-based monitor can be shown to provide a reliable, low-cost risk signal that is not interchangeable with any frequent alert, the approach could reduce inference cost for always-on safety while preserving task performance. The reported empirical gains on two benchmarks are practically relevant for computer-use agents, but the current evidence does not yet isolate the projection's contribution from the correction mechanism itself.
major comments (3)
- [Experiments] Experiments section (OS-Harm and RiosWorld results): the headline improvements (unsafe rate 16%→3%, completion 59%→65%) are measured only for the full pipeline. No ablation is described that replaces the low-dimensional risk signal with a non-informative trigger (constant, random, or prompt-only) while preserving the same correction frequency and VLM, so the data cannot distinguish whether the projection accurately detects drift or whether any sufficiently frequent alert would produce equivalent numbers.
- [Method] Method description (projection and threshold): the abstract and main text supply no derivation, equations, or algorithmic details for constructing the low-dimensional projection from interaction history, nor any procedure for choosing or validating the risk threshold. Without these, it is impossible to assess whether the scalar signal is a genuine monitor or an ad-hoc fitted quantity.
- [Evaluation] Evaluation (reported percentages): no error bars, number of runs, or statistical tests accompany the 16%→3% and 59%→65% figures, and no description is given of how the risk threshold was selected or cross-validated. This weakens confidence that the observed differences are robust.
minor comments (1)
- [Abstract] Abstract: the phrase 'low-dimensional projections' is used without stating the target dimensionality or the projection technique (e.g., PCA, random projection, learned embedding).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the empirical and methodological presentation of ProjGuard. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Experiments] Experiments section (OS-Harm and RiosWorld results): the headline improvements (unsafe rate 16%→3%, completion 59%→65%) are measured only for the full pipeline. No ablation is described that replaces the low-dimensional risk signal with a non-informative trigger (constant, random, or prompt-only) while preserving the same correction frequency and VLM, so the data cannot distinguish whether the projection accurately detects drift or whether any sufficiently frequent alert would produce equivalent numbers.
Authors: We agree that the current experiments do not isolate the projection monitor's contribution from the correction mechanism. In the revised manuscript we will add an ablation that substitutes the learned risk signal with non-informative triggers (constant, random, and prompt-only) while holding correction frequency and VLM usage fixed. This will directly test whether the projection-based signal provides value beyond frequent alerting. revision: yes
-
Referee: [Method] Method description (projection and threshold): the abstract and main text supply no derivation, equations, or algorithmic details for constructing the low-dimensional projection from interaction history, nor any procedure for choosing or validating the risk threshold. Without these, it is impossible to assess whether the scalar signal is a genuine monitor or an ad-hoc fitted quantity.
Authors: We acknowledge that the submitted manuscript does not include explicit equations or algorithmic details for the projection and threshold. We will expand the Method section with the full derivation of the low-dimensional projection (including the embedding and dimensionality-reduction steps), the precise scalar risk formula, and the threshold selection procedure (including validation approach). revision: yes
-
Referee: [Evaluation] Evaluation (reported percentages): no error bars, number of runs, or statistical tests accompany the 16%→3% and 59%→65% figures, and no description is given of how the risk threshold was selected or cross-validated. This weakens confidence that the observed differences are robust.
Authors: We agree that the reported results lack statistical characterization. The revised evaluation section will include the number of runs, error bars, statistical significance tests for the key metrics, and a description of how the risk threshold was chosen and validated (e.g., via cross-validation). revision: yes
Circularity Check
No circularity in derivation chain; purely empirical system description
full rationale
The manuscript presents ProjGuard as a practical monitoring pipeline that computes a scalar risk signal from interaction history and triggers an auxiliary VLM on alert. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. Experimental claims (unsafe-rate and completion-rate improvements on OS-Harm and RiosWorld) are direct measurements of the combined system; they do not reduce by construction to any internal fit or definition. The skeptic concern about missing ablations is an experimental-validity issue, not a circularity issue under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Elie Bursztein, Jonathan Mane, Michael T. Ribeiro, and Christopher Parris. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection.arXiv preprint arXiv:2302.12173, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Thomas Kuntz, Agatha Duzan, Hao Zhao, Francesco Croce, Zico Kolter, Nicolas Flammarion, and Maksym Andriushchenko. Os-harm: A benchmark for measuring safety of computer use agents.arXiv preprint arXiv:2506.14866, 2025
-
[4]
Attacking multimodal os agents with malicious image patches
Lukas Aichberger, Alasdair Paren, Philip Torr, Yarin Gal, and Adel Bibi. Attacking multimodal os agents with malicious image patches. InICLR 2025 shop on F oundation Models in the Wild, 2025
2025
-
[5]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions.arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents
Feiran Jia, Tong Wu, Xin Qin, and Anna Squicciarini. The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[8]
Yibing Liu, Chong Zhang, Zhongyi Han, Hansong Liu, Yong Wang, Yang Yu, Xiaoyan Wang, and Yilong Yin. Trajad: Trajectory anomaly detection for trustworthy llm agents.arXiv preprint arXiv:2602.06443, 2026
-
[9]
Zhaorun Chen, Mintong Kang, and Bo Li. Shieldagent: Shielding agents via verifiable safety policy reasoning.arXiv preprint arXiv:2503.22738, 2025
-
[10]
Stepshield: When, not whether to intervene on rogue agents
Gloria Felicia, Michael Eniolade, Jinfeng He, Zitha Sasindran, Hemant Kumar, Milan Hussain Angati, and Sandeep Bandarupalli. Stepshield: When, not whether to intervene on rogue agents. arXiv preprint arXiv:2601.22136, 2026
-
[11]
World of bits: An open-domain platform for web-based agents
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang. World of bits: An open-domain platform for web-based agents. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 3135–3144, 2017
2017
-
[12]
Webshop: Towards scalable real-world web interaction with grounded language agents, 2023
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents, 2023. 10
2023
-
[13]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024
2024
-
[14]
Mind2web: Towards a generalist agent for the web, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web, 2023
2023
-
[15]
Webvoyager: Building an end-to-end web agent with large multimodal models, 2024
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models, 2024
2024
-
[16]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
The browsergym ecosystem for web agent research, 2025.URL https://arxiv
Thibault Le Sellier De Chezelles, Maxime Gasse, Alexandre Drouin, Massimo Caccia, Léo Boisvert, Megh Thakkar, Tom Marty, Rim Assouel, Sahar Omidi Shayegan, Lawrence Keunho Jang, et al. The browsergym ecosystem for web agent research, 2025.URL https://arxiv. org/abs/2412.05467, 2025
-
[18]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021
2021
-
[19]
Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer
Tom B. Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer. Adversarial patch, 2018
2018
-
[20]
React: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023
2023
-
[21]
Toolformer: Language models can teach themselves to use tools, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023
2023
-
[22]
Tool documentation enables zero-shot tool-usage with large language models, 2023
Cheng-Yu Hsieh, Si-An Chen, Chun-Liang Li, Yasuhisa Fujii, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, and Tomas Pfister. Tool documentation enables zero-shot tool-usage with large language models, 2023
2023
-
[23]
Tool learning with foundation models, 2024
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, et al. Tool learning with foundation models, 2024
2024
-
[24]
Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023
2023
-
[25]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, 2023
2023
-
[26]
Reflexion: Language agents with verbal reinforcement learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023
2023
-
[27]
V oyager: An open-ended embodied agent with large language models, 2023
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models, 2023
2023
-
[28]
do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. "do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models, 2024
2024
-
[29]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023
2023
-
[30]
Baseline defenses for adversarial attacks against aligned language models, 2023
Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Baseline defenses for adversarial attacks against aligned language models, 2023. 11
2023
-
[31]
Promptfuzz: Harnessing fuzzing techniques for robust testing of prompt injection in llms, 2025
Jiahao Yu, Yangguang Shao, Hanwen Miao, and Junzheng Shi. Promptfuzz: Harnessing fuzzing techniques for robust testing of prompt injection in llms, 2025
2025
-
[32]
Constitutional ai: Harmlessness from ai feedback, 2022
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback, 2022
2022
-
[33]
Jingyi Yang, Shuai Shao, Dongrui Liu, and Jing Shao. Riosworld: Benchmarking the risk of multimodal computer-use agents.arXiv preprint arXiv:2506.00618, 2025
-
[34]
Term-weighting approaches in automatic text retrieval
Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. Information Processing & Management, 24(5):513–523, 1988
1988
-
[35]
Manning, Prabhakar Raghavan, and Hinrich Schütze.Introduction to Information Retrieval
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze.Introduction to Information Retrieval. Cambridge University Press, 2008
2008
-
[36]
Feature hashing for large scale multitask learning
Kilian Weinberger, Anirban Dasgupta, John Langford, Alex Smola, and Josh Attenberg. Feature hashing for large scale multitask learning. InProceedings of the 26th International Conference on Machine Learning (ICML), 2009
2009
-
[37]
Ronald A. Fisher. The use of multiple measurements in taxonomic problems.Annals of Eugenics, 7(2):179–188, 1936
1936
-
[38]
On lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 2(11):559–572, 1901
Karl Pearson. On lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 2(11):559–572, 1901
1901
-
[39]
Visualizing data using t-sne.Journal of Machine Learning Research, 9(Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9(Nov):2579–2605, 2008
2008
-
[40]
Benyamin Ghojogh, Ali Ghodsi, Fakhri Karray, and Mark Crowley. Uniform manifold approximation and projection (umap) and its variants: tutorial and survey.arXiv preprint arXiv:2109.02508, 2021
-
[41]
Cavnar and John M
William B. Cavnar and John M. Trenkle. N-gram-based text categorization. InProceedings of SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, pages 161–175, 1994
1994
-
[42]
A vector space model for automatic indexing
Gerard Salton, Anita Wong, and Chung-Shu Yang. A vector space model for automatic indexing. Communications of the ACM, 18(11):613–620, 1975. 12 Appendix A Agent Performance Ablation This appendix reports an ablation of agent performance by observation modality, with the goal of justifying the reference configuration used in the main experiments. In partic...
1975
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.