A Hierarchical Language Model with Predictable Scaling Laws and Provable Benefits of Reasoning
Pith reviewed 2026-05-14 20:25 UTC · model grok-4.3
The pith
Bounded-context autoregressive models require linear context to sample hierarchical languages faithfully, while reasoning models succeed with only logarithmic memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
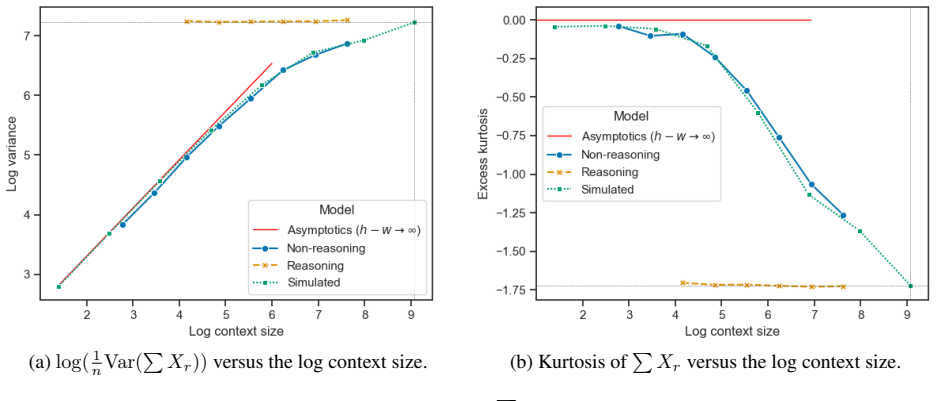
For languages generated by tree broadcast processes, standard autoregressive generation with any fixed context length fails to match the true distribution or produce consistent outputs, but an autoregressive reasoning model equipped with Theta(log n) working memory can sample exactly from the true language.
What carries the argument
The exact k-gram ansatz, which replaces a transformer with context length k and is used to derive closed-form predictions for sequence statistics.
If this is right
- In the Ising broadcast process, the variance of the sum of generated sequences scales log-linearly with context depth.
- The kurtosis of generated sequences in the Ising process converges to the Gaussian value for any sublinear context.
- In the freezing regime of the coloring broadcast process, bounded-context autoregression produces sequences inconsistent with any valid tree coloring with high probability.
- An autoregressive reasoning model achieves exact sampling from the true language using only Theta(log n) working memory.
Where Pith is reading between the lines
- The exponential gap suggests that explicit reasoning steps could be inserted into transformers to reduce effective context requirements on structured data.
- The results raise the question of whether similar logarithmic-memory reasoning mechanisms appear implicitly in large language models trained on natural hierarchical data.
- One could test whether the same scaling appears in other tree-structured or recursive generation tasks beyond the broadcast processes studied here.
Load-bearing premise
The exact k-gram ansatz is a faithful model of what a transformer with context length k actually does.
What would settle it
Train a transformer on the coloring broadcast process with context length o(n) and check whether the generated length-n sequences are valid colorings of the underlying tree with high probability.
Figures


read the original abstract
We introduce a family of synthetic languages with hierarchical structure -- generated by a broadcast process on trees -- for which the role of context length and reasoning in autoregressive generation can be analyzed precisely. At the heart of our analytic approach is an \emph{exact $k$-gram ansatz} in place of transformers with context length $k$, a substitution we then validate empirically. Using this ansatz we derive explicit asymptotic predictions for distributional statistics of the sequences produced by a trained model, instantiated in two settings. For the \emph{Ising broadcast process} (a soft-constrained language), we prove that the variance of the generated sum scales log-linearly in the context depth and its kurtosis converges to that of a Gaussian -- both deviating from the true language for any sublinear context. For the \emph{coloring broadcast process} (a hard-constrained language) in the freezing regime, bounded-context autoregression produces sequences that, with high probability, are inconsistent with \emph{any} valid coloring of the underlying tree. Together these results imply an $\Omega(n)$ lower bound on the context length required to faithfully sample length-$n$ sequences. In contrast, we prove that an autoregressive \emph{reasoning} model with only $\Theta(\log n)$ working memory can sample exactly from the true language -- an exponential improvement. We confirm both the lower-bound predictions and the reasoning-based upper bound empirically with transformers trained on the synthetic language; the trained models track our asymptotic predictions quantitatively across a wide range of context sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces synthetic hierarchical languages generated by broadcast processes on trees. It substitutes an exact k-gram ansatz for transformers with context length k (validated empirically), derives explicit asymptotic predictions for the Ising broadcast process (variance of generated sum scales log-linearly in context depth; kurtosis converges to Gaussian, both deviating from the true language for sublinear context) and shows that bounded-context autoregression on the coloring broadcast process produces sequences inconsistent with any valid tree coloring with high probability. These imply an Ω(n) lower bound on context length for faithful sampling of length-n sequences. In contrast, the paper proves that an autoregressive reasoning model with only Θ(log n) working memory samples exactly from the true language. Both the lower-bound predictions and reasoning upper bound are confirmed empirically with trained transformers that track the asymptotics quantitatively.
Significance. If the k-gram ansatz holds, the work supplies a rigorous analytic framework for context-length requirements and reasoning benefits on hierarchical languages, together with explicit, falsifiable asymptotic scaling laws. The combination of independent proofs for the broadcast processes, the exponential gap between Ω(n) and Θ(log n), and quantitative empirical matches on trained models constitutes a substantive contribution to understanding scaling in autoregressive generation.
major comments (3)
- [exact k-gram ansatz and lower-bound derivations] The exact k-gram ansatz (introduced as a substitute for context-k transformers) is load-bearing for every lower-bound derivation in both the Ising and coloring settings, yet the manuscript supplies only empirical validation rather than a formal argument that the k-gram marginals and sampling behavior match those of trained transformers (attention, positional encodings, optimization) for large n or in the freezing regime. Without such an argument the claimed Ω(n) context lower bound does not necessarily transfer to actual networks.
- [coloring broadcast process analysis] For the coloring broadcast process, the high-probability inconsistency claim (sequences inconsistent with any valid coloring) is central to the Ω(n) bound; the manuscript must state the explicit probability bound and its scaling with n and context length, as the current presentation leaves the quantitative strength of the result unclear.
- [empirical validation] The empirical section reports that trained transformers track the asymptotic predictions quantitatively, but provides insufficient detail on fitting procedures, data-exclusion criteria, or how quantitative agreement was assessed across context sizes; these gaps prevent full verification of the claimed matches.
minor comments (2)
- [reasoning model construction] Clarify the precise definition of 'working memory' in the reasoning model and how the Θ(log n) bound is realized in the autoregressive implementation.
- [figures] Add error bars or confidence intervals to the variance and kurtosis plots so that the quantitative tracking of predictions can be assessed visually.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important points for strengthening the manuscript. We address each major comment below and will revise the paper accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [exact k-gram ansatz and lower-bound derivations] The exact k-gram ansatz (introduced as a substitute for context-k transformers) is load-bearing for every lower-bound derivation in both the Ising and coloring settings, yet the manuscript supplies only empirical validation rather than a formal argument that the k-gram marginals and sampling behavior match those of trained transformers (attention, positional encodings, optimization) for large n or in the freezing regime. Without such an argument the claimed Ω(n) context lower bound does not necessarily transfer to actual networks.
Authors: We acknowledge that the k-gram ansatz is central and that a more formal justification would strengthen the transfer of the Ω(n) bound to trained networks. Our empirical results show quantitative agreement between trained transformers and the k-gram predictions across regimes, but we agree this is not a full proof. In revision we will add a new subsection analyzing the approximation, including how self-attention can realize k-gram marginals on tree-structured data and a discussion of error bounds in the freezing regime. This will clarify the conditions under which the lower bound applies to actual models. revision: yes
-
Referee: [coloring broadcast process analysis] For the coloring broadcast process, the high-probability inconsistency claim (sequences inconsistent with any valid coloring) is central to the Ω(n) bound; the manuscript must state the explicit probability bound and its scaling with n and context length, as the current presentation leaves the quantitative strength of the result unclear.
Authors: We agree that the presentation should be more precise. In the revised manuscript we will explicitly state the probability bound derived in our analysis of the freezing regime, including its scaling with sequence length n and context length k, so that the quantitative strength of the Ω(n) lower bound is clear. revision: yes
-
Referee: [empirical validation] The empirical section reports that trained transformers track the asymptotic predictions quantitatively, but provides insufficient detail on fitting procedures, data-exclusion criteria, or how quantitative agreement was assessed across context sizes; these gaps prevent full verification of the claimed matches.
Authors: We thank the referee for noting these gaps. In the revision we will expand the empirical section with: (i) explicit description of the fitting procedures (e.g., regression details for scaling laws), (ii) data-exclusion criteria applied, and (iii) quantitative metrics (R² values, confidence intervals) used to assess agreement across context sizes. Supplementary material will include raw data points for verification. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper explicitly introduces and adopts an exact k-gram ansatz as a modeling substitute for context-k transformers, then derives its asymptotic predictions (variance scaling, kurtosis, inconsistency probabilities) directly from the ansatz applied to the Ising and coloring broadcast processes. These derived quantities are subsequently compared to outputs of trained transformers via separate empirical validation, without any reduction of the predictions to quantities fitted from the target data or any tautological equivalence by construction. The contrasting upper bound for the autoregressive reasoning model with Θ(log n) memory is established via an independent proof that does not rely on the ansatz or fitted statistics. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear in the provided text; the central claims remain self-contained against the stated modeling assumptions and external empirical checks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The exact k-gram ansatz accurately models the output distribution of a transformer with context length k
Reference graph
Works this paper leans on
-
[1]
The first term corresponds to choosing the same subtree each time. In this case, with probabilityρ, the root of the subtree remains the same as the root of the full tree and we get the same quantity of the subtree one level below. If this does not occur, then the root of the subtree is rerandomized and the expectation is zero by symmetry since we are comp...
-
[2]
The second term corresponds to the different ways of choosing two subtrees, one of them twice. There ared·(d−1)choices for them (where the first choice is taken twice), and given this choice, there are three permutations. The square term is preciselyM d,ρ,h−1(2), while for the linear term, it again becomes mean zero with probability1−ρindependently, else ...
-
[3]
Finally, all three indices are different, and we may freely permute them to gived(d−1)(d−2) options. Conditioned on the root, each retains the signal with probabilityρindependently, and given they all do, the corresponding means areM d,ρ,h−1(1) = (dρ)h−1. When any of these events fails, the expectation simply becomes zero. The second equality then comes f...
-
[4]
We first sample, if not already observed, the values along the path defined byrin the current(d, h, κ)- broadcast process. • Ifr= (1,· · ·,1), then we recursively sample through the broadcast channelκ X∅, X(1), X(1,1),· · ·, X r . That is,X ∅ is sampled from the stationary distribution ofκ, andX r[1:ℓ+1] is sampled from κ(Xr[1:ℓ],·)for eachℓ= 0,1,· · ·, h...
-
[5]
We sample a(d, w, κ, δ Xr)-language and setY ′ to be the sampled leaves
Now we have access to the valuesX ∅,· · ·, X r. We sample a(d, w, κ, δ Xr)-language and setY ′ to be the sampled leaves. This is the broadcast process onT d,w where the root has a fixed valueX r. Then we set P ′ = (X∅,· · ·, X r[1:h−w−1])
-
[6]
Letkbe the largest integer such thatr k < d. We set r′ = (r1,· · ·, r k + 1,1,· · ·,1). If such an integer does not exist, the sampling has finished and we reset tor ′ = (1,· · ·,1). As noted before, this can be understood as the depth-first sampling of a broadcast process and thus samples the correct language by construction. 34 G Experiment Details G.1 ...
-
[7]
Sample an infinite sequence of independent broadcast processes:T (1) d,h with leavesX (1) r ,T (2) d,h with leavesX (2) r , and so on
-
[8]
Tokenize the processes which gives the sequences (τ (1) 1 ,· · ·, τ (1) L ),(τ (2) 1 ,· · ·, τ (2) L ),· · ·
-
[9]
Join them with the context refresh token, giving an infinite sequence (˜τ1,˜τ2,· · ·) = (τ (1) 1 ,· · ·, τ (1) L ,∅, τ (2) 1 ,· · ·, τ (2) L ,∅, τ (3) 1 ,· · ·). 35
-
[10]
In particular,˜τι =τ (1) ι ifι≤Land˜τ ι =∅otherwise
Sample a random indexι∼Uniform({1,· · ·, L+ 1})and obtain a consecutive subsequence ˜τι,˜τι+1,· · ·,˜τ ι+k . In particular,˜τι =τ (1) ι ifι≤Land˜τ ι =∅otherwise
-
[11]
Now set x= (˜τι,· · ·,˜τ ι+k−1),y= (˜τ ι+1,· · ·,˜τ ι+k). For each backpropagation, a fresh pair of(x,y)is sampled from this procedure. This resembles the way the pre-training of large language models is usually done on large corpuses. In practice, the sequence(˜τ1,· · ·,) and the indexιare not randomly sampled for each training step, but oftenιis just ta...
-
[12]
Sample an infinite sequence of independent broadcast processesT (1) d,h , T (2) d,h and the corresponding sequences of memory states: for eachT (i) d,h we write ∅=M (i) 0 , M (i) 1 ,· · ·, M (i) L+1 =∅ for its sequence of memory states
-
[13]
Following the same process in Section G.2 we obtain the sequence (˜τ1,˜τ2,· · ·) = (τ (1) 1 ,· · ·, τ (1) L ,∅, τ (2) 1 ,· · ·, τ (2) L ,∅, τ (3) 1 ,· · ·)
-
[14]
Sample a random indexι∼Uniform({1,· · ·, L+ 1})and consider the infinite sequence ˜τι,˜τι+1,· · ·
-
[15]
The memory tokens to insert before˜τs are determined by the following
We insertℓ m = 2 + 2htokens right before each of the tokens˜τ ι,˜τι+ℓv ,˜τι+2ℓv ,· · ·. The memory tokens to insert before˜τs are determined by the following. Ifs−1 = (L+ 1)i+jfor integersiand 0≤j≤L, we insert the tokenization ofM (i+1) j
-
[16]
Take the firstk+ 1tokens from the new token sequence. Setxandyto be the firstkand the lastk tokens from the chosen subsequence. Note thatxis an alternating sequence ofℓ m memory tokens andℓ v output value tokens. Thus, the model learns to predict the next tokens given the firstℓ m memory tokens, and to maintain its memory state every ℓv outputs. G.4 Compu...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.